Bill Kennedy在他精彩的
Ultimate Go编程课程的演讲中说:
许多开发人员寻求优化他们的代码。 他们排成一行并重写,说这样会变得更快。 需要停止。 仅在概要分析并创建基准之后,才可以说此代码或该代码更快。 算命不是编写代码的正确方法。
我一直想通过一个实际的例子来演示这是如何工作的。 前几天,我的注意力转移到以下代码,可以将其用作示例:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
在此,在从数据库返回的
构建切片的所有元素中,
PatchURLs被
ReversePatchURLs替换,
ExtractedSize被
RPatchExtractedSize替换,然后执行反向操作-更改元素的顺序,以使最后一个元素成为第一个和最后一个。
我认为,源代码阅读起来有些复杂,可以进行优化。 这段代码执行了一个简单的算法,该算法由两个逻辑部分组成:更改切片元素和排序。 但是对于程序员来说,隔离这两个组件将需要时间。
尽管两个部分都很重要,但是反向代码并未像我们希望的那样被强调。 它分散在三行撕裂的线上:初始化一个新的切片,以相反的顺序迭代一个现有的切片,在新的切片的末尾添加一个元素。 但是,人们不能忽视该代码的无疑优势:该代码正在运行并经过测试,如果客观地说,它就足够了。 单个开发人员对代码的主观理解不能成为改写代码的借口。 不幸的是,幸运的是,我们不会仅仅因为不喜欢它而重写代码(或者,经常发生,仅仅是因为它不是我们的代码,请参见
致命缺陷 )。
但是,如果我们不仅设法改善对代码的理解,还大大加快了代码的处理速度,该怎么办? 这是完全不同的事情。 您可以提供几种替代算法来执行代码中嵌入的功能。
第一种选择:遍历
范围循环中的所有元素; 要在每次迭代中反转原始切片,请在最终数组的开头添加一个元素。 因此,我们可以摆脱使用变量
len的麻烦,使用
len函数,很难从头开始遍历元素,并且还减少了两行代码(从七行减少到五行),并且代码越小,允许它的可能性就越小一个错误。
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
从末尾删除了切片枚举后,我们清楚地区分了更改元素的操作(第三行)和原始数组的反向操作(第四行)。
第二种选择的主要思想是进一步扩展元素的变化和排序。 首先,我们对元素进行排序并进行更改,然后通过单独的操作对切片进行排序。 此方法将需要切片的分类接口的其他实现,但它将提高可读性,并将反向元素与更改元素完全分离并隔离,并且
反向方法必定会向读者指示所需的结果。
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
第三个选项几乎是第二个选项的重复,但是使用
sort.Slice进行排序,这使代码量增加了一行,但避免了对排序接口的其他实现。
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
乍一看,在内部复杂性,迭代次数,应用函数,初始代码和第一个算法方面都非常接近。 第二个和第三个选项似乎比较困难,但是不可能毫不含糊地说出四个选项中的哪一个是最佳的。
因此,我们禁止我们根据没有证据支持的假设进行决策,但是很明显,最有趣的是,在切片的末尾添加元素时,append函数的行为方式。 毕竟,实际上,此功能并不像看起来那样简单。
Append的工作
方式如下 :如果其容量大于总长度,则将其添加到现有切片中,或者在内存中为新切片保留一个位置,将第一个切片中的数据复制到其中,添加第二个切片的数据,并返回一个新的结果片。
该函数工作中最有趣的细微差别是用于为新阵列保留内存的算法。 由于最昂贵的操作是分配新的内存,因此Go开发人员做了一些小技巧,以使
append操作更便宜。 首先,为了避免每次添加元素时都重新保留内存,以一定的余量分配内存量-是原始内存的两倍,但是在一定数量的元素之后,新保留的内存部分的大小不超过两倍,而是增加25%。
在对
append函数有了新的理解之后
,问题的答案是:“什么会更快:将一个元素添加到现有切片的末尾,或者将现有切片添加到一个元素中的切片?” -已经更加透明。 可以假设在第二种情况下,与第一种情况相比,会有更多的内存分配,这将直接影响工作速度。
因此,我们顺利达到了基准。 借助基准测试,您可以评估算法在最关键的资源(例如运行时和RAM)上的负载。
让我们编写一个基准来评估我们所有四种算法,同时我们将评估哪些增长可以使我们拒绝排序(以便了解在排序上花费了总时间)。 基准代码:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
使用命令
go test -bench =启动基准
。 -benchmem 。
下图显示了切片10、100、1000、10000和100000元素的计算结果,其中F1是初始算法,F2是将元素添加到数组的开头,F3是使用
sort.Reverse to sort,F4是使用
sort.Slice ,F5-拒绝排序。
运作时间 内存分配数
内存分配数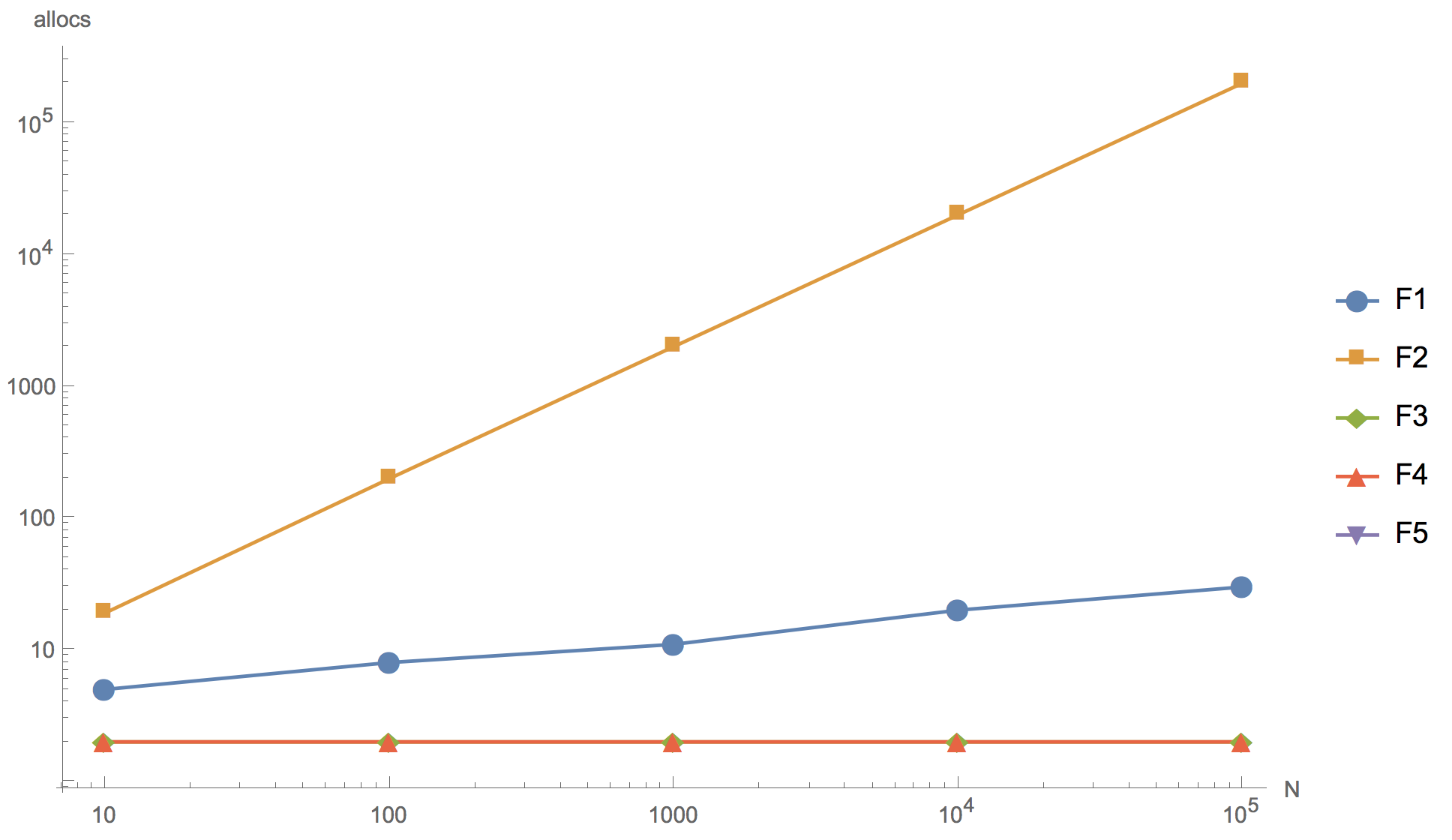
从图中可以看到,可以增加数组,但是最终结果在原则上已经可以在10个元素的切片上区分。
所提出的替代算法(F2,F3,F4)在速度上均不能超过原始算法(F1)。 即使事实是除F2之外的所有内存都比原始内存少。 最初在切片的开头添加元素的算法(F2)效果最差:如预期的那样,它拥有太多的内存分配,以至于绝对不可能在产品开发中使用它。 使用内置反向排序功能(F3)的算法比原始算法慢得多。 而且只有
sort.Slice排序
算法在速度上与原始算法相当,但略逊于原始算法。
您还可以注意到,拒绝排序(F5)会显着加速。 因此,如果您确实要重写代码,则可以朝这个方向发展,例如,从数据库中提高初始
构建切片,在请求中使用按ID DESC而不是ASC进行排序。 但是同时,我们被迫超越了所考虑的代码部分的边界,这带来了引入多个更改的风险。
结论
编写基准。
花时间去思考某个特定的代码是否会更快是没有意义的。 互联网上的信息,同事和其他人的判断,无论他们的权威性如何,都可以作为辅助性论据,但首席法官在决定是否要使用新算法方面的作用应由基准保持。
乍看之下,Go只是一种相当简单的语言。 综合的80⁄20规则在此处适用。 这20%代表了语言内部结构的精妙之处,其知识将新手与有经验的开发人员区分开。 编写基准解决问题的实践是获得答案并更深入了解Go语言内部结构和原理的最便宜,最有效的方法之一。