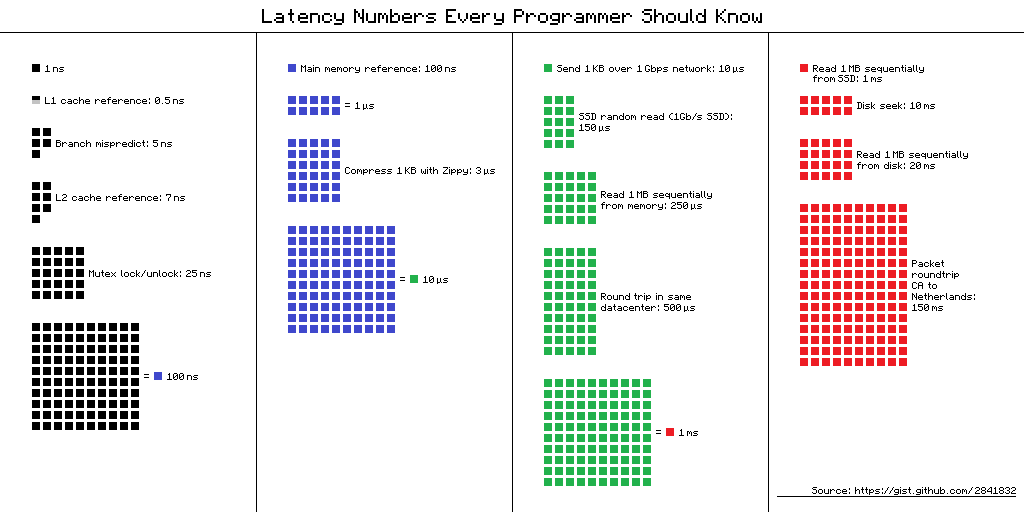
每个程序员都应该知道的延迟数 -“每个程序员都应该知道的延迟”表。 它包含2012年执行基本计算机操作的时间平均值。 该表有多个替代视图,这里是其中之一。
 链接到架构源
链接到架构源但是,2019年该信息对移动开发人员有何好处? 似乎没有,但是Yandex.Navigator团队的
Dmitry Kurkin (
SClown )认为:“现代iPhone的桌子会是什么样?” 结果出在Dmitry关于
AppsConf的报告的修订文本中。
这是为了什么
程序员为什么要知道这些数字? 它们与移动开发人员相关吗? 这些数字可以解决两个主要任务。
了解计算机的时间尺度
一个简单的情况-电话交谈。 我们可以轻松地说出这个过程何时快速,何时漫长:几秒钟非常快,几分钟是一次平均对话,一个小时或更长的时间很长。 加载页面的过程类似:在不到一秒钟的时间内(很快,几秒钟)可以忍受,而一分钟就是灾难,用户可能不必等待下载。
但是,诸如将数字添加到数组这样的操作(人们有时喜欢在采访中谈论的非常“快速插入”)又如何呢? 智能手机需要多少钱? 纳秒,微秒还是毫秒? 我见过很少有人会说1毫秒很长的时间,但就我们而言,情况确实如此。
各种计算机组件的速度比
在各种设备上执行操作的时间可能相差数十倍或数百倍。 例如,对主存储器的访问时间与访问L1缓存的时间相差100倍。 这是一个很大的差异,但不是无限的。 如果我们对此有特定含义,则在优化应用程序时,我们可以评估是否会节省时间。

现实生活中的“延迟数”
当我看到这些数字时,我开始对缓存和内存访问之间的区别感兴趣。 如果我小心翼翼地将数据放入不小于64 KB的字节中,那么我的代码将以100倍的速度运行-速度很快,一切都会飞起来!

我立即想将其全部检查出来,展示给我的同事,并尽可能地应用它。 我决定从Apple提供的标准工具开始-XSTest和measureBlock。 该测试的组织方式如下:确定一个数组,将其填充数字,对其进行XOR'il运算,然后重复10次该算法。 之后,我查看了一个元素需要花费多少时间。
| 缓冲区大小 | 总时间 | 手术时间 |
| 50 kb | 1.5毫秒 | 30纳秒 |
| 500 kb | 12毫秒 | 24毫微秒 |
| 5000 kb | 85毫秒 | 17 ns |
缓冲区的大小增加了100倍,并且操作时间不仅没有增加100倍,而且减少了近2倍。
先生们,军官,他们出卖了我们?!得出这样的结果之后,我大为怀疑,这些数字可以在现实生活中看到。 常规应用程序可能无法感觉到这种差异。 也许在移动平台上,一切都不同。
我开始寻找一种方法来查看缓存和主内存之间的性能差异。 在搜索过程中,我遇到了一篇文章,作者抱怨说,他在Mac和iPhone上运行了基准测试,没有显示这些延迟。 我拿了这个工具并得到了结果-就像在药房一样。 当缓冲区大小超过相应缓存的大小时,内存访问时间会明显增加。
 LMbench
LMbench帮助我获得了这些结果。 这是由Linux内核的开发者之一拉里·麦克沃伊(Larry McVoy)创建的基准,它使您能够测量内存访问时间,切换线程和文件系统操作的成本,甚至是主处理器操作所花费的时间:加,减等。德州仪器(TI)为处理器提供了
有趣的测量
数据 。 LMBench用C编写,因此在iOS上运行它并不困难。
内存成本
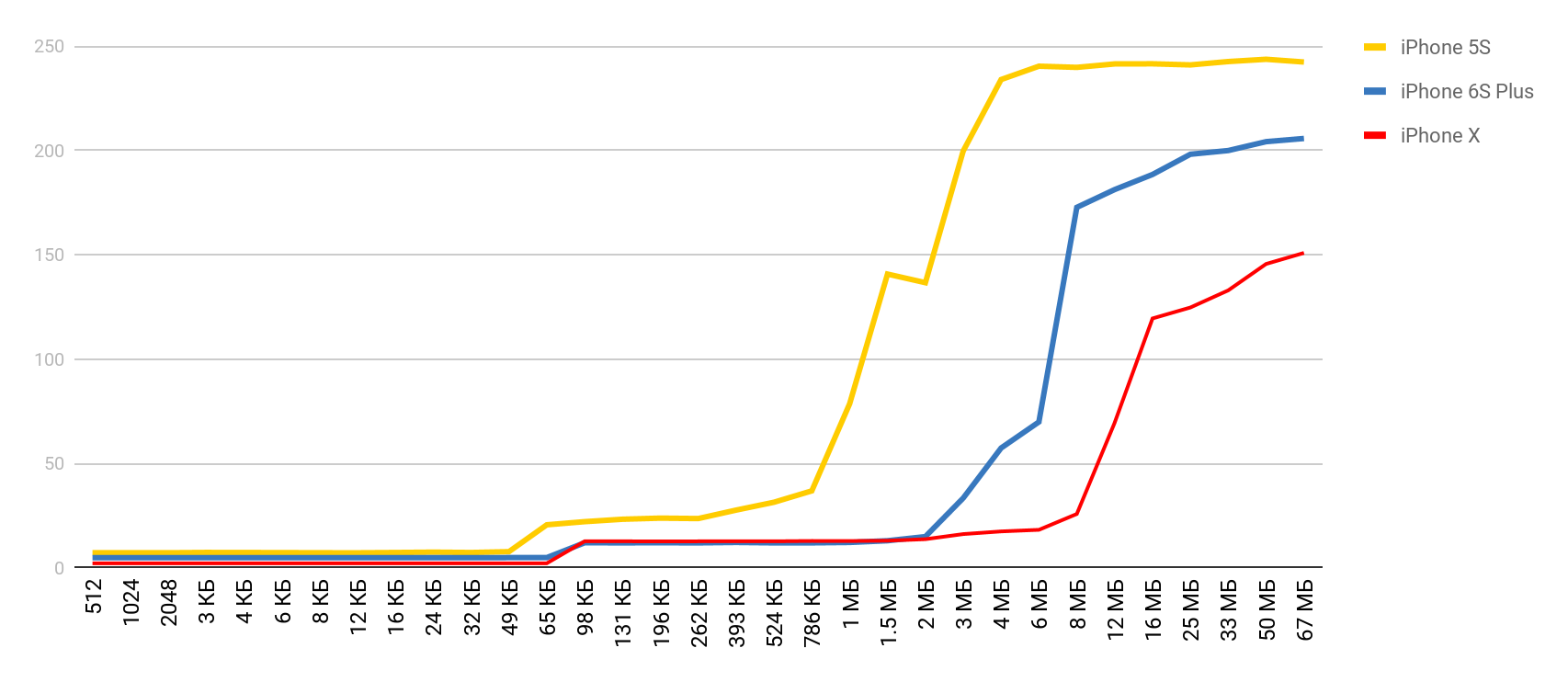
有了如此出色的工具,我决定进行类似的测量,但要针对实际的移动设备-iPhone。 主要测量是在5S上进行的,然后当其他设备落入我的手中时,我得到了结果。 因此,如果未指定设备,则为5S。
记忆体存取
对于此测试,使用一个特殊的数组,其中填充有互相引用的元素。 每个元素都是指向另一个元素的指针。 数组不是通过索引遍历的,而是从一个节点到另一个节点的转移。 这些元素散布在整个阵列中,因此,在访问新元素时,它通常尽可能不在缓存中,而是从RAM中卸载。 这种安排尽可能地干扰了缓存。
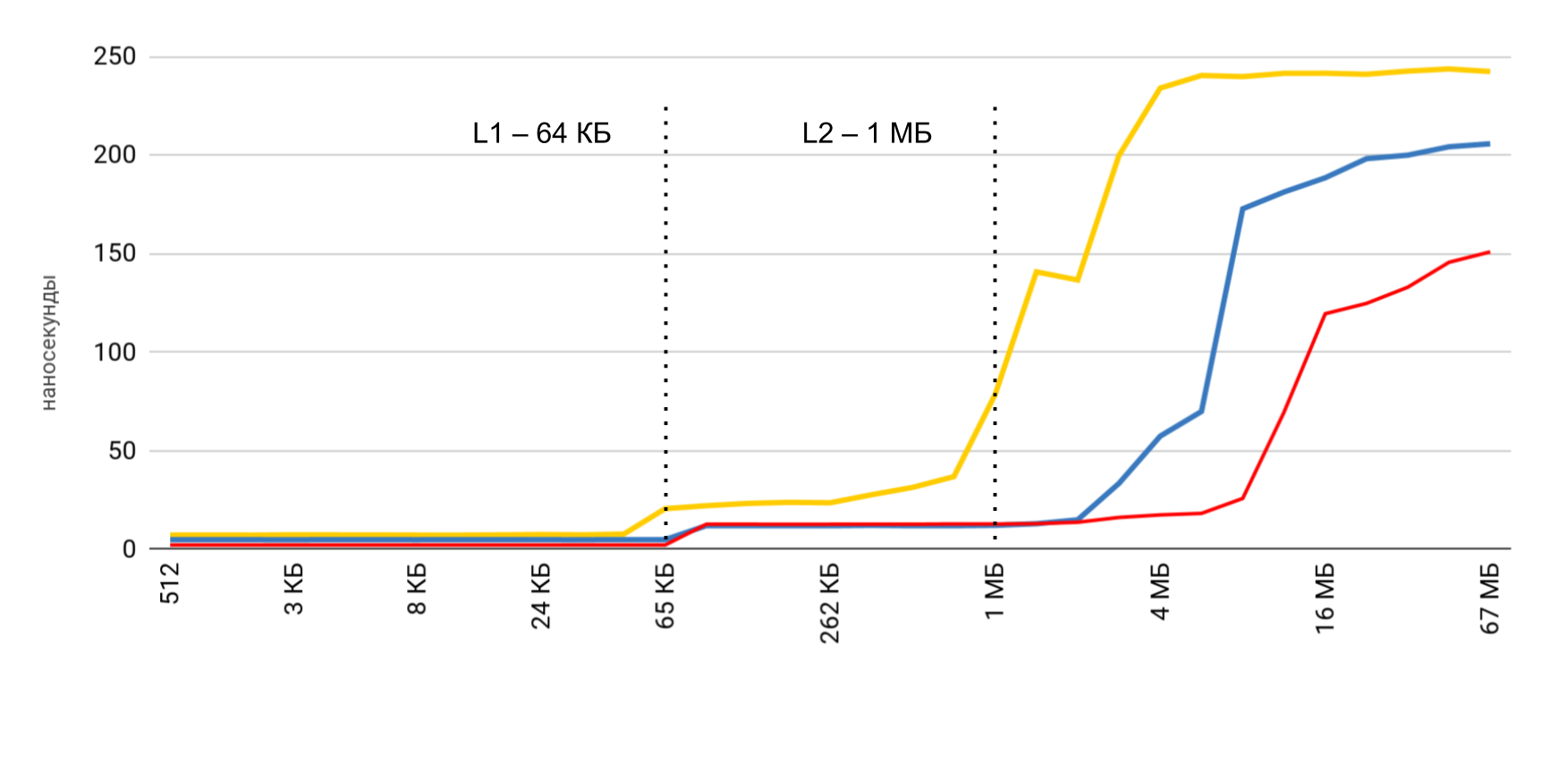
您已经看到了初步结果。 在L1高速缓存的情况下,它小于10纳秒,对于L2,则是几十纳秒,而在主存储器的情况下,时间增加到数百纳秒。
读写速度
测量了三个主要操作:
- 阅读( p [i] + )-我们阅读元素并将它们添加到总量中;
- record( p [i] = 1 )-在每个元素中写入一个常数;
- 读写( p [i] = p [i] * 2 )-我们取出元素,对其进行更改,然后将新值写回。
使用缓冲区时,使用2种方法:在第一种情况下,仅使用每四个元素,而在第二种情况下,所有元素都按顺序使用。
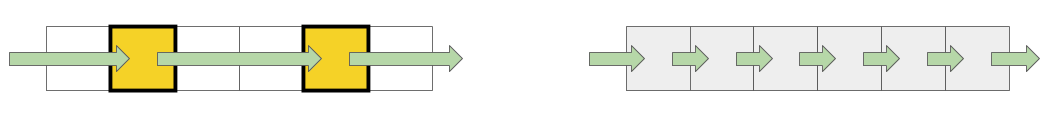
以较小的缓冲区大小获得最高速度,然后根据L1和L2高速缓存的大小有明确的步骤。 最有趣的是,当顺序读取数据时,不会降低速度。 但是在通过的情况下,可以看到清晰的步骤。
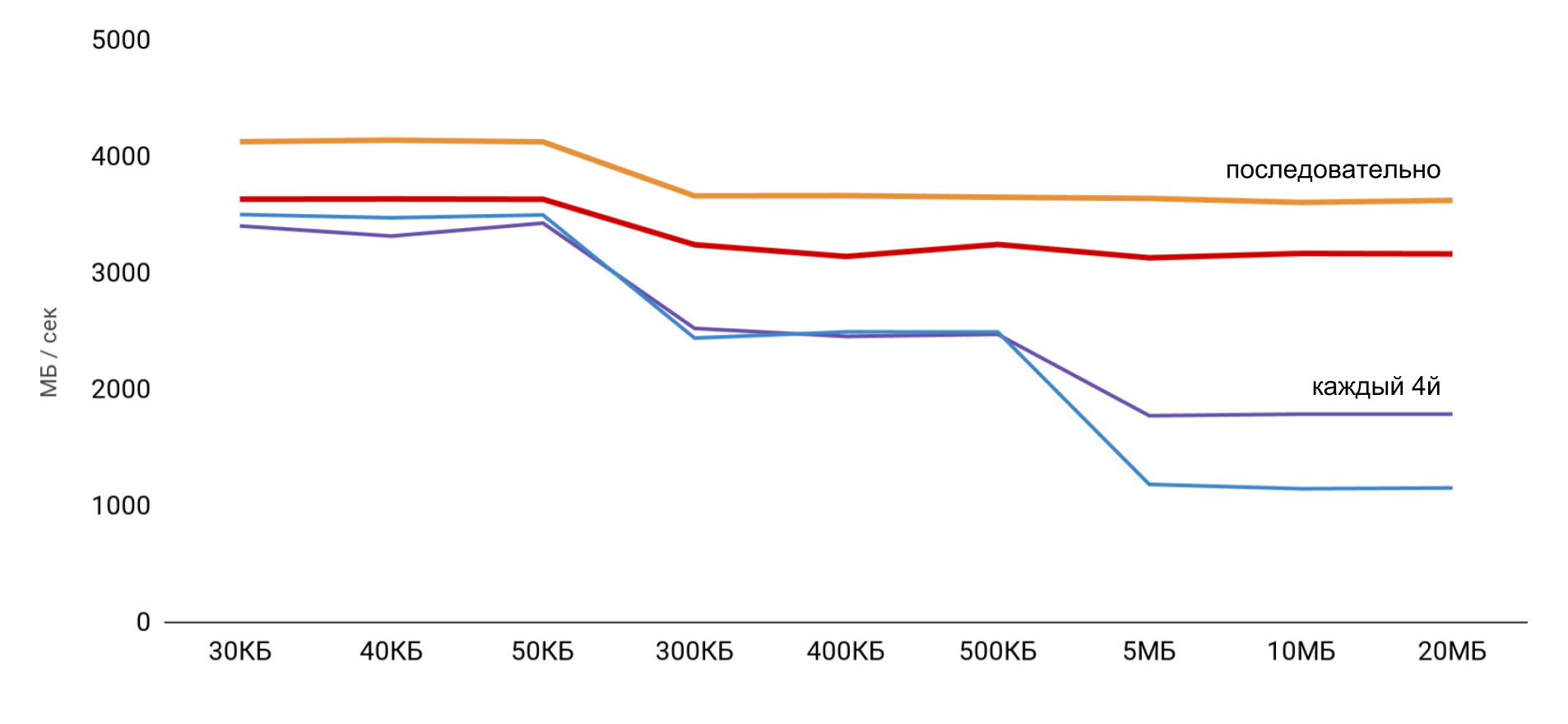
在顺序读取期间,操作系统设法将必要的数据加载到缓存中,因此对于任何缓冲区大小,我都不需要访问内存-所有必需的数据都是从缓存中获取的。 这解释了为什么我在基本测试中没有看到时差。
读写操作的测量结果表明,在正常应用中,很难获得100倍的估计加速度。 一方面,系统本身很好地缓存了数据,即使使用大型数组,我们也很可能在缓存中找到数据。 另一方面,使用各种变量很容易需要访问内存,并且损失了数百纳秒。
| L1 | L2 | 记忆体 |
| 延迟数 | 1纳秒 | 7 ns | 100毫微秒 |
| iPhone 5s | 7 ns | 30纳秒 | 240毫微秒 |
| iPhone 6s Plus | 5纳秒 | 12纳秒 | 200纳秒 |
| iPhone X | 2纳秒 | 12纳秒 | 146 ns |
穿线费用
接下来,我想获得与线程一起使用的类似数据,以便
了解使用多线程的成本 :创建一个线程并从一个线程切换到另一个线程要花费多少钱。 对我们来说,这些都是频繁的操作,我想了解损失。
仪器。 系统跟踪
系统跟踪对跟踪应用程序中的线程工作很有帮助。 在
WWDC 2016上对该工具进行了详细描述。 该工具有助于按流状态查看过渡,并在三个主要类别中显示流上的数据:系统调用,处理内存和流状态。
- 系统调用 它们以红色“香肠”的形式呈现。 指向它们时,您可以看到系统方法的名称和执行的持续时间。 通常在应用程序应用程序中,这样的系统调用不会直接发生:我们使用某些东西,而后者又已经调用了system方法。 您不应该依赖这样的事实,即您的代码中的方法在此处可见。
- 内存操作 。 它们以蓝色“香肠”的形式呈现。 这包括诸如内存分配,释放,清零等操作。
- 流的状态 。 蓝色-线程正在运行,某些处理器正在从该线程执行代码。 灰色-线程由于某种原因被阻塞,无法继续执行。 红色-线程已准备就绪,但是目前没有可用的内核来执行其代码。 橙色-中断流程以进行更高优先级的工作。
- 兴趣点 。 这些是特殊标签,可以通过调用
kdebug_signpost由代码安排。 标签可以是单个标签(在代码中的特定位置),也可以是范围标签(以突出显示整个过程)。 使用这样的标签,将微秒和系统调用与您的应用程序关联起来要容易得多。
流创建成本
第一个测试是
在新线程中执行任务 。 我们创建具有特定过程的线程,然后等待其完成工作。 将总时间与该过程本身的时间进行比较,我们得到在新线程中启动该过程的总损失。
在系统跟踪中,您可以清楚地看到所有事情是如何发生的:
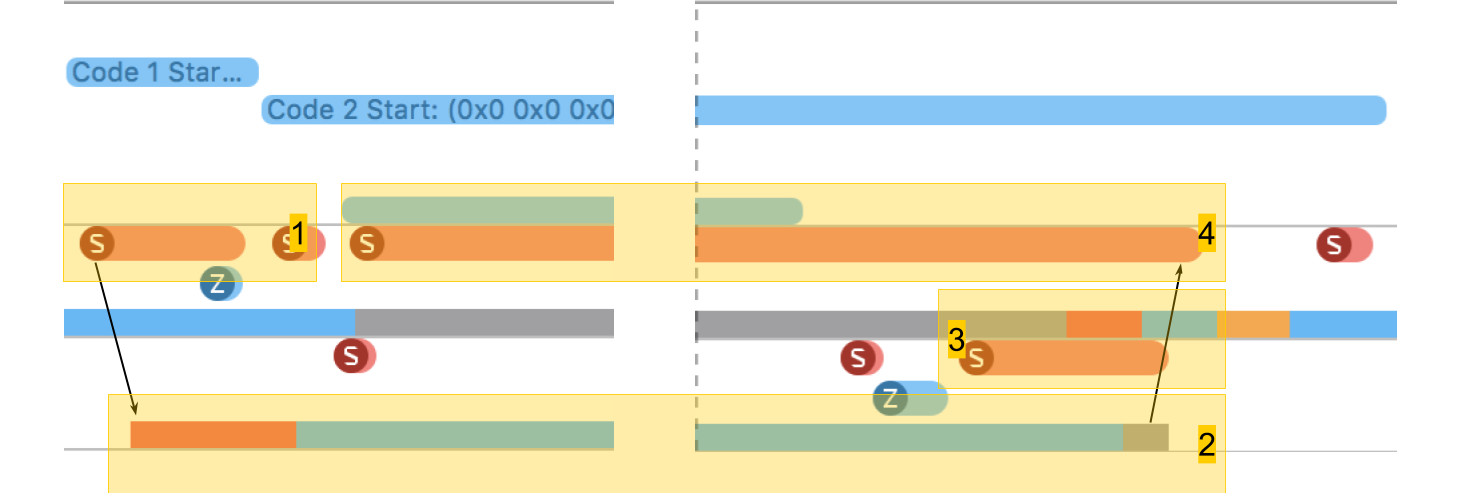
- 创建流。
- 我们的过程在其中运行的新线程。 开头的红色区域表示该线程已创建,但由于没有可用的内核,因此一段时间以来无法执行。
- 流的完成。 有趣的是,线程完成过程本身甚至比其创建还要大。 尽管删除似乎总是更快。
- 等待该过程的完成,这是原始方案中的过程,并且在流结束之后结束-暂时,该方法意识到了这一点,然后报告。 此时间比流完成的时间略长。
因此,创建流需要相当大的成本:iPhone 5S-230微秒,6S-50微秒。
流的完成花费的时间几乎是创建时间的2倍 ,加入流也需要花费明显的时间。 当使用内存时,我们得到了数百纳秒,比数十微秒少100倍。
| 开销 | 创造 | 结束 | 参加 |
| iPhone 5s | 230微秒 | 40微秒 | 70微秒 | 30微秒 |
| iPhone 6s Plus | 50微秒 | 12微秒 | 20微秒 | 7微秒 |
信号量切换时间
下一个测试是
对信号量的工作进行测量 。 我们有2个预先创建的线程,每个线程都有一个信号量。 流交替发信号通知邻居的信号量,并等待它们的信号量。 彼此传递信号,小溪互相打乒乓球,相互复兴。 这种双重迭代使信号量切换时间加倍。
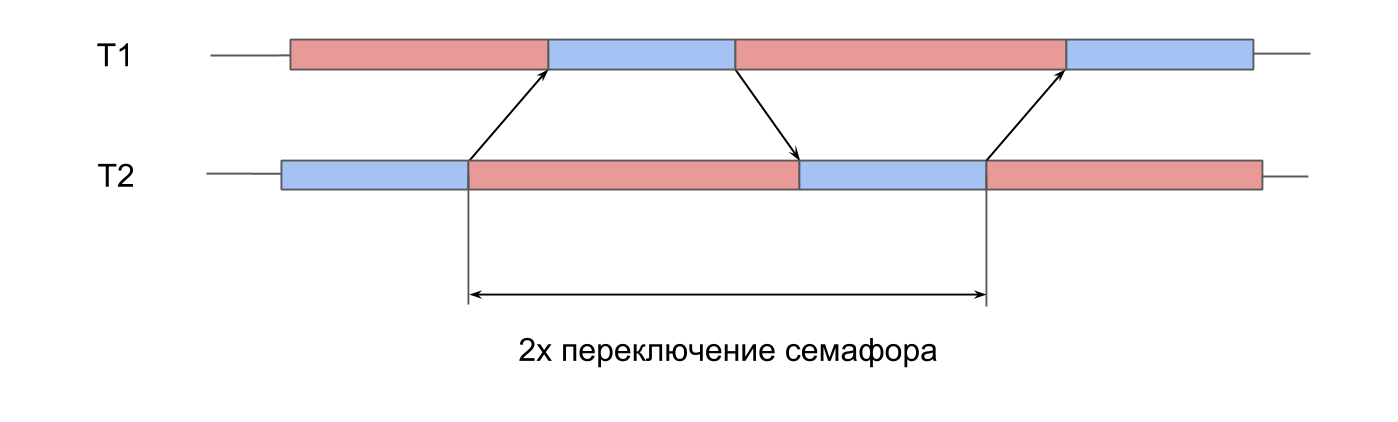
在系统跟踪中,一切看起来都类似:
- 给第二流的信号量信号。 可以看出该操作非常短。
- 第二个线程被解锁,对其信号量的等待结束。
- 为第一流的信号量提供信号。
- 第一个线程被解除阻塞,对其信号量的等待结束。
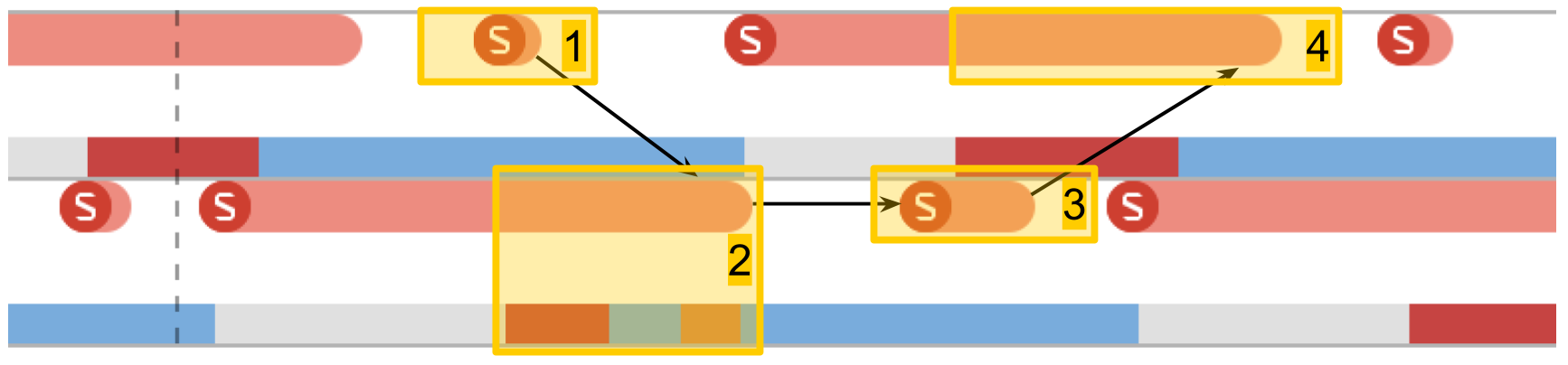
切换时间在10微秒以内。 创建线程50次的区别恰恰是创建线程池的原因,而不是每个过程都有一个新线程。
系统线程上下文切换的损失
在前面的两个测试中,线程之间的控制传递是完全受控的-我们清楚地了解了应该在哪里发生过渡。 但是,经常会发生系统本身从一个线程切换到另一个线程的情况。 当我们并行运行的任务多于设备内核时,操作系统必须能够切换自身以为每个人提供处理器时间。
在此测试中,我想衡量启动太多线程的损失。 为此,创建了一个由16个线程组成的池,每个线程都等待一个信号量,并在接收到信号后立即执行特定的过程并向该信号量发信号。 主线程启动整个池,给出16个信号,然后等待16个信号作为响应。
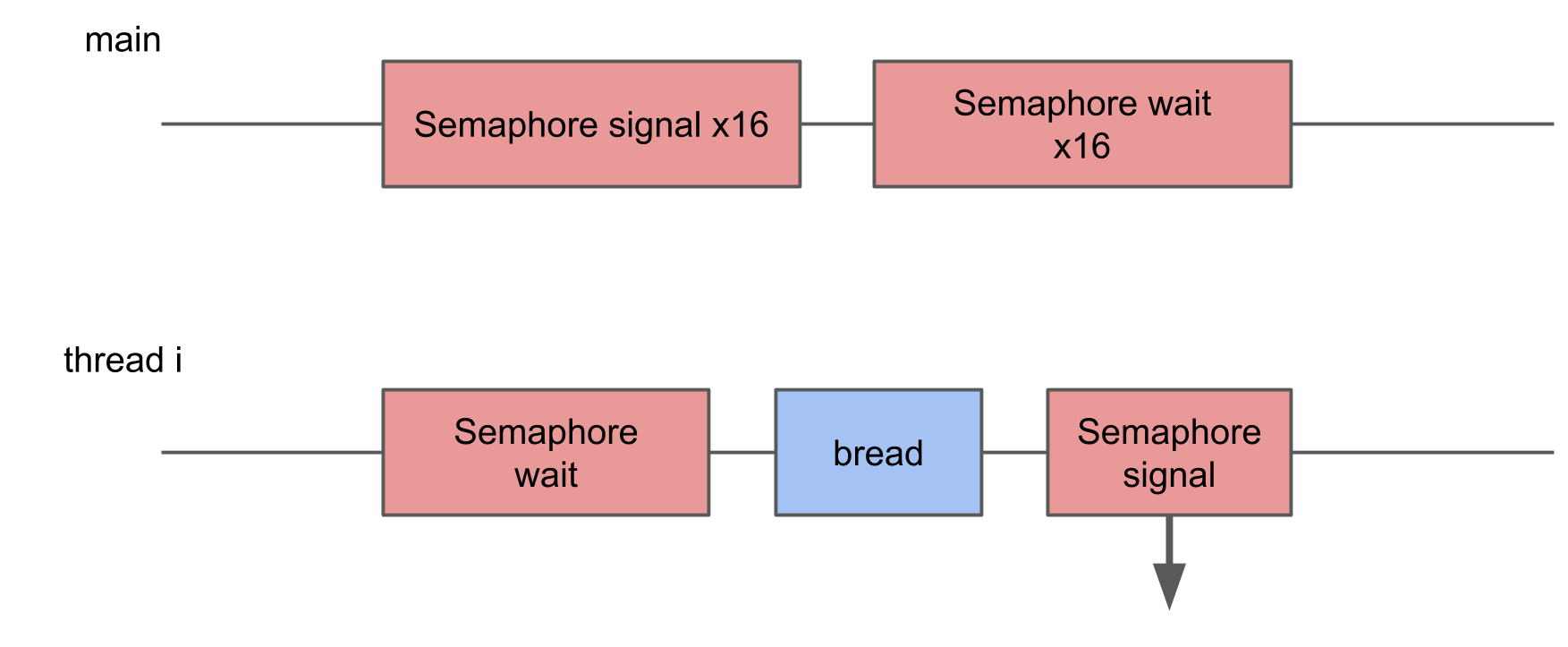
在系统跟踪中,您可以看到这些块是随机分散的,其中一些块的长度比其余块长得多。 如果多次切换导致操作的执行时间增加,那么平均执行时间将因此增加。
但是,随着线程数的增加,平均操作时间不会增加。理论上,只要负载对应于处理能力,就应保持平均时间。 即,任务数量对应于核心数量。
如果并行运行许多任务,则OS从一项任务切换到另一项任务将引入更多延迟。 这应该反映在结果中。
实际上,不仅我们的应用程序可以在设备上运行,而且仍然具有许多并行和系统进程。 即使是我们应用程序中的唯一线程也将受到切换的影响,这会导致中断和延迟。 因此,在所有情况下都存在延迟,并且是串行构建任务还是并行运行任务都没有区别。

以下是我们的延迟编号表,其中包含有关流和信号量的数据。
| L1 | L2 | 记忆体 | 信号量 |
| 延迟数 | 1纳秒 | 7 ns | 100毫微秒 | 25 ns |
| iPhone 5s | 7 ns | 30纳秒 | 240毫微秒 | 8微秒 |
| iPhone 6s Plus | 5纳秒 | 12纳秒 | 200纳秒 | 5微秒 |
| iPhone X | 2纳秒 | 12纳秒 | 146 ns | 3.2微秒 |
档案费用
我们已经有内存和线程-为了完整起见,我们只需要文件系统操作。
读取档案
第一个测试是
读取速度 -读取文件要花多少钱。 该测试包括两个部分。 首先,我们
在考虑文件打开,读取和关闭的情况下
测量读取速度 。 在第二个
例子中 ,我们
假设文件一直处于打开状态 :我们将自己放置在某个地方并读取所需的内容。
从两个角度正确查看了结果。
当文件较小时 ,从文件中读取数据的时间最少。 最长1 KB为5.3微秒-没关系:1字节,2或1 KB-整个5.3μs。 因此,您只能在文件较大的情况下谈论速度,而固定时间已经可以忽略。 对于任何文件大小,打开和关闭文件的操作大约需要相同的时间-在5S的情况下,大约需要50微秒。
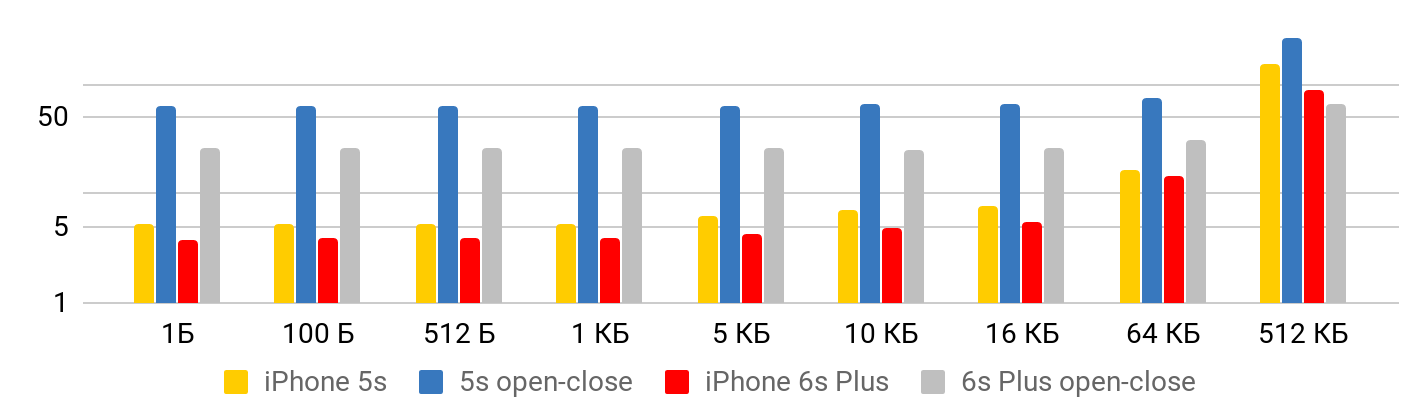
为了读取速度,获得了这样的图。
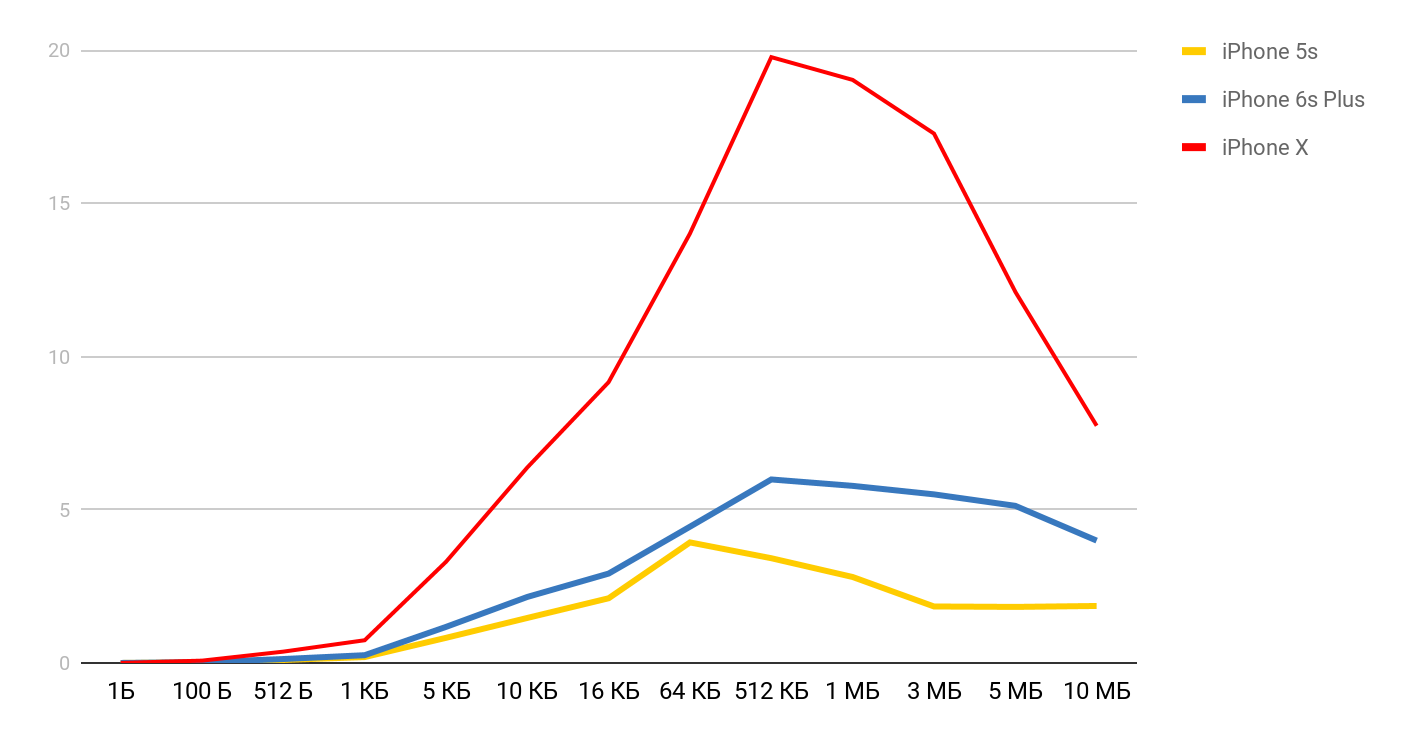
对于iPhone X和1 MB的文件,速度可以达到20 MB / s。 有趣的是,读取1 MB的文件效率更高。 对于大文件,缓存大小似乎会受到影响。 这就是为什么速度会进一步下降并在10 Mb的范围内保持均匀的原因。
创建和删除文件
该测试包括以下步骤:
创建文件并写入数据 ,然后
删除创建的文件。 结果是逐步的:在小尺寸上,时间稳定-大约7μs,并且还会进一步增长。 比例是对数的。
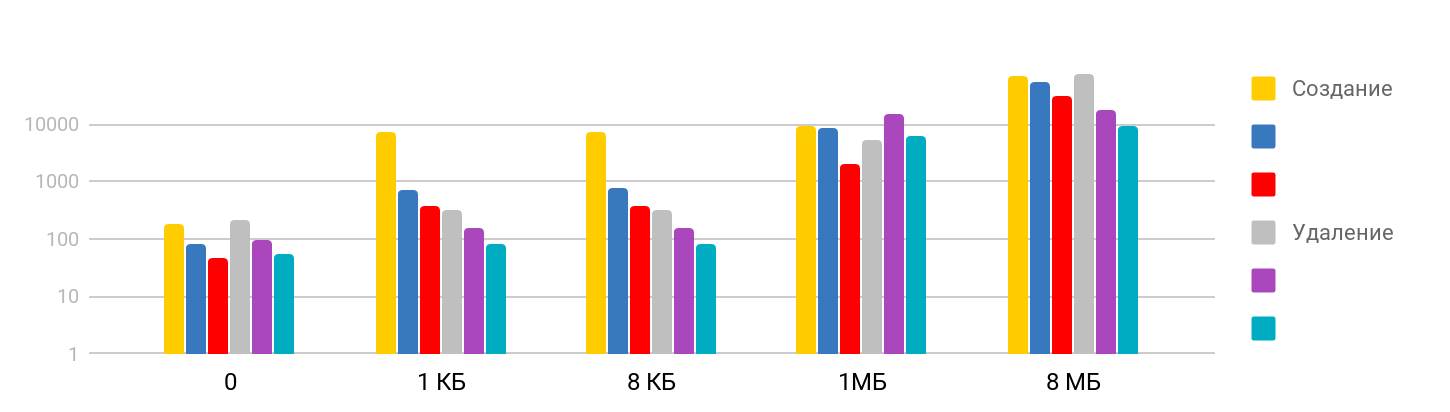
令我惊讶的是,删除大文件所需的时间与创建时间相当,因为我认为删除是一种快速的操作。 事实证明,对于iPhone而言,及时删除与创建文件相当。 摘要表如下所示。
| L1 | L2 | 记忆体 | 信号量 | 磁碟 |
| 延迟数 | 1纳秒 | 7 ns | 100毫微秒 | 25 ns | 150微秒 |
| iPhone 5s | 7 ns | 30纳秒 | 240毫微秒 | 8微秒 | 5微秒 |
| iPhone 6s Plus | 5纳秒 | 12纳秒 | 200纳秒 | 5微秒 | 4微秒 |
| iPhone X | 2纳秒 | 12纳秒 | 146 ns | 3.2微秒 | 1.3微秒 |
结论
根据这些测量,我们现在对基本的iOS操作需要多少时间有了一个想法:访问内存为纳秒,处理文件的时间为微秒,创建流的时间为数十微秒,而切换仅为几微秒。
要使应用程序真正挂起,程序的执行时间必须超过15毫秒(以60fps的速度更新屏幕所花费的时间)。 这几乎是本文中进行的大多数测量的一千倍。 在这样的规模上,毫秒是相当大的,一秒已经是“永远”。
测试表明,尽管访问内存和缓存的时间差异很大,但是直接使用此比率还是很困难的。 在根据L1编译所有数据之前,需要确保您的情况确实能得到结果。
根据使用线程进行的操作测试,我们能够确保创建和销毁线程需要大量时间,但是执行大量并行操作不会带来额外的成本。
好吧,总而言之,我想提醒您在进行性能
测试时最重要的规则-
首先进行测量,然后进行优化 !
GitHub上的简介发言人Dmitry Kurkin。
将AppsConf 2018报告转换和转换为文章的过程与筹备全新的 2019年会议同时进行 。 到目前为止, 已接受报告的列表中只有7个主题,但是此列表将一直扩展,以便于4月22日至23日为移动开发人员举办一个很棒的会议。
关注出版物,订阅youtube频道和新闻通讯 ,这一次很快就会过去。