
改善操作系统性能和发现瓶颈的话题正变得越来越流行。 在本文中,我们将讨论一种工具,该工具使用Linux中的块堆栈示例以及一种对主机进行故障排除的案例来查找这些位置。
例子1.测试
没用
我们部门的测试是对产品硬件进行综合测试,之后进行应用软件测试。 我们收到了英特尔傲腾硬盘进行测试。 我们已经
在博客中写了关于测试Optane驱动器
的信息 。
磁盘安装在一个标准项目服务器中,该标准服务器在一个云项目中构建了相对较长的时间。
在测试过程中,磁盘表现出的并不是最佳状态:在测试过程中,每1个流的队列深度为1个请求,以4KB的块为单位,大约为70Kiops。 这意味着响应时间非常长:每个请求大约13微秒!
奇怪的是,由于该
规范承诺“等待时间-读取10 µs”,而我们又得到了30%的收益,两者之间的差异非常大。 磁盘被重新布置到另一个平台,另一个项目中使用了更“新鲜”的组件。
为什么行得通?
这很有趣,但是新平台上的驱动器可以正常工作。 性能提高,延迟减少,每个机架的CPU,每个请求1个流,4K字节块,每个请求约9微秒的〜106Kiops。
然后该是
比较设置以从宽
腿获得性能的时候了。 毕竟,我们想知道为什么会这样吗? 使用性能
,您可以:
- 以硬件计数器读数为例:指令调用的次数,高速缓存未命中,错误地预测了分支等。 (PMU事件)
- 从静态交易点中删除信息,出现次数
- 进行动态跟踪
为了进行验证,我们使用了CPU采样。
最重要的是,
perf可以编译正在运行的程序的整个堆栈跟踪。 自然,运行
perf将导致整个系统运行的延迟。 但是我们有标志
-F# ,其中
#是采样频率,以Hz为单位。
重要的是要了解,采样频率越高,捕获特定功能调用的可能性就越大,但探查器带给系统的制动就越多。 频率越低,我们看不到堆栈的一部分的机会就越大。
选择频率时,需要以常识和一个技巧为指导-尽量不要设置一个偶数频率,以免出现某些以该频率在计时器上运行的工作进入样本的情况。
最初会引起误解的另一点是-如果可能的话,应该使用标志
-fno-omit-frame-pointer编译软件。 否则,在跟踪中,我们将看到可靠的
未知值,而不是函数名。 对于某些软件,调试符号作为单独的软件包提供,例如
someutil-dbg 。 建议您在运行
perf之前安装它们。
我们执行了以下操作:
- 取自git://git.kernel.dk/fio.git,标记为fio-3.9
- 在Makefile中的CPPFLAGS中添加了-fno-omit-frame-pointer选项
- 启动了make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
需要使用-g选项来捕获跟踪堆栈。
您可以通过以下命令查看结果:
perf report -g fractal
需要使用
-g fractal选项,以便以百分比表示反映此函数的样本数量并以
perf表示的百分比相对于调用函数,该函数的调用次数为100%。
在“新构建”平台上的长fio调用堆栈即将结束时,我们将看到:
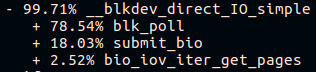
在“旧版本”平台上:

太好了! 但是我想要美丽的弗拉格里夫。
建筑火焰图
为了美观,有两种工具:
这些实用程序接受
perf脚本>结果作为输入。
下载
结果并通过管道将其发送到
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
在浏览器中打开并欣赏可点击的图片。
您可以使用另一种方法:
- 将结果添加到Flamescope /示例/
- 运行python ./run.py
- 我们通过浏览器进入本地主机的5000端口
我们到底看到了什么?
优秀的员工在
轮询中花费大量时间:
糟糕的Fio会花时间在任何地方,但不会花在轮询上:
乍一看,轮询似乎无法在旧主机上进行,但在所有4.15内核具有相同程序集的情况下,默认情况下会在NVMe磁盘上启用轮询。 检查是否在
sysfs中启用了轮询:
在测试期间,将使用带有
RWF_HIPRI标志的
preadv2调用-轮询工作的必要条件。 而且,如果您仔细研究火焰图(或
perf报告输出中的上一个屏幕截图),则可以找到它,但是它花费的时间非常少。
可见的第二件事是submit_bio()函数的调用堆栈不同,并且缺少io_schedule()调用。 让我们仔细看一下Submit_bio()内部的区别。
缓慢的平台“旧版本”:
快速平台“新鲜”:
看来,在缓慢的平台上,请求对设备的处理很长,同时进入了
kyber调度程序 。 您可以在
我们的文章中阅读有关I / O调度程序的更多信息。
一旦关闭了
kyber ,相同的fio测试显示平均延迟约为10微秒,正如规范中所述。 太好了!
但是,另一微秒的差异是从哪里来的呢?
如果更深一点?
如前所述,
perf允许您从硬件计数器收集统计信息。 让我们尝试查看每个周期的缓存未命中数和指令:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


从结果可以看出,一个快速的平台在CPU周期内执行更多的指令,并且在执行期间的缓存未命中率更低。 当然,我们不会在本文的框架中详细介绍不同硬件平台的操作。
例子2.杂货
出问题了
在分布式数据存储系统的工作中,观察到主机之一上CPU的负载增加,而传入流量增加。 主机是对等体,具有相同的硬件和软件。
让我们看一下CPU负载:
~
问题出现在09:23:46,我们看到该进程在内核空间中仅工作了整整一秒钟。 让我们看看里面发生了什么。
为什么这么慢?
在这种情况下,我们从整个系统中取样:
perf record -a -g -- sleep 22 perf script > perf.results
这里需要
-a选项以使
perf从所有CPU中删除跟踪。
使用
Flamescope打开
perf.results来跟踪CPU负载增加的时刻。
在我们面前的是“热图”,其两个轴(X和Y)都表示时间。
在X轴上,空间分为几秒钟,在Y轴上,空间在X秒内分为20毫秒,时间从下到上,从左到右。 最亮的正方形具有最大数量的样本。 即,此时的CPU工作最活跃。
实际上,我们对中间的红色斑点感兴趣。 用鼠标选择它,单击并查看隐藏的内容:
通常,已经很明显的问题是
tcp_recvmsg和
skb_copy_datagram_iovec运行缓慢。
为了清楚起见,请与其他主机的样本进行比较,在该样本上相同数量的传入流量不会引起问题:
基于这样的事实,即我们有相同数量的传入流量,长时间运行的相同平台而没有停止,因此我们可以假设问题出在铁侧。
skb_copy_datagram_iovec函数将数据从内核结构复制到用户空间中的结构,以传递给应用程序。 主机内存可能有问题。 同时,日志中没有错误。
我们重新启动平台。 加载BIOS时,我们会看到一条有关内存条损坏的消息。 更换后,主机启动,并且不再重现CPU过载的问题。
后记
perf的系统性能
一般而言,在繁忙的系统上,运行性能可能会导致处理请求的延迟。 这些延迟的大小还取决于服务器上的负载。
让我们尝试找出这种延迟:
~
差别不是很明显,只有大约8纳秒。
让我们看看如果增加负载会发生什么:
~
在这里,差异已经变得明显。 可以说,该系统的速度降低了不到1%,但是在负载较重的系统上,基本上损失了大约7Kiops会导致问题。
显然,这个例子是综合性的,尽管如此,它还是很有启发性的。
让我们尝试运行另一个综合测试来计算质数
-sysbench :
~
在这里您可以看到,即使最小处理时间也增加了270微秒。
而不是结论
Perf是用于分析系统性能和调试的非常强大的工具。 但是,与其他任何工具一样,您需要控制自己,并记住在受到密切监视的情况下,任何已加载系统的工作情况都更糟。
相关链接: