
社交网络是当今最受欢迎的Internet产品之一,也是分析的主要数据来源之一。 在社交网络内部,数据科学领域最困难和最有趣的任务被认为是新闻源的形成。 实际上,为了满足用户对内容质量和相关性的日益增长的需求,有必要学习如何从许多来源收集信息,计算用户反应的预测并在A / B测试中平衡数十种竞争指标之间的平衡。 大量数据,高工作量以及对响应速度的严格要求使任务变得更加有趣。
今天看来,排名的任务已经被广泛研究,但是如果仔细观察,它并不是那么简单。 提要中的内容非常不同-这是一张朋友的照片,以及备忘录,病毒式视频,长篇小说和科学流行音乐。 为了将所有内容整合在一起,您需要来自不同领域的知识:计算机视觉,使用文本,推荐系统,以及无所不能的现代高负载存储和数据处理工具。 今天,要找到一个拥有所有技能的人非常困难,因此,对磁带进行分类确实是一项团队任务。
Odnoklassniki早在2012年就开始尝试使用不同的色带排名算法,而在2014年,机器学习也加入了这一过程。 首先,这要归功于数据流处理技术领域的进步。 刚开始在
Kafka中收集对象显示及其属性,并使用
Samza汇总日志时,我们就能够建立训练模型的数据集并
计算出最“吸引”的功能:“点击率”对象和推荐系统的预测“基于”
LinkedIn同事的
工作 。

很快就清楚地发现,逻辑回归的主力军无法单独带走磁带,因为用户的反应可能非常多样化:类,评论,单击,隐藏等,并且内容可能非常不同-照片朋友,群发帖子或朋友题词的视频。 每种内容类型的每种反应都有其自身的特性和自身的商业价值。 结果,我们想到了“
逻辑回归矩阵 ”的概念:针对每种内容类型和每种反应建立一个单独的模型,然后将其预测值乘以根据当前业务优先级由人工形成的权重矩阵。
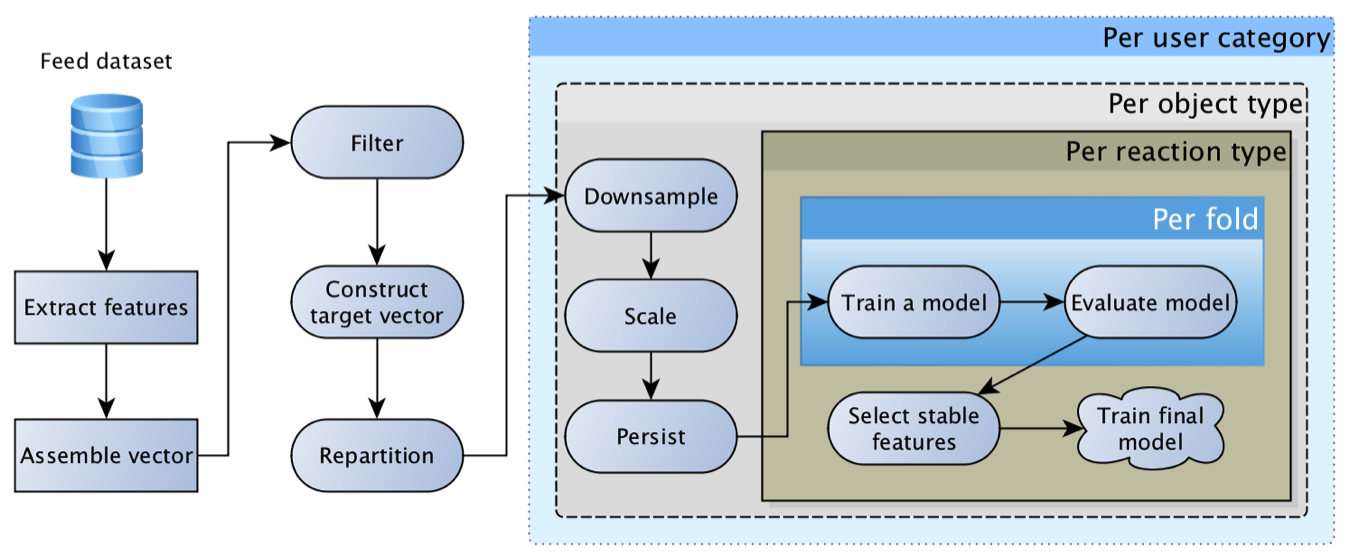
此模型非常可行,并且很长时间以来一直是主要模型。 随着时间的流逝,它获得了越来越有趣的功能:对象,用户,作者,用户与作者的关系,与对象进行交互的人等。 结果,用神经网络替换回归的第一次尝试以可悲的“我们拥有的功能太糟糕了,网格无法提供帮助”而告终。
在这种情况下,从用户活动的角度来看,最明显的提升通常是技术上的改进而不是算法上的改进:挖出更多候选者进行排名,更准确地跟踪节目的事实,优化算法的响应速度,加深浏览历史。 此类改进通常可以产生单位,有时甚至可以增加数十%的活动,而更新模型和添加功能通常可以增加十分之几。

更新模型的实验中的另一个困难是创建内容的重新平衡-“新”模型的预测分布通常可能与其前身有很大不同,从而导致流量和反馈的重新分布。 结果,很难评估新模型的质量,因为首先您需要校准内容平衡(重复出于业务目的设置矩阵权重的过程)。 在研究了
来自Facebook同事的
经验之后 ,我们意识到该模型
需要进行校准 ,并且等渗回归在logistic回归的基础上添加了:)。
通常,在准备新的内容属性的过程中,我们会感到沮丧-使用基本协作技术的简单模型可以提供80%甚至90%的结果,而时尚的神经网络在超昂贵的GPU上进行了为期一周的训练,可以完美地检测出猫和汽车,但增加了指标仅在第三位数。 在实现主题模型,fastText和其他嵌入时,通常会看到类似的效果。 我们通过从正确的角度进行验证来克服挫败感:随着有关对象信息的积累,协作算法的性能显着提高,而对于“新鲜”对象,内容属性则带来了明显的提升。
但是,当然,总有一天有待改进logistic回归的结果,并通过应用最近发布的
XGBoost-Spark取得了进展。 集成
并非易事 ,但最终,该模型终于变得时尚而年轻,并且指标增长了百分之几。
当然,可以从数据中提取更多的知识,并且可以将磁带的排名提高到新的高度-今天,每个人都有机会在
SNA Hackathon 2019竞赛中尝试这项
非凡的任务。 比赛分为两个阶段:2月7日至3月15日,将解决方案下载到以下三个任务之一。 3月15日之后,将汇总中间结果,排行榜顶部的15个人将接受第二阶段的邀请,第二阶段将于3月30日至4月1日在Mail.ru Group的莫斯科办事处举行。 此外,第二阶段的邀请将在2月23日结束时接受三人的领导。
为什么要执行三个任务? 作为在线阶段的一部分,我们提供三组数据,每组数据仅呈现以下一个方面:图像,文本或有关各种协作属性的信息。 而且只有在第二阶段,当不同领域的专家汇聚在一起时,才会显示通用数据集,从而使您可以找到不同方法协同作用的要点。
对任务感兴趣? 加入
SNA Hackathon :)