
在上一篇文章中,我们讨论了诸如对抗性示例之类的机器学习问题以及使它们生成的某些类型的攻击。 本文将重点介绍这种效果的保护算法以及对测试模型的建议。
防护等级
首先,让我们立即解释一个观点-不可能完全抵御这种影响,这很自然。 确实,如果我们完全解决了对抗性示例的问题,那么我们将同时解决构造理想的超平面的问题,当然,如果没有通用数据集,这是无法完成的。
捍卫机器学习模型有两个阶段:
学习 -我们讲授我们的算法以正确应对对抗性例子。
操作 -我们正在尝试在模型的操作阶段检测一个对抗性示例。
值得一提的是,您可以使用IBM的Adversarial Robustness Toolbox使用本文介绍的保护方法。
对抗训练

如果您用示例向刚接触对抗问题的人提出问题:“如何保护自己免受这种影响?”,那么,十个人中有九个人会说:“让我们将生成的对象添加到训练集中”。 早在2013年,在《 吸引人的神经网络的属性 》一文中立即提出了这种方法。 正是在本文中,首先描述了此问题以及L-BFGS攻击,该攻击允许接收对抗性示例。
这个方法很简单。 我们使用各种攻击来生成对抗示例,并将其添加到每次迭代的训练集中,从而增加对抗模型对示例的“抵抗力”。
这种方法的缺点非常明显:在每次训练迭代时,对于每个示例,我们都可以分别生成大量示例,并且对训练进行建模的时间增加了很多倍。
您可以使用ART-IBM库来应用此方法,如下所示。
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
高斯数据增强
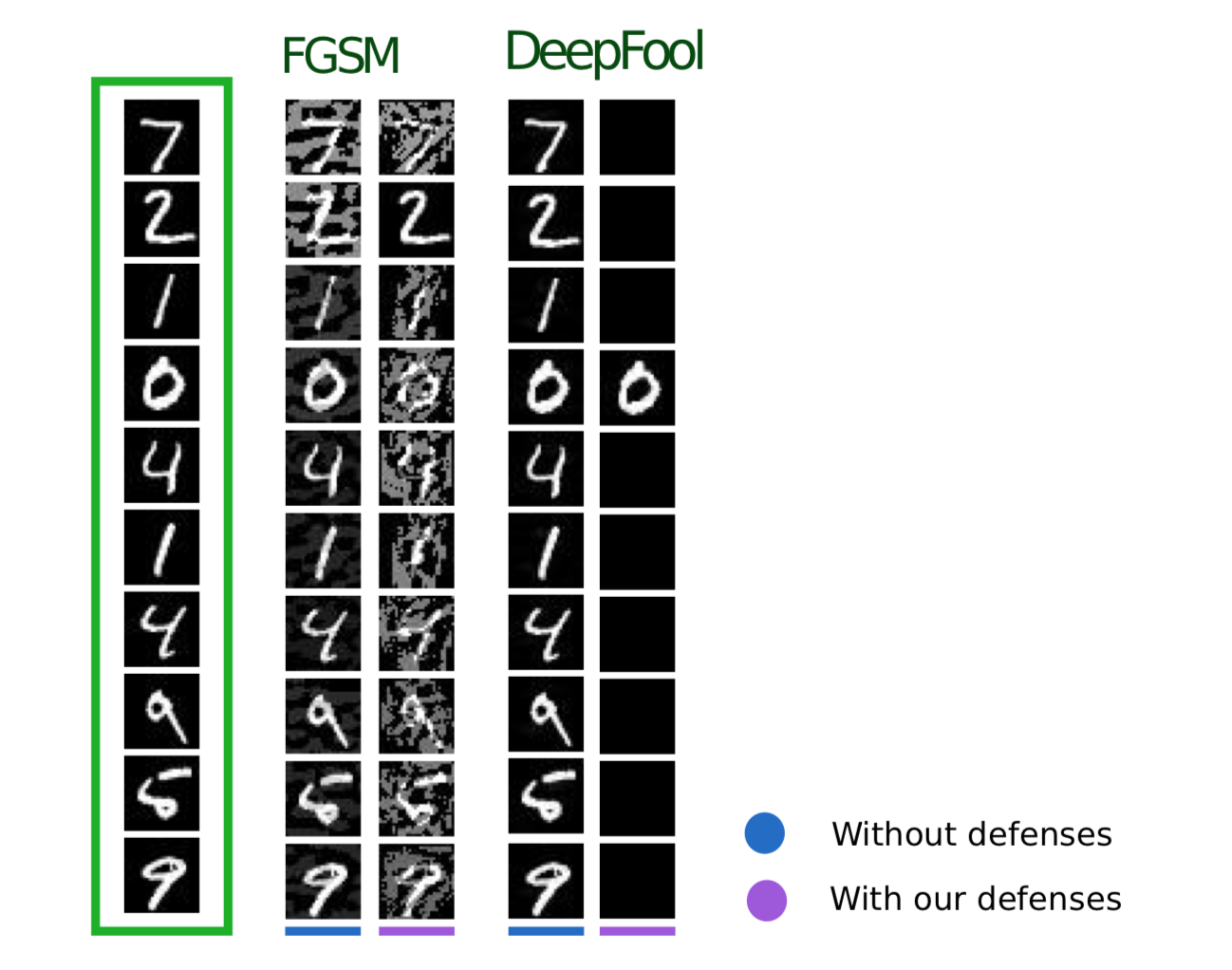
在有效防御对抗攻击文章中描述的以下方法使用类似的逻辑:它还建议向训练集中添加其他对象,但是与对抗训练不同,这些对象不是对抗性示例,而是稍微嘈杂的训练集对象(将高斯用作噪声)噪声,因此方法的名称)。 而且,实际上,这似乎很合乎逻辑,因为这些模型的主要问题恰恰是它们的抗噪能力差。
这种方法显示出与对抗训练相似的结果,同时花费更少的时间生成训练对象。
您可以使用ART-IBM中的GaussianAugmentation类来应用此方法
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
标签平滑
标签平滑方法很容易实现,但是仍然具有很多概率意义。 我们不会详细讨论此方法的概率解释;您可以在原始文章Rethinking Inception Architecture for Computer Vision中找到它。 但是,简单地说,“标签平滑”是分类问题中模型的另一种正则化类型,这使其更耐噪声。
实际上,此方法可平滑类标签。 使它们不是1,而是0.9。 因此,对训练模型进行了优化,以使标签具有更大的“可信度”,从而使特定对象的标签更加清晰。
可以在下面看到此方法在Python中的应用。
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
有界的露露
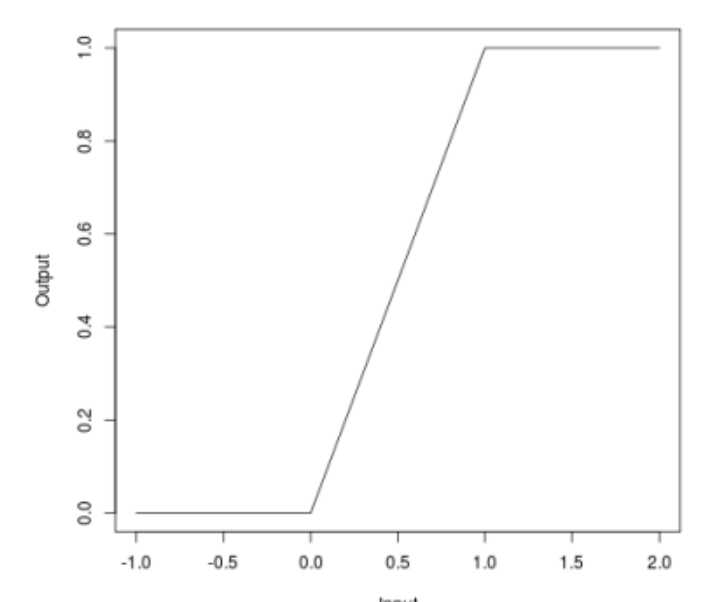
当我们谈论攻击时,许多人可能会注意到,某些攻击(JSMA,OnePixel)取决于输入图像中一点或另一点的渐变强度。 有界ReLU的简单且“便宜”(就计算和时间成本而言)方法正在尝试解决此问题。
该方法的实质如下。 让我们用相同的神经网络替换ReLU的激活函数,该函数不仅从下方受限制,而且从上方受限制,从而平滑了梯度图,并且在特定点上将不会产生飞溅,这将不允许您通过更改图像的一个像素来愚弄算法。
\开始{equation *} f(x)=
\开始{cases}
0,x <0
\\
x,0 \ leq x \ leq t
\\
t,x> t
\结尾{cases}
\ end {equation *}
在对抗攻击的有效防御中也对此方法进行了描述
建筑模型组合
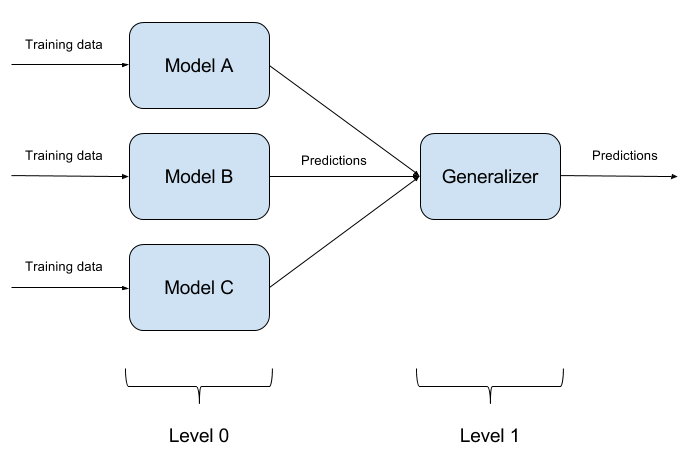
欺骗一个训练有素的模型并不难。 用一个对象同时欺骗两个模型更加困难。 如果有N个这样的模型? 正是基于此,模型的集成方法才是基础。 我们只需构建N个不同的模型,然后将其输出汇总到一个答案中即可。 如果模型也由不同的算法表示,那么欺骗这样的系统非常困难,但是却非常困难!
很自然地,模型集成的实现是一种纯粹的体系结构方法,会问很多问题(要采用什么基本模型?如何汇总基本模型的输出?模型之间是否存在关系?等等。) 因此,ART-IBM中未实现此方法。
功能挤压
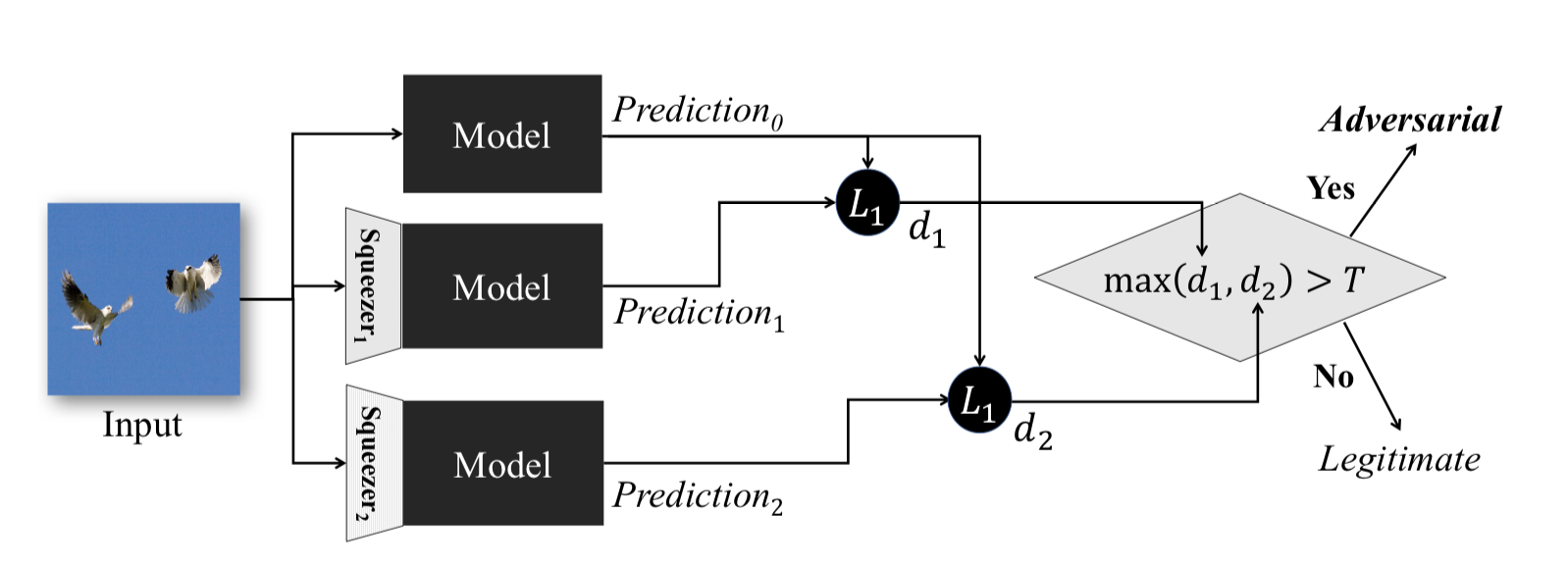
在特征压缩:在深度神经网络中检测对抗示例中描述的该方法在模型的操作阶段起作用。 它使您可以检测对抗性示例。
该方法背后的思想如下:如果您在相同的数据上训练n个模型,但压缩率不同,则它们的工作结果仍将相似。 同时,在源网络上运行的对抗示例很可能在其他网络上失败。 因此,考虑初始神经网络输出和附加神经输出之间的成对差异,从中选择最大值,并将其与预选阈值进行比较,我们可以说输入对象是对抗性的或绝对有效的。
以下是使用ART-IBM获取压缩对象的方法
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
我们将以保护方法结束。 但是,如果不掌握一个重点,那是错误的。 如果攻击者无权访问模型的输入和输出,则在进入模型之前,他将不了解如何在系统内部处理原始数据。 然后,只有到那时,他的所有攻击都将减少为对输入值进行随机排序,这自然不可能导致期望的结果。
测试中
现在,让我们讨论测试算法以对抗对抗性示例。 在这里,首先,有必要了解我们将如何测试模型。 如果我们以某种方式假定攻击者可以获得对整个模型的完全访问权限,则有必要使用WhiteBox攻击方法来测试我们的模型。
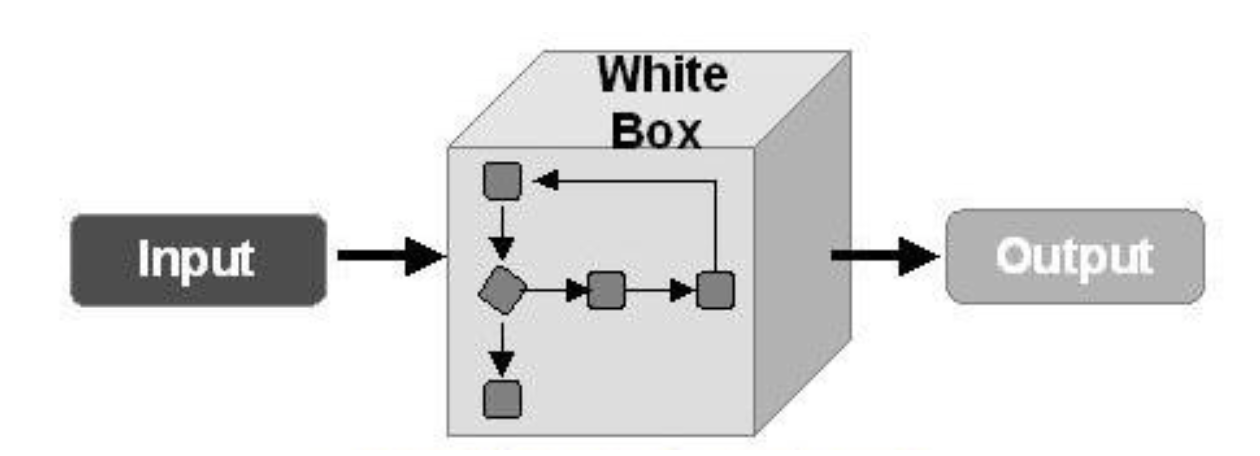
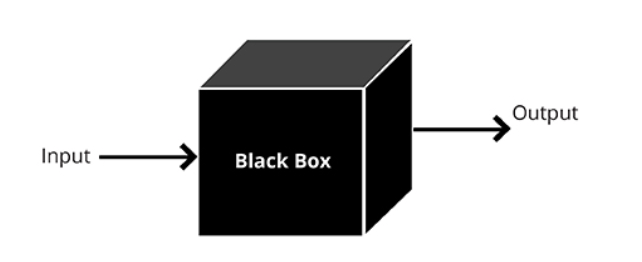
在另一种情况下,我们假设攻击者将永远无法访问模型的“内部”,但他将能够(尽管间接地)影响输入数据并查看模型的结果。 然后,您应该应用BlackBox攻击的方法。
通用测试算法可以通过以下示例进行描述:
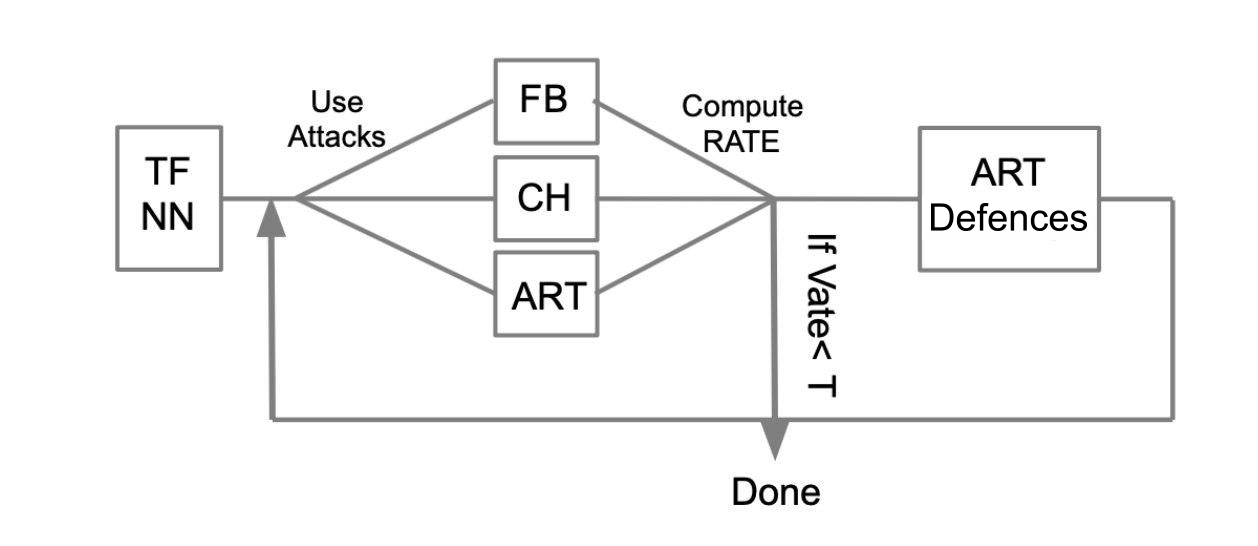
假设有一个用TensorFlow(TF NN)编写的受过训练的神经网络。 我们专家断言,通过渗透模型所在的系统,我们的网络可以落入攻击者的手中。 在这种情况下,我们需要进行WhiteBox攻击。 为此,我们定义了一个攻击池和框架(FoolBox-FB,CleverHans-CH,Adversarial鲁棒性工具箱-ART),可以实施这些攻击。 然后,计算成功攻击次数,计算出成功率(SR)。 如果SR适合我们,我们将完成测试,否则我们将使用一种保护方法,例如在ART-IBM中实施的保护方法。 然后我们再次进行攻击并考虑SR。 我们会周期性地执行此操作,直到SR适合我们为止。
结论
我想在此结束时提供有关攻击,防御和测试机器学习模型的一般信息。 总结这两篇文章,我们可以得出以下结论:
- 不要相信机器学习是可以解决所有问题的奇迹。
- 在您的任务中应用机器学习算法时,请考虑一下该算法对对抗性示例的抵抗力。
- 您既可以从机器学习的角度,也可以从运行该模型的系统的角度,保护算法。
- 测试模型,尤其是在模型结果直接影响决策的情况下
- FoolBox,CleverHans,ART-IBM等库为攻击和防御机器学习模型提供了方便的界面。
同样在本文中,我想总结一下FoolBox,CleverHans和ART-IBM库的工作:
FoolBox是一个简单易懂的库,用于攻击神经网络,支持许多不同的框架。
CleverHans是一个库,通过该库,您可以通过更改攻击的许多参数来进行攻击,该过程比FoolBox复杂得多,支持的框架更少。
ART-IBM是上述工具中唯一允许您使用安全性方法的库,到目前为止,它仅支持TensorFlow和Keras,但其开发速度比其他方法快。
值得一提的是,还有另一个库可以处理百度的对抗性示例,但不幸的是,它仅适合说汉语的人。
在关于该主题的下一篇文章中,我们将通过使用FoolBox库欺骗典型的神经网络来分析拟在ZeroNights HackQuest 2018期间解决的部分任务。