很久以前,当一部手机的价格约为2000美元,而一分钟的语音通话费用为50美分时,传呼机确实很受欢迎。 后来蜂窝电话变得更便宜,通话和短信价格降低,最后寻呼机大部分消失了。
对于以前拥有寻呼机并想知道其工作原理的人来说,本文将非常有用。
主要资讯
对于那些忘记了原理或在2000x之后出生的人,我会在短期内提醒您一些主要思想。
寻呼通信网络具有一些优点,即使在现在也有时很重要:
-它是单向通信,没有任何形式的确认,因此网络不会过载-它仅取决于许多用户。 消息不断地“原样”传输,如果寻呼机的号码(所谓的Capcode)等于设备内部号码,则寻呼机正在接收消息。
-接收器非常轻巧(无论是字面上还是电子方式),并且使用2节AA电池最多可以工作一个月。
消息传输有两个基本标准
-POCSAG (邮局代码标准化顾问组)和
FLEX 。 两种标准都相当老,POCSAG于1982年制成,它可以支持512、1200和2400 bit / s的速度。 为了传输FSK(频移键控)方法,使用了4.5KHz的频率间隔。 FLEX较新(由Motorola在90年代制造),它可以高达6400 bit / s的速度工作,并且可以同时使用FSK2和FSK4。
两种协议通常都很容易,大约在20年前就已经制造出PC解码器,可以解码来自声卡串行端口的消息(不支持加密,因此任何人都可以读取所有消息)。
让我们看看它是如何工作的。
接收信号
首先,我们需要一个信号进行解码。 让我们拿一台笔记本电脑,rtl-sdr接收器来买。
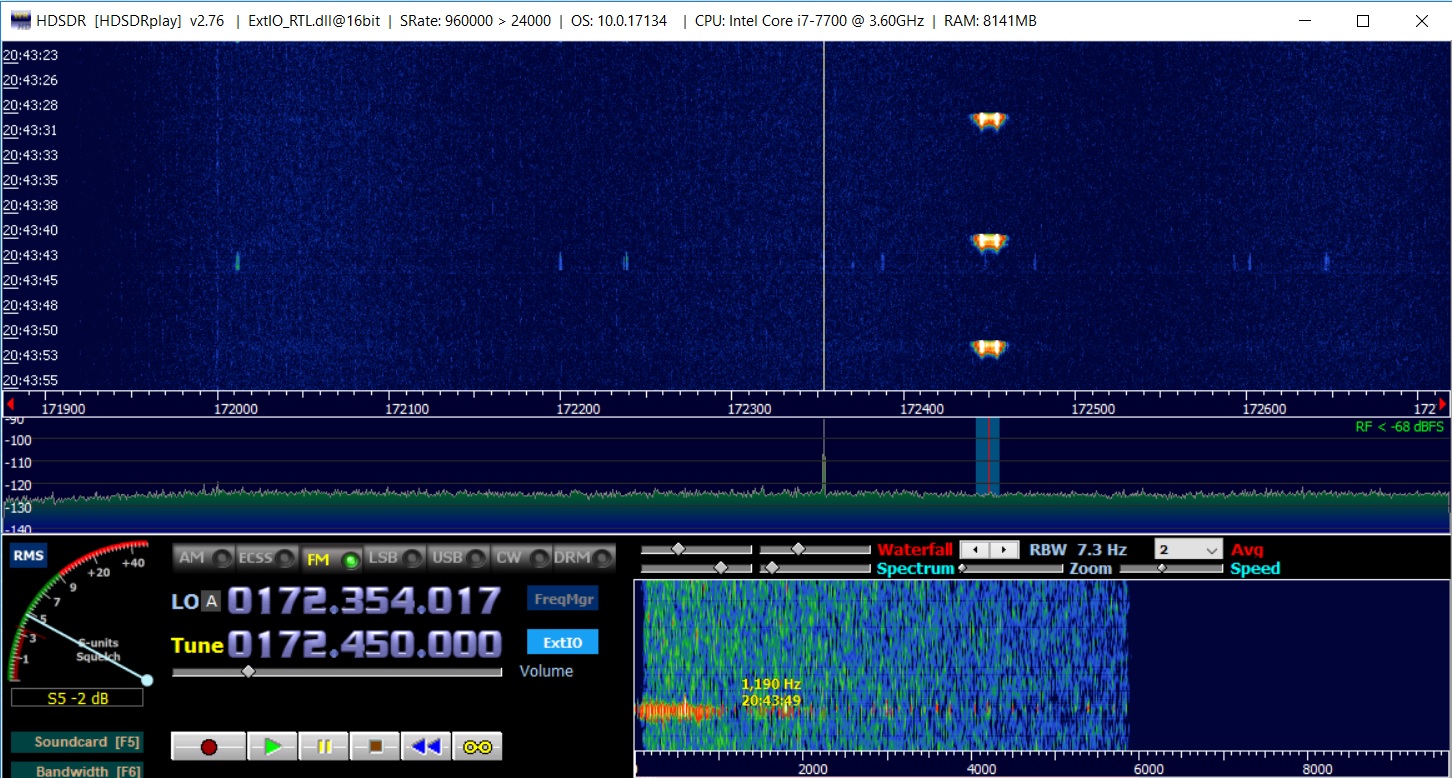
使用了频移键控,因此我们将设置FM。 使用HDSDR,我们将以WAV格式保存信号。
让我们检查一下,我们得到了什么。 将wav文件加载为Python数据数组:
from scipy.io import wavfile import matplotlib.pyplot as plt fs, data = wavfile.read("pocsag.wav") plt.plot(data) plt.show()
输出(手动添加的位):

如我们所见,它很容易,甚至可以用“肉眼”在Paint中绘制位,它很容易区分“ 0”和“ 1”。 但是手动进行将太长,需要时间来自动化该过程。
放大图表后,我们可以看到每个位具有20个样本宽度。 我们每秒有24000个采样率的wav文件,因此键控速度为1200bit / s。 让我们找到一个零交叉位置-它是位序列的开始。 我们还添加标记以验证所有位都在正确的位置。
speed = 1200 fs = 24000 cnt = int(fs/speed) start = 0 for p in range(2*cnt): if data[p] < - 50 and data[p+1] > 50: start = p break
正如我们所看到的,它并不完全匹配(发送器和接收器的频率略有不同),但是对于解码来说绝对足够。

对于长信号,我们可能需要自动频率校正算法,但是对于此类信号,它并不重要。
最后一步-我们需要将wav文件转换为位序列。 这也很容易,我们知道每个位的长度,如果数据总和为正,我们将添加“ 1”,否则将添加“ 0”(最终发现信号需要还原,因此替换了0和1) 。
bits_str = "" for p in range(0, data.size - cnt, cnt): s = 0 for p1 in range(p, p+cnt): s += data[p] bits_str += "1" if s < 0 else "0" print("Bits") print(bits_str)
输出-包含我们消息的正确位序列(以字符串格式)。
101010101010101010101010101010101010101010101010101010101010101010101010101
010101010101010101010101010101010101010101010100111110011010010000101001101
100001111010100010011100000110010111011110101000100111000001100101110111101
010001001110000011001011101111010100010011100000110010111011110101000100111
000001100101110111101010001001110000011001011101111010100010011100000110010
011011110101000100111000001100101110111101010001001110000011001011101111010
100010011100000110010111011110101000100111000001100101110111101010001001110
...
111101111解码纯数字消息
位序列比wav文件方便得多,我们可以从中提取数据。 首先,让我们将数据分成4个字节的块。
10101010101010101010101010101010
10101010101010101010101010101010
10101010101010101010101010101010
10101010101010101010101010101010
01111100110100100001010011011000
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
00001000011011110100010001101000
10000011010000010101010011010100
01111100110100100001010111011000
11110101010001000001000000111000
01111010100010011100000110010111
01111010100010011100000110010111
01111010100010011100000110010111
00100101101001011010010100101111我们绝对可以看到一个模式。 现在我们需要找出每个部分的含义。 POCSAG手册
以PDF格式提供 ,让我们检查数据结构说明。
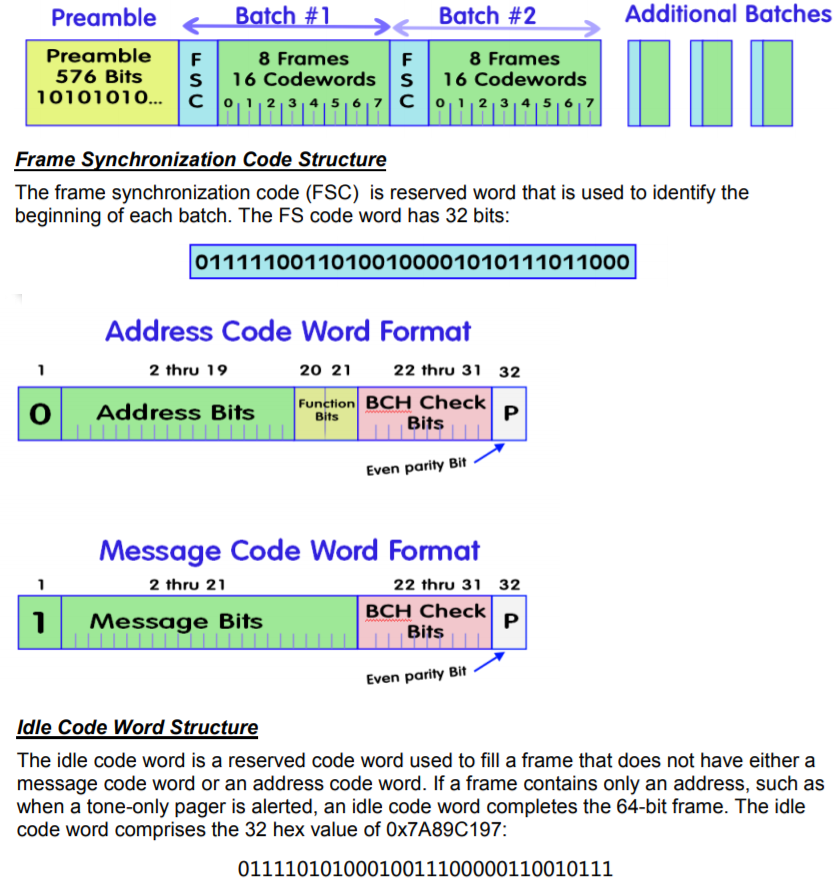
现在更清楚了。 标头包含一个长块“ 10101010101”,用于从睡眠模式“唤醒”寻呼机。 消息本身包含块Batch-1 ... Batch-N,每个块都从唯一序列FSC开始。 然后,如我们在手册中所见,如果字符串以“ 0”开头,则它包含收件人地址。 地址本身(代码)存储在寻呼机中,如果不匹配,则寻呼机将忽略该消息。 如果字符串从“ 1”开始,则它包含消息正文。 在我们的示例中,我们有2个这种类型的字符串。
不检查每个块。 我们还可以看到空闲代码-空块01111 ... 0111,它们没有任何有用的信息。 删除它们后,我们仅得到以下内容:
01111100110100100001010011011000 - Frame Sync
00001000011011110100010001101000 - Address
10000011010000010101010011010100 - Message
01111100110100100001010111011000 - Frame Sync
11110101010001000001000000111000 - Message
00100101101001011010010100101111 - Address我们需要找到里面的东西。
在检查了手册之后,可以清楚地知道消息有两种类型:
纯数字和
字母数字 。 仅数字消息被保存为4位BCD码,因此20位可以包含5个符号(也有CRC位,我们暂时不使用它们)。 如果消息是字母数字,则使用7位ASCII编码。 该消息太短,因此只能是纯数字消息。
从字符串10000011010000010101010011010100和11110101010001000001000000111000中我们可以得到以下4位序列:
1 0000 0110 1000 0010 10101 0011010100-0h 6h 8h 2h Ah
1 1110 1010 1000 1000 00100 0000111000 -Eh Ah 8h 8h 2h
下一步是从手册中获取解码表:

很明显,纯数字消息可以包含数字0-9,字母U(“ ugrent”),空格和两个括号。 让我们编写一个小的方法对其进行解码:
def parse_msg(block):
最后,我们收到一条消息“ 0682 *)* 882”。
很难说出它的含义,但是如果使用仅数字消息,则可能有人需要它。
解码字母数字消息
接下来,也是更有趣的步骤是解码字母数字消息。 它更有趣,因为作为输出,我们应该获得人类可读的文本。
首先,我们需要再次记录一条消息,我们将使用HDSDR。 我们在解码之前不知道消息类型,因此我们将记录一条最长的消息,我们可以得到,并且希望它包含一些文本。
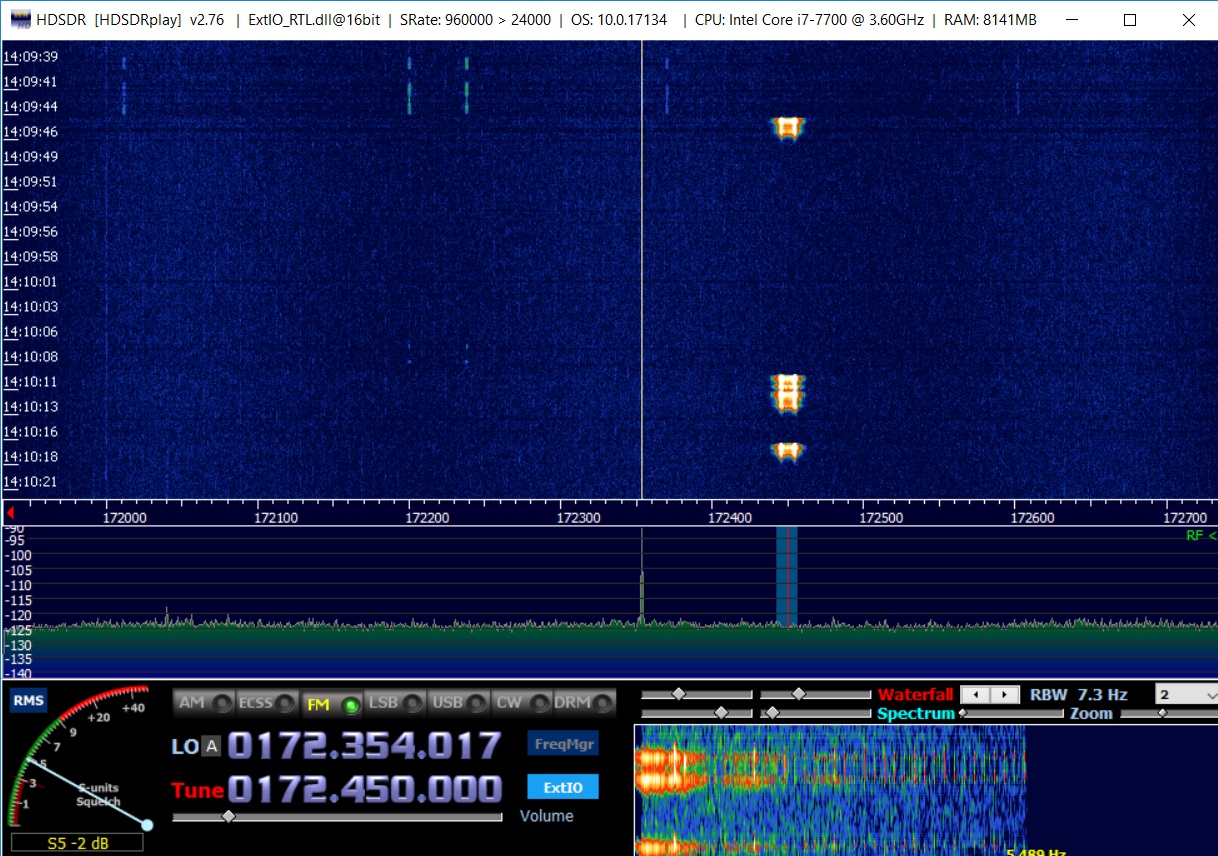
从wav转换为位序列(请参见上面的Python代码)后,我们得到以下信息:

我们可以用肉眼立即看到一些有趣的东西-例如,开始序列01010101010101重复了两次。 因此,此消息不仅更长,而且它实际上包含合并在一起的两条消息(顺便说一句,标准并不否认)。
正如我们之前所发现的,每个数据块都是在发送32位块之后从称为帧同步代码(01111100 ...)的序列开始的。 每个块可以存储地址或消息正文。
之前我们得到了纯数字消息,现在我们想读取ASCII消息。 首先,我们需要区分它们。 该数据保存在“功能位”字段(位20-21)中-如果两个位均为00,则为纯数字消息;如果位为11,则为文本消息。
有趣的是,该消息字段的长度为20位,因此,对于纯数字消息,最好在其中放置5个4位块。 但是,如果我们有7位ASCII消息,则不能将20划分为7。可以预测第一个协议版本仅支持纯数字消息(不要忘了它是1982年制造的,
并且可能是第一个数码管寻呼机)无法显示更多 ),并且仅添加了更高版本的ASCII消息支持。 由于遗留的原因,框架标准没有改变,开发人员使用了简单的方法-他们只是“原样”组合位。 对于每条消息,我们需要占用20位并将其合并到下一条,最后我们可以对消息正文进行解码。
让我们看一下我们的消息块(空格是加法器,易于阅读):
0 0001010011100010111111110010010
1 00010100000110110011 11100111001
1 01011010011001110100 01111011100
1 11010001110110100100 11011000100
1 11000001101000110100 10011110111
1 11100000010100011011 11101110000
1 00110010111011001101 10011011010
1 00011001011100010110 10011000010
1 10101100000010010101 10110000101
1 00010110111011001101 00000011011
1 10100101000000101000 11001010100
1 00111101010101101100 11011111010第一个字符串中的“ 0”位告诉我们这是地址字段,而20-21位中的“ 11”告诉我们该消息实际上是字母数字。 然后,我们只需从每个字符串中提取20位并将其合并在一起。
这是我们的位序列:
00010100000110110011010110100110011101001101000111011010010011000001101000
11010011100000010100011011001100101110110011010001100101110001011010101100
000010010101000101101110110011011010010100000010100000111101010101101在POCSAG中,使用7位ASCII代码,因此我们将字符串分成7个字符块:
0001010 0000110 1100110 1011010 0110011 1010011 ...尝试对其进行解码(可以在Internet上轻松找到ASCII表)之后,我们得到的只是什么。 再次检查手册,这是一个小短语“ ASCII字符从左到右放置(MSB到LSB)。 LSB首先发送。 因此,低位先发送-为了正确解码,我们需要反转所有字符串。
手动进行操作太无聊了,所以让我们编写一个Python代码:
def parse_msg(block): msgs = "" for cw in range(16): cws = block[32 * cw:32 * (cw + 1)]
最后,我们得到以下序列(位,符号代码和ASCII符号):
0101000 40 ( 0110000 48 0 0110011 51 3 0101101 45 - 1100110 102 f 1100101 101 e 1100010 98 b 0101101 45 - 0110010 50 2 0110000 48 0 0110001 49 1 0111001 57 9 0100000 32 0110001 49 1 0110011 51 3 0111010 58 : 0110011 51 3 0110001 49 1 0111010 58 : 0110100 52 4 0110101 53 5 0100000 32 0101010 42 * 0110100 52 4 0110111 55 7 0110110 54 6 0101001 41 ) 0100000 32 1000001 65 A 1010111 87 W 1011010 90 Z
合并后,我们得到字符串:“((03-feb-2019 13:31:45 * 476)AWZ”。 如所承诺的,它的可读性很强。
顺便提一下,值得一提的是,使用了7位ASCII码。 某些字母(德语,西里尔字母等)的符号无法正确编码为7位。 为什么是7位? 工程师可能已经决定“ 7位就足够了所有人”,谁知道...
结论
调查POCSAG的工作方式真的很有趣。 它是直到现在仍在使用的稀有协议之一,可以从字面上解码出来(我绝对不会在TETRA或GSM上尝试此协议)。
当然,这里没有完整描述POCSAG协议。 最重要和最有趣的部分已完成,其他内容并不那么令人兴奋。 至少没有Capcodes解码,也没有纠错码(BCH Check Bits)-它可以修复消息中最多2个错误的位。 但是这里没有写另一个POCSAG解码器的目标,已经足够了。
对于那些想要使用rtl-sdr测试真实解码的人,可以使用免费的
PDW应用程序 。 它不需要安装,仅需通过虚拟音频电缆应用程序将声音从HDSDR转发到PDW。
结果看起来像这样:
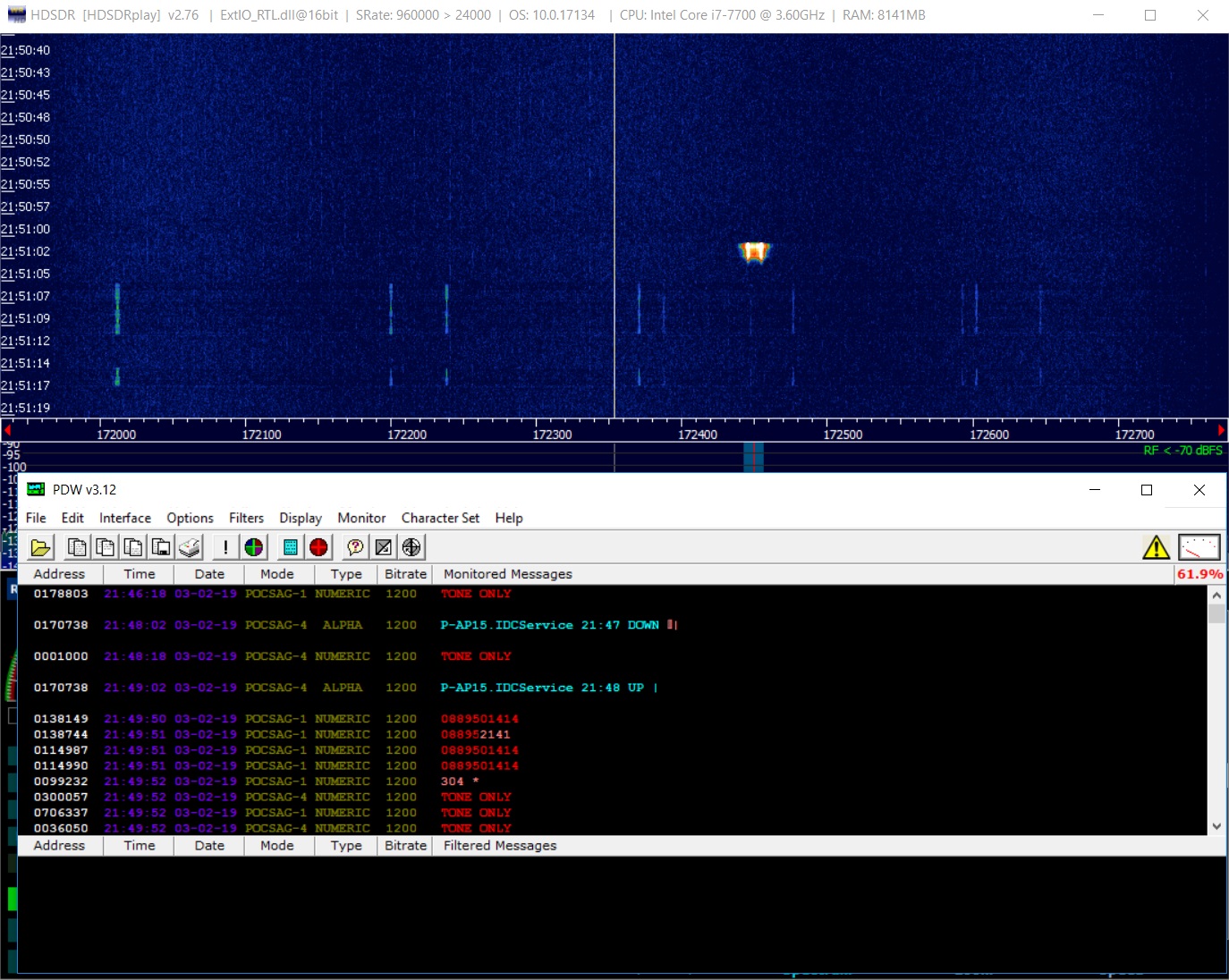
(请记住,在某些国家/地区,公共服务消息的解码可能是非法的,并且无论如何都要尊重接收者的隐私)
如果有人想获得有关此主题的更多信息,可以使用
multimon-ng解码器的源,它可以解码许多协议,包括POCSAG和FLEX。
感谢您的阅读。