哈Ha!
在12月,我们来自高级分析的同事Leonid Sherstyuk在第二届DigitalSkills行业冠军赛中的机器学习和大数据能力方面获得了第一名。 这是WorldSkills俄罗斯组织的著名专业比赛的“数字”分支。 总共有200多人参加了冠军争夺战,在25个数字能力方面争夺领导地位-防范内部安全威胁的企业保护,互联网营销,计算机游戏和多媒体应用程序的开发,量子技术,物联网,工业设计等。

作为机器学习的一个案例,提出了使用半自动超声控制系统监测和检测核电厂,石油和天然气管道中的缺陷的任务。
列昂尼德(Leonid)将讲述比赛中的情况以及他如何在降级中获胜。
WorldSkills是一个国际组织,在世界各地组织专业技能竞赛。 传统上,工业公司的代表和相关大学的学生参加了这些比赛,展示了他们在专业领域的技能。 最近,数字提名开始出现在比赛中,年轻的专家们在机器人技术,应用程序开发,信息安全以及您甚至不能称之为工人的其他专业领域中竞争。 在其中一项提名(机器学习和大数据处理)中,我参加了在WS主持下举行的DigitalSkills竞赛中的喀山竞赛。
由于比赛的能力是新的,所以我很难想象会发生什么。 为了以防万一,我重复了所有有关使用数据库和分布式计算,指标和训练算法,统计标准和预处理方法的知识。 熟悉大致的评估标准后,我不了解如何将成熟的工作与Hadoop相适应并在6个简短的会话中创建聊天机器人。
整个比赛进行3天,共6节。 每个会话为3小时,需要休息一下,为此您需要完成一些有意义地相关的任务。 起初,似乎时间已经足够,但实际上要花很多时间才能完成所设想的一切。
在比赛中,预计不会使用大数据,因此整个任务池被简化为分析有限的数据集。
实际上,我们被要求重复其中一个组织者的路线,客户将他们的问题和数据发送给他们,并希望他们在几周内获得商业报价。
我们处理了PUZK(半自动超声波控制系统)的数据。 该系统旨在检查管道接头是否有裂纹和缺陷。 设备本身沿着安装在管道上的导轨行进,并在每个步骤进行16次测量。 在理想条件下且没有缺陷的情况下,某些传感器应提供最大信号,其他传感器应为零。 实际上,数据非常嘈杂,回答给定位置是否存在缺陷这一问题变得不容易。
 安装PUZK系统
安装PUZK系统第一天致力于了解数据,清理数据,编制描述性统计数据。 我们仅获得有关设备安装和传感器类型的基本背景信息。 除了数据预处理之外,我们还必须确定传感器属于什么类型以及它们在设备上的位置。
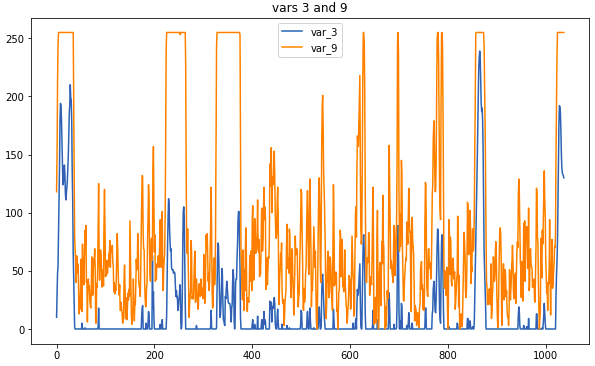 样本数据:这是相关传感器的外观
样本数据:这是相关传感器的外观主要的预处理操作是用移动平均值代替测量值。 如果窗口太大,则可能会丢失太多信息,但是有助于确定类型的关联将更加直观。 一些连接未经预处理就很明显。 但是,由于没有时间仔细检查原始数据,因此必须使用相关图。
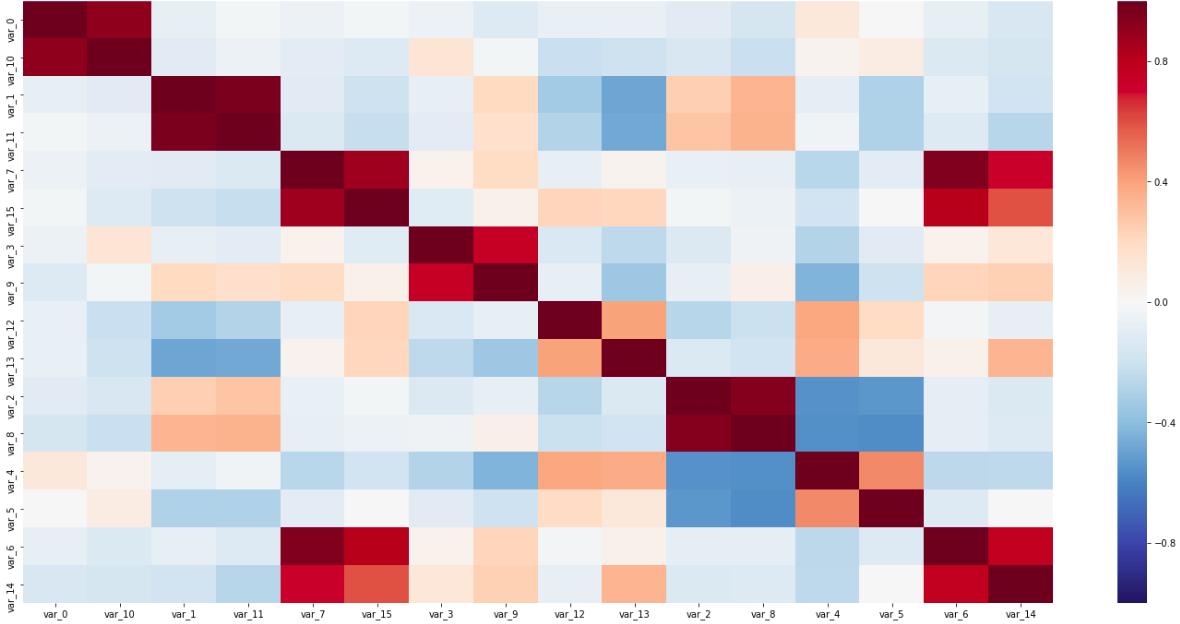 相关矩阵
相关矩阵在这个矩阵上,可以看到沿对角线的两对传感器,它们彼此紧密相连,并且具有负相关的变量。 所有这些有助于确定传感器的类型。
最后一项强制性的措施是将传感器减少到一个坐标。 由于测量设备明显超过一个测量步骤,并且传感器在整个设备上都隔开一定距离,因此在进一步使用数据进行训练之前,这是必不可少的步骤。
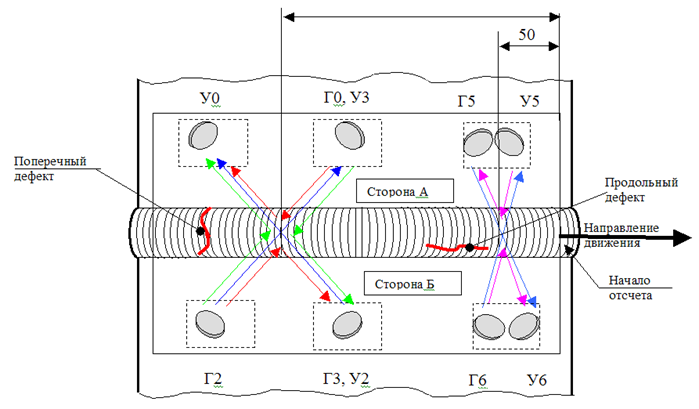
\
装置上的传感器布置在设备上安装传感器的示意图表明,我们需要找到三组传感器之间的距离。 这里最简单,最快的方法是确定每个传感器应该在设备的哪个部分,然后搜索最大相关性,一步步移动部分测量值。
由于无法保证我对传感器类型的假设,因此这一阶段变得很复杂,因此我必须仔细研究所有相关性,类型,方案,并将其链接到一个一致的系统中。
第二天,我们必须准备用于训练的数据并在点上进行聚类,然后构建分类器。
在准备数据期间,我删除了过于相关的读数,并且作为综合功能,我添加了移动平均值,导数和z得分。 无疑,新变量的合成可以广泛地进行,但是时间强加了它的局限性。
聚类可以帮助将缺陷点与其他所有人分开。 我尝试了3种方法:k均值,Birch和DBScan,但是不幸的是,它们均未给出良好的结果。
对于预测算法,我们有完全的自由度。 仅指定应在输出中获取的格式。 该算法应该提供一张表(或可简化为该表的数据),其中一行对应一个裂纹,而其列对应其特性(例如长度,宽度,类型和侧面)。 在我看来,这是最简单的选择,其中我们对测试样品的每个点进行预测,然后将相邻的点合并为一个裂纹。 结果,我做出了3个分类器,回答了以下问题:缺陷在接缝的哪一侧,走到多深以及它属于哪种类型(纵向或横向)。
在这里,应该通过回归预测的深度是惊人的。 但是,在标记的样本中,我发现只有5个唯一的深度,因此我发现这种简化是可以接受的。
 算法评估指标
算法评估指标在所有算法中(我设法尝试了逻辑回归,决定性树和梯度增强),按预期,增强效果最佳。 度量无疑是非常令人愉快的,但是要在没有新的测试集结果的情况下评估算法的操作是相当困难的。 组织者从未返回过具体的指标,而是将自己局限于一般性评论,即没有人进行测试以及延迟抽样。
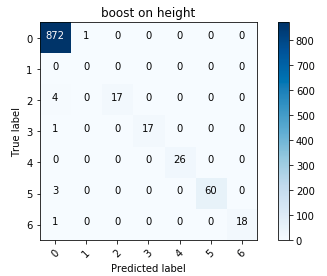 提升误差矩阵
提升误差矩阵总的来说,我对结果感到满意。 尤其是将高度降低到分类变量的回报。
在最后一天,我们不得不将训练有素的算法包装在潜在客户可以使用的产品中,并准备好我们的企业就绪解决方案的演示文稿。
在这里,完美主义帮助我编写了相对简洁的代码,即使在有限的时间内,代码也没有消失。 通过现成的代码,原型得以快速开发,并且我有时间调试错误。 与之前的阶段相比,这里的解决方案性能起着更为重要的作用,而不是满足正式的标准。
 成品-CLI实用程序
成品-CLI实用程序在会议即将结束时,我得到了一个CLI实用程序,该实用程序接受源文件夹作为输入,并以技术人员方便的形式返回带有预测结果的表。
在最后阶段,我有机会谈论自己的成功,并了解其他参与者。 即使在严格的标准下,我们的决定也完全不同-一个人成功地聚类,另一个人熟练地使用线性方法。 在演讲中,参赛者强调了自己的优势-有些人出售产品,另一些人更沉迷于技术细节; 有精美的图形和自适应解决方案界面。
 我的解决方案的主要优点可以放在一张幻灯片上
我的解决方案的主要优点可以放在一张幻灯片上一般情况下竞争如何?
这种类型的比赛是一个很好的机会,以了解您能够以多快的速度执行自己专业的典型任务。 标准的编制方式使获得最佳结果的人员(例如,在Kaggle上)获得最高分,但最有可能执行行业日常工作中典型的操作。 在我看来,参与此类竞赛并取得胜利可以告诉潜在的雇主,与他们在黑客马拉松和Kaggle的行业经验一样。
列侬尼德·谢尔斯蒂克
SIBUR高级分析数据分析师