哈勃!
曾几何时,一部手机的价格为2000美元,通话一分钟的价格为50美分,这是很流行的事情,例如寻呼。 然后,连接变得便宜了,寻呼机首先从商务人士的声望变成了快递员或秘书的声望,然后这种技术几乎完全消失了。
对于那些记得这个笑话的人来说,“阅读寻呼机,想了很多”,并想弄清楚它是如何工作的,继续进行下去。 对于那些想进一步了解的人,可以使用
第二部分 。
一般资讯
对于那些在2000年代之后忘记或出生的人,我将简要回顾其主要思想。
从用户的角度来看,分页通信具有两个大优点,在某些情况下仍然有意义:
-通信是单向的,没有任何确认,因此不可能使寻呼网络过载,其性能不取决于用户数。 消息仅按“原样”顺序广播,如果接收方号码与寻呼机号码匹配,则寻呼机接收消息。
-接收设备非常简单,因此寻呼机可以工作,而无需用两节普通AA电池充电长达一个月。
发送消息有两个主要标准
-POCSAG (邮局代码标准化顾问组)和
FLEX 。 标准不是什么新标准,POCSAG早在1982年就获得批准,支持512、1200和2400 bit / s的速度。 对于传输,使用频率间隔为4.5KHz的频移键控(FSK)。 较新的FLEX标准(由Motorola在90年代提出)支持最高6400 bps的速度,不仅可以使用FSK2,而且可以使用FSK4。
这些协议从本质上讲非常简单,并且为它们编写了解码器,这些解码器可以解密声卡输入中的信号(不提供消息加密,原则上任何人都可以用这样的程序读取它们)。
让我们看看它是如何工作的。
接收信号
首先,我们需要一个样本进行解码。 我们拿一台笔记本电脑,一台rtl-sdr接收器,一台时间机器,然后接收所需的信号。
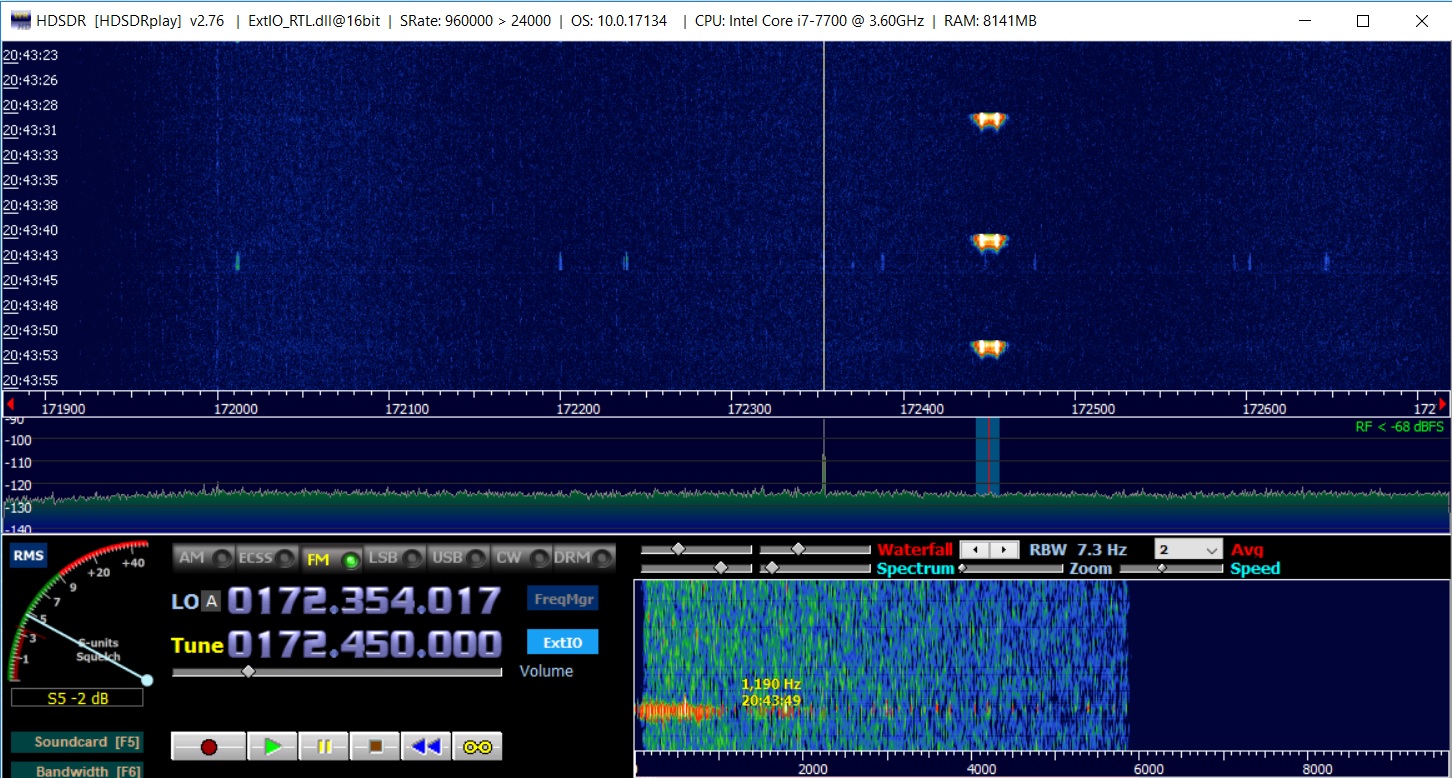
因为 调频,接收模式也设置FM。 使用HDSDR,我们以WAV格式记录信号。
让我们看看我们得到了什么。 使用Python将wav文件下载为数组:
from scipy.io import wavfile import matplotlib.pyplot as plt fs, data = wavfile.read("pocsag.wav") plt.plot(data) plt.show()
结果(位手动签名):

如您所见,一切都很简单,甚至在Paint中“肉眼可见”,您都可以在“ 0”和“ 1”处绘制位。 但是要对整个文件执行此操作将太长,该过程需要自动化。
如果增加图表,则可以看到每个“位”的宽度为20个样本,在wav文件的采样频率为24000个样本/秒的情况下,对应的速度为1200个比特/秒。 我们在信号中找到从零过渡的位置-这将是比特序列的开始。 我们将在屏幕上显示标记以检查位是否匹配。
speed = 1200 fs = 24000 cnt = int(fs/speed) start = 0 for p in range(2*cnt): if data[p] < - 50 and data[p+1] > 50: start = p break
如您所见,匹配并不完美(发射器和接收器的频率仍然略有不同),但足以进行解码。

对于长信号,必须引入频率调整算法,但是在这种情况下不需要。
最后一步是将数组从wav转换为位序列。 这里的一切也很简单,我们已经知道一位的长度,如果该时间段的数据为正,则加“ 1”,否则加“ 0”(编辑-事实证明,信号需要反转,所以0和1反转了)。
bits_str = "" for p in range(0, data.size - cnt, cnt): s = 0 for p1 in range(p, p+cnt): s += data[p] bits_str += "1" if s < 0 else "0" print("Bits") print(bits_str)
也许可以通过放弃循环来优化代码,尽管在这种情况下它并不重要。
结果是完成的位序列(作为字符串)保存了我们的消息。
10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010010101010101
010101010101010101010101010101010101010101010101010100111110011010010000101001101101
100001111010100010011100000110010111011110101000100111000001100101110111101
01000100111000001100101110111101010001001110000011001011101111010101000100111
000001100101110111101010001001110000011001011101111010100010011100000110010
011011110101000100111000001100101110111101010001001110000011001011101111010
100010011100000110010111011111110101000100111000001100101110111101010001001110
...
111101111解码方式
比特序列比仅仅是wav文件要方便得多;您已经可以从其中提取任何数据。 我们将文件分成4个字节的块,并获得一个更易理解的序列:
1010101010101010101010101010101001010
1010101010101010101010101010101001010
1010101010101010101010101010101001010
1010101010101010101010101010101001010
011111001101001000010110110110001000
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
00001000011011110100010001101000
10000011010000010101010011010100
011111001101001000010101110110001000
11110101010001000001000000111000
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
00100101101001011010010100101111这就是我们可以从文件中提取的全部内容,仍然需要了解这些行的含义。 打开该格式的文档,该文档以
PDF格式提供 。
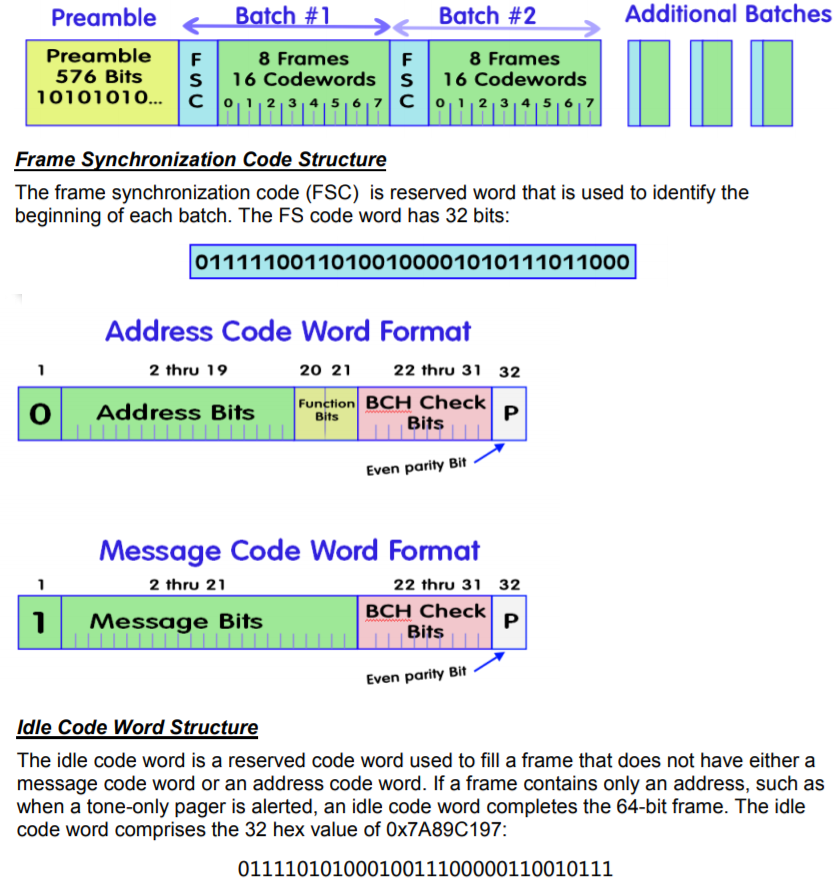
一切都差不多了。 消息标题由一个长块“ 10101010101”组成,需要此块,以便寻呼机退出“睡眠模式”。 消息本身由Batch-1 ... Batch-N块组成,每个块均以唯一的FSC序列(在文本中以粗体突出显示)开头。 此外,从手册中可以看出,如果该行以“ 0”开头,则这是收件人的地址。 该地址被连接到寻呼机本身,如果不匹配,则寻呼机将简单地忽略该消息。 如果该行以“ 1”开头,则实际上是一条消息。 我们有两条这样的线。
现在查看每个块。 我们看到空闲代码-空块01111 ... 0111没有携带有用的信息。 我们删除了它们,只剩下很少的信息了,剩下的一切:
01111100110100100001010011011000-帧同步
00001000011011110100010001101000-地址
10000011010000010101010011010100-消息
01111100110100100001010111011000-帧同步
11110101010001000001000000111000-消息
00100101101001011010010100101111-地址仍然需要了解里面的东西。
我们在手册中进一步查找,发现消息可以是数字或文本。 数字消息以4位BCD码的形式存储,这意味着5个字符可以容纳20位(仍有控制位,我们将不考虑它们)。 该消息也可以是文本,在这种情况下,使用7位编码,但是对于文本,我们的消息太小-消息位的总数不是7的倍数。
从字符串10000011010000010101010011010100和11110101010001000001000000111000得到以下4位序列:
1 0000 0110 1000 0010 10101 0011010100-0h 6h 8h 2h Ah
1 1110 1010 1000 1000 00100 0000111000 -Eh Ah 8h 8h 2h
最后,最后一步-我们在文档中查看字符对应表。

如您所见,数字消息只能包含数字0–9,字母U(“ ugrent”),空格和一对方括号。 我们编写了一个简单的输出函数,以免手动读取它们:
def parse_msg(block):
结果,我们得到了发送的消息“ 0682 *)* 882”。 很难说出它的含义,但是由于该格式支持数字消息,因此可能有人需要它。
结论
如您所见,POCSAG格式非常简单,实际上,甚至可以在学校笔记本中对其进行解码。 尽管现在它具有相当大的历史意义,但是从认知的角度分析此类协议非常有用。
下一节描述解码ASCII消息。