在先前的文章中,他们已经写了关于我们的文本识别技术如何工作的文章:
直到2018年,日文和中文字符的识别方式都是相同的:主要使用栅格和要素分类器。 但是随着象形文字的识别,存在一些困难:
- 需要区分大量的类。
- 整体上更复杂的设备特征。

准确地说出中文字母有多少个字符是很难的,因为要计算俄语中有多少个单词是准确的。 但大多数情况下用中文书写〜10,000个字符。 对于它们,我们限制了用于识别的类的数量。
上述两个问题还导致以下事实:要获得高质量,您必须使用大量符号,并且这些符号本身是在字符图像上计算得更长的时间。
为了使这些问题不会导致整个识别系统的严重减速,我不得不使用许多启发式方法,主要目的是快速切掉大量的象形文字,而这张图片绝对不是这样。 它仍然无济于事,但我们希望将我们的技术提升到一个全新的水平。
我们开始研究卷积神经网络的适用性,以提高象形文字的质量和识别速度。 我想借助神经网络替换用于识别这些语言的单个字符的整个单元。 在本文中,我们将描述我们如何最终成功。
一种简单的方法:一个卷积网络识别所有象形文字
通常,使用卷积网络进行字符识别根本不是一个新主意。
从历史上看,早在1998年
,它们就被首次用于此任务。 是的,那么这些不是印刷字符,而是手写的英文字母和数字。
20多年来,当然,深度学习领域的技术已经实现了飞跃。 包括更高级的体系结构和新的学习方法。
实际上,上图(LeNet)中显示的体系结构,如今已经非常适合于诸如打印文本识别之类的简单任务。 与计算机视觉的其他任务(例如面部搜索和识别)相比,我称之为“简单”。
看来解决方案再简单不过了。 我们采用一个神经网络,一个标记象形文字的样本,并对其进行分类训练。 不幸的是,事实证明一切都不是那么简单。 LeNet用于对10,000个象形文字进行分类的所有可能的修改都没有提供足够的质量(至少与我们已经拥有的识别系统相当)。
为了达到要求的质量,我们必须考虑更深,更复杂的体系结构:WideResNet,SqueezeNet等。 在他们的帮助下,有可能达到所需的质量水平,但速度却大大降低了-是CPU上基本算法的3-5倍。
有人可能会问:“如果在图形处理器(GPU)上运行得更快,那么测量CPU上的网络速度有什么意义呢?”? 这里值得一提的是,CPU上算法的速度对我们而言至关重要。 我们正在为ABBYY的大型识别产品线开发技术。 在大多数情况下,识别是在客户端进行的,我们不知道它具有GPU。
因此,最后,我们遇到了以下问题:一个根据体系结构选择来识别所有字符的神经网络,要么工作得太差,要么工作得太慢。
两级神经网络象形文字识别模型
我不得不寻找另一种方式。 同时,我不想放弃神经网络。 似乎最大的问题是类别众多,因此有必要构建复杂体系结构的网络。 因此,我们决定不针对大量类(即整个字母)训练网络,而是针对少量类(字母子集)训练许多网络。
一般而言,理想系统的介绍如下:将字母分为相似字符的组。 一级网络对给定图像属于哪一组字符进行分类。 依次为每个组训练第二级网络,该网络将在每个组内生成最终分类。
可点击的图片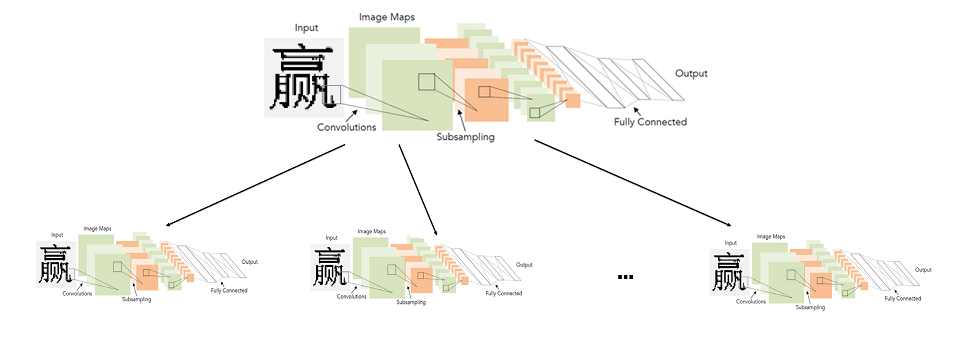
因此,我们通过启动两个网络来进行最终分类:第一个确定要启动哪个第二级网络,第二个已经进行了最终分类。
实际上,这里的基本要点是如何将字符分成几组,以便可以使第一级网络准确而快速。
建立一级分类器
要了解哪些网络符号更容易区分,哪些网络符号更难,最简单的方法是查看哪些符号对于特定符号而言比较突出。 为此,我们采用了经过训练的分类器网络,该网络经过训练可以很好地区分字母的所有字符,并研究了该网络倒数第二层的激活统计信息-我们开始研究了网络针对所有字符接收的最终特征表示。
同时,我们知道图片中应该包含以下内容:
这是将手写数字选择(MNIST)分为10类的简单示例。 在分类之前的倒数第二个隐藏层上,只有2个神经元,这使得它们的激活统计信息易于在平面上显示。 图上的每个点都对应于测试样本中的一些示例。 点的颜色对应于特定类别。
在本例中,特征空间的尺寸大于示例中的128,我们从测试样本中运行了一组图像,并为每个图像接收了一个特征向量。 之后,将它们标准化(按长度划分)。 从上图可以明显看出为什么这样做值得。 我们通过KMeans方法对归一化向量进行聚类。 我们将样本细分为相似的图像组(从网络角度来看)。
但是最后,我们需要将字母表分为几组,而不是测试样本的一部分。 但是第二个中的第一个并不难获得:将每个类标签分配给包含该类最多图像的群集就足够了。 当然,在大多数情况下,整个类甚至都可以集中在一个集群中。
好的,就是这样,我们将整个字母表分为相似字符组。 然后剩下的是选择一个简单的体系结构并训练分类器来区分这些组。
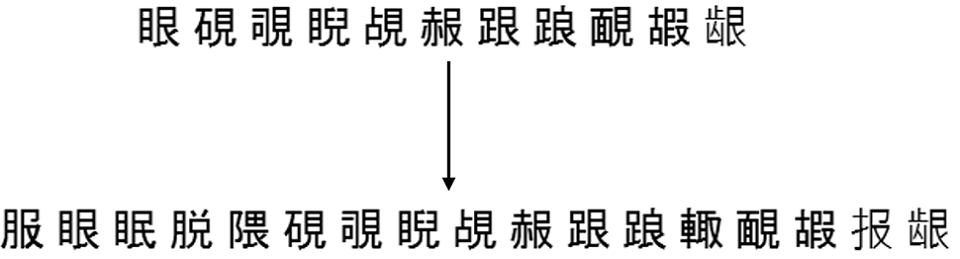
这是通过将整个源字母划分为500个簇而获得的随机6组的示例:
二级分类器的构造
接下来,您需要确定第二级分类器将学习哪些目标字符集。 答案似乎很明显-这些应该是在上一步中获得的字符组。 这将起作用,但并非总是具有良好的质量。
事实是,第一级分类器在任何情况下都会产生错误,并且可以通过如下构造第二级集来部分抵消它们:
- 我们修复了某些单独的符号图像样本(不参加培训或测试);
- 我们通过训练有素的一级分类器运行此样本,并使用该分类器的标签(组标签)标记每个图像;
- 对于每个符号,我们考虑第一级分类器属于该符号图像的所有可能的组。
- 将此符号添加到所有组中,直到达到所需的覆盖率T_acc;
- 我们将符号的最终组视为第二级的目标集,在第二级上将训练分类器。
例如,符号“ A”的图像由第一级分类器980分配给第五组,19次分配给第二组并且1次分配给第六组。 总共我们有1000个该符号的图像。
然后,我们可以将符号“ A”添加到第五组,并获得该符号的98%覆盖率。 我们可以将其归为第5和第2组,并获得99.9%的覆盖率。 我们可以立即将其归为组(5、2、6),并获得100%的覆盖率。
本质上,T_acc在速度和质量之间设置了一些平衡。 等级越高,分类的最终质量就越高,但是第二级的目标集越大,第二级的分类就越困难。
实践表明,即使在T_acc = 1的情况下,由于上述补货程序导致的套数增加也不是很明显-平均约为2倍。 显然,这将直接取决于受过训练的一级分类器的质量。
这是一个示例,说明如何完成从同一分区到更高的500个组中的一组集合的工作:
模型嵌入结果
经过训练的两级模型最终比以前使用的分类器更快,更好。 实际上,使用相同的线性分割图(GLD)来“交友”并不容易。 为此,我不得不单独讲授该模型,以区分字符与先验垃圾和行分割错误(在这些情况下返回低置信度)。
嵌入以下完整文档识别算法的最终结果(在中文和日文文档的集合中获得),指示了完整算法的速度:
在将所有字符识别都转移到神经网络的同时,我们提高了质量并加快了正常和快速模式下的速度。
关于端到端识别的一些知识
如今,大多数众所周知的OCR系统(与Google的Tesseract相同)都使用神经网络的端到端体系结构来整体识别字符串或其片段。 但是在这里,我们精确地使用了神经网络来代替单个字符识别模块。 这不是偶然的。
事实是,由于
等距打印,将字符串分割成中文和日文印刷字符不是什么大问题。 在这方面,对这些语言使用端到端识别不会显着提高质量,但速度要慢得多(至少在CPU上如此)。 通常,不清楚如何在端到端上下文中使用建议的两级方法。
相反,有些语言将线性划分为字符是一个关键问题。 明确的例子是阿拉伯语,印地语。 例如,对于阿拉伯语,端到端解决方案已经在与我们积极研究中。 但这是一个完全不同的故事。
OCR新技术集团负责人Alexey Zhuravlev