
我再一次开车在我的家乡绕过另一个坑,我想:在我们的国家中是否存在这样的“好”道路,所以我决定我们应该用我们国家的道路质量客观地评估情况。
任务形式化
在俄罗斯,对道路质量的要求在GOST R 50597-2017“道路与道路。 在确保道路安全的条件下可接受的运行状态要求。 控制方法。” 该文件定义了覆盖行车道,路边,分隔带,人行道,人行道等的要求,并确定了损坏的类型。
由于确定道路的所有参数的任务非常艰巨,因此我决定自己缩小范围,仅关注确定道路覆盖范围缺陷的问题。 在GOST R 50597-2017中,对道路涂层的以下缺陷进行了区分:
我决定解决这些缺陷。
资料收集
在哪里可以得到描绘道路足够大的照片,甚至参考地理位置? 答案来自水钻-Yandex(或Google)地图上的全景图,但是,经过一番搜索,我发现了更多其他选择:
不幸的是,对这些选项的分析表明,它们对我而言不太合适:发出搜索引擎的声音很多(很多不是道路的照片,各种渲染等),来自投诉站点的照片仅包含严重违反沥青表面的照片,在这些站点上有很多违反覆盖率小的照片,而没有违反覆盖率的照片,RoadDamageDetector项目的数据集是在日本收集的,不包含违反覆盖率大的样本以及完全没有覆盖率的道路。
由于其他选项不合适,因此我们将使用Yandex全景图(我排除了Google全景图选项,因为该服务在俄罗斯的城市较少,并且更新频率也不高)。 他决定在人口超过10万的城市以及联邦中心收集数据。 我列出了城市名称列表-其中有176个城市,后来发现只有149个城市名称。 我不会深入探讨解析图块的功能,我会说最终得到了149个文件夹(每个城市一个文件夹),其中总共有170万张照片。 例如,对于Novokuznetsk,该文件夹如下所示:

根据下载的照片数量,城市分布如下:
桌子城市名
| 照片数量,件
|
|---|
莫斯科
| 86048
|
圣彼得堡
| 41376
|
萨拉斯克
| 18880
|
波多尔斯克
| 18560
|
克拉斯诺戈尔斯克
| 18208
|
柳伯特西
| 17760
|
加里宁格勒
| 16928
|
科洛姆纳
| 16832
|
密志
| 16192
|
海参div
| 16096
|
巴拉希卡
| 15968
|
彼得罗扎沃茨克
| 15968
|
叶卡捷琳堡
| 15808
|
大诺夫哥罗德
| 15744
|
纳贝雷兹尼·切尔尼(Naberezhnye Chelny)
| 15680
|
克拉斯诺达尔
| 15520
|
下诺夫哥罗德
| 15488
|
希姆基
| 15296
|
图拉
| 15296
|
新西伯利亚
| 15264
|
特维尔
| 15200
|
米亚斯
| 15104
|
伊万诺沃
| 15072
|
沃洛格达
| 15008
|
茹科夫斯基
| 14976
|
科斯特罗马
| 14912
|
萨马拉
| 14880
|
科罗廖夫
| 14784
|
卡卢加
| 14720
|
Cherepovets
| 14720
|
塞瓦斯托波尔
| 14688
|
普希金诺
| 14528
|
雅罗斯拉夫尔
| 14464
|
乌里扬诺夫斯克
| 14400
|
顿河畔罗斯托夫
| 14368
|
多莫杰多沃
| 14304
|
卡门斯克-乌拉尔斯基
| 14208
|
普斯科夫
| 14144
|
约什卡尔奥拉
| 14080
|
刻赤
| 14080
|
摩尔曼斯克
| 13920
|
陶里亚蒂
| 13920
|
弗拉基米尔
| 13792
|
老鹰
| 13792
|
西克特夫卡
| 13728
|
多尔格普鲁德尼
| 13696
|
汉蒂·曼西斯克
| 13664
|
喀山
| 13600
|
恩格斯
| 13440
|
阿尔汉格尔斯克
| 13280
|
布良斯克
| 13216
|
鄂木斯克
| 13120
|
赛兹兰
| 13088
|
克拉斯诺亚尔斯克
| 13056
|
谢尔科沃
| 12928
|
奔萨
| 12864
|
车里雅宾斯克
| 12768
|
切博克萨雷
| 12768
|
下塔吉尔
| 12672
|
斯塔夫罗波尔
| 12672
|
拉门斯科耶
| 12640
|
伊尔库茨克
| 12608
|
安加尔斯克
| 12608
|
秋明州
| 12512
|
奥丁佐沃
| 12512
|
乌法
| 12512
|
马加丹
| 12512
|
烫发
| 12448
|
基洛夫
| 12256
|
下涅卡姆斯克
| 12224
|
马哈奇卡拉
| 12096
|
下涅瓦尔托夫斯克
| 11936
|
库尔斯克
| 11904
|
索契
| 11872
|
坦波夫
| 11840
|
皮雅提哥尔斯克
| 11808
|
伏尔加东斯克
| 11712
|
梁赞
| 11680
|
萨拉托夫
| 11616
|
捷尔任斯克
| 11456
|
奥伦堡
| 11456
|
土墩
| 11424
|
伏尔加格勒
| 11264
|
伊热夫斯克
| 11168
|
金口
| 11136
|
利佩茨克
| 11072
|
基斯洛沃茨克
| 11072
|
苏尔古特
| 11040
|
马格尼托哥尔斯克
| 10912
|
斯摩棱斯克
| 10784
|
哈巴罗夫斯克
| 10752
|
科佩斯克
| 10688
|
Maykop
| 10656
|
彼得罗巴甫洛夫斯克-堪察加斯基
| 10624
|
塔甘罗格
| 10560
|
巴瑙尔
| 10528
|
塞尔吉夫·波萨德(Sergiev Posad)
| 10368
|
埃莉斯塔
| 10304
|
斯特利塔马克
| 9920
|
辛菲罗波尔
| 9824
|
托木斯克
| 9760
|
Orekhovo-Zuevo
| 9728
|
阿斯特拉罕
| 9664
|
Evpatoria
| 9568
|
诺金斯克
| 9344
|
赤太
| 9216
|
别尔哥罗德
| 9120
|
比斯克
| 8928
|
雷宾斯克
| 8896
|
谢韦罗德文斯克
| 8832
|
沃罗涅日
| 8768
|
布拉戈维申斯克
| 8672
|
新罗西斯克
| 8608
|
乌兰乌德
| 8576
|
谢尔普霍夫
| 8320
|
阿穆尔河畔科姆索莫尔斯克
| 8192
|
阿巴坎
| 8128
|
诺里尔斯克
| 8096
|
南萨哈林斯克
| 8032
|
奥布宁斯克
| 7904
|
埃森图基
| 7712
|
巴塔斯克
| 7648
|
沃尔日斯基
| 7584
|
新切尔卡斯克
| 7488
|
别尔茨克
| 7456
|
Arzamas
| 7424
|
Pervouralsk
| 7392
|
克麦罗沃
| 7104
|
Elektrostal
| 6720
|
德本特
| 6592
|
雅库茨克
| 6528
|
慕罗姆
| 6240
|
涅夫捷尤甘斯克
| 5792
|
罗伊托夫
| 5696
|
比罗比詹
| 5440
|
新库比雪夫斯克
| 5248
|
Salekhard
| 5184
|
新库兹涅茨克
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
新切贝克萨尔斯克
| 4352
|
叶列兹
| 3968
|
卡斯皮斯克
| 3936
|
斯塔里·奥斯科尔(Stary Oskol)
| 3840
|
Artyom
| 3744
|
热列兹诺戈尔斯克
| 3584
|
萨拉瓦特
| 3584
|
普罗科别耶夫斯克
| 2816
|
戈尔诺-阿尔泰斯克
| 2464
|
准备训练数据集
这样,数据集就被组装好了,现在,如何获得路段和周围物体的照片,以找出上面显示的沥青的质量? 我决定在原始照片的中间正中间的下方切出一块尺寸为350 * 244像素的照片。 然后将裁切的裁片水平缩小到244像素。 生成的图像(大小为244 * 244)将作为卷积编码器的输入:

为了更好地了解我处理的数据,我对自己标记的前2000张照片,其余的照片由Yandex.Tolki员工进行了标记。 在他们面前,我用以下措词提出了一个问题。
指明您在照片中看到的路面:
- 土壤/瓦砾
- 铺路石,瓷砖,人行道
- 铁轨,铁轨
- 水,大水坑
- 沥青
- 照片中没有道路/异物/汽车遮挡不可见
如果表演者选择“沥青”,则会出现一个菜单,用于评估其质量:
- 出色的覆盖率
- 轻微的单裂纹/浅的单坑
- 大裂缝/网格裂缝/单个小坑洼
- 大坑洞/深坑洞/涂层被破坏
正如任务的测试运行所示,Y。Toloki的执行者在工作的完整性上并没有不同-他们不小心用鼠标单击了字段并认为任务已完成。 我必须添加控制问题(作业中有46张照片,其中12张是控制照片),并允许延迟接受。 作为控制问题,我使用了自己标记的照片。 我自动执行了延迟验收-Y. Toloka允许您将工作结果上传到CSV文件,并加载对响应进行验证的结果。 验证答案的工作方式如下-如果任务包含控制问题的5%以上的不正确答案,则认为该任务未完成。 此外,如果承包商指示的答案在逻辑上接近于真,则认为他的答案是正确的。
结果,我得到了大约3万张带标签的照片,我决定将这些照片分三类进行培训:
- “好”-标有“沥青:出色的涂层”和“沥青:轻微的单裂缝”的照片
- “中间”-标有“铺路石,瓷砖,人行道”,“铁路,铁轨”和“沥青:大裂缝/网格裂缝/单个小坑洼”的照片
- “大”-贴有“土壤/碎石”,“水,大水坑”和“沥青:大量坑洼/深坑洼/被毁路面”的照片
- 标记为“照片中没有路/异物/汽车遮盖不可见”的照片很少(22个。)我将它们排除在以后的工作之外
分类器开发和培训
因此,收集并标记数据后,我们便进行分类器的开发。 通常,对于图像分类的任务,尤其是在小数据集上进行训练时,使用现成的卷积编码器,将新的分类器连接到其输出。 我决定使用没有隐藏层,大小为128的输入层和大小为3的输出层的简单分类器。我决定立即使用在ImageNet上训练的几个现成的选项作为编码器:
- Xception
- Resnet
- 起始时间
- Vgg16
- Densenet121
- 移动网
这是使用给定编码器创建Keras模型的函数:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
为了进行培训,我使用了带有增强功能的生成器(由于Keras内置的增强功能似乎不足,因此我使用了
Augmentor库):
- 斜坡
- 随机失真
- 转弯
- 换色
- 班次
- 改变对比度和亮度
- 添加随机噪声
- 作物
扩充后,照片如下所示:

生成器代码:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
该代码显示扩充不用于测试数据。
有了经过调整的生成器,您就可以开始训练模型,我们将分两个阶段执行该模型:首先,仅训练我们的分类器,然后完全训练整个模型。
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
调用full_fit()并等待。 我们等待了很长时间。
结果,我们将有六个训练有素的模型,我们将在标记数据的单独部分上检查这些模型的准确性;我收到以下信息:
型号名称
| 准确度%
|
Xception
| 87.3
|
Resnet
| 90.8
|
起始时间
| 90.2
|
Vgg16
| 89.2
|
Densenet121
| 90.6
|
移动网
| 86.5
|
总的来说,并没有很多,但是由于培训样本如此之小,人们不能期望更多。 为了稍微提高精度,我通过平均以下方式组合了模型的输出:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
得出的准确度为91.3%。 基于这个结果,我决定停下来。
使用分类器
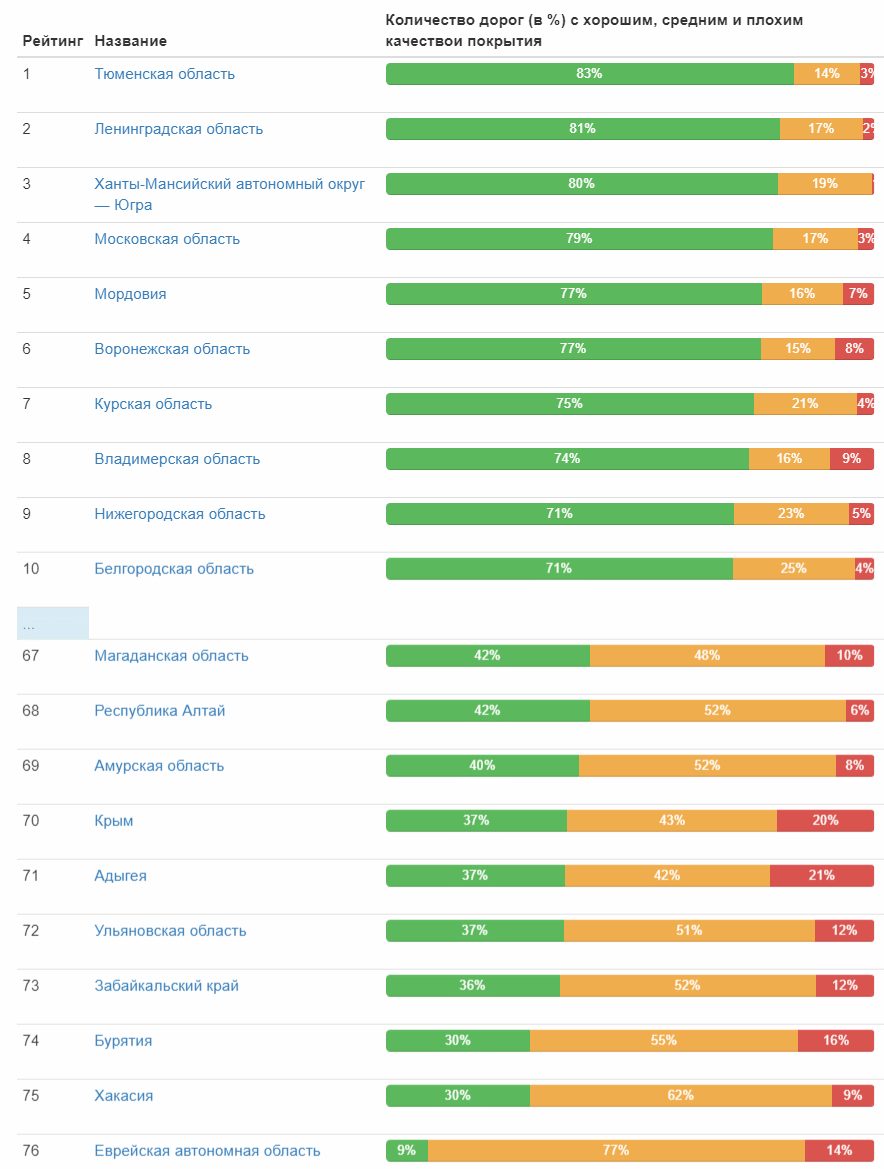
最终,分类器已准备就绪,可以投入使用! 我准备输入数据并运行分类器-一天多一点,处理了170万张照片。 现在最有趣的部分是结果。 立即将相对数量的道路中的前十个城市和后十个城市带入覆盖范围良好的道路:

这是联邦科目的道路质量等级:
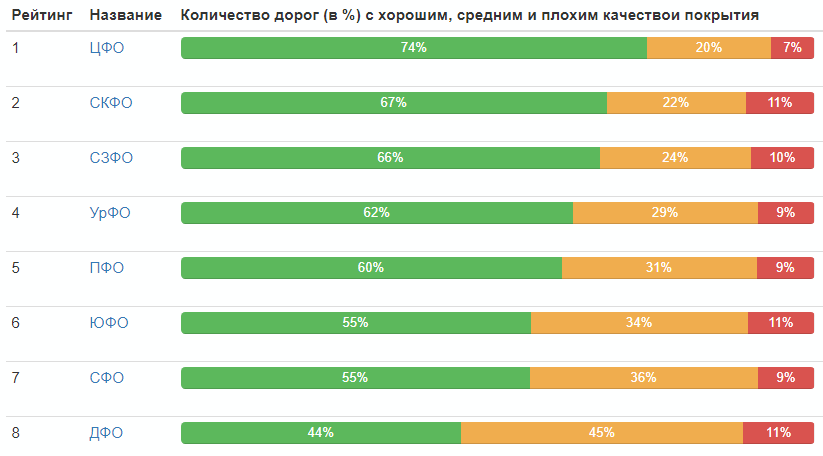
联邦地区评分:
整个俄罗斯的道路质量分布:

好,就是这样,每个人都可以自己得出结论。
最后,我将提供每个类别中最好的照片(在该类别中获得了最高的评价):
PS在评论中,很正确地指出了有关照片接收年份的统计数据。 我更正并给出一张桌子:
年份
| 照片数量,件
|
| 2008年 | 37 |
| 2009年 | 13 |
| 2010 | 157030 |
| 2011年 | 60724 |
| 2012年 | 42387 |
| 2013年 | 12148
|
| 2014年 | 141021
|
| 2015年 | 46143
|
| 2016年 | 410385
|
| 2017年 | 324279
|
| 2018年 | 581961
|