无人驾驶汽车不能不了解周围的事物以及确切的位置。 去年12月,开发人员Viktor Otliga
vitonka进行了关于在
数据圣诞树上检测3D对象的演示。 Victor在无人驾驶汽车Yandex的指导下工作,在处理交通状况的小组中工作(并在ShAD任教)。 他解释了我们如何解决在三维点云中识别其他道路使用者的问题,此问题与识别图像中的对象有何不同以及如何从共享不同类型的传感器中受益。
大家好! 我叫Victor Otliga,我在明斯克的Yandex办公室工作,我正在开发无人驾驶汽车。 今天,我将讨论无人机的一项相当重要的任务-识别周围的3D对象。

要骑车,您需要了解周围的事物。 我将简要介绍一下无人驾驶车辆上使用的传感器和传感器以及我们使用的传感器。 我将告诉您检测3D对象的任务是什么以及如何测量检测质量。 然后,我将告诉您可以衡量哪些质量。 然后,我将简要回顾一下良好的现代算法,包括我们的解决方案所基于的算法。 最终-小结果,比较了这些算法,包括我们的算法。

这就是我们目前无人驾驶汽车的原型。 在俄罗斯的因诺波利斯以及斯科尔科沃,任何没有驾驶员的人都可以租用这种出租车。 而且,如果您仔细观察,顶部会有一个死角。 里面有什么?

在一组简单的传感器内。 有一个GNSS和GSM天线,可以确定汽车的位置并与外界通信。 那里没有像相机这样的经典传感器。 但是今天,我们将对激光雷达感兴趣。


激光雷达在其周围产生大约这样的点云,它们具有三个坐标。 而且您必须与他们合作。 我将告诉您如何使用相机图像和激光雷达云识别任何物体。
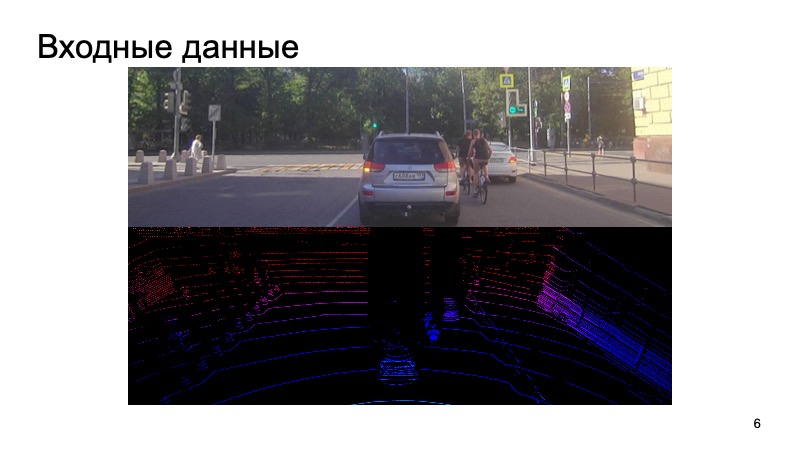
挑战是什么? 来自相机的图像进入输入,相机与激光雷达同步。 一秒钟前使用相机拍摄的图片,从完全不同的时刻拍摄激光雷达云并尝试识别其上的物体,这很奇怪。

我们以某种方式使相机和激光雷达同步,这是一个单独的困难任务,但我们成功地解决了这一难题。 这样的数据输入到输入中,最后我们想要得到限制对象的框,边界框:不仅是行人,骑自行车的人,汽车和其他道路使用者。
任务已设定。 我们将如何评估?

图像中物体的2D识别问题已得到广泛研究。
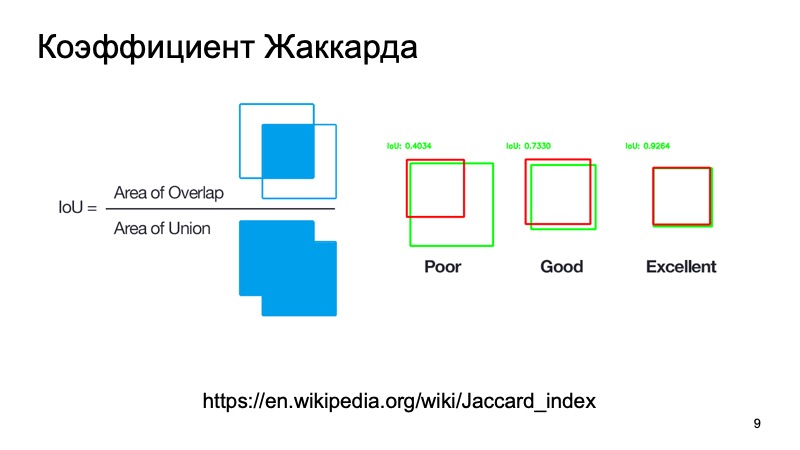
您可以使用标准指标或类似指标。 有一个提花系数或联合上的交点,这是一个奇妙的系数,显示了我们对物体的检测程度。 我们可以假设一个盒子(假设是该对象所在的位置)和一个盒子实际所在的位置。 计算此指标。 有标准阈值-假设对于汽车,它们通常采用0.7的阈值。 如果该值大于0.7,则我们认为我们已经成功检测到该对象,并且该对象在此处。 我们很棒,我们可以走得更远。
另外,为了检测物体并了解它在某处,我们想确定某种程度,即我们确实在该物体上看到了物体,并对其进行了测量。 您可以测量简单,考虑平均精度。 您可以获取精确召回曲线及其下的面积,然后说:它越大越好。
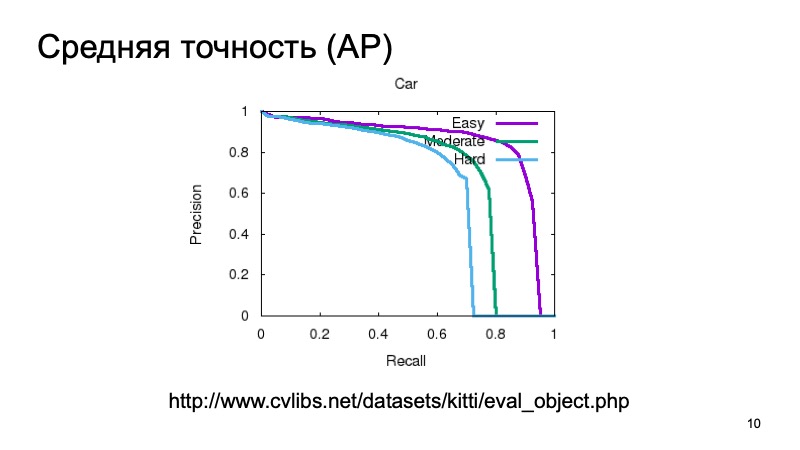
通常,为了测量3D检测的质量,他们会获取数据集并将其分为几个部分,因为对象可能更近或更远,它们可能会被其他物体部分遮盖。 因此,验证样本通常分为三个部分。 容易检测,中等复杂,复杂,遥远或被严重遮挡的对象。 它们分三部分进行测量。 在比较结果中,我们还将采用这种划分。
您可以像在3D中那样测量质量,3D是联合的交集的模拟,但不是面积比,而是例如体积。 但通常来说,无人驾驶汽车并不真正在意Z坐标中发生的事情。我们可以从上方鸟瞰并采取某种度量标准,就像我们在2D模式中观看一样。 人或多或少地以2D导航,无人驾驶的车辆是相同的。 盒子有多高不是很重要。

要测量什么?

大概每个至少以某种方式面临着通过激光雷达云进行3D检测的任务的人都听说过诸如KITTI这样的数据集。

在德国的一些城市,记录了一个数据集,一辆装有传感器的汽车开了,它装有GPS传感器,摄像头和激光雷达。 然后将其标记为8000个场景,并分为两个部分。 一部分是培训,每个人都可以在上面进行培训,第二部分是验证,以便衡量结果。 KITTI验证样本被视为一种质量度量。 首先,KITTI数据集站点上有一个排行榜,您可以将您的决定发送到那里,将结果发送到验证数据集,并与其他市场参与者或研究人员的决定进行比较。 但是,该数据集也可以公开获得,您可以下载而不告诉任何人,自己检查一下,与竞争对手进行比较,但不要公开上传。

外部数据集很好,您不必花费时间和资源,但通常,到德国旅行的汽车可以配备完全不同的传感器。 拥有自己的内部数据集总是一件好事。 此外,以其他人为代价扩展外部数据集比较困难,但管理自己的数据集则更容易。 因此,我们使用了出色的Yandex.Tolok服务。

我们完成了特殊任务系统。 对于想要帮助标记并为此获得奖励的用户,我们从照相机中发出图片,发出可以旋转,放大,缩小的激光雷达云,并请他放置限制我们边界框的框,以便汽车或行人进入其中或其他内容。 因此,我们收集内部采样供个人使用。
假设我们已经决定要解决的任务,如何假设我们做的好坏。 我们将数据收集到某处。
有哪些算法? 让我们从2D开始。 二维检测的任务是众所周知的,并且已经得到研究。
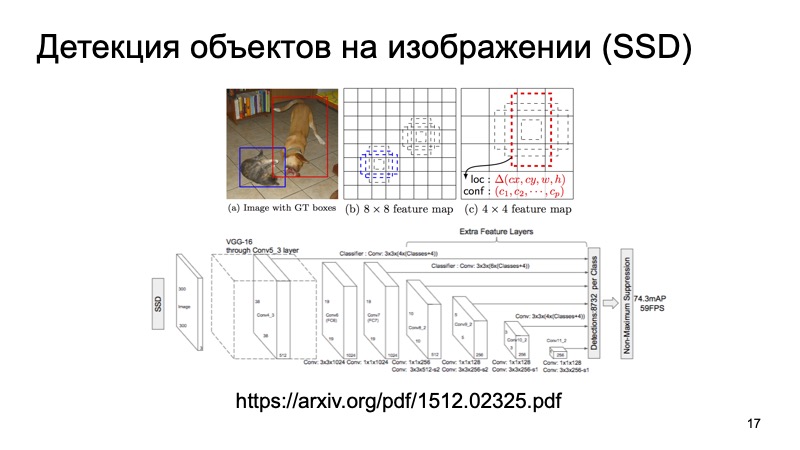
当然,很多人都知道SSD算法,它是检测2D对象的最先进方法之一,原则上,我们可以假定以某种方式可以很好地解决检测图像中对象的问题。 如果有的话,我们可以将这些结果用作某种附加信息。
但是我们的激光雷达云有其自身的特征,可将其与图像区分开来。 首先,它非常稀疏。 如果图片是密集的结构,像素是紧密的,一切都是密集的,那么云很薄,没有太多的点,并且没有规则的结构。 从物理上来说,附近的点远比距离远。要走的越远,点越少,精度越低,确定某件事越困难。
好吧,从原则上讲,来自云的观点是一种难以理解的顺序。 没有人能保证一个点总是比另一个点早。 它们以相对随机的顺序出现。 您可以以某种方式同意对其进行排序或对其进行预先排序,然后才将模型提交给输入,但这将非常不便,您需要花费时间来更改它们,依此类推。
我们想提出一个对我们的问题不变的系统,它将解决所有这些问题。 幸运的是,去年CVPR提出了这样一个系统。 曾经有过这样的架构-PointNet。 她如何工作?

由n个点组成的云到达入口,每个点具有三个坐标。 然后,通过特殊的小变换以某种方式将每个点标准化。 此外,它是通过完全连接的网络来驱动的,以便通过符号来丰富这些点。 然后再次进行转换,最后进行额外的充实。 在某个点上可以获得n个点,但是每个点都有大约1024个特征,它们以某种方式进行了标准化。 但是到目前为止,我们还没有解决关于位移,转弯等不变性的问题。 在这里,建议进行最大池化,在每个通道上的点之间取最大值,并获得1024个符号的向量,这将是我们云的某些描述符,其中将包含有关整个云的信息。 然后,使用此描述符,您可以执行许多不同的操作。
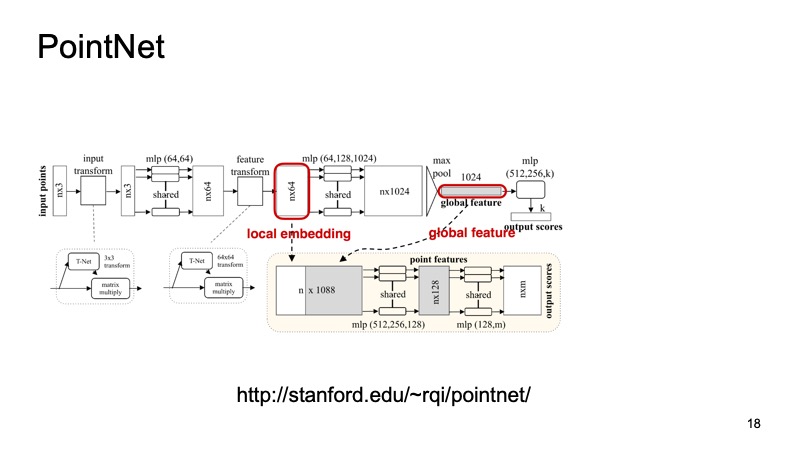
例如,您可以将其粘贴到各个点的描述符并解决分割问题,从而确定每个点所属的对象。 它只是道路,人或汽车。 这是文章的结果。

您可能会注意到,该算法非常出色。 特别是,我真的很喜欢那个小桌子,上面丢了一些有关工作台面的数据,尽管如此,他还是决定了支脚在哪里以及工作台面在哪里。 而且,该算法尤其可用作构建其他系统的模块。
使用此方法的一种方法是Frustum PointNets方法或截断的金字塔方法。 这个想法是这样的:让我们识别2D对象,我们擅长这样做。
然后,知道了相机的工作原理,我们就可以估计机器感兴趣的对象可能位于哪个区域。 要进行投影,只切出该区域,并已经在其上解决了寻找有趣物体(例如机器)的问题。 这比在云中查找任意数量的汽车要容易得多。 完全在同一云中搜索一辆汽车似乎更清晰,更高效。
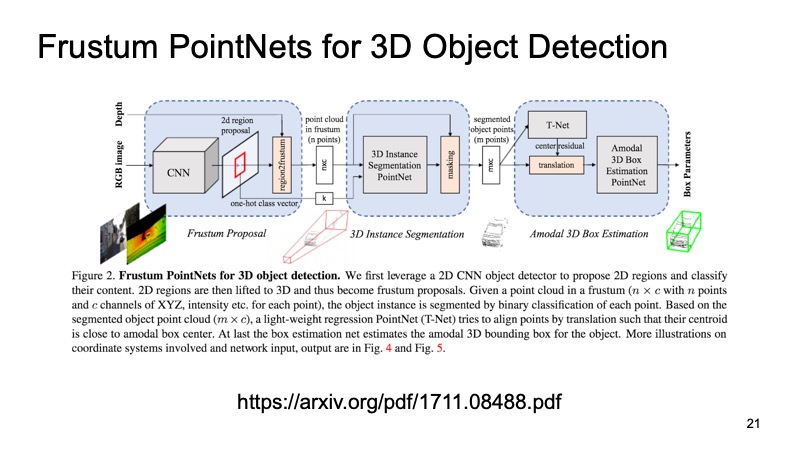
该架构看起来像这样。 首先,我们以某种方式选择我们感兴趣的区域,在每个区域中进行分割,然后解决找到边界框限制我们感兴趣的对象的问题。

该方法已经证明了自己。 在图片中,您可以看到它运行良好,但是也有缺点。 该方法分为两层,因此可能很慢。 我们需要首先应用网络并识别2D对象,然后进行切割,然后解决边界盒在一块云上的分割和分配问题,因此它的工作速度可能会有些慢。
另一种方法。 我们为什么不将云变成某种看起来像图片的结构? 想法是这样的:让我们从上方看一下并采样我们的激光雷达云。 我们得到了立方体的空间。
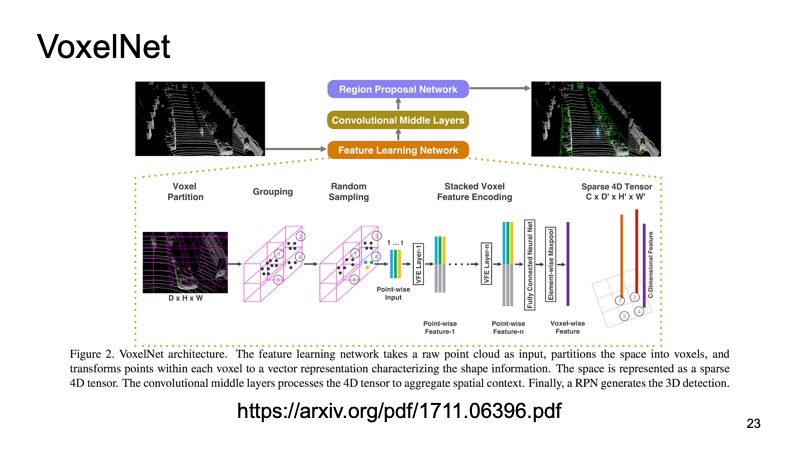
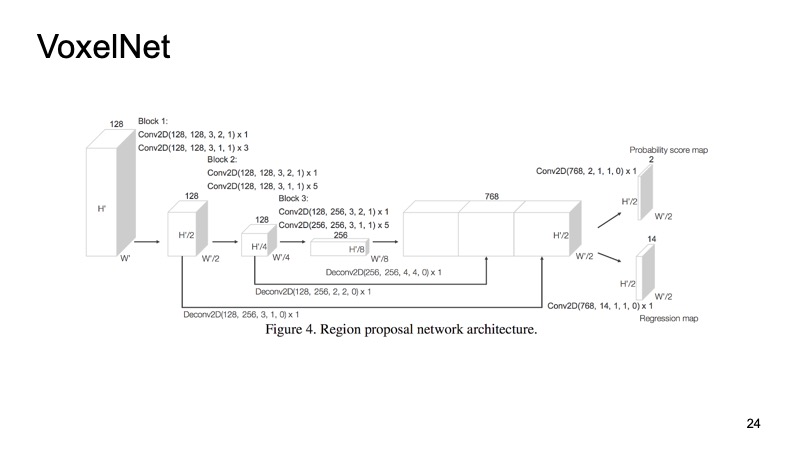
在每个立方体内,我们都有一些要点。 我们可以对它们进行一些计数,但是我们可以使用PointNet,对于每个空间,PointNet都会计数某种描述符。 我们将得到一个体素,每个体素都有一个特征描述,并且它或多或少看起来像一个密集的结构,如图片。 我们已经可以建立不同的架构,例如用于检测对象的类似SSD的架构。
后一种方法是组合来自多个传感器的数据的最早方法之一。 当我们也有相机数据时,仅使用激光雷达数据将是一个罪过。 这些方法之一称为多视图3D对象检测网络。 他的想法是:将三个输入数据通道馈送到大型网络的输入。
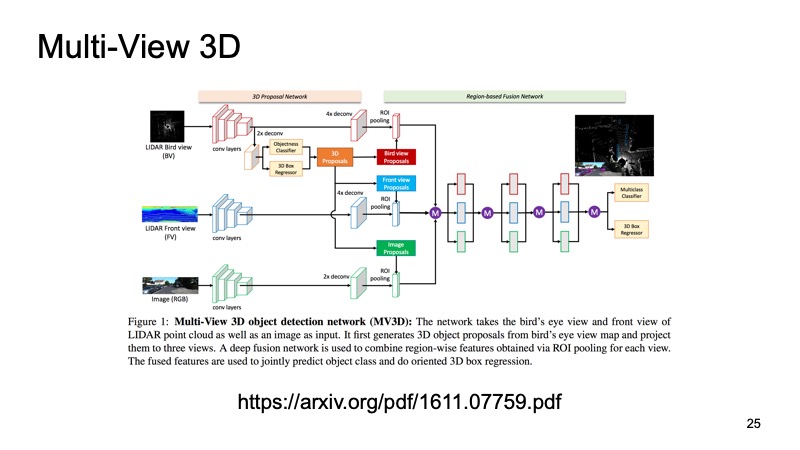
这是从相机拍摄的图片,有两种版本,分别是激光雷达云:从上方俯瞰的鸟瞰图和某种正视图,即我们眼前的景象。 我们将其提交给神经元的输入,它将配置其内部的所有内容,从而为我们提供最终结果-对象。
我想比较这些模型。 在KITTI数据集上,在验证驱动器上,质量以平均精度的百分比进行评估。
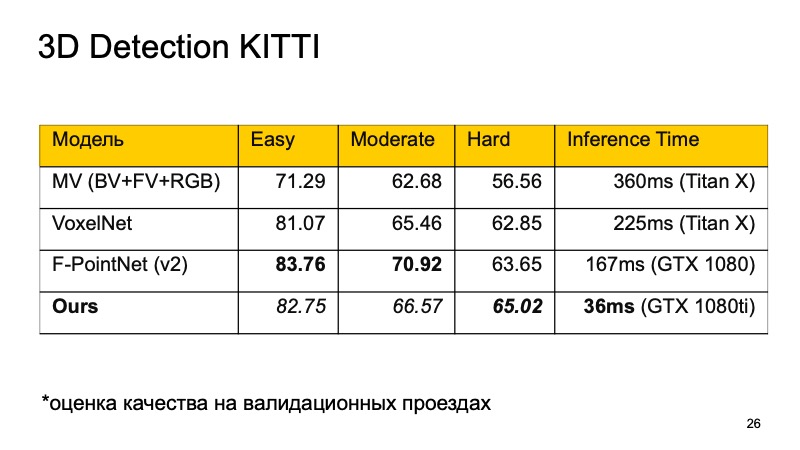
您可能会注意到,F-PointNet运行得很好且足够快,至少在作者看来,它击败了不同领域的其他所有人。
我们的方法或多或少地基于我列出的所有想法。 如果进行比较,您将得到以下图片。 如果我们没有占据第一的位置,那么至少是第二。 此外,在那些难以发现的物体上,我们突围而出。 最重要的是,我们的方法足够快。 这意味着它已经非常适用于实时系统,对于无人驾驶车辆监视道路上正在发生的事情并突出显示所有这些对象尤其重要。

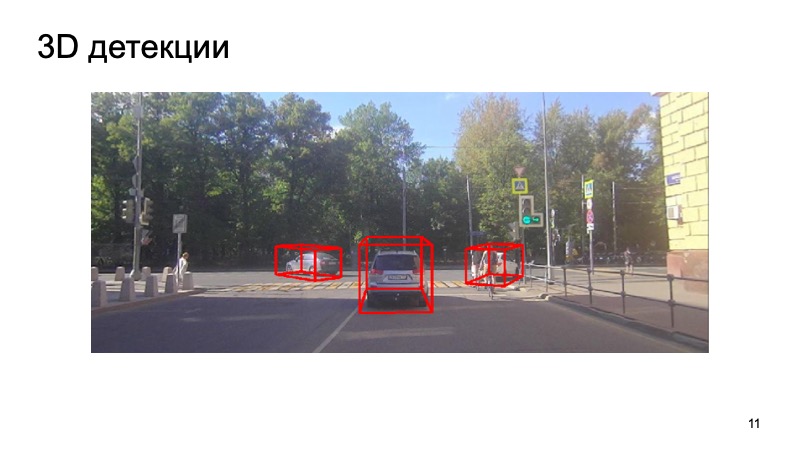
最后-我们的检测器示例:
可以看出情况很复杂:有些对象是关闭的,有些是相机看不到的。 行人,骑自行车的人。 但是探测器足够应付。 谢谢你