你好!
同事们,在一月的最后一天,我们将启动
“ MS SQL Server开发人员”课程,与此课程相关的是主题公开课。 在会议上,我们讨论了MS SQL Server如何执行SELECT查询,以什么顺序和分析了什么进行了讨论,并且还花了一点时间来阅读查询计划。
讲师
-Kristina Kucherova ,俄罗斯联邦储蓄银行的数据模型架构师。
网络研讨会的目标和途径在网络研讨会开始时设定了以下目标:
- 查看服务器如何执行请求,以及为什么以这种方式发生。
- 学习阅读查询计划。
为了实现这些目标,老师准备了一条简单而有效的方法:
 为什么需要查询计划?
为什么需要查询计划?查询计划是一个非常有用的工具,不幸的是,许多开发人员没有使用它。 乍一看,似乎没有必要了解请求的机制。 但是,如果您了解SQL Server内部的情况,则可以编写更有效的查询。 例如,在优化过程中,它将有很大帮助。
我们如何看到SELECT查询?让我们看看SELECT查询的样子:
选择[field1],[field2] ...
| 我们选择什么领域?
|
来自[表格]
| 从哪里来?
|
[条件]
| 条件在哪里
|
GROUP BY [field1]
| 按字段分组
|
有[条件]
| 有这样的条件
|
ORDER BY [field1]
| 订购(排序)
|
如何理解去哪里找数据?服务器试图了解请求何时到达的第一件事是数据的去向。 FROM命令回答了这个问题,因为在这里我们将有一个表列表(或一个表的名称)。
为了清楚起见,让我们假设我们的服务器是一种管家,我们打算在度假时将其收集给我们。 因此,管家开始思考,但是在什么壁橱里有必要的东西(您需要在哪个表中获取数据)? 为了使我们的管家可以轻松完成他的任务,我们使用FROM。
 如何理解要取什么数据?
如何理解要取什么数据?假设管家找到了正确的橱柜并将其打开。 但是要拿什么呢? 也许我们要去滑雪胜地? 或者也许在炎热的阳光明媚的海滩上? 为了使我们的东西与天气匹配,WHERE命令对我们很有用,它定义了条件,即允许我们过滤数据。 如果天气很热,我们会选择板岩,衬衫和泳装(如果天气很冷,则要戴手套,针织袜,毛衣))。
下一步是将此数据附加到组,这在GROUP BY(分别为T恤衫和袜子)中发生。 根据分组结果,可以使用HAVING施加另一个条件(例如,清除未配对的事物)。 最后,我们使用ORDER BY添加所有内容,在输出中获得完整的手提箱,或者说是有序的数据块。

顺便说一下,这是有细微差别的,但这是因为在WHERE中应规定哪些条件以及HAVING中应规定哪些条件之间存在差异。 但这最好在视频中看到。
我们继续。 请求执行路径
作为请求计划保存在缓存中,也就是说,我们的管家将所有内容写下来,因为他是一个很好的管家-如果您想在明年再次下订单怎么办? 从原则上讲,这样的计划可能很多。
查询计划中的连接类型就查询而言,您可能会遇到三个连接:
- 嵌套循环。
- 合并加入。
- 哈希加入。
在更详细地介绍它们之前,让我们总结一下为什么我们甚至应该阅读查询计划。 这实际上非常有用,因为您将学习:
- 使用哪个索引;
- 以什么顺序加入;
- 从缓冲区选择什么;
- 服务器在操作上花费了多少资源;
- 假设计划和实际计划之间有什么区别?
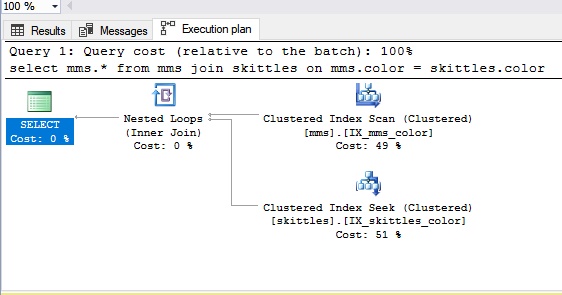
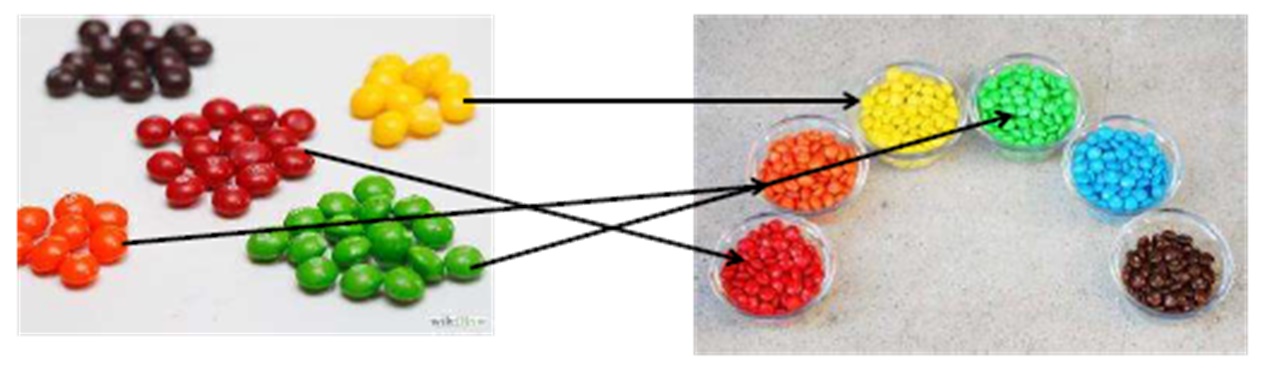
嵌套循环假设我们需要连接来自不同表的数据。 让我们将这些表展示为……少量的Skittles巧克力和M&M的完整包装。

连接嵌套循环类型时,我们先吃Skittles糖果,然后再从M&M的包装中得到盲糖果。 如果我们没有碰到相同颜色的糖果(这是我们的状况),我们会得到下一个糖果,那就是通常的半身像。 结果,我们可以说嵌套循环连接更适合少量数据。 显然,如果有很多数据,那么破坏不是最佳选择。

让我们看看它在SQL面板中的外观:
 合并加入
合并加入连接用于大量数据。 当您有一个合并联接时,两个表都有一个索引,通过它们它们可以被联接。 就糖果而言,就好像我们是按颜色预先安排它们一样。
看起来像这样:

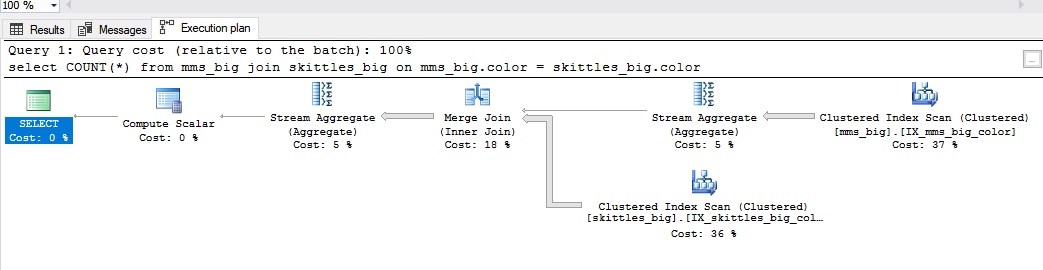
在以下情况下,合并联接是好的:
- 大数据集;
- 相同类型的相同连接字段;
- 连接字段具有索引。
哈希联接哈希联接用于未排序的大量数据。 在这种情况下,要联接表,您需要构建一些类似于索引的东西。
哈希联接示例:
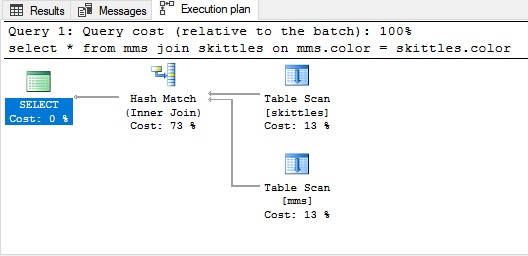
为了清楚起见,我们回顾一下我们的糖果:

使用哈希联接涉及两个阶段的操作:
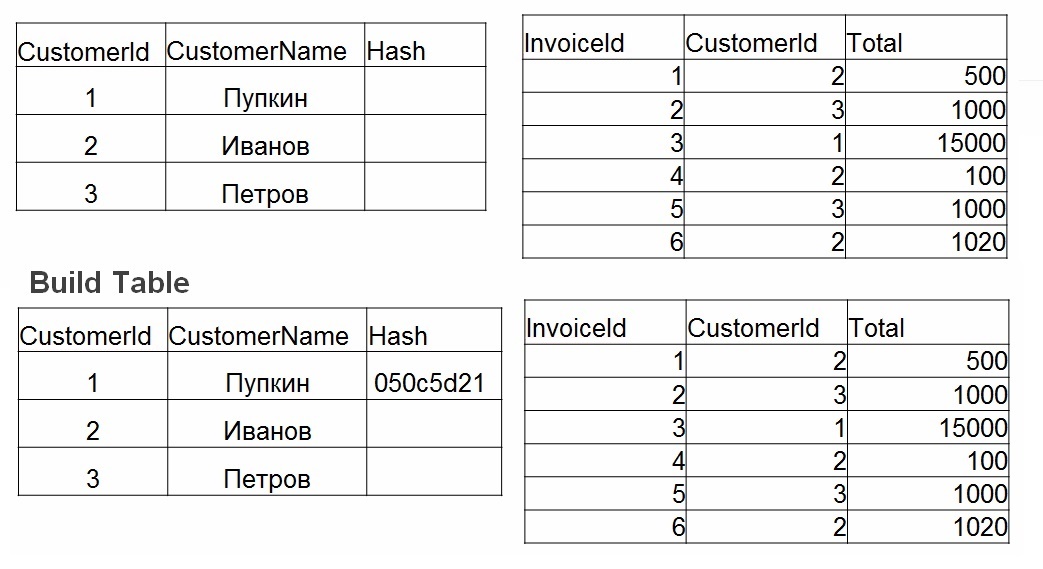
- 构建-哈希表建立在最小的表上。 对于表1中的每个值,考虑一个散列。 该值存储在哈希表中,并将计算出的哈希值用作键。
- 探查。 对于表2中的每一行,将为join(operator =)中指定的字段计算哈希值。 在哈希表中搜索哈希,检查字段值。
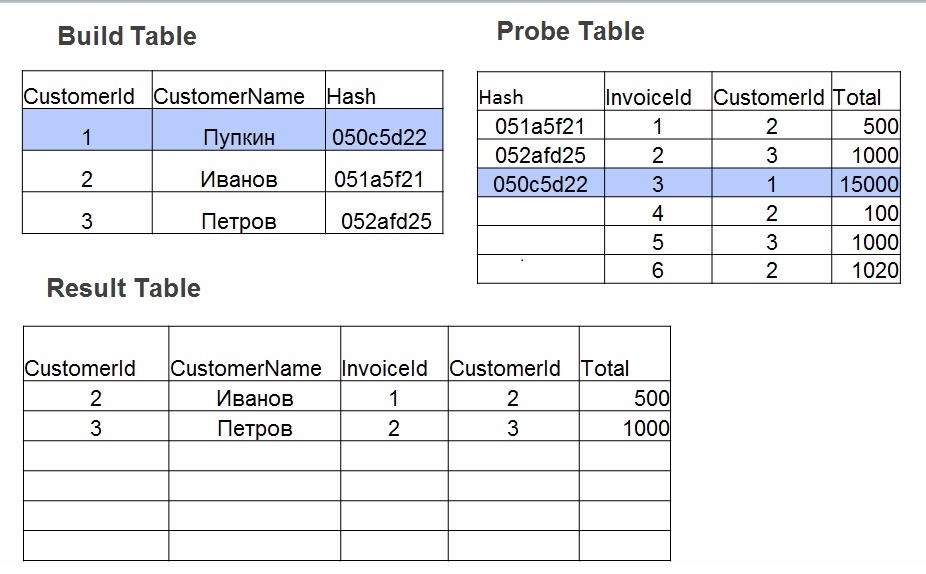
当哈希联接很好时:
重要的一点:如果没有足够的内存,记录将转到tempdb-到磁盘。
朋友们,除了上述内容之外,公开课还包括其他有趣的观点,最好通过观看视频来观看。 我们建议您参观“ MS SQL Server Developer”
课程的
开放日,在这里您可以向老师提问。
PS老师
克里斯蒂娜·库切罗娃(Kristina Kucherova)感谢Jes Schultz Borland在PASS Summitt执行计划:查询调优成功的秘诀上的
演讲 ,该
演讲被用于准备公开课。