在我之前的项目中,我们面临着对多对地理坐标执行
反向地理编码的任务。 反向地理编码是一种过程,它匹配由坐标指定的点所属或接近的地图上对象的地址或名称。 也就是说,我们以坐标表示,例如:@ 55.7602485,37.6170409,然后得到的结果是“俄罗斯,中央联邦区,莫斯科,剧院广场,某某房屋”或“莫斯科大剧院”。
如果地址或名称在输入中,而坐标在输出中,则此操作为
直接地址解析 ,我们希望稍后再讨论。
作为输入,我们在入口处大约有100或20万个点,它们作为Hive表位于Hadoop集群中。 这是为了明确任务的规模。
最终选择了Spark作为处理工具,尽管在此过程中我们尝试了MapReduce和Apache Crunch。 但这是一个独立的故事,也许值得发表。
简单的解决方案,价格合理
首先,我们可以尝试解决这个问题。 作为一种工具,有一台提供反向地理编码REST服务的ArcGIS Server。 使用它非常简单,为此,我们使用以下URL执行http GET请求:
http://-url/GeocodeServer/reverseGeocode?<>
在许多参数中,只需将location设置为x,y(主要是不要混淆其中哪个是纬度,哪个是经度;)。 现在,我们已经有了带有结果的JSON:国家,地区,城市,街道,门牌号。 文档中的示例:
{ "address": { "Match_addr": "Beeman's Redlands Pharmacy", "LongLabel": "Beeman's Redlands Pharmacy, 255 Terracina Blvd, Redlands, CA, 92373, USA", "ShortLabel": "Beeman's Redlands Pharmacy", "Addr_type": "POI", "Type": "Pharmacy", "PlaceName": "Beeman's Redlands Pharmacy", "AddNum": "255", "Address": "255 Terracina Blvd", "Block": "", "Sector": "", "Neighborhood": "South Redlands", "District": "", "City": "Redlands", "MetroArea": "Inland Empire", "Subregion": "San Bernardino County", "Region": "California", "Territory": "", "Postal": "92373", "PostalExt": "", "CountryCode": "USA" }, "location": { "x": -117.20558993392585, "y": 34.037880040538894, "spatialReference": { "wkid": 4326, "latestWkid": 4326 } } }
您还可以指出我们想要什么类型的答案-邮政地址,或说POI(兴趣点,这是为了获得诸如“莫斯科大剧院”之类的答案),或者例如我们是否需要街道交叉路口。 您还可以指定将从指定点搜索命名对象的半径。
为了快速检查响应的质量,您可以估计请求参数中的起点与服务响应中的接收点之间的距离。
看来现在一切都会好起来的。 但事实确实如此。 我们的ArcGIS实例运行速度很慢,为服务器分配了4个内核,以及大约8 GB的RAM。 结果,群集上的任务可以非常快速地读取我们的20万个点,但是要依靠REST和ArcGIS的性能。 对所有点进行地理编码需要花费数小时。 同时,我们在Hadoop上仅分配了大约8个核心,并分配了一些内存,但是由于在很长时间内加载ArcGIS Server接近100%,集群中的额外资源无法提供任何帮助。
ArcGIS不知道如何执行批量反向地理编码操作,因此该请求对每个点执行一次。 顺便说一句,如果服务没有响应,那么我们会因超时或出现错误而失败,并且该怎么办就是答案不明确的问题。 也许再试一次,或者完成整个过程,然后对原始点重复一下。
第二种近似,我们介绍缓存
首先,我们发现集合中的许多点都有重复的坐标。 原因很简单-显然,GPS精度不足以使彼此相距两米的点的坐标在输出端出现差异,或者将不是从GPS而是从另一个基准获得的坐标简单地输入到源数据库中。 一般来说,为什么会这样并不重要,主要是这是一种非常典型的情况,因此从服务接收的结果缓存将使您只能对每对坐标进行一次地理编码。 而且我们可以负担得起缓存的内存。
实际上,对该算法的第一个修改是微不足道的-从REST获得的所有结果都添加到了缓存中,并且对于所有点,都首先搜索了其中的坐标。 我们甚至没有开始为所有Spark进程创建通用缓存-每个集群节点都有自己的缓存。
用这种简单的方法,我们能够获得高达10倍的加速度,这大约相当于原始集中的坐标重复次数。 它已经可以接受,但仍然很慢。
好吧,这时我们的客户告诉我们,如果我们不能更快地找出地址,我们是否可以迅速识别至少一个城市? 然后我们开始...
简化的解决方案,实现了Geomerty API
我们必须定义一个城市吗? 我们具有俄罗斯区域的几何形状,即行政区域划分,大致与城市地区相同。
您可以
在此处以这些数据为例。 那里有什么? 这是俄罗斯联邦行政边界的数据库,级别从2(国家)到9(城市地区)。 格式为geojson或CSV(而几何图形本身为wkt格式)。 该数据库总共有大约2万条记录。
一个新的简化的解决方案如下所示:
- 将ADT数据上传到Hive。
- 对于具有坐标的每个点,我们在区域划分表中查找该点进入的多边形。
- 按级别对找到的多边形进行排序。
结果,我们得到了类似的东西:俄罗斯,中央联邦区,莫斯科,某某行政区,某某地区,即我们所指的领土清单。
ADT加载
要轻松下载CSV,请使用
kite 。 该工具可以很好地基于CSV中的列标题为Hive构建方案。 实际上,导入可归结为三个命令(每个级别文件重复一个命令):
kite-tools csv-schema admin_level_2.csv --class al --delimiter \; >adminLevel.avrs kite-tools create dataset:hive:/default/levelswkt -s adminLevel.avrs kite-tools csv-import admin_level_2.csv dataset:hive:/default/levelswkt --delimiter \; ... kite-tools csv-import admin_level_10.csv dataset:hive:/default/levelswkt --delimiter \;
我们在这里做了什么? 第一组为我们建立了一个用于csv的Avro方案,为此我们指定了方案的一些参数(在本例中为类),以及一个CSV的字段分隔符。 接下来,值得用您的眼睛查看所获得的图表,并可以进行一些更正,因为Kite并不查看文件的所有行,而只是查看一些示例,因此有时可能对数据类型做出错误的假设(我看到了三个数字-我决定数字列,然后转到该行)。
好吧,然后基于该方案,我们创建一个数据集(这是通用术语Kite,在Hive中概括表,在HBase中概括表,等等)。 在这种情况下,默认值是数据库(对于Hive,它与架构相同),而levelwkt是表的名称。
好吧,最新的命令将CSV文件上传到我们的数据集中。 下载成功完成后,您可以完成请求:
select * from levelswkt;
在某个地方。
处理几何
为了在Java中使用几何,我们选择了Esri
Java Geometry API (ArcGIS开发人员)。 原则上,可以采用其他框架,也可以选择一些开放源代码,例如广为人知的
JTS拓扑套件或
Geotools 。
第一项任务使我们能够处理来自同一Esri公司的另一个框架,称为
Spatial Framework for Hadoop ,并基于第一个
框架 。 实际上,我们需要从中获得所谓的SerDe,即Hive的序列化/反序列化模块,该模块允许我们在Hive中以表格形式显示一堆geojson文件,其列均来自geojson属性。 几何本身成为另一列(带有二进制数据)。 结果,我们有了一张表,其中一列是某个区域的几何形状,其余是其属性(名称,ADT中的级别等)。 该表可用于Spark应用程序。
如果我们以CSV格式加载数据库,那么将有一个列,其中的几何形状为
WKT格式的文本形式。 在这种情况下,Spark可以在运行时使用Geometry API创建几何对象。
我们选择CSV格式(和WKT)是出于一个简单的原因-众所周知,俄罗斯在地图上所占楚科奇坐标系超过180个子午线。 geojson格式有一个局限性-内部的所有多边形都必须限制为180度,而穿过180子午线的多边形必须沿其切成两部分。 结果,当将几何导入到Geometry API中时,我们得到了一个几何API不正确地为俄罗斯边界定义边界框(包围矩形)的对象。 原来答案是经度-180.180。 当然哪一个是不正确的-实际上,俄罗斯大约需要20到-170度。 这是一个Geometry API问题;今天它可能已经修复,但是我们不得不解决它。
WKT没有这样的问题。 您可能会问,为什么我们需要边界框? 然后我会告诉;)
要解决所谓的PIP问题,仍然是政策问题。 Java Geometry API可以再次执行此操作,对我们来说很简单,一种是Point类型的几何,该区域的另一种多边形(Multipoligon),一个contains方法。
结果,第二种解决方案以及在额头上都看起来像这样:Spark应用程序加载ADT,包括几何图形。 像地图名称->几何图形这样的东西是由它们构建的(实际上稍微复杂一点,因为ADT相互嵌套,并且我们只需要在已经找到的较高层次中包含的较低层次中进行搜索。结果,存在某种几何形状树根据源数据仍然需要构建)。 然后,我们用我们的点构建一个Spark数据集,并为每个点应用我们自己的UDF,该UDF检查该点在所有几何体(在树中)中的输入。
编写新版本大约需要一天的工作,因为Hadoop捆绑软件Spatial Framework包括直接用于解决PIP任务的好示例(尽管使用其他几种方法)。
我们开始了,……哦,恐怖,事情并没有变得更快。 再次观看。 现在是时候考虑优化了。
简化的解决方案,QuadTree
刹车的原因很明显-例如,俄罗斯的几何形状。 外部边界,这是geojson的兆字节,一个很大的多边形,而不是一个。 如果您回想起PIP问题是如何解决的,那么一种著名的方法是从某个点构建一条光线,例如说到无穷远处,然后确定与多边形相交的点数。 如果点的数量为偶数,则该点在多边形之外;如果为奇数,则为内部。
这是
Wiki的描述。

很明显,对于一个巨大的多边形,相交问题的解决方法要复杂得多,因为多边形中有直线。 因此,希望以某种方式丢弃那些点显然不能进入的多边形。 作为额外的救生工具,可以将支票放下进入俄罗斯边境(如果我们知道显然所有坐标都包括在内)。
为此,
象限树适合我们。 幸运的是,实现全部在同一个Geometry API中(还有更多)。

基于树的解决方案如下所示:
- 加载ATD几何
- 对于每种几何,我们定义一个封闭的矩形
- 我们把它放在QuadTree中,得到索引
- 索引被记住
接下来,当处理要点时:
- 我们问QuadTree它知道哪些几何可能包含一个点
- 获取几何索引
- 仅针对他们,我们通过解决PIP问题来检查发生情况
开发全部需要四个小时。 我们再次开始,我们看到任务很快就完成了。 我们检查-一切都很好,解决方案已收到。 几分钟就到了。 QuadTree为我们提供了几个数量级的加速。
总结
那么,我们最终得到了什么? 我们获得了一种反向地理编码机制,该机制可在Hadoop集群上有效地并行化,并在大约一分钟的时间内解决了20万个点的最初问题。 即 我们可以轻松地将此解决方案应用于数百万个点。
该解决方案的局限性是什么? 首先,显而易见的一个-它基于我们可获得的ADT数据,其中a)可能不相关b)仅限于俄罗斯。
第二-我们无法解决封闭多边形以外的对象的反向地理编码问题。 这意味着-街道也是如此。
发展历程
该怎么办?
要拥有当前的ADT几何形状,最简单的方法是从OpenStreetMap中获取它们。 当然,他们将需要做一些工作,但这是一个完全可解决的任务。 如果有兴趣,我将在其他时间讨论将OpenStreetMap数据加载到Hadoop集群中的任务。
街道和房屋可以做什么? 原则上,街道位于同一OSM中。 但是这些不是封闭的结构,而是线条。 要确定该点“接近”某条街道,您将必须从与该街道等距的点为该街道构建一个多边形,并检查其是否进入该多边形。 结果,一种香肠变成了……看起来像这样:
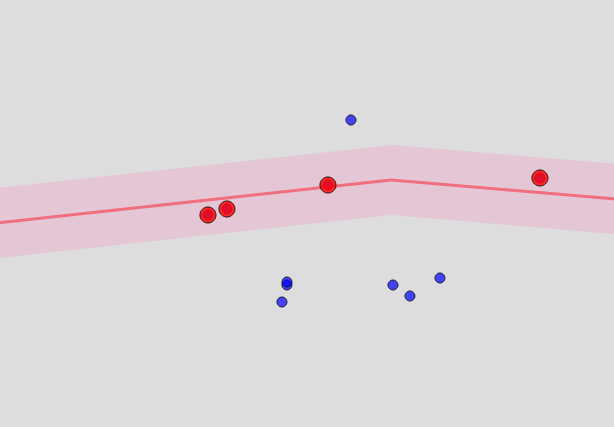
该点有多近? 这是一个参数,大致对应于ArcGIS在其中寻找对象的半径,我一开始就提到了该半径。
因此,我们发现到某个点的距离小于某个限制(例如100米)的街道。 并且此限制越小,算法的运行速度越快,但是您找不到单个匹配项的可能性就越大。
明显的问题是不可能预先计算这些所谓的缓冲区-它们的大小是服务的参数。 在我们确定了城市的所需区域并从OSM基地中选择穿过该区域的街道之后,需要即时构建它们。 但是,可以预先选择街道。
发现区域中的房屋也不会移动到任何地方,因此它们的清单可以提前建立-但是进入房屋仍然需要即时考虑。
也就是说,您必须首先建立“城市区域”形式的索引->带有几何形状链接的房屋列表,以及类似的街道列表。
一旦我们确定了区域,我们就会获得房屋和街道的清单,我们沿着边界的街道建造,只有针对它们,我们才能解决PIP问题(可能使用与区域边界相同的优化方法)。 显然,在这种情况下,房屋的象限树也可以预先构建并保存在某个地方。
我们的主要目标是最大程度地减少计算量,同时预先最大化并保留可以计算和保存的所有内容。 在这种情况下,该过程将包括构建索引的缓慢阶段和计算的第二阶段,该阶段已经很快进行,接近于在线版本。