
大家好
在实际实践中,您经常遇到的任务远非复杂的ML算法,但同时对企业而言同样重要且紧迫。
让我们谈一谈。
任务归结为将某些目标表的数据与更详细粒度的表中的汇总(汇总值)一起分发(锯切,花样繁多,这是企业的用语不竭)。
例如,商务部门需要分解在品牌一级商定的年度计划-产品的详细信息,以供营销人员按国家细分年度营销预算,计划和经济部门按财务责任中心分解一般业务支出等。 等
如果您觉得这样的任务已经迫在眉睫,或者已经在对待那些遭受此类任务折磨的人,那么我请一只猫。
考虑一个真实的例子:
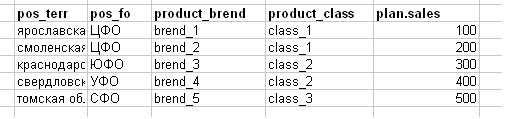
他们降低了销售计划,如下图所示(实际上,我故意简化了示例-100-200 mb excel横幅)。
标题说明:
- 插座的pos_terr-territory(区域)
- pos_fo-网点的联邦区(例如,中央联邦区-中央联邦区)
- product_brend-产品品牌
- product_class-产品类别
- plan.sales是任何产品的销售计划。
他们要求,例如,打破他们的超级表(在我们孩子的榜样的框架内,当然是比较温和的)-进入销售渠道。 问题是-根据分解的逻辑,我得到了答案:“但要获取当年第4季度和该年第4季度的实际销售统计数据,以计划的每一行来获取渠道的实际份额(%)并分解计划的这部分内容。''
实际上,这是此类任务中最常见的答案...
到目前为止,一切似乎都很简单。
我得到这个事实(请参见下图):
- pos_channell-销售渠道(计划的目标属性)
- fact.sales-某物的实际销售额。
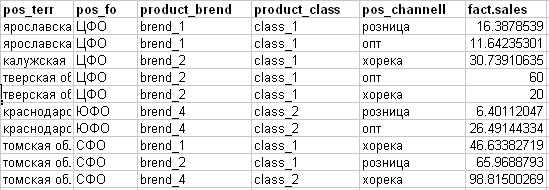
基于在计划第一行的示例中获得的“锯切”方法,我们将基于以下事实将其分解:

但是,如果我们将事实与整个板块的计划进行比较以了解计划的所有行是否都可以适当地“削减”,我们将得到以下图片:(绿色-计划行的所有属性与事实相符,黄色单元格不匹配)。
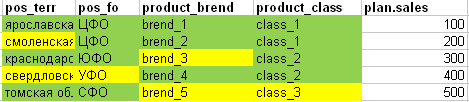
- 在计划的第一行中,事实中完全找到了所有字段。
- 在计划的第二行中,事实中未找到相应的区域
- 该计划的第三行实际上是品牌不足的
- 实际上,该计划的第4行还不够领土和联邦区
- 该计划的第五行实际上缺乏品牌和级别。
正如帕尼科夫斯基所说:“看见了修罗,看见了-他们是金子……”

我去找商业客户,并在第二行的例子中进行说明,他对这种情况有什么看法?
我得到的答案是:“在无法计算斯摩棱斯克地区第二品牌的渠道份额的情况下(考虑到我们在中央联邦区-中央联邦区拥有斯摩棱斯克地区这一事实,然后根据整个中央联邦区的渠道结构打破这一界限!”
也就是说,对于{斯摩棱斯克地区+ brand_2},我们在中央联邦区一级汇总事实,并拆分斯摩棱斯克地区,如下所示:

回过头来,总结一下我所听到的,我尝试归纳为更普遍的启发式方法:
如果在事实表的当前详细级别上没有数据,则在计算目标字段(销售渠道)的份额之前,我们将事实表汇总到上面的层次结构属性。
也就是说,如果不是针对该领土,则我们将事实汇总到更高的层次结构级别-与计划中相同的中央联邦区所占的份额。 如果不是品牌,则在上面的层次结构中有一个产品类别-因此,我们重新计算相同类别的份额,依此类推。
即 我们在耦合字段上结合了计划和事实,并考虑了事实中的份额,并且在每次迭代时根据剩余的未分配计划,依次减少了耦合字段的组成。
某种数据分发模式已经在这里显现出来:
- 实际上,我们根据相应字段的完全一致来分发计划
- 我们得到了一个残破的计划(我们在中间结果中进行了累加)和一个残破的计划(并非所有行都匹配)
- 我们采取了不间断的计划并将其实际上划分为更高的层次结构级别(即,我们放弃了将这2个表耦合在一起的某个字段,并汇总了没有该字段的事实以计算份额)
- 我们得到了一个破损的计划(我们将其添加到中间结果中)和一个完整的计划(并非所有行都匹配)
- 我们重复相同的步骤,直到没有“未解决”的计划。
一般而言,没有人强迫我们仅在层次结构内一致地删除挂钩字段。 例如,我们已经从挂钩字段中删除了品牌和地区,并通过以下方式分配了剩余的计划:product_class(品牌之上的层次结构)+ Fed.krug(领域之上的层次结构)。 并且仍然获得了计划的一些未分配余额。
此外,我们可以从耦合字段中删除产品类别或联邦地区,例如 它们不再嵌入彼此的层次结构中。
考虑到此类表中有数十行字段-多达一百万个用您的双手进行此类操作-这项任务并不是最令人愉快的。
鉴于此类任务是在每年年底定期向我提出的(董事会批准下一年度的预算),因此您必须将此流程转换为某种灵活的通用模板。
而且由于大多数时候我都是通过R处理数据的,因此实现也相同。
首先,我们需要编写一个通用魔术函数,该函数将带有一个基础表(basetab)和一个细分数据(在我们的示例中为一个计划),以及一个用于计算份额的表(sharetab),基于此我们将“看到”数据(在我们的示例中,事实)。 但是该函数还必须了解这些对象需要做什么,因此该函数还将接受耦合字段名称的向量(merge.vrs)-即 这些在两个表中都具有相同名称的字段,这将使我们能够将一个表与这些表在其工作的地方(即右联接)连接起来。 此外,函数还应了解应将基本表的哪一列计入分布(basetab.value),并根据哪个字段计算份额(sharetab.value)。 好了,最重要的是-对于结果字段(sharetab.targetvars)采取什么措施,在我们的案例中,我们希望通过事实从销售渠道详细计划。
顺便说一句,这个变量sharetab.targetvars在我的复数中不是随机的-它可能不是一个字段而是字段名称的向量,在某些情况下,您不需要一次从共享表向基本表中添加一个字段,而是一次添加多个字段(例如,基于事实,您不能拆分计划(不仅通过销售渠道,而且还通过品牌中包含的产品名称)。
是的,还有一个条件:)我的函数应该尽可能地具有局部性和可读性,并且在两个屏幕上都没有任何多层建筑物(我真的不喜欢大型函数)。
在最后一种情况下,流行的dplyr软件包尽可能舒适地安装,并且考虑到其管道运算符必须了解已归类到该函数中的字段的文本名称,因此,如果没有
Standart评估 ,就无法做到这一点。
这是这个孩子(不包括内部评论):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
在输出处,该函数应返回两个表的并集的data.frame,其中有计划的行+事实,可以在当前版本的耦合字段上拆分计划,而计划的原始行(以及空事实)则在当前迭代中无法拆分计划的行中。
也就是说,函数在第一次迭代(中断Yaroslavl地区计划的第一行)之后返回的结果将如下所示:
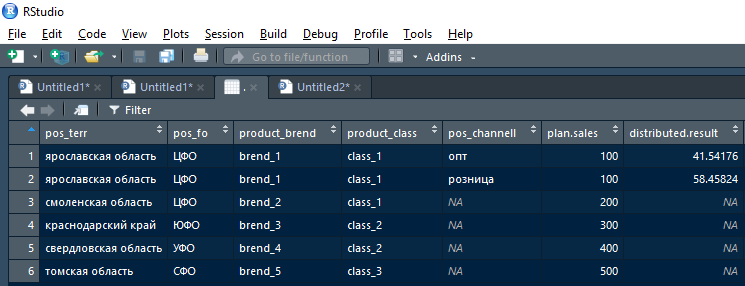
此外,此结果可以通过非空的distributed.result取到累积结果中,也可以通过空的(NA)distributed.result取到—发送到下一个典型的迭代,但按较高层次结构的份额进行分解。
所有的魅力和便利之处在于,工作是在相同类型的块和一个通用函数中完成的,每一步(迭代)所需要做的只是纠正merge.vrs向量并观察魔术如何为您完成所有这些繁琐的工作:

是的,我几乎忘记了一个细微的差别:如果出现问题,最终我们将得到一个破碎的计划,总的来说,该计划将不等于崩溃之前的计划-很难跟踪所有迭代在哪里出错。
因此,我们为每个迭代提供一个校验和:
(_)-(___ )-(___.)=0
现在,让我们尝试在分发模板中运行示例,并查看输出结果。
首先,获取源数据:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1.我们按Terr,FD(联邦区),品牌,类别进行分销 merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2.我们按照pho,品牌,类别进行分配(也就是说,我们实际上放弃了领土)
2.我们按照pho,品牌,类别进行分配(也就是说,我们实际上放弃了领土)与第一个块的唯一区别是,通过删除其中的pos_terr,它们略微缩短了merge.fields
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3.按班级分配pho merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4.按班级分配 merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. FD派发
5. FD派发 merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
如您所见,这里没有“未锯”的计划,而分布式计划的算法与原始计划相同。

这是销售渠道的结果(在右列中,该函数显示了耦合/聚合的作用域,以便稍后我们可以了解这种分布的来源):

仅此而已。 这篇文章不是很小,但是比代码本身有更多的解释性文字。
我希望这种灵活的方法不仅可以节省时间和精力:-)
谢谢您的关注。