
我叫Elena Rastorgueva,负责
HFLabs的Factor产品。 Factor是一个复杂的算法企业;它以工业规模处理数据。
在本文中,我将告诉您我们如何开始测试“因子”,我们如何开发自动测试以及为什么要使用自写框架。
这是什么产品-“因子”
“ Factor”可以清理拥有数百万客户的数据库中的数据:删除名称,电话和电子邮件中的错别字,检查护照,还有很多其他事情。 最困难的事情是更正邮寄地址。
 地址以数百种方式编写,因此该因子具有强大的算法功能
地址以数百种方式编写,因此该因子具有强大的算法功能“因子”充当服务:输入数据-输出数据。
这是一个无状态系统,其中每个调用都独立于先前的调用。 无状态极大地简化了测试仪的寿命。 当一系列动作很重要时,测试有状态系统要困难得多。
该产品必须像ISS一样可靠,因为它被银行,移动运营商,保险和Lenta级别的零售商所使用。 如果与客户的合同中的SLA属于不存在错误的范围,那么我们就对错误负责。
由于自动测试的可靠性要求,我们从开发之初就开始编写。 准备就绪的条件之一是“添加自动测试”。
从手动检查和自动测试开始
我们于2005年推出了Factor,并首先进行了手动测试。 早上,测试人员对带有案例的文件进行自动测试,并将数据处理的结果与前一天的结果进行比较:前一天的代码提交后,结果发生了变化。
该过程可能需要半天,这种对齐方式不好。 因此,我们对关键功能进行了最少的测试,并包含在单元测试中。 这些测试很快,开发人员自己在提交之前运行了它们。
单元测试是如此便捷,如此之快,以至于我们增加了数千个单元测试。 然后我们遇到了:当测试看起来像成千上万的代码片段时,滚动到正确的位置并不容易。 更不用说添加或更新。
 用于检查SNILS格式的单元测试
用于检查SNILS格式的单元测试此外,在工业数据中突然出现了一些意料之外的事情,其中不包括单元测试。 例如,一个新客户的地址具有新功能,单元测试不涵盖这些功能。 您需要坐下来看看要为新数据添加哪些测试。 我们仍然手动执行此操作。
创建自己的框架
在传统的单元测试中,数据和代码混合在一起;很难找到合适的部分。
因此,我们尝试了
数据驱动测试(DDT)范例中的自动
测试 。 DDT是指用于测试的数据与用于测试的代码分开存储的时间。
案例是从excel文件加载的;它们位于“原始数据”和“预期结果”列中。 滴滴涕是一项突破:在“ exelnik”中更新案例非常简单。
我们一点一点地开发了一种方法并开发了自己的测试框架。 它接收文本文件作为输入,其中包含源数据和预期结果。
 我们拒绝使用excel文件作为存储:文本文件打开速度更快,不更改内容,更容易从它们中收集数据
我们拒绝使用excel文件作为存储:文本文件打开速度更快,不更改内容,更容易从它们中收集数据该框架由标准工具提供帮助:
- TeamCity每晚自动运行测试;
- testNG比较预期结果和实际结果。
 如果结果与预期不同,则在TeamCity中测试会脸红。 如果一切正常,则测试为绿色
如果结果与预期不同,则在TeamCity中测试会脸红。 如果一切正常,则测试为绿色自己修改框架
从那时起已经过去了12年。 在这段时间内,该框架已经拥有了标准解决方案所没有的功能。
计入Jira中的任务状态。 HFLabs坚持
测试驱动开发 :首先,我们编写测试或添加测试用例以实现新的行为,然后才更改功能。
我们通过注释行关闭了新案例。 否则,它们首先跌倒并受到干扰,因为案例之前曾添加功能或错误修复。
但是该任务可能无法完成相应的测试用例:该错误非常罕见,或者客户将带来更重要的东西。 有些任务以低优先级挂了几个月,并且累积了断断续续的案例。 同时,不清楚每个案例属于什么任务,是否可以删除该案例。
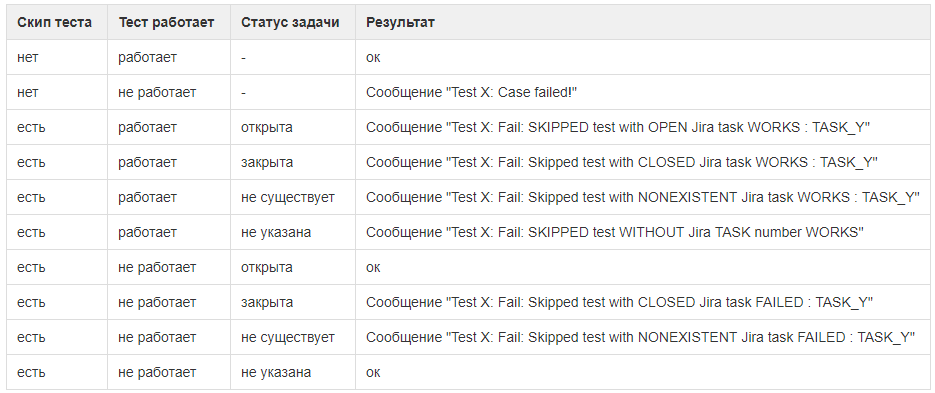
因此,我们在未连接的情况下增加了任务编号,并增加了自动化程度。 现在,一切工作如下:
- 通过与Jira中的打开任务匹配来禁用测试用例;

要将案例附加到任务上,请在任务号和任务编号前写上
- 该框架甚至在禁用情况下也运行测试。 但是忽略在Jira中打开任务时的崩溃;
- 任务一旦关闭,测试就开始依赖于附加的案例。 这是一个信号:他们通过了任务,但忘了开箱。
- 如果突然断开任务的测试通过一个开放任务而开始通过,则框架还将告知有关情况。 也许是时候打开机箱或关闭附带的任务了(加上更新发行说明并通知客户)。

框架说,断断续续的情况正在发生。 也许有人将代码改正为另一项任务的一部分,现在一切正常
因此,在管理测试用例时,我们节省了TDD并消除了健忘。
 我们记录了所有选项以及测试用例和相关任务的状态,以免忘记在半自动模式下更新测试用例。
我们记录了所有选项以及测试用例和相关任务的状态,以免忘记在半自动模式下更新测试用例。 看来,如果测试崩溃,请在代码中查找错误。 但是对我们而言,并非总是如此。 有时会发生测试用例需要更新的情况,因为对结果的要求已更改。
例如,在清除地址中的客户想要“ g。 莫斯科”。 现在,他已经更改了数据库的体系结构,他希望一个字段中的“城市”,另一个字段中的“莫斯科”。 现在该更改测试用例了。
对于失败的测试,TeamCity显示预期结果与实际结果之间的差异。 以前,我们复制了这种差异并手动更新了测试用例。 进行大规模更改-一项非常昂贵的活动。
 一个生动的例子:我们教“因素”来通过电话号码确定一个国家,TeamCity中的测试失败了。 可以从实际结果中得出新的基准,但是需要很长时间
一个生动的例子:我们教“因素”来通过电话号码确定一个国家,TeamCity中的测试失败了。 可以从实际结果中得出新的基准,但是需要很长时间我们使框架更新了基准本身。 为此,在运行测试后,它将标准中的预期清洁结果替换为不符合标准的实际清洁结果。 结果将作为案例更新文件保存在工件中。
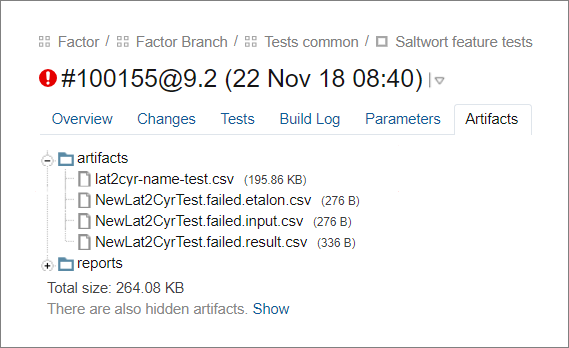 第一个文件是新的基准,框架在其中更新了预期的结果。 其余文件是输入数据,旧标准和已删除案例的实际数据。
第一个文件是新的基准,框架在其中更新了预期的结果。 其余文件是输入数据,旧标准和已删除案例的实际数据。使用新的基准,测试人员可以分三步更新案例。
- 下载生成的文件。
- 通过任何合并工具检查新基准中有哪些更改。 仅留下必要的内容。
- 提交
 测试人员检查新标准中的更新是否正确并提交
测试人员检查新标准中的更新是否正确并提交是的,如果不加考虑地进行更新,将不会带来任何好处。 但是,如果手动进行操作,则可能会进行粗心的更新。
使用存根稳定测试数据。 “因子”返回数十个字段中的已处理数据。 仅在一个地址中有很多组件:索引,区域,区域类型,城市类型,城市,街道类型,房屋,建筑物,建筑物,公寓。 对他们来说,“要素”抓住了IFTS,OKATO,OKTMO甚至是小东西。 因此,从输入的一行获得了数十个值。
并非所有结果字段都需要用测试用例进行检查。 例如,对同一地址的识别直接取决于状态目录-FIAS。 而且在其中,领域经常变化,对于我们的任务而言,它们是完全无关的。 更新房屋的一些CLADR代码会丢弃数百个测试用例。
当我们意识到浪费时间分析不重要的跌倒时,我们在预期结果中添加了存根。
当根本不需要检查该字段时,测试人员会在预期结果中写入一个符号:
$$ DNV $$ 。 应填写字段的时间,但值本身并不重要:
$$ NE $$ 。
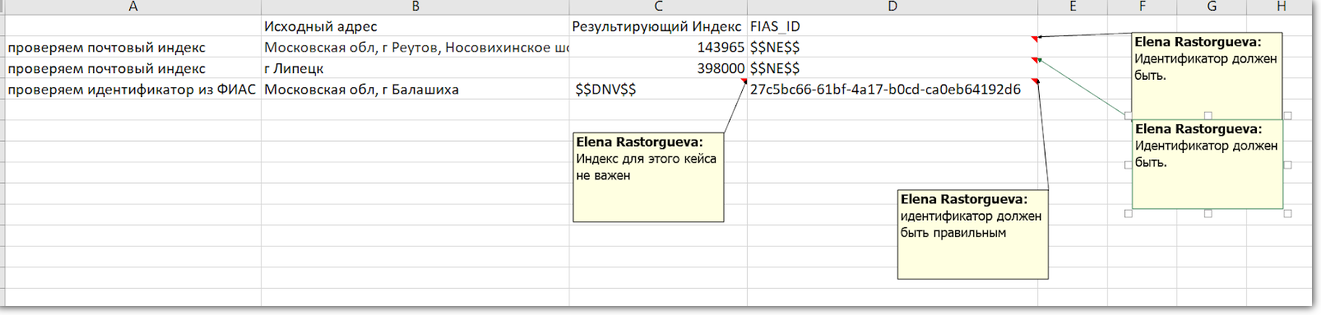 FIAS ID始终在地址中,因此我们在所有测试中都对其进行检查。 如果该字段为空,则表示有问题。 但是索引可能不是,因此在检查FIAS ID时,我们将忽略索引
FIAS ID始终在地址中,因此我们在所有测试中都对其进行检查。 如果该字段为空,则表示有问题。 但是索引可能不是,因此在检查FIAS ID时,我们将忽略索引您可以采用另一种方式来分离测试:每个字段都有自己的字段。 但这很困难,因为并非所有事物都可以隔离。 例如,“城市”和“街道”是地址的一部分,彼此之间没有意义。
自写框架更方便
因此,我根本不认为创建自己的框架是一项愚蠢的工作。 如果我们没有创建自己的工具,那么我们将不会获得太多的新机会和灵活性。
我们的测试人员现在在其他框架中要求按任务状态关闭文本情况,生成新基准和结果存根。 如果采用标准解决方案,我们将永远无法做到。
如果您想在企业中做复杂的事情,请来找我们。 现在我们正在寻找一名Java开发人员 ,薪水从135 000₽起没有个人所得税。