这是本文的第一部分,我将在其中讨论如何构建大型数据库迁移项目的工作流程:安全实验,团队计划和跨团队交互。 在以下文章中,我将详细讨论我们解决的技术问题:有关PostgreSQL的伸缩性和容错性以及负载测试。
长期以来,Miro(前RealtimeBoard)中的主要数据库是Redis。 我们在其中存储了所有基本信息:有关用户,帐户,董事会等的数据。 一切工作都很快,但是我们遇到了许多问题。
Redis的问题- 取决于网络延迟。 现在,在我们的云中,莫斯科时间约为20,但是当您增加它时,该应用程序将开始运行非常缓慢。
- 缺乏业务逻辑级别上的索引。 它们的独立实现可能会使业务逻辑复杂化,并导致数据不一致。
- 代码复杂性也使维护数据一致性变得困难。
- 带选择的查询的资源强度。
这些问题以及服务器上的数据量增加导致数据库迁移。
问题陈述
关于迁移的决定已经做出。 下一步是了解哪个数据库适合我们的数据模型。
我们进行了一项研究,为我们选择了最佳数据库,并选择了PostgreSQL。 我们的数据模型非常适合关系数据库:PostgreSQL具有内置工具来确保数据一致性,JSONB类型和对JSONB中的某些字段建立索引的能力。 它适合我们。
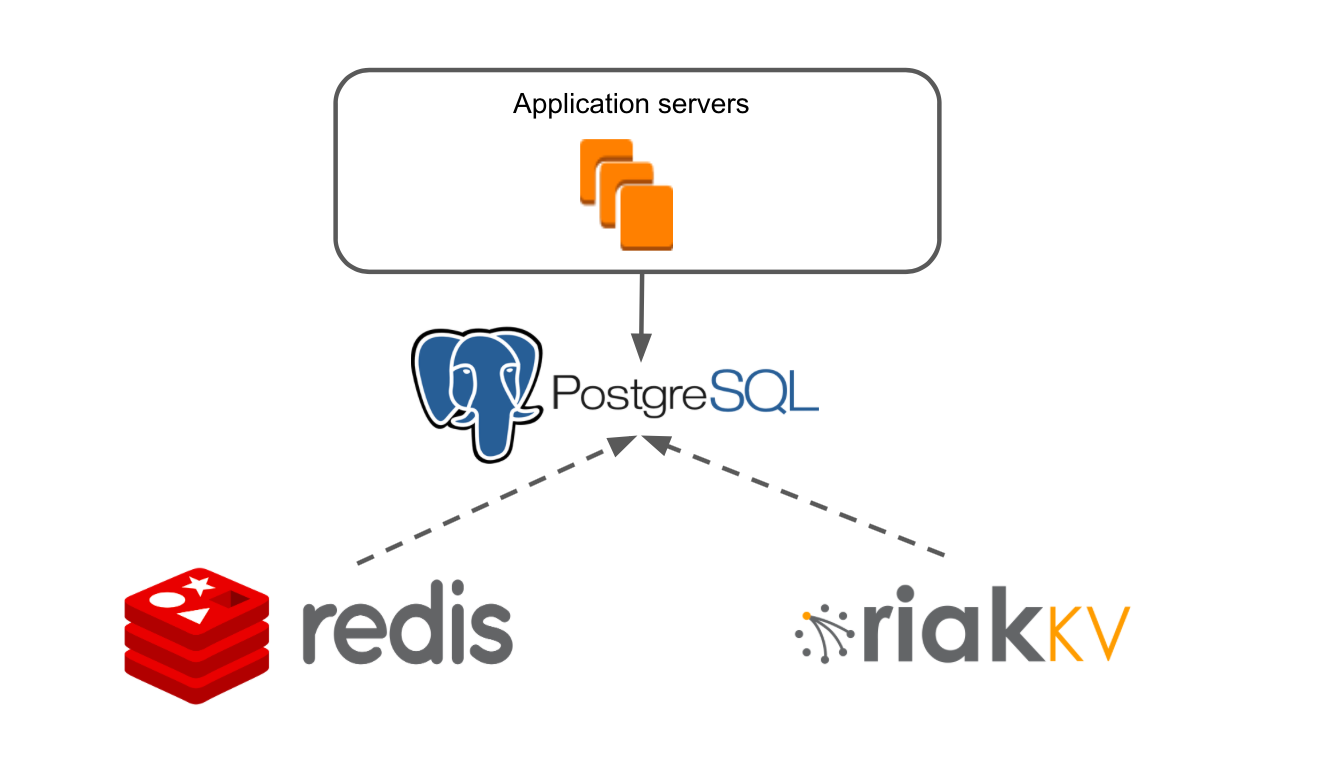
我们的应用程序的简化架构如下所示:有些应用程序服务器通过数据层访问Redis和RiakKV。
我们的应用程序服务器是整体Java应用程序。 业务逻辑是在适用于NoSQL的框架中编写的。 该应用程序具有其自己的交易系统,该系统使您可以在我们的任何板上提供多个用户。
我们使用RiakKV存储了7天未打开的档案板上的数据。
将PostgreSQL添加到该架构。 我们使Application Server与新数据库一起使用。 将数据从Redis和RiakKV复制到PostgreSQL。 问题解决了!
没什么复杂的,但有细微差别:- 我们有220万注册用户。 每天,Miro雇用5万名用户,峰值负载一次高达1.4万。 用户不应因我们的工作而遇到错误,他们通常不应该注意到转移到新基地的时刻。
- 数据库中1 TB的数据或4.1亿个对象。
- 其他团队不断发布新功能,我们不应干涉他们的工作。
解决问题的选项
我们面临着两种数据迁移选择:
- 停止服务的开发→在服务器上重写代码→测试功能→启动新版本。
- 执行平稳的迁移:逐步将产品的某些部分转移到新数据库中,同时支持PostgreSQL和Redis,并且不中断新功能的开发。
停止服务的开发是我们可以用来增长的时间的损失,这意味着用户和市场份额的损失。 这对我们至关重要,因此我们选择了平滑迁移的选项。 尽管存在复杂性的事实,但可以将此过程与驾驶时更换汽车上的车轮相提并论。
在评估工作时,我们将产品划分为几个主要部分:用户,帐户,董事会等。 另外,还进行了创建PostgreSQL基础结构的工作。 如果出现问题(发生的方式),他们会在评估中承担风险。
冲刺和目标
下一步是建立一个由五人组成的团队,以使每个人都以正确的速度朝着一个共同的目标迈进。
我们有两点:开始执行任务和最终目标。 当我们以直接的方式实现目标时,这是理想的选择。 但是,经常发生我们想要直截了当的情况,但结果却是这样的:
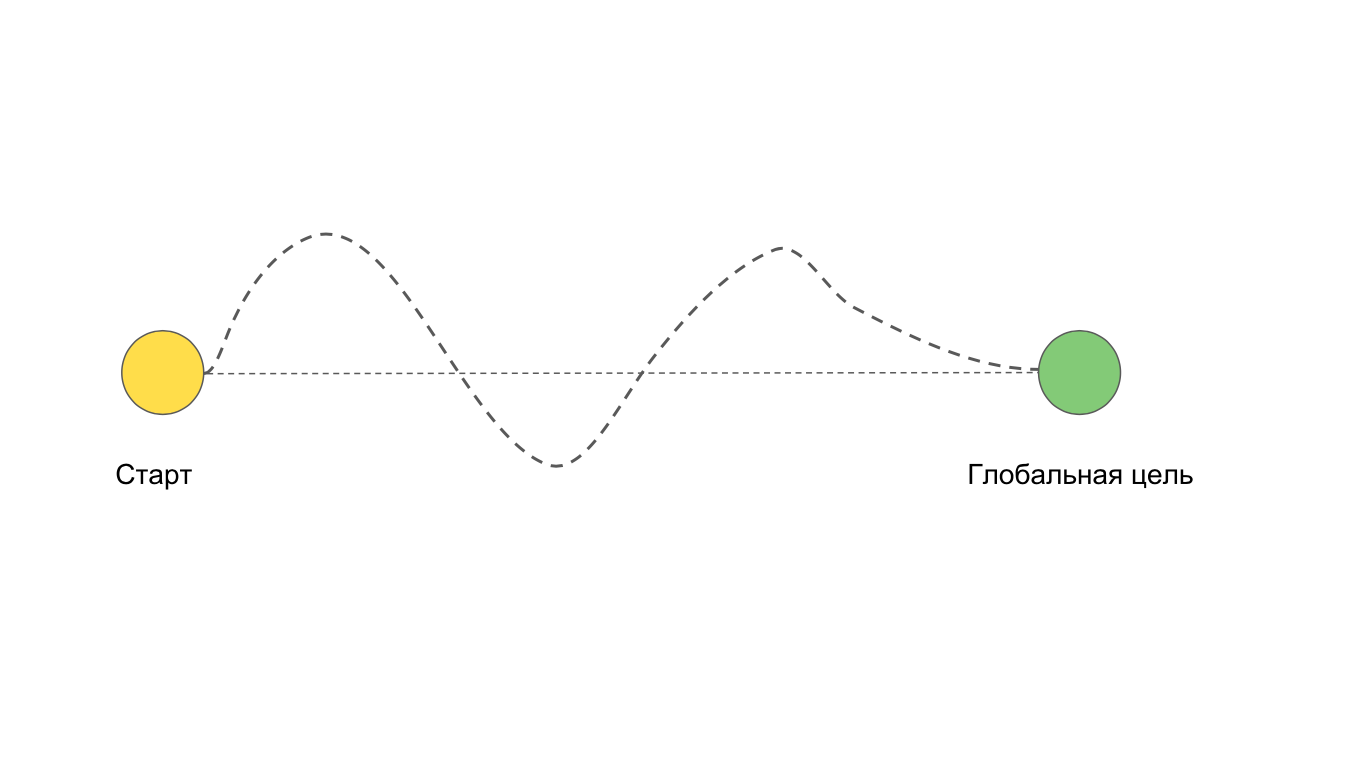
例如,由于困难和问题,无法事先预见。
有可能我们根本达不到目标。 例如,如果我们要进行深度重构或重写整个应用程序。
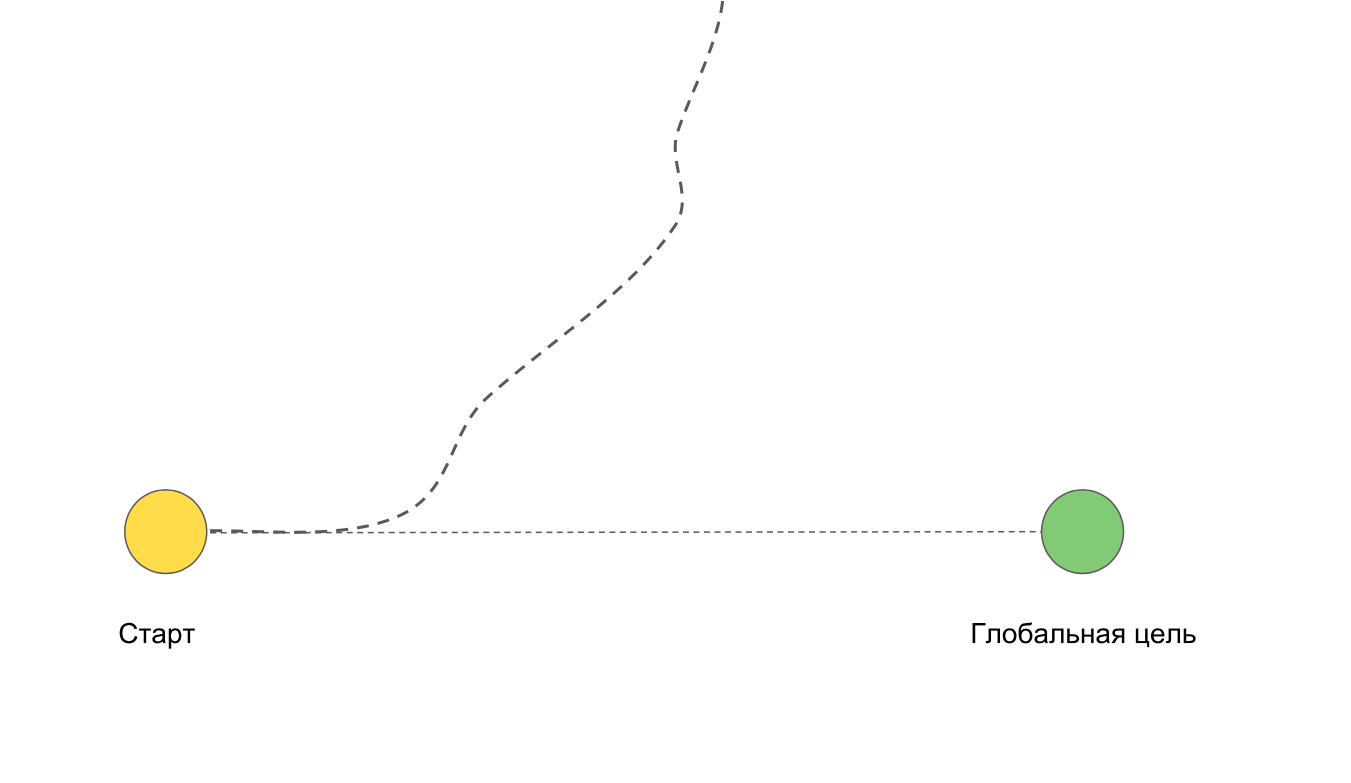
我们将任务分成每周冲刺,以最大程度地减少上述困难。 如果团队突然离开,可以以最小的项目损失迅速返回,因为短暂的迭代不会使您“走错路”。
每次迭代都有其自己的目标,这将使团队达到最终的大结果。

如果在冲刺期间出现新任务,我们将评估其执行是否使我们更接近目标。 是的-进行下一个冲刺或更改当前冲刺的优先级,如果不是,则不要进行。 如果出现错误,我们将给予他们最高优先级并迅速修复它们。
碰巧,冲刺内的开发人员必须按照严格定义的顺序执行任务。 或者,例如,开发人员将完成的任务交给质量检查工程师进行紧急测试。 在计划阶段,我们尝试为每个团队成员在任务之间建立相似的关系。 这使整个团队可以看到谁将在什么时候做什么,而不必忘记对他人的依赖。
团队每天和每周同步。 每天早晨,我们讨论今天将由谁,做什么以及要优先处理的事情。 每次冲刺之后,我们都会相互同步,以确保每个人都朝着正确的方向前进。 确保计划大型或复杂版本。 我们任命值班的开发人员,如果有必要,他们会在发布过程中在场并监视一切正常。
团队内部的计划和同步允许项目所有阶段的所有参与者参与。 计划和评估并非来自我们上方,而是我们自己制定。 这增加了团队完成任务的责任感和兴趣。
这是我们的冲刺之一。 我们将所有东西放在Miro板上:

模式和安全实验
在迁移期间,我们必须保证在战斗条件下该服务的稳定运行。 为此,您需要确保所有内容都经过测试,并且任何地方都没有错误。 为了实现此目标,我们决定使我们的顺利迁移更加顺利。
想法是逐步将产品模块切换到新数据库。 为此,我们提出了一系列模式。
在第一个“ Redis读/写”模式下,仅旧数据库Redis有效。
 在第二种“ PostgreSQL被动写入”模式下,
在第二种“ PostgreSQL被动写入”模式下,我们可以确保对新数据库的写入正确并且数据库是一致的。
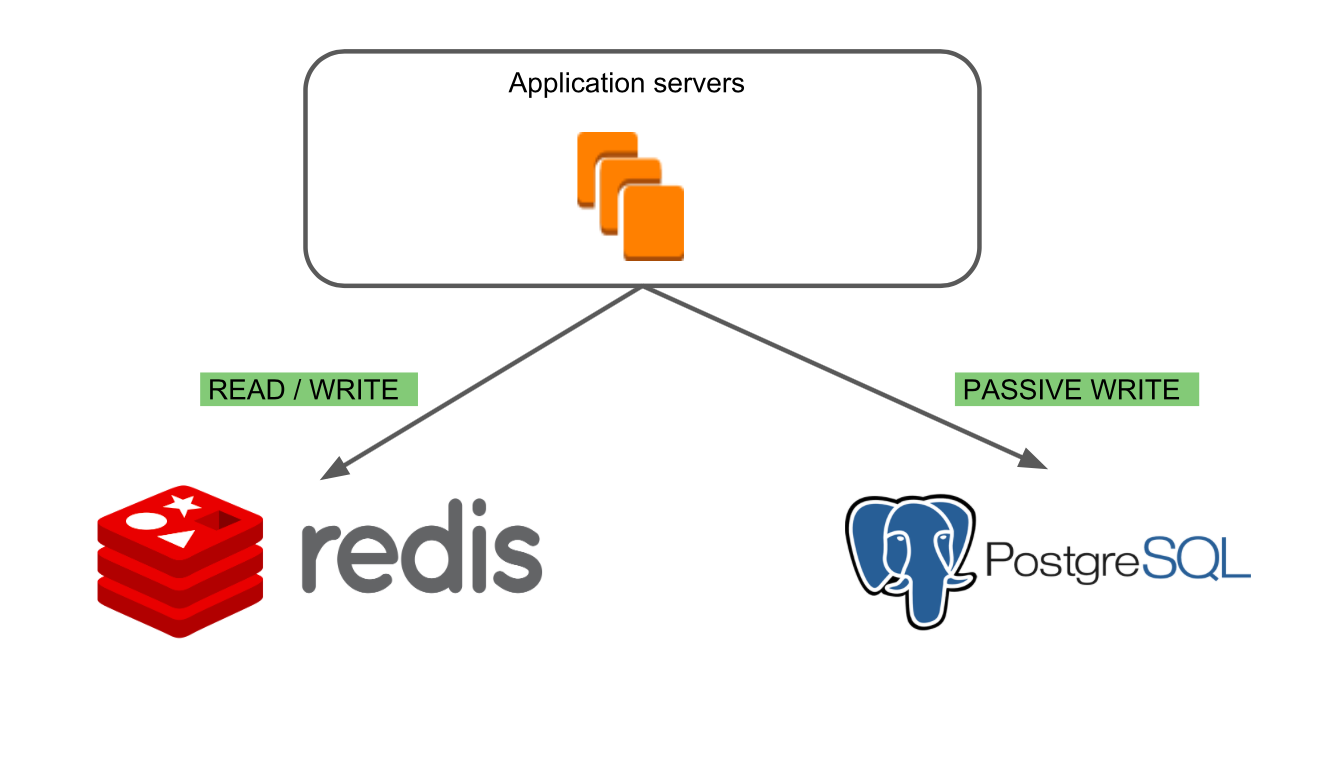 第三种模式“ PostgreSQL读/写,Redis被动写”
第三种模式“ PostgreSQL读/写,Redis被动写”允许您验证从PostgreSQL读取数据的正确性,并查看新数据库在战斗条件下的行为。 同时,Redis仍然是主要基础,这使我们能够找到与董事会合作可能导致错误的具体案例。
 在最后的“ PostgreSQL读/写”模式下,
在最后的“ PostgreSQL读/写”模式下,仅新数据库正在运行。
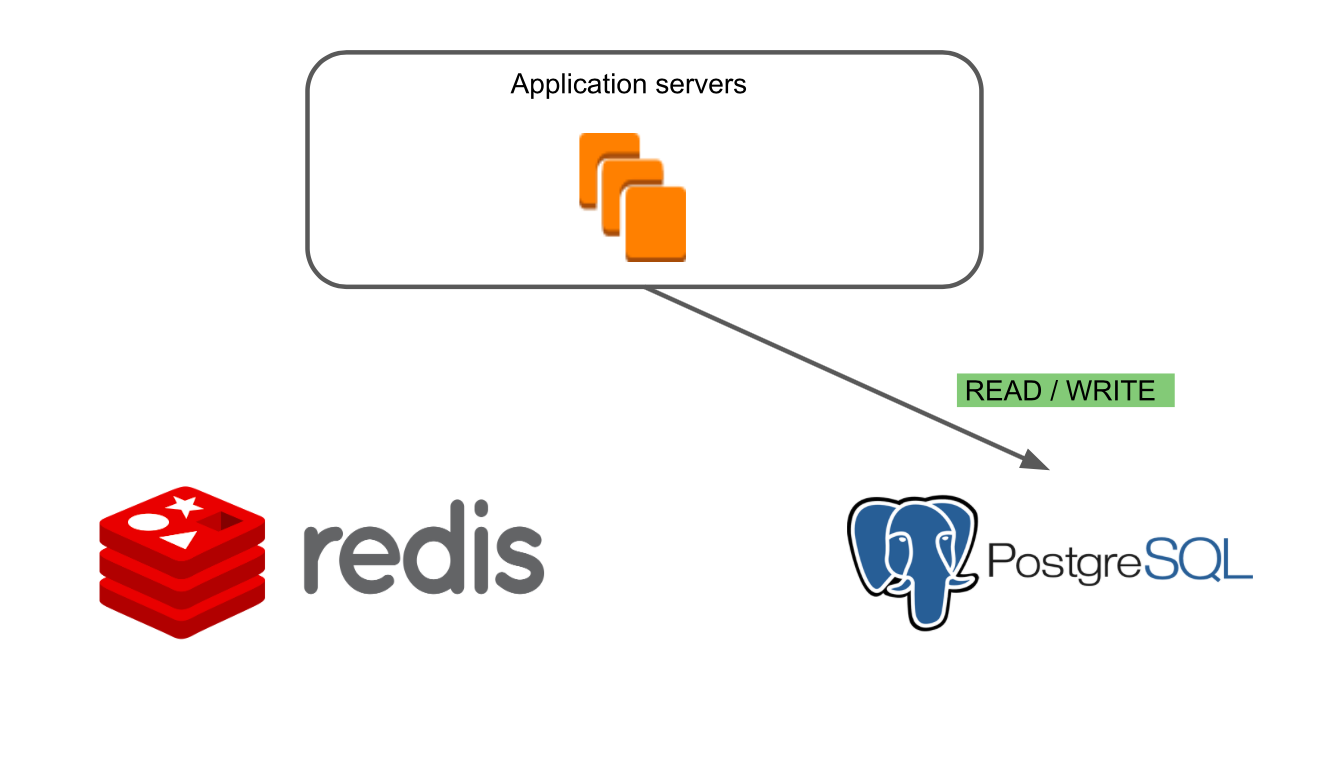
迁移工作可能会影响产品的主要功能,因此我们必须100%确保我们不会破坏任何东西,并且新数据库的运行速度至少与旧数据库一样慢。 因此,我们开始使用切换模式进行安全的实验。
我们开始在公司帐户中切换模式,我们每天在工作中使用该模式。 在确保其中没有错误之后,我们开始在少量外部用户上切换模式。
使用这些模式启动实验的时间表如下:
- 1月至2月:Redis读/写
- 3月至4月:PostgreSQL被动写入
- 5月至6月:PostgreSQL读/写,主数据库-Redis
- 7月至8月:PostgreSQL读/写
- 9月-12月:完全迁移。
如果发生错误,我们就有机会快速修复它们,因为我们自己可以在参与实验的用户工作的服务器上发布版本。 我们不依赖主要版本,因此我们可以随时随地更正错误。
跨团队合作
在迁移期间,我们经常与发布了新功能的团队进行交流。 我们只有一个代码库,作为工作的一部分,团队可以更改新数据库中的现有结构或创建新结构。 同时,开发和撤消新功能的团队可能会交叉。 例如,其中一个产品团队曾答应市场营销团队在特定日期之前发布新功能; 营销团队已计划在此期间进行广告宣传; 销售团队正在等待功能和活动开始与新客户进行沟通。 事实证明,每个人都相互依赖,一个团队延迟最后期限会破坏另一个团队的计划。
为避免这种情况,我们与其他团队一起编制了一个杂货店路线图,该路线图每季度进行几次同步,每周与一些团队进行同步。
结论
我们在这个项目中学到了什么:
- 不要害怕从事复杂的项目。 在分解,评估和开发工作方法之后,复杂的项目似乎不再可行。
- 不要在初步估计,分解和计划上花费时间和精力。 这有助于您在开始解决问题之前更深入地了解问题,并有助于了解工作的数量和复杂性。
- 在困难的技术和组织项目中承担风险。 在工作过程中,您肯定会遇到计划时没有考虑的问题。
- 除非必要,否则不要迁移。
在以下文章中,我将更多地讨论我们在迁移过程中解决的技术问题。