抒情介绍
一个晚上,我把东西整理在壁橱里,偶然发现一个大纸箱。 她在两次搬迁中幸存下来,而且没有开门这么多年,以至于我完全忘记了里面存放的东西。 原来,有照片-在相册中,在商店的信封中,有些就是这样。
许多照片是在七十多年前拍摄的。 一个是祖父-在他的学生时代,还年轻又英俊,戴着绝对
具有破坏性的眼镜。 “哇,我的祖父甚至在成为主流之前就穿时髦的衣服,”我想着,不由自主地笑了。 我立刻认出了他,但随后走了我不记得任何人的照片。 在面部特征中,您可以隐约猜测出这种关系-就是这样。

我15岁那年,祖母反复出示这些卡片,并谈论其中所描绘的人物。 不幸的是,只有当没有人告诉他们时,才了解这种故事的价值。 那时,第十次听我一些关于战前生苔的故事对我来说绝对是没有意思的,我挥舞着他们,让他们耳目一新。 现在,突然间,我完全意识到自己的一部分家庭历史已不可挽回地丢失了,我想到了系统化并保留剩下的东西的想法。
在我看来,存储家庭数据的理想解决方案似乎是Wiki引擎和相册的混合体。 没有现成的合适解决方案,因此我必须编写自己的解决方案。 它被称为
Bonsai ,在MIT许可下是开源的。 然后会有一个关于它的组织方式和使用方法的故事,以及它的发展和一些
DRAMA的故事。

另一辆自行车?
如今,有很多工具可让您制作家谱和有关亲戚的目录信息。 有条件地将它们分为两大类-在线服务和桌面应用程序。
对于桌面应用程序,数据库通常以文件形式存储在磁盘上。 您打开该应用程序并以单用户模式对其进行补充。 如有必要,可以导出数据以进行备份或传输到另一个系统(例如,以
GEDCOM格式)。 在我所观看的影片中,最有趣的使用似乎是
Gramps (免费)和家庭
Life Tree (需要一次性购买)。
网络服务的另一面。 他们将您的数据存储在远程服务器上,并收取定期使用费。 由于这是具有集中基础和良好货币化的商业产品,因此该计划的服务使您有机会例如通过DNA测试或档案记录来寻找失散的亲属。
两种选择的优缺点都非常明显。 在第一种情况下,您将数据库存储在本地,并完全控制对数据库的访问和备份的创建。 如果应用程序是开源的,则如有必要,您甚至可以为其添加其他功能。 但是,很难一起使用这样的数据库或查看来自另一设备的数据。 相反,在第二种方法中,可以从任何设备进行访问,但是您可以将数据提供给第三方并希望它们具有良好的外观。 在我的家庭历史上,没有妥协和可怕的秘密,但是,我仍然认为此信息纯粹是个人信息,原则上,我不希望任何人存储或分析该信息。
鉴于这两种方法的缺点,我们可以制定“理想”引擎的要求列表:
- 托管在您自己的服务器上的Web应用程序
- 创建有关人,宠物,地点,事件等的文章。 像维基
- 下载媒体
- 照片和视频中的人物标记
- 自动家谱建设
- 具有所有重要日期的日历。
- 共同编辑和填写的工具
公平地说,我设法找到了几个具有自托管实现的项目,但是它们处于令人沮丧的状态:在2000年中期,外观冻结了,没有完整的必需功能集,但是我不想深入研究PHP中的旧脚本。 此外,以前的宠物项目已经结束,因此有一种尝试新事物的愿望。
黄金法则说:
如果您想做得好-自己动手!使用的技术是根据三个标准选择的:我对它们的经验,知名度和开放性。 结果如下:
- Rantime :.NET Core 2.1
- 后端 :ASP.NET Core MVC
- 数据库 :PostgreSQL
- 前端逻辑 :部分为Vue,部分为jQuery。
- 前端样式 :Bootstrap + Sass
支持角色包括用于全文搜索的Elasticsearch和用于从视频截屏的ffmpeg。
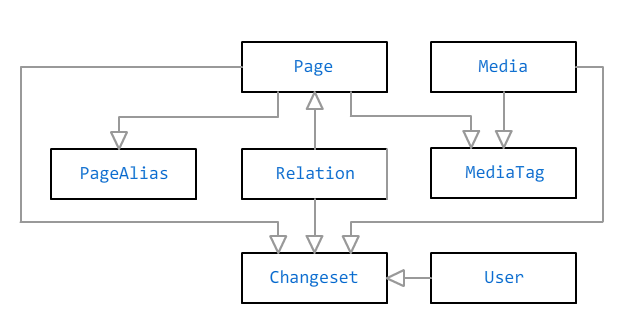
数据模式
盆景数据库中的主要对象是
页面和
媒体文件 。 它们通过
标记通过多对多关系连接在一起。 标签可以具有不带链接的标题-例如,如果您需要在照片中为某人添加标签,则整页上没有关于它的信息。
除自由文本外,该页面还可能包含在管理面板的特殊字段中输入的
事实 。 其他事实是根据事实计算得出的:例如,如果您指明此人的出生日期,则将其标记在日历上,并且他的页面将显示当前年龄(或预期寿命,如果还标明了死亡日期),则性别可用于确定关系的正确名称(“父亲” “或”母亲”代替普通的“父母”),等等。 事实作为JSON文档存储在数据库中。
有五种类型的页面可供选择:人物,宠物,事件,地点等。 可用事实的列表取决于页面的类型:例如,“教育”仅与一个人相关,“出生日期”(与一个人和动物有关),“地址”(仅与某个地方有关)。
页面之间通过
关系相互
关联 :“父母”,“配偶”,“朋友”,“所有者”,“居民”和许多其他关系。 某些关系可能会受到时间限制(配偶,所有者,居民),而其他关系则被认为是永久的。
保存任何页面或关系时,将检查结果模型的一致性。 例如,
配偶的寿命必须重叠 ,每个人的性别不能超过一个亲生父母,您也不能
成为自己的父亲 。 但是,同性婚姻是允许的。
编辑页面,媒体文件或关系会将
更改保存到数据库。 这使您可以保存编辑的历史记录,并在必要时将其回滚。
关系
亲属关系是社会上最古老的观念之一。
在前印欧语系中已经有许多名称,这些名称经过稍加修改后又迁移到各个群体的现代语言中:“母亲”一词将以俄语,英语和汉语来理解。
亲属关系有很多选择,但基本选择是三个:
父母 ,
子女和
配偶 。 它们使您可以从家庭建立有向图,其中这些关系是边,人是节点。 在此列上,您可以表达任何其他关系,知道参与者与他们的性别之间的关系:例如,要确定某人的祖父,您必须先找到其父母(任何性别),然后再找到该父母的父母(男性),依此类推。
在“盆景”管理面板中,您可以输入这三种基本类型的关系。 将自动为每个关系创建相反的关系-父母为孩子,配偶为配偶,所有者为宠物。 所有其他关系均由引擎计算,并显示在页面的侧栏上:
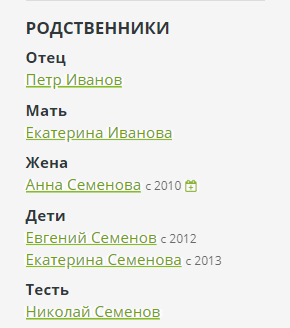
要计算关系,将使用基本图遍历,并以特殊的DSL形式设置关系名称:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
甚至一个人也可以有
很多直接的亲戚。 盆景将链接分为以下几组:
- 最亲密的血缘关系是这个人成长的家庭:母亲和父亲,祖父母,兄弟姐妹。 如果您查看该图,则这是1-2向上的路径和1的横向路径。
- 自己的家庭 :每个配偶和他的孩子一个小组。 这还包括配偶的亲戚-岳母,brother子等。
- 其他 :较远的亲戚(孙子,叔叔,阿姨)和非亲属关系(朋友,同事)。
有时,确定组成员身份的一种方法还不够。 数据可能不完整,但是仍然需要尽可能充分地显示它们。 考虑以下同级图:
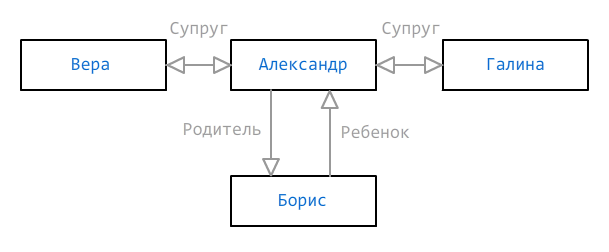
正如我们所看到的,亚历山大指示了两个妻子(Vera和Galina)和一个儿子(Boris),但我们不知道哪个妻子是孩子的母亲-也许这是第三种女人,但尚未添加。 在这种情况下,可能会指示应该存在或不存在的若干路径,并且分别用
+和
-标记它们:
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
家谱
任何体面的族谱引擎都应该能够建立家谱。 这是显示有关人及其家庭关系的一般信息的最直观的方式。 数据以有向图的形式存储在数据库中,从理论上讲,它应该易于可视化。 实际上,大多数困难都是通过树的显示而出现的。
以下是家谱可能的一些示例:

Targaryenov的家谱。 非常紧凑,因为它是手工制作的。 从任意数据自动生成这样的树将非常困难。
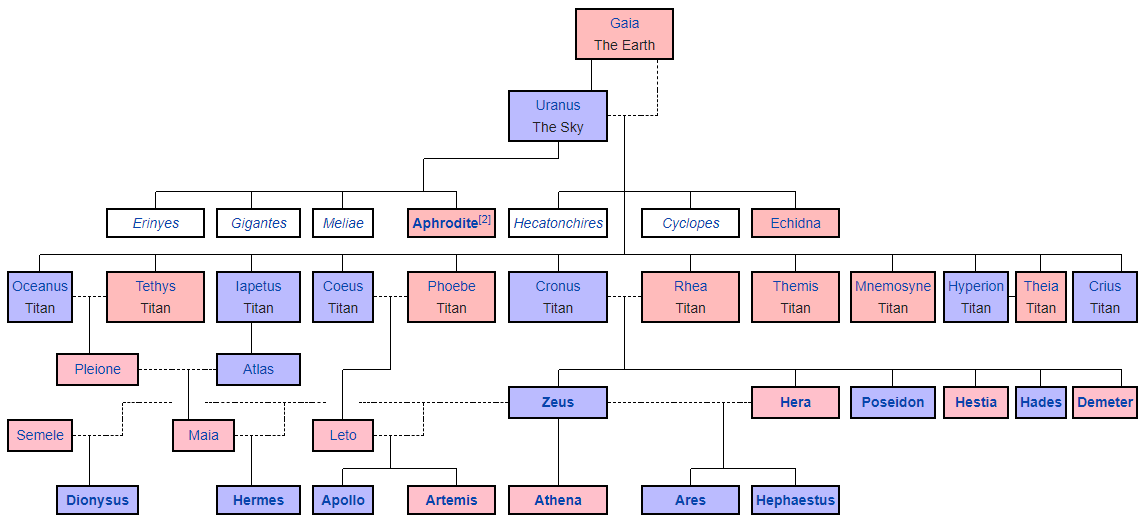
希腊诸神。 图形表示法是通过
特殊的markdown语法生成的,在该
语法中,您仍然需要手动排列所有块并绘制它们之间的链接。 有点像ASCII艺术。

以半圆图的形式表示树。 易于自动生成,但仅考虑直接祖先。
我浏览了许多选项。 最美观的是在MyHeritage网站上:
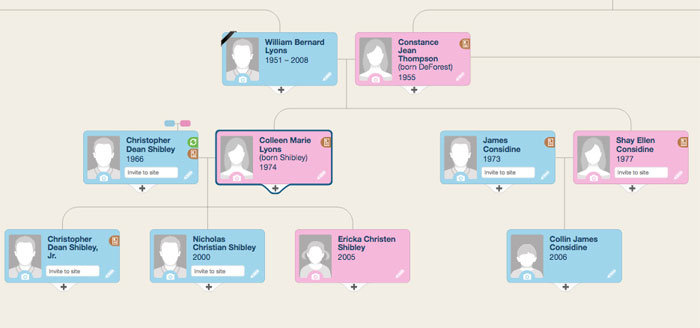
这样一棵树的渲染可以分为三个条件步骤:从数据库中获取数据,排列块/连接线以及直接在页面上显示它们。 如果第一步和第三步都很琐碎,那么在第二步中,我跌跌撞撞。
匆忙投掷自制解决方案的尝试以惨败告终。 图形元素的有效排列是如此复杂,以至于在其
上写有
论文 ,并且
完成的组件就像是莫斯科的公寓。 好的,您将无法编写自己的文字,但是肯定有不错的免费解决方案吗?
我的大部分希望都在
D3.js库中 。 如果您需要在网页上绘制图形或图表,这可能是第一件事。 las,在Wiki上的三百多个示例中,没有多少与MyHeritage的树相似。
下一步是深入研究不涉及渲染但用于计算图形中元素的最佳排列的库。 它们中的大多数提供了所谓的“
力”布局 。 这是一个非常简单的方法,它基于物理公式:图形的节点由弹性体表示,连接线由弹簧表示。 它的特征动画可以很容易地识别它-图形似乎在旅途中“变直”,这不是一个附加功能,而是算法仿真性质的必然结果。 强制布局方法适用于在没有清晰层次结构(例如社交网络中的连接)的情况下可视化数据,但是这种形式的家谱看起来有缺陷。
考虑的另一个选项是
Graphviz库。 她的工作成果可以通过特征箭头轻松识别。 特殊语言
DOT用于描述图形。 测试用例看起来或多或少,但是实际数据会出现问题:箭头“折断”并以奇怪的角度连接,图形爬升,您无法进行调整,也就无法解决。
我自己没有找到合适的解决方案,所以我决定由自由职业者订购它,然后开始了
DRAMA 。
该订单于10月22日上午下达,一个小时之内收到了几封答复。 其中一位受访者叫弗拉迪斯拉夫(Vladislav); 他发送了一个类似解决方案的例子,并承诺在
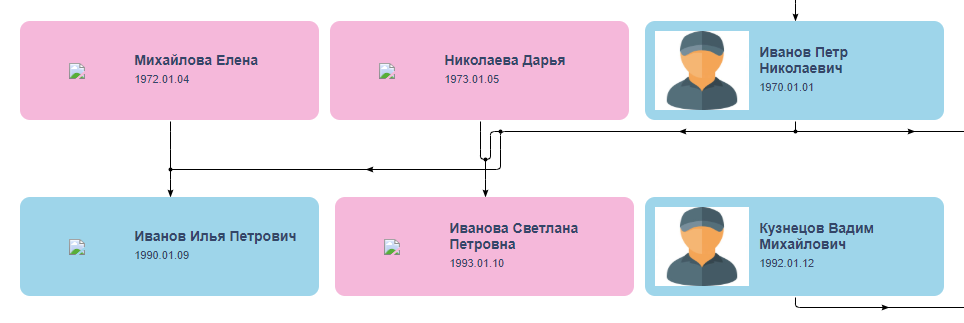
一天之内完成任务。 这个速度对我来说似乎令人怀疑,但是我希望他的经历和我自己给这个家伙一个星期的错误。 前几天,弗拉迪斯拉夫(Vladislav)提出了其他问题,但对项目的沉浸和对细节的专心致志让我惊讶不已,然后消失了。 他于11月1日醒来,由于家庭原因被迫失踪而道歉,并发送了一个Beta版本的链接,该链接看上去与他想要的(如果不是中心连接线中的节点的链接)相似:
表演者的失踪始终是一个警钟,但您永远不知道会发生什么,因为他做了什么。 让他继续! 我发送了预付款并开始等待改善。 几天后,弗拉迪斯拉夫(Vladislav)写道他无法解决问题,然后又消失了-这次是三个星期。 在此期间,他没有采取任何行动,也拒绝退还预付款,因为“这项任务实际上是由一个
愚蠢的前任朋友完成的,他让他失望了,却不还钱。” 在澄清了几个问题之后,不幸的代表停止了为自己辩解的想法,只是闭嘴。 因此,现在我们生活了-我定期提醒他欠债,并作为回应,他从银行应用程序发送了一个屏幕截图-他们说:“没有钱,但马上-马上就开始。” 我希望弗拉迪斯拉夫(Vladislav)在业务上取得成功,并迅速致富!
把孩子扔了-减去业力!亏钱不是那么烦人,但是一个月过去了,任务没有完成,现在没有地方可以等待帮助了。 首先,我对自己很生气:我走了阻力最小的道路,违反了
黄金法则 -这就是结果。 充满正义的愤怒,我再次坐下来研究图书馆来绘制图形,并且-看哪! -突然发现您真正需要的东西。
该库名为
Eclipse Layout Kernel ,缩写为ELK。 您可能会猜到,它用于在Eclipse IDE中显示图,但也可以自动使用。 通常,它是用Java编写的,但是有一个用JS广播的版本。 是的,她的代码是
一场噩梦 ,重达一个半兆字节,但是可以弥补这些缺点,因为它
可以正常工作并且可以正确地完成
工作 。 界面是基本的:节点,边线和设置被传输到输入,在输出处我们获得坐标。 您可以通过任何方便的方式使用它们来绘制树:我选择了SVG来连接具有绝对位置的块的线和div。
库的集成和最佳设置的选择花了两个晚上的时间。 当然,这并不是我不幸的和自负的自由职业者所承诺的“一天”,而是非常接近。 结果,盆景能够以以下形式显示树:
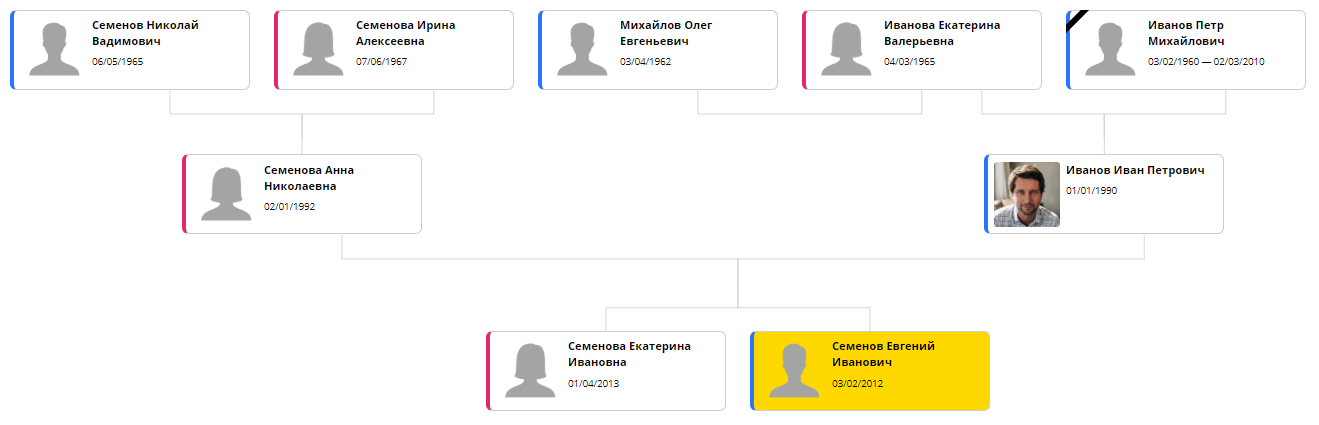
现在剩下的唯一问题是处理时间。 ELK使用迭代算法:您可以通过花费更多时间来接近最佳放置位置。 在20到30个元素的树上,一个好的结果大约需要5秒钟。 因此,长时间打开带有树的页面,然后它很快就变得烦人。 在下一个版本中,计算将被传输到后端,以便在更改页面和缓存时可以进行一次计算。
全文搜索
没有便利的全文搜索,用于存储文本信息的系统将毫无用处。 盆景使用PostgreSQL数据库,所以我决定的第一件事就是立即检查它可以提供什么。 另一个令人失望的地方:
tsvector处理普通单词,但拒绝搜索最重要的内容-名称和姓氏:
SELECT to_tsvector('') @@ to_tsquery(''),
Trigrams也没有带来任何好处。 最后,我确定了一个比较期望的选择:ElasticSearch +
Russian Morphology 。 事实证明,从.NET使用它非常不方便,但是,他可以用自己的全名搜索可靠的五个字符。
意识缺陷
在进行项目工作时,经常会发生
内部完美主义者对所选解决方案感到愤怒的情况。 主题领域是非标准的,并且普遍接受的“良好举止”并不总是有效。
例如,当我们打开任何页面时会发生什么?
- 页面文本从Markdown编译为HTML。 如果文本包含指向其他页面和媒体文件的链接,则必须转到数据库以获取更多信息。
- 在视图模型中,事实将从存储在数据库中的JSON反序列化。
- 关系确定。 为此,必须从长期遭受苦难的数据库中获取整个连接图,并根据先前已知的路径列表在其中找到节点。
乍一看,这似乎是一个非常困难的操作,但实际上并不是因为数据量相对较小。 您能记住多少亲戚并想写下来? 出于兴趣的缘故,请尝试重新叙述一下,发现拨打至少一百个电话非常困难。 还有多少人要授予访问权限? 对于一个家庭来说,即使是天文数字庞大的人口,也有数千人! -按照现代数据库的标准,它仍然很可笑。
当然,编译后的页面视图模型在第一次打开时仍会被缓存,并在后续模型中重用,这主要是因为它非常易于实现。 在管理面板中更改缓存无效的规则也尽可能地简单:如果我们仅更改文本和某些
本地事实(语言列表,血型,头发颜色等),则只需重置此特定页面即可。 进行任何其他更改(页面名称,出生日期或性别,添加或更改任何连接)后,缓存将
完全重置。 是的,这不是最聪明的清洁方法。 是的,可以肯定的是,您可以编写一个复杂的算法,该算法仅会重置您需要的内容,但是对于该项目,它并不能证明成本合理。
该项目不支持本地化和外观更改,在Facebook \ Google上的OAuth上可以进行授权,并且管理面板是按常规形式制作的,而不是某些基于最新时尚的SPA框架。 所有这些
都可以实现或改善,但是它并不能解决任何问题,因此会浪费时间。
展望未来
对引擎设备的复杂性进行投资毫无意义的另一个原因是,与存储的数据相比,实现的短暂性。 请想一想:当前形式的网络已经存在了将近20年,家族历史已经存在
了多个世纪 。 还没有人仅仅因为信息技术行业本身的存在而解决了这个问题。 该怎么办?
必须定期从头开始重写引擎-就像几千年来,和尚一直在努力将文本从残旧的书本复制到新书本上一样。 唯一的区别是,如果适当地处理和应用,该书可以说谎一百年-强度为15-20年。 我希望二十年后我仍然可以自己做,但是再过二十年,我的孩子或孙子将不得不去做。 我想给他们一个简单,易于理解和记录的资料。
在设计的最初阶段,我想在引擎中嵌入某种类似于SQL的语言,借助它我可以得到一些具体问题的答案:“祖先蓝眼睛的比例是多少? 必须放弃这个想法,因为它将要求以某种形式化的形式输入所有信息,而不是纯文本,并且仅需花费数年时间才能描述此类型。 另一方面,自然语言理解正在蓬勃发展。 如果在十到两年内可以要求Siri为您阅读文本,点击链接并提出事实摘录,我不会感到惊讶。 伙计们,推!
怎么尝试?
不幸的是,我无法提供指向完成的演示的链接:没有服务器可以承受habra效应。 但是有一些可视屏幕截图(图片是可单击的)。

如果Bonsai对您似乎有用,并且您想自己运行它,则可以从Github下载源代码:
https://github.com/impworks/bonsai自述文件中提供了详细的安装说明。 您将需要以下内容:
- .NET Core 2.1以上
- PostgreSQL 10+
- ElasticSearch 5.x和Russian Morphology插件
- 用于oAuth授权的Facebook或Google应用
首次启动后,将在数据库中创建几个测试页和照片。 对于生产而言,此行为不是必需的,并且会被设置中的标志禁用。
就在一个月前,我启动了自己的实例并开始运行它,以获取真实数据。 遇到一些粗糙度,但否则我对结果完全满意。 现在,该项目将逐步开发并完成。 主要任务是加速树的显示,允许以PDF格式下载文档并添加对访问权限的微调。 改善某些地方的管理面板的可用性或自动识别照片中的面孔会很好,
但这并不准确 。