哈勃!
在
第一部分中 ,考虑了POCSAG消息传递协议。 考虑了数字消息,现在我们将传递给ASCII格式的更多“成熟”消息。 此外,对它们进行解码更有趣,因为 输出将是可读文本。
对于那些对它如何工作感兴趣的人,继续进行下去。
信号接收
首先,必须接收信号,为此,我们使用相同的rtl-sdr接收器和HDSDR程序。 从第一部分我们已经知道寻呼消息可以是数字的(内容只有数字0-9,字母U是“ ugrent”,一个空格和一对方括号)和字母数字,内容是完整的ASCII字符。 自然,我们并不预先知道消息的类型(仍然无法通过“耳朵”对其进行解码),因此在录制时,我们只选择一条更真实的消息。
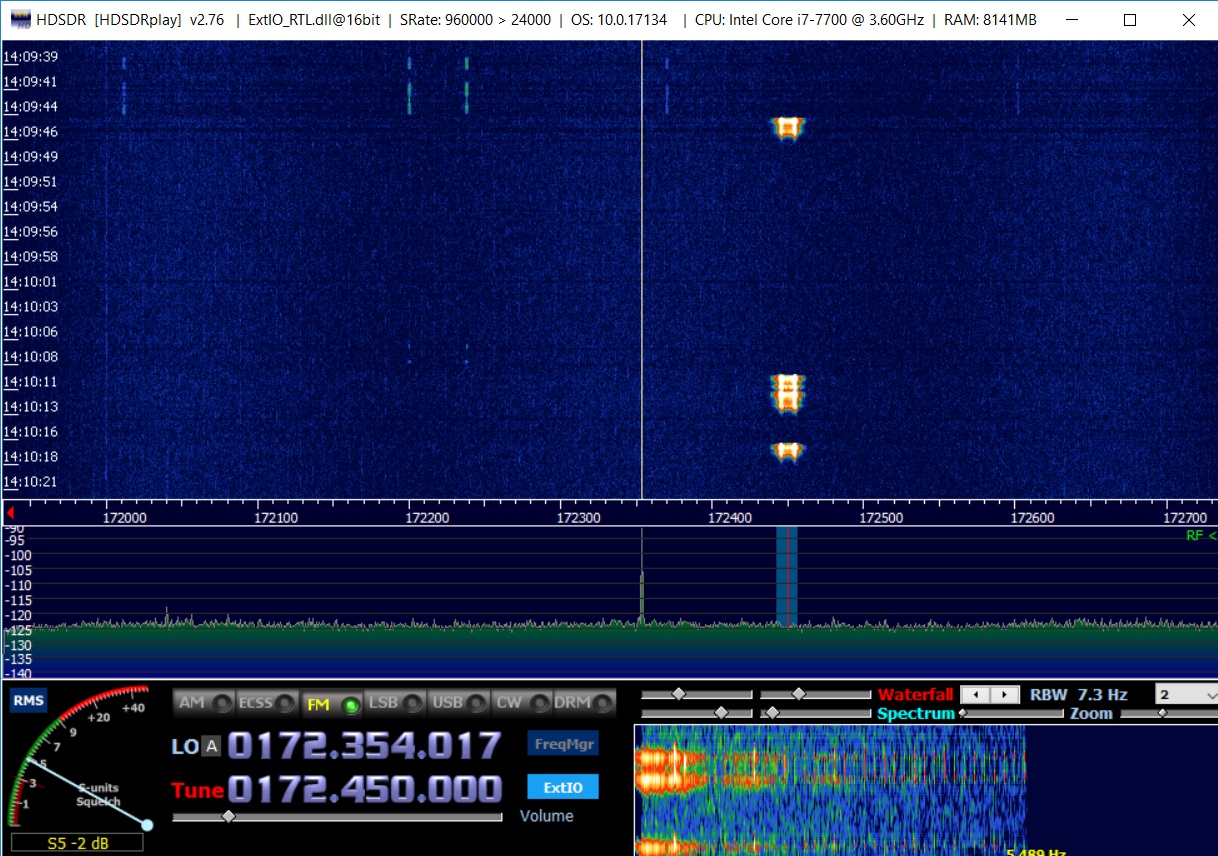
已经考虑过将wav文件转换为比特流的程序,因此请立即显示结果-整个分页消息如下所示:

一些功能可以用肉眼立即看到-例如,可以看到起始序列01010101010101重复了两次。 即 该消息不仅更长,而且基本上由两个“胶合”在一起组成,但是该标准并未禁止它。
解码方式
首先,请回顾
上一部分的简要内容。 寻呼消息以长标头0101010101开始,后跟图中所示为Batch1..N的“包”序列:
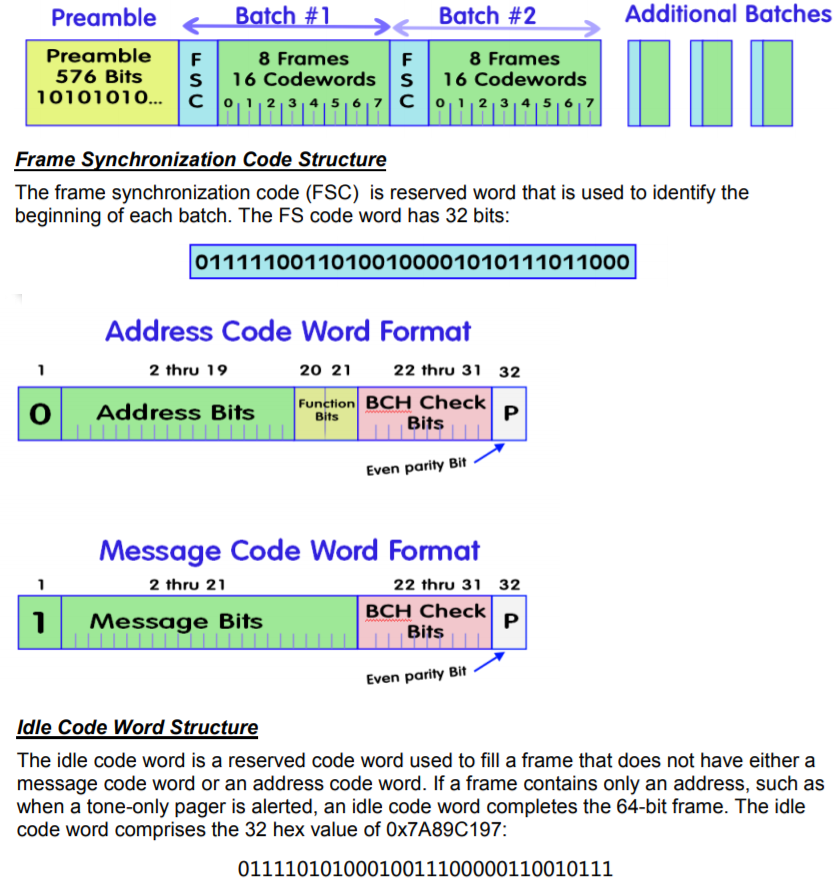
每个数据包均以帧同步码开始序列(01111100 ...)开头,后跟32位块。 每个块可以存储一个地址或一个消息正文。
上一次我们只看数字消息,现在对ASCII消息感兴趣。 首先,您需要学习如何区分它们。 为此,我们需要“功能位”字段-如果这2位为00,则消息为数字,如果为11,则为文本。
从图中可以看出,如果消息是数字的,则将20位分配给消息字段,这恰好适合5个4位BCD代码。 但是,如果消息是文本,那么很多文本就不能容纳20位,并且20不能被7或8分割。可以假设该协议的第一个版本(该协议是在1982年创建的)仅支持数字消息(
是而且,当年在数码管上的第一个传呼机不太可能显示更多 ),只有到那时,在下一个版本中,才添加了对ASCII的支持。 但是因为 不再可能违反格式标准,这更容易-比特流按原样简单组合(从每个消息中提取20位并添加到缓冲区的末尾),然后才将所有这些解码为字符。
考虑接收到的消息的一个块(为清楚起见添加了空格):
0 0001010011100010111111110010010 1 00010100000110110011 11100111001 1 01011010011001110100 01111011100 1 11010001110110100100 11011000100 1 11000001101000110100 10011110111 1 11100000010100011011 11101110000 1 00110010111011001101 10011011010 1 00011001011100010110 10011000010 1 10101100000010010101 10110000101 1 00010110111011001101 00000011011 1 10100101000000101000 11001010100 1 00111101010101101100 11011111010
在第一行中,第一位的“ 0”表示这是一个地址字段,而第20-21位的“ 11”表示此消息是符号消息。 接下来,只需从每行中取20位,然后将它们加在一起即可。
我们得到以下位序列:
00010100000110110011010110100110011101001101000111011010010011000001101000 11010011100000010100011011001100101110110011010001100101110001011010101100 000010010101000101101110110011011010010100000010100000111101010101101
POCSAG协议使用7位ASCII,因此只需将行分成7位的块即可:
0001010 0000110 1100110 1011010 0110011 1010011 ...
我们尝试对字符代码进行解码(在Internet上可以很容易地在ASCII表上搜索ASCII表),并且...我们在输出中得到了垃圾。 再次打开文档,找到一个微妙的短语“ ASCII字符从左到右放置(MSB到LSB)。 LSB首先发送。 即 首先,传输低位,然后传输高位-为了正确解码ASCII码,必须翻转7位字符串。
为了避免手动执行此操作,我们编写Python代码:
def parse_msg(block): msgs = "" for cw in range(16): cws = block[32 * cw:32 * (cw + 1)]
结果,我们得到以下序列(位,字符代码和字符本身):
0101000 40 ( 0110000 48 0 0110011 51 3 0101101 45 - 1100110 102 f 1100101 101 e 1100010 98 b 0101101 45 - 0110010 50 2 0110000 48 0 0110001 49 1 0111001 57 9 0100000 32 0110001 49 1 0110011 51 3 0111010 58 : 0110011 51 3 0110001 49 1 0111010 58 : 0110100 52 4 0110101 53 5 0100000 32 0101010 42 * 0110100 52 4 0110111 55 7 0110110 54 6 0101001 41 ) 0100000 32 1000001 65 A 1010111 87 W 1011010 90 Z
将字符组合在一起,得到以下行:“((03-feb-2019 13:31:45 * 476)AWZ”。 正如文章开头所承诺的,该文本可读性强。
顺便说一句,另一个有趣的地方是,如您所见,该协议使用7位ASCII。 西里尔字母不适合该范围,因此关于寻呼机如何闪烁俄语的问题仍然存在。 如果有人知道,请在评论中写。
结论
当然,协议还没有被完全理解,但是最有趣的部分已经完成,然后例程仍然存在,这不再那么有趣了。 至少没有对接收方地址(capcodes)进行解码,并且未实现对纠错码(BCH Check Bits)的支持-这将允许在传输过程中最多纠正2个“损坏”的位。 但是,目标并不是要制造出完整的解码器-已经有这样的解码器了,几乎不需要一个。
那些想尝试使用rtl-sdr解码消息的人可以使用免费的
PDW程序自己进行解码。 它不需要安装,在启动后,有必要使用虚拟音频电缆程序将HDSDR输出重定向到PDW输入,并在PDW音频设置中选择适当的设备。
程序的结果如下所示:
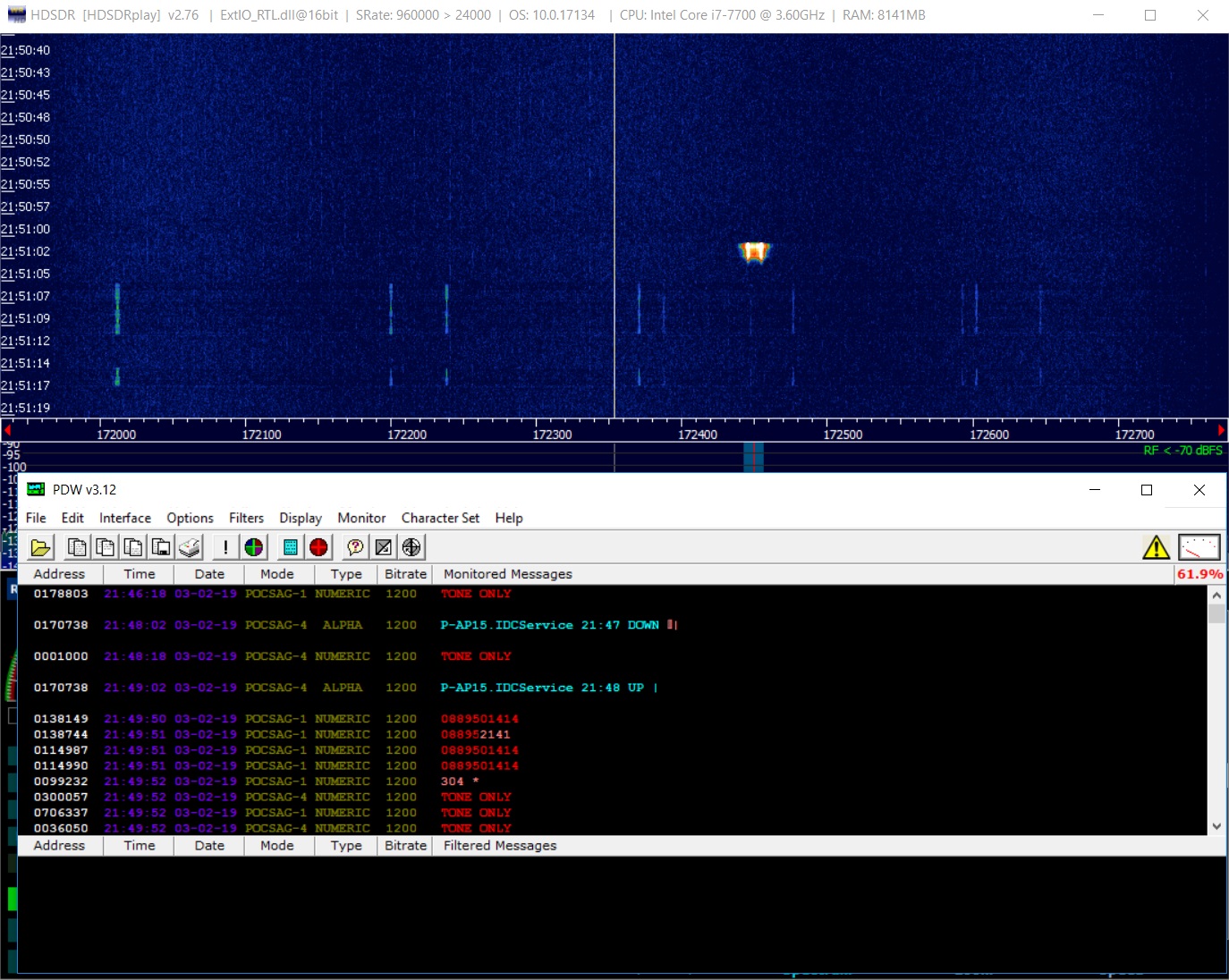
关于此主题,可以将寻呼消息视为已关闭。 那些想更详细地研究该主题的人可以研究
multimon-ng程序的源代码,该程序可以解码许多协议,包括POCSAG和FLEX。