哈Ha 我叫Aleksey Rak,我是Yandex明斯克办事处语音助手Alice的开发人员。 去年,我在同一支球队中参加了为期三个月的实习,从而获得了这一职位。 我要告诉你关于她的事。 如果您想自己尝试,这里是
2019年实习的
链接 。

我如何安定下来
我是BSU的四年级学生,2018年我从数据分析学院毕业,我住在明斯克。
首先,我和其他SHAD毕业生一样,在2018年获得了一个实习链接。 发送问卷后一周内,有必要连续6小时分配时间以完成在线竞赛。 它包含有关概率论,编码能力和算法的任务。 可以用您知道的语言编写代码。 我用C ++编写了一些任务,用Python编写了一些任务,我根据特定任务的易用性选择了语言。
当您提交决策时,将立即做出判决,此后可以再次解决任务以获得更正确的答案。 我花了几个小时才能完成所有任务,但第一次尝试并没有解决某些问题。
几天后,招聘人员与我联系,并要求在明斯克办公室进行首次面谈。 我曾在声学模型和生物识别技术团队的负责人Alexei Kolesov任职。 面试包括在纸上或黑板上解决问题,并回答有关概率论,算法和机器学习的问题。 我认为,即使我没有在ShAD上学习,但奥林匹克编程的背景使我能够应付在线竞赛,但是在面试时,ShAD的经历对我来说真的很有用。
几天后,第二次会议举行了,又问我两个有关算法知识的任务:热身和基本任务。 对于每个任务,都是这样的:我提出了一个解决方案,回答了有关该解决方案的几个问题,然后将代码写在了纸上。
几天后,我被告知我已接受实习。 她应该持续三个月(结果是发生了)。 他们没有承诺转为永久职位,但表示这样的选择是可能的。
开始使用
在第一天,整理好组织问题并拿了笔记本电脑,我去和同事共进午餐。 我们进行了交谈,然后我整理了一个团队存储库并承担了第一个任务-编译一个简单的Python脚本以开始在多个线程中运行一个已经完成的程序,从而加快其执行速度。 在创建脚本的过程中,我熟悉了代码检查系统-当团队中的其他人验证您的代码时。 知道您最亲密的同事将首先与他打交道,以后再与其他开发人员打交道,您会尝试写得更清晰。 在奥林匹克编程中,一切都有些不同:编程的速度很重要,而且很可能甚至不需要查看所写的内容。 另一方面,当我不得不面对Yandex之前仍然需要阅读代码的情况时,我也试图使其或多或少变得清晰。
在实习期间,我曾多次解决过与此脚本类似的问题,但我的主要时间花在了一个更大的项目上-一个为侦探爱丽丝设计的新解码器。
为了使Yandex设备和应用程序可以通过语音呼叫助手,一切都可以按照用户期望的方式工作,因此您需要高质量的侦听器-语音激活机制。 最常见的是,激活短语(您需要发音以启动Alice)本身包含单词“ Alice”。
Spotter包括功能的准备(机器学习的功能),神经网络和解码器。
以前的解码器
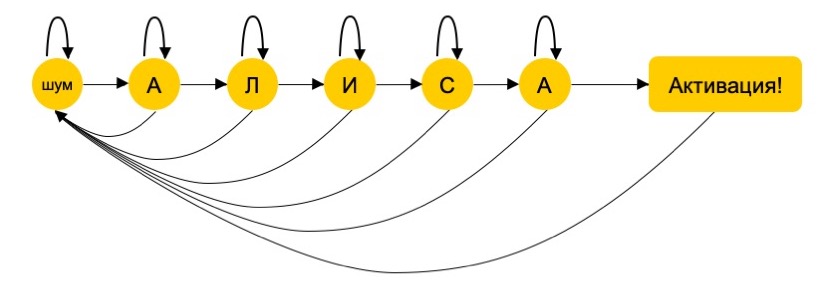
解码器的先前版本通过处理概率向量来工作。 有一个声学模型-神经网络,对于每个帧(持续10到20毫秒的语音片段),该函数都会返回它现在已经发音的概率。 框架可以重叠。 解码器包含一个矩阵,该矩阵具有设备“听到”的最后100帧的概率。 每个字母的声音对应于某个概率向量。 在字母A的向量中,算法找到了概率最高的元素,此后,它仅考虑了矩阵相对于该元素的正确部分。 然后,对字母L,I,C和A重复该操作-每次被找到的元素“切断”矩阵时。 单词开头和结尾处的A的声音实际上是不同的-它们中的第二个通常称为Shva,它看起来像A,E和O同时。
如果最终概率大于阈值,则该算法认为该单词实际上已被说出并为用户激活了Alice。

这种方案导致了这样一个事实,即助手有时不仅在人们说“爱丽丝”时自动打开,而且在他听到其他单词(例如“亚历山大”)时自动打开。 该词的第一部分(“ Alex”)中的声音遵循相同的顺序,并且基本上与“ Alice”一词中的声音一致。 区别仅在于字母E和K,但声音中的E与I非常接近,并且该算法未考虑字母K的存在。

从理论上讲,您不仅可以在语音中搜索“爱丽丝”一词,还可以搜索相似的词。 其中没有很多:“亚历山大”,“亚历山大”,“被捕”,“楼梯”,“ aristarchus”。 如果该算法认为用户很有可能说了其中一个,则无论主解码器的结果如何,都可以禁止激活。
但是,即使没有Internet,语音激活也应该起作用。 因此,解码器是一种本地机制。 它的工作要归功于神经网络,它每次都直接在用户设备(例如电话)上运行,而无需与Yandex服务器通信。 而且由于所有事情都是本地发生的,因此(同一部手机相比整个数据中心的性能)还有很多不足之处。 不仅认识到“爱丽丝”一词,还意味着使这个小型神经网络的工作大大复杂化,并超出了性能极限。 激活将开始工作得更慢,助手将延迟很长时间。
需要一个根本不同的解码器。 同事建议我实施隐马尔可夫模型(HMM)的想法:在实习初期,社区已经对其进行了很好的描述,并且还在Amazon的Alexa助手中找到了应用。
新的HMM解码器
HMM解码器将构建6个顶点的图形:一个单词“ Alice”中的每个声音,一个顶点,所有其他声音(另一个语音或噪声)。 顶点之间的过渡概率是在记录的和带注释的语音样本上估算的。 对于所听到的每种声音,将考虑6个概率:与五个字母中的每个字母一致并到达第六个顶点(也就是说,与单词“爱丽丝”中找不到的其他声音)一致。 如果用户说“亚历山大”,则解码器将落入K值:语音不是激活短语的一部分的机率太大,并且助手将无法工作。
在不久的将来,这些更改将对Alice和SpeechKit库的所有用户可用。
完成实习并过渡到永久性工作
在实习的三个月中,我花了一个半小时编写一个HMM解码器。 在这一个半月的结束时,经理告诉我,如果我继续保持有效率的工作,就可以过渡到永久职位和永久合同。 大约在同一时间,我休了两个星期的假期去参加奥林匹克编程营。 回国后,我开始了一项新任务-培训各种设备的侦察员:Yandex.Phone,Yandex.Auto等车载计算机。
几周后,大约在实习结束前一个月,我进行了关于永久职位的第一次面试,几天后-第二次,也是最后一次。 我与相关团队的负责人进行了交谈。 在第一次面试中,我被问到了理论上的问题:关于机器学习,神经网络,逻辑回归,优化方法。 另外,他们询问正则化,即减少给定算法的再训练程度,以及正则化方法应用于哪些算法。 第二次采访是实际的:我们与来自莫斯科的同事在Skype上进行了交谈,然后我在一个简单的在线编辑器中键入了代码。
我并没有全职工作,而是¾-事实上,我在BSU的学习尚未完成。 在固定位置上,我还从事自动选择阈值和其他超参数的工作。 在任何时候,系统都会获得说出关键字“爱丽丝”的可能性。 最终分类器将此概率与阈值进行比较,如果超过阈值,则激活Alice。 以前,阈值是由开发人员选择的,当前的任务是学习如何自动执行此操作。
所以我去了Yandex,保留了我在爱丽丝团队中的位置。