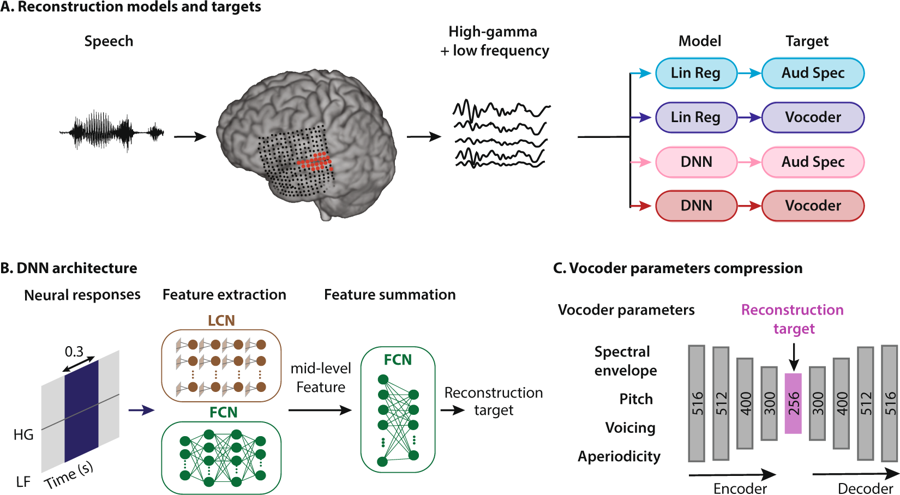
 语音重建方法的方案。 一个人听单词,结果是听觉皮层的神经元被激活。 数据以四种方式解释:通过结合两种类型的回归模型和两种类型的语音表示,然后它们进入神经网络系统以提取特征,这些特征随后用于配置声码器参数
语音重建方法的方案。 一个人听单词,结果是听觉皮层的神经元被激活。 数据以四种方式解释:通过结合两种类型的回归模型和两种类型的语音表示,然后它们进入神经网络系统以提取特征,这些特征随后用于配置声码器参数美国哥伦比亚大学的神经工程师是世界上第一个
创建将人类思想转换为可以理解的,可区分的语音
的系统的人,这是由大脑活动合成
的单词 (mp3)的
录音 。
通过观察听觉皮层中的活动,系统以前所未有的清晰度恢复了人们听到的单词。 当然,这不是字面意义上的思想评分,而是朝着这个方向迈出了重要一步。 的确,当一个人想象自己正在听语音时,或者当他在头脑中说话时,大脑皮层中也会发生类似的大脑活动模式。
使用人工智能技术的这一科学突破使我们更接近创建将计算机直接连接到大脑的有效神经接口。 它还将帮助不会说话的人,因中风或其他原因暂时或持续无法说话的人。
数十年的研究证明,在说话甚至是心理说话的过程中,活动的控制方式出现在大脑中。 另外,当我们听某人或想象我们正在听时,会出现一个独特的(可识别的)信号模式。 长期以来,专家们一直在尝试记录和破译这些模式,以从头骨中“解放”一个人的思想,并自动将其转换为口头形式。
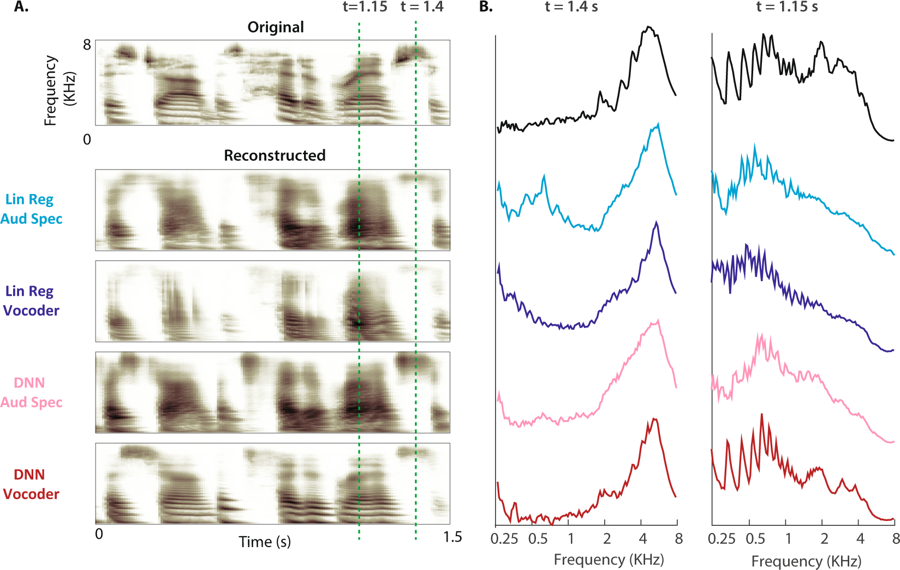 (A)语音样本的原始声谱图如上所示。 四个模型的重建听觉频谱图如下所示。 (B)清音(t = 1.4 s)和浊音(t = 1.15 s:原始频谱图和四次重构的虚线所示的频段)的幅度功率
(A)语音样本的原始声谱图如上所示。 四个模型的重建听觉频谱图如下所示。 (B)清音(t = 1.4 s)和浊音(t = 1.15 s:原始频谱图和四次重构的虚线所示的频段)的幅度功率该论文的主要作者尼玛·梅斯加拉尼(Nima Mesgarani)博士
解释说: “这与Amazon Echo和Apple Siri口头回答我们的问题所使用的技术相同。” 为了教声码器解释大脑活动,专家们发现了五名已经接受过脑外科手术治疗的癫痫患者。 他们被要求听不同人的句子,而电极则测量大脑活动,这是由四个模型处理的。 这些神经模式教声码器。 然后,研究人员要求相同的患者听说话者如何发音从0到9的数字,记录可以通过声码器传递的大脑信号。 由声码器响应这些信号而产生的声音被几个神经网络分析和清除。
作为在神经网络输出处进行处理的结果,收到了机器人语音,并发出了一系列数字。 为了测试识别的准确性,人们听了他们自己大脑活动合成的声音:“我们发现人们可以在75%的情况下理解并重复声音,这要高得多,而且超过了以前的任何尝试,” Mesgarani博士说。
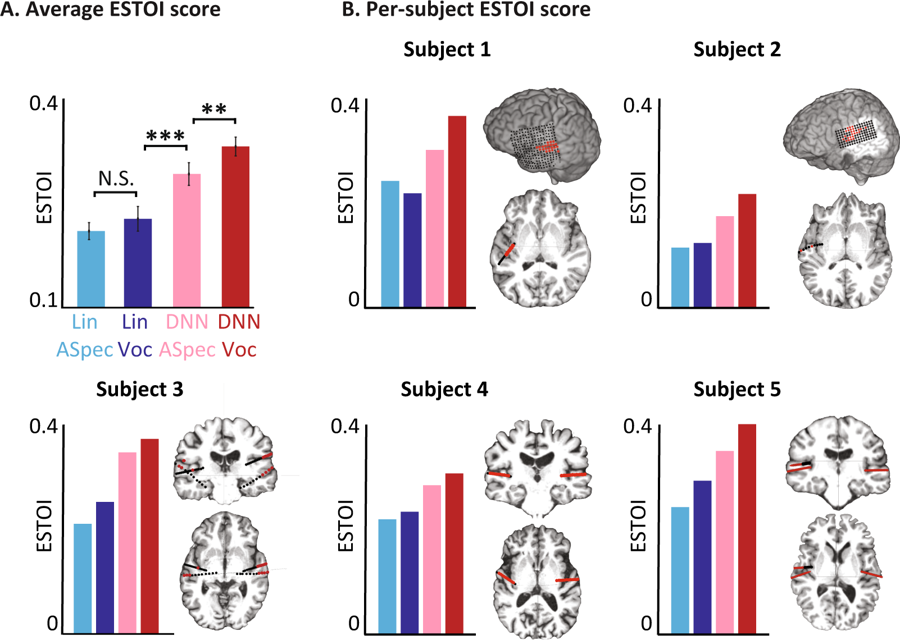 不同型号的客观评价。 (A)四个模型的所有受试者的平均ESTOI分数 。 B)五个人中每个人的电极覆盖范围和位置以及ESTOI分数。 每个人对于DNN声码器的ESTOI得分都比其他型号更高。
不同型号的客观评价。 (A)四个模型的所有受试者的平均ESTOI分数 。 B)五个人中每个人的电极覆盖范围和位置以及ESTOI分数。 每个人对于DNN声码器的ESTOI得分都比其他型号更高。现在,科学家计划用更复杂的单词和句子来重复该实验。 此外,当一个人想象自己在说什么时,同样的测试将针对大脑信号进行。 最终,他们希望该系统成为植入物的一部分,从而将佩戴者的思想直接转化为文字。
该科学文章于2019年1月29日在公共领域的《
科学报告 》杂志上发表(doi:10.1038 / s41598-018-37359-z)。
用于进行语音分析,计算高频振幅和重建听觉频谱图的程序代码已
公开可用 。