
从事人工智能领域研究的Alphabet子公司DeepMind宣布了这一宏伟目标的新里程碑:
AI首次在《星际争霸II》战略中击败了人类 。 2018年12月,一个名为
AlphaStar的卷积神经网络传播了职业选手
TLO (德国达里奥·翁什)和
MaNa (波兰格则哥斯·科明兹),赢得了十场胜利。 该公司昨天在YouTube和Twitch的
直播中宣布了此活动。
在这两种情况下,人员和程序都扮演着神族的角色。 尽管TLO并不擅长这场比赛,但马纳(MaNa)提出了严重的抵抗,甚至赢得了一场比赛。
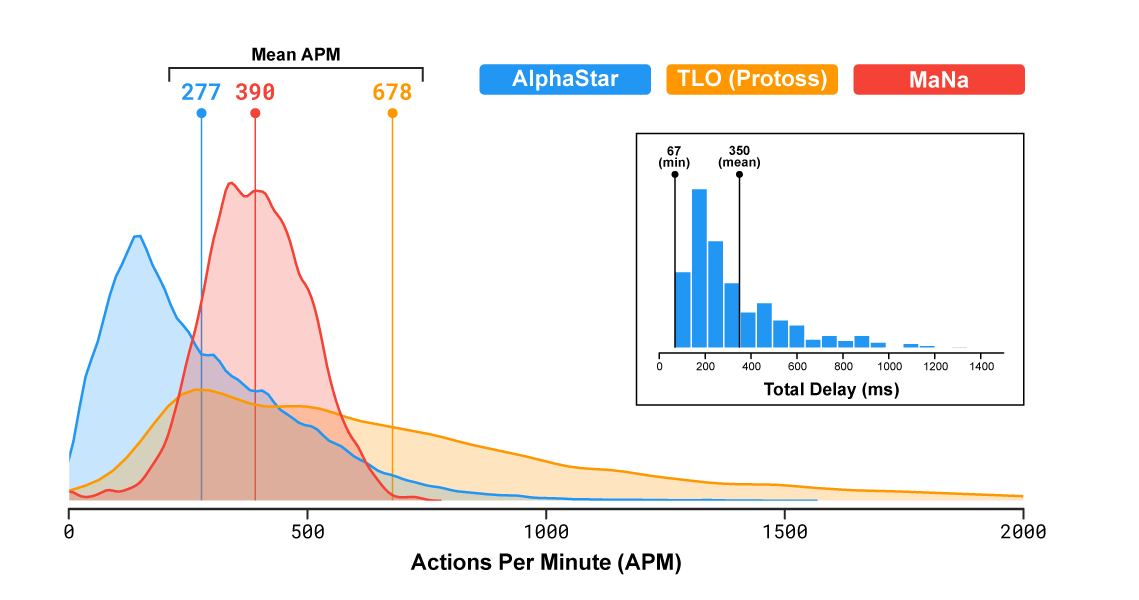
在流行的实时策略中,玩家代表三项争夺资源,构建结构并在大地图上战斗的竞赛之一。 重要的是要注意,程序的速度及其在战场上的能见度是有限的,因此AlphaStar不会在战胜他人方面获得不公平的优势(更正:显然,能见度仅在最后一场比赛中受到限制)。 实际上,根据统计数据,该程序每分钟执行的动作甚至少于人:AlphaStar平均为277,MaNa为390,TLO为678。
该
视频从第二次对阵MaNa的AI代理的角度显示了游戏的视角。 还显示了从人的角度看的视图,但是该视图不适用于该程序。
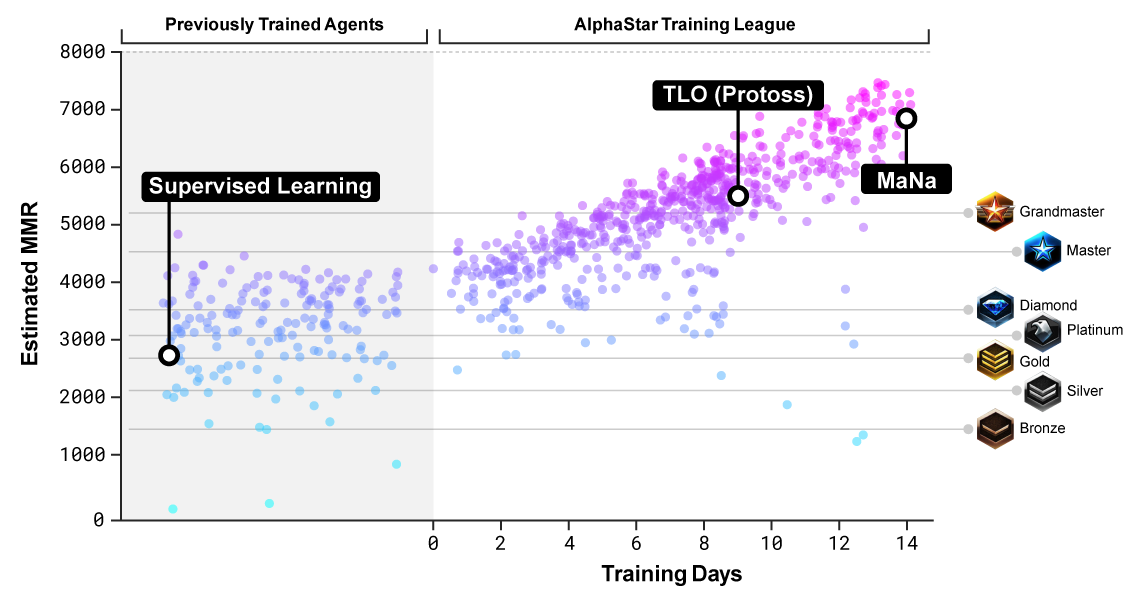
AlphaStar受过训练,可以在称为AlphaStar League的环境中玩神族。 首先,神经网络花了三天的时间查看游戏记录,然后使用一种称为强化训练,磨练技巧的技术自己玩游戏。
在12月,他们首次组织了一场针对TLO的游戏,其中测试了五个不同版本的AlphaStar。 这次,TLO
抱怨说他不能适应对手的比赛。 该程序以5-0的分数获胜。
在优化了神经网络的设置之后,一周后与MaNa进行了比赛。 该程序再次赢得了5场比赛,但是MaNa在最后一场比赛中对最新版本的算法进行了报仇,因此他有一些值得骄傲的地方。
 评估训练神经网络的对手的水平
评估训练神经网络的对手的水平为了了解战略计划的原理,AlphaStar必须掌握特殊的思想。 当需要复杂策略时,为此游戏开发的方法可能在许多实际情况中有用:例如贸易或军事计划。
《星际争霸2》不仅是一款极具挑战性的游戏。 这也是一个信息不完整的游戏,玩家无法始终看到对手的动作。 它还缺乏最佳策略。 而且,玩家的动作结果需要一些时间才能变得清晰:这也使学习变得困难。 DeepMind团队使用了非常专业的神经网络架构来解决这些问题。
游戏学习有限
DeepMind是著名的软件开发人员,击败了世界上最好的围棋和象棋专家。 在此之前,该公司开发了几种算法,可以学会玩简单的Atari游戏。 电子游戏是衡量人工智能进步并将计算机与人进行比较的好方法。 但是,这是一个非常狭窄的测试区域。 与以前的程序一样,AlphaStar仅执行一项任务,尽管效果非常好。
可以说,一个弱小的狭义的AI掌握了战略计划和作战策略的技能。 从理论上讲,这些技能可以在现实世界中派上用场。 但实际上并非一定如此。
一些专家认为,如此高度专业化的AI应用与强大的AI无关:“已经学会了以“超人”级别熟练玩特定视频游戏或棋盘游戏的程序,在条件发生最小变化(更改屏幕背景或更改位置)的情况下,
完全 消失了。虚拟“平台”跳动的“球”), -说,计算机科学教授在波特兰州立大学,梅拉妮米切尔的文章
“人工智能跑进一个障碍ponima 蒸发散“ 。 -如果情况与接受培训的情况略有不同,这些仅是几个例子,说明最佳AI程序的可靠性。 这些系统中的错误范围从荒谬,无害到潜在的灾难性。
这位教授认为,人工智能商业化竞赛给研究人员施加了巨大压力,要求他们创建在狭窄任务中“合理运行”的系统。 但是最终,可靠的AI的发展需要对我们自己的能力进行更深入的研究,并对我们自己使用的认知机制有新的理解:
我们对面对的情况的理解基于广泛,直观的“常识概念”,即世界如何运转以及其他生物(尤其是其他人)的目标,动机和可能的行为。 此外,我们对世界的理解基于我们的基本能力,即我们能够概括我们所了解的知识,形成抽象概念并进行类推-简而言之,就是使我们的概念灵活地适应新情况。 几十年来,研究人员一直在尝试教授AI直观常识和可持续人类能力来进行概括,但是在这一非常困难的问题上进展甚微。
到目前为止,AlphaStar神经网络只能为神族效力。 开发商宣布了未来训练她参加其他比赛的计划。