去年,俄罗斯和乌克兰媒体在硅谷的派对上掀起了一波关于好莱坞的气氛的文章,但没有指定具体的名称,照片,也没有描述与这些名称相关的硬件开发和软件编写技术。 这篇文章不一样! 它还将有亿万富翁,天才和女孩,但带有照片,幻灯片,图表和程序代码片段。 因此:
前几天,坎贝尔市长以俄罗斯名字Paul Resnikoff在新成立的Wave Computing启动办公室剪彩,该公司与Broadcom一起正在开发7纳米芯片以加速神经网络的计算。 该办公室位于19世纪末至20世纪初历史悠久的水果和罐头工厂的建筑中,当时硅谷是世界上最大的果园。 即使在那时,该办公室仍在从事创新工作,并在杏李业中引入了用于输送机的第一台电动机,该电动机为大约200名员工(主要是女性)工作。
在剪彩之后的晚会上,许多业内知名人士受到关注,包括Kernigan-Richie的同志和70年代后期至80年代最受欢迎的C编译器的作者,Stephen Johnson,浮点数标准Jerome Kunen的发明者之一。本地总线概念和第一个PC AT芯片组开发人员Diosdado Banatao,Sun,DEC,Cyrix,Intel,AMD和Silicon Graphics处理器,高通,Xilinx和Cypress芯片的前开发人员,工业分析师,红头发的女孩和其他加利福尼亚居民 这种类型的mpany。
在文章的结尾,我们将讨论为了加入这个社区而需要阅读和练习的书籍。
让我们从Jerome Kunen开始,他是自第一台Macintosh以来的浮点算法创新者和Apple经理。
候选论文并不常见,不会影响数十亿个设备上的计算。 这就是Jerome Kunen的Diser(左)所做的,对二进制浮点算术提议标准的贡献,其结果包括在IEEE标准754浮点数中。 杰罗姆(Jerome)于1982年从伯克利研究生院毕业后,就去苹果公司工作,在那里他将浮点库引入了第一台Macintosh。
在苹果公司工作了10年之后,Kunen咨询了惠普和微软公司,并在2000年为AMD的新64位x86版本优化了128位算法。 Jerome最近将注意力转向了神经网络浮点标准的研究,特别是有关Unum和Posit的争论。 Unum是新提议的标准,由加州理工学院的John Gustafson的科学家提倡,他现在是一本喧闹的书《错误的终结》,《错误的终结》的作者。 Posit是Unum的一个版本,在硬件上比Unum可以更有效地实现(*)。
(*)更有效地结合以下参数:时钟频率,每次操作的周期数,输送机吞吐量,芯片上的相对面积和相对功耗。

文章图片(并非来自Jerome)
使浮点数学运算对于AI硬件和
在自己的游戏中超越浮点:John L. Gustafson和Isaac Yonemoto的正算术 :

但是在聚会上,Stephen / Steve Johnson是C编程语言在其编译器上流行的人。 第一个C编译器由Denis Ritchie编写,但是Richie的编译器与PDP-11架构紧密绑定。 史蒂夫·约翰逊(Steve Johnson)基于艾伦·斯奈德(Alan Snyder)的工作,在1970年代中期编写了可移植C编译器(PCC),该便携式C编译器易于重制以生成用于不同体系结构的代码。 同时,Johnson编译器工作迅速并且正在优化。 他是如何实现的?
在PCC输入端,史蒂夫·约翰逊(Steve Johnson)使用了也由史蒂夫·约翰逊(Steve Johnson)编写的YACC(Yet Another Compiler Compiler)生成的LALR(1)解析器。 之后,将编译任务简化为在递归函数中处理树并从模板表生成代码。 其中一些递归函数与机器无关,另一部分是由将PCC转移到另一台机器的人编写的。 模板表由类型为“如果类型A的寄存器和类型B的两个寄存器是空闲的规则条目”组成,则将树重建为类型C的节点并生成带有字符串D的代码。 该表与机器有关。
由于优雅,灵活性和效率的完美结合,PCC编译器被移植到200多种体系结构上-从PDP,VAX,IBM / 370,x86到苏联BESM-6和Orbit 20-700(MiG-29早期版本的车载计算机)。 根据Denis Ritchie的说法,几乎在1980年代初的每个C编译器都基于PCC。 在BSD Unix世界中,1994年PCC被取代为仅标准的GNU GCC编译器。
除了PCC和Yacc,史蒂夫·约翰逊(Steve Johnson)还是原始Lint程序验证程序的作者(例如,参见
1978年文章 )。 从那时起,Yacc和Lint程序的名称已成为通用名词。 在2000年代,史蒂夫重写了MATLAB的前端并编写了MLint。 现在,史蒂夫·约翰逊(Steve Johnson)忙于在CGRA(粗粒度可重配置架构)等设备上并行化用于计算神经网络的算法的任务,其中包括成千上万个类似处理器的元素,这些元素被张量通过一个大规模芯片内的数以万计的开关网络跨越,该大规模芯片内有数十亿个晶体管:

但随着一杯酒,亿万富翁Diosdado Banatao,Chips&Technologies的创始人,S3 Graphics的创始人兼Marvell的投资者。 如果您是在1985年至1988年对IBM PC进行编程的,当时它们首次出现在苏联,那么您可能会知道,大多数带有EGA和VGA图形的AT机架中都有Chips&Technologies的芯片组,这些芯片组与IBM同时出现。 早期的C&T芯片组由Banatao设计,Banatao在斯坦福大学(Stanford)担任波音工程师之前就已经在斯坦福大学学习电子工程师。 1987年,英特尔收购了Chips&Technologies。


下图的左侧是自2000年代巅峰时期以来MIPS Technologies总裁John Bourgoin,当时大多数DVD播放器,数码相机和电视中都装有MIPS内核的芯片,而Zoran,Sigma Design, Realtek,Broadcom等公司。 在此之前,John自1996年以来一直担任MIPS Silicon Graphics的总裁,当时MIPS处理器位于Silicon Graphics工作站内部,好莱坞用来拍摄第一部逼真的3D Jurassic Park电影。 在加入Silicon Graphics之前,John自1976年以来一直是AMD的副总裁之一。
右图是Art Swift,在2000年代曾担任MIPS营销副总裁,在此之前的1980年代,他曾在Fairchild Semiconductor(是的)担任工程师,然后在Sun,DEC,Cirrus Logic和Sun担任营销副总裁。 Transmet总裁。 最近,Art担任RISC-V营销委员会的副主席,并在这个职位上熟悉俄罗斯的Syntacore和CloudBear。 现在他已经成为Wave的MIPS IP的总裁:
 关于MIPS历史
关于MIPS历史的
演示文稿中的幻灯片与John Bourgoin控制MIPS的时期有关,如左图所示:

Transmet公司的总裁曾在一段时间内担任Art Swift,在右上方的图片中,于1990年代末发布了Crusoe处理器,该处理器可以遵循x86指令,并在Toshiba Libretto L子笔记本电脑,NEC和Sharp笔记本电脑中进入市场。 ,来自Compaq的瘦客户端。 它们相对于英特尔和AMD的竞争优势被设定为可控制的低功耗。
直接实现和验证完整的x86套件是一项非常昂贵的工作,因此Transmeta采取了另一种方式,这类似于俄罗斯MTsST公司使用Elbrus处理器的路线(该线始于Elbrus 2000,现在称为Elbrus 8C)。 Transmeta和Elbrus基于具有VLIW微体系结构的结构简单的处理器,并且x86仿真级别使用Transmeta称为代码变形的技术在其之上工作。
VLIW(超长指令字)的思想非常简单-多个处理器指令被显式声明为一个超级指令并并行执行。 与超标量处理器不同,特别是Intel从PentiumPro(1996)开始,在该处理器中,处理器会根据对指令之间依赖性的自动分析,从内存中选择几条指令,然后决定并行执行哪些指令和顺序执行哪些指令。
超标量处理器比VLIW复杂得多,因为超标量必须花费逻辑来维持程序员对所有选择的指令依次执行的错觉,尽管实际上在处理器的不同执行阶段可能有数十条指令在执行。 对于VLIW,维护这种错觉的负担在于高级语言的编译器。 最后,当处理器必须使用多级缓存时,VLIW电路中断,该缓存具有不可预测的延迟,这使编译器难以调度时钟指令。 但是对于数学计算(例如,将Elbrus放在雷达上并计算目标的运动)来说,这就是问题,尤其是在缺乏合格的工程人员的情况下(更多的人需要验证超标量)。
VLIW创意,Crusoe处理器和Toshiba Libretto L1子笔记本电脑的图示:

Wave Computing现任首席执行官Derek Meyer,Derek Meyer下图中的中心。 在Wave之前,Derek曾是ARC的首席执行官,ARC是用于音频芯片的ARC处理器内核的开发商。 这些内核当时
获得了许可,包括俄罗斯公司NIIMA Progress的许可,后者随后又获得了MIPS内核的许可,并
在喀山Innopolis的一次展览中展示了基于它们的芯片 。 德里克·迈耶(Derek Meyer)曾多次前往俄罗斯,前往圣彼得堡(Virage Logic)的开发团队所在的圣彼得堡。 2009年,ARC收购了Virage Logic,2010年,全球领先的芯片设计公司Synopsys收购了ARC。
照片的右边-
谢尔盖·瓦库连科 (
Sergey Vakulenko) ,在他职业生涯的黎明就站在
鲁内特 (Runet)的原籍,曾在合作社Demos和库尔恰托夫研究所(Kurchatov Institute)工作,这使互联网进入了苏联。 现在,谢尔盖(Sergey)正在编写用于计算神经网络的Wave处理器元素的周期精确模型,并且在较早的时候,他编写了用于验证MIPS处理器内核I6400 Samurai,I7200 Shaolin等的MIPS内核的指令精确模型。

这是1990年的瓦迪姆·安东诺夫(Vadim Antonov)和谢尔盖·瓦库连科(Sergey Vakulenko),苏联的第一台计算机已连接到Internet:

这是右边的Larry Hudepohl(Hüdepol用俄语拼写吗?)。 Larry在Digital Equipment Corporation(DEC)担任MicroVAX的处理器设计师,开始了他的职业生涯。 然后Larry在一家小型公司Cyrix工作,该公司在1980年代后期挑战了Intel,并制造了与Intel 80387兼容且速度提高50%的FPU协处理器。 然后,拉里(Larry)在Silicon Graphics公司设计了MIPS芯片。 当MIPS Technologies从Silicon Graphics分离出来时,Larry和Ryan Quinter共同推出了第一个独立的MIPS产品MIPS 4K,该产品成为主导2000年代家用电子产品(DVD播放器,照相机,数字电视)的产品线的骨干。 然后,MIPS 5K飞入太空-日本航天局JAXA使用了它。 然后,作为硬件工程副总裁的拉里(Larry)领导了以下几行的开发,现在他正在研究新的Wave加速器体系结构。
 去年降落在Ryugu小行星表面上的
去年降落在Ryugu小行星表面上的日本飞船自豪地命名为Hayabusa-2(Sapsan-2),由基于MIPS 5Kf处理器内核的HR5000处理器控制,该处理器内核已获得MIPS Technologies的长期许可。
这是来自其
数据表的64位MIPS 5Kf处理器内核的简单串行管道:

就在照片中-Darren Jones,Darren Jones。 他曾是MIPS的硬件工程总监,负责开发复杂的内核,硬件多线程和具有非凡执行指令的超标量。 然后,Darren前往Xilinx,参与了Xilinx Zynq-芯片,该芯片上结合了FPGA和ARM处理器。 Darren现在是Wave的工程副总裁。
在MIPS上,Darren是该小组的负责人,其成员后来去苹果和三星工作。 去三星的设计师莫妮卡曾经对我说过一句话,我记得很深刻:“ RTL设计:一些简单的原理,而其余的都是作弊的”(寄存器级硬件设计:一些简单的原理,其他都是“ muhlezh”) muhlezh的一个典型示例是高速缓存(程序会写入数据并读取数据,但是稍后会记住),但这只是Monica能够执行的非常特殊的情况。

硬件多线程和非凡的超标量是提高处理器性能的两种不同方法。 硬件多线程允许您在不消耗大量能量的情况下,通过非平凡的编程来提高吞吐量。 超标量使您可以以大约两倍的速度运行单线程程序,但耗电量却是其两倍。 但是没有编程技巧。
最后,硬件多线程在俄语Wikipedia中得到了很好的解释,这是它的
临时多线程 (在MIPS interAptiv和MIPS I7200 Shaolin中实现),但是
同时多线程 (在1990年代由DEC Alpha处理器,然后在SPARC,然后在MIPS I6400武士/ I6500大名)。
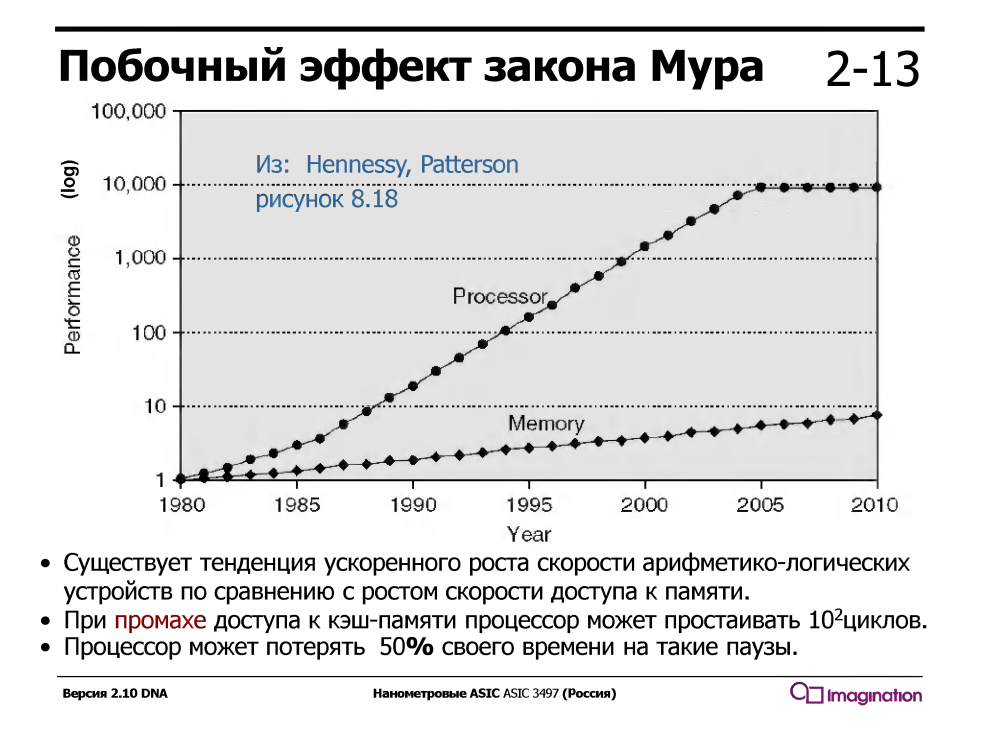
临时多线程利用了一个事实,即具有常规串行管道的处理器处于空闲状态/等待执行时间的一半。 他还在等什么呢? 通过内存缓存的数据。 它等待很长时间-在等待一个高速缓存未命中时,处理器可以执行数十个甚至一百二十个简单的算术指令,例如加法。
情况并非总是如此-在1960年代,算术设备比内存慢得多。 但是从1980年左右开始,处理器内核的速度增长速度远远超过了内存速度,甚至处理器中出现了多级缓存也只能部分解决该问题。
具有临时多线程的处理器支持多组寄存器,每个线程一组,当当前线程在高速缓存未命中期间正在等待内存中的数据时,处理器将切换到另一个线程。 这是在一个周期内立即发生的,没有中断,并且中断处理程序没有中断数千个周期,这在软件(而非硬件)多线程处理期间被激活。
加利福尼亚大学圣克鲁斯分校硅谷分校教授
Charles Danchek讲习班的幻灯片上是多线程的想法。 为什么用俄语? 因为Charles Danchek在莫斯科MISiS,然后在圣彼得堡ITMO和基辅KPI进行了演讲:


有趣的是,多线程硬件可以简单地用C编程。 看起来是这样的:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
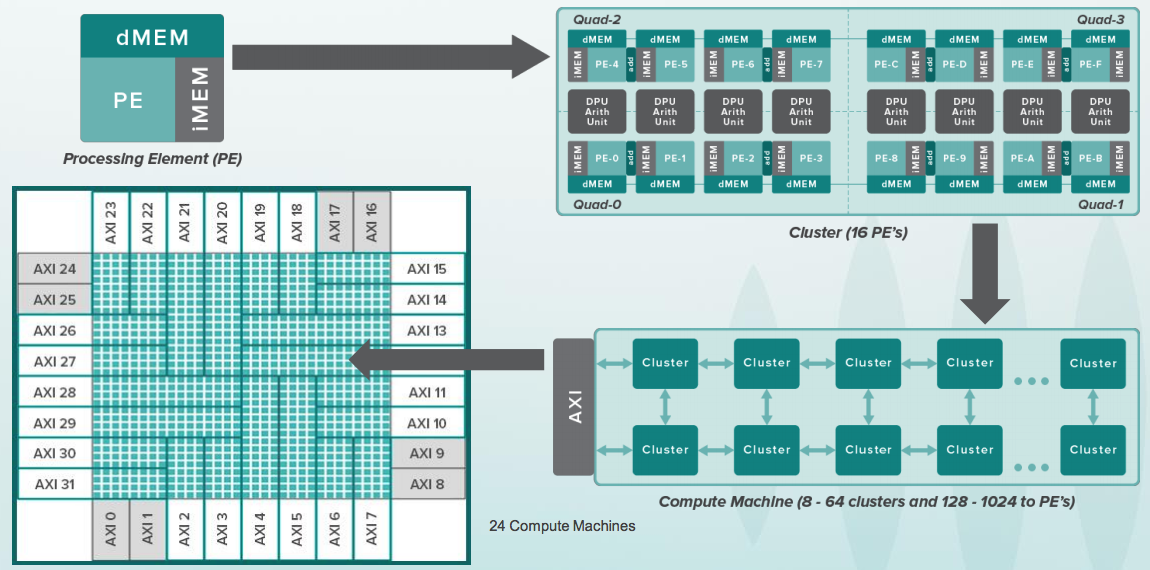
在聚会的这边是用于数据中心的Wave设备。 尽管某些客户可以将这些芯片作为Beta计划的一部分使用,但它仍无法完全正常工作:

该设备做什么? 你知道如何用Python编程吗? 在Python中,您可以使用TensorFlow库进行构建,该库称为所谓的数据流图(DFG)。 神经网络本质上是带有矩阵运算的专用图。 在Wave软件组中,该软件的一部分由Steve Johnson领导。在该设备芯片的配置文件中,有一个带有Google TensorFlow表示的子集的编译器。 配置后,它可以非常快速地进行此类图形的计算。 该设备是为数据中心设计的,但是相同的原理也可以应用于小型芯片,甚至在移动设备内部,例如用于面部识别:

Chijioke Anyanwu(左)-多年来,他一直是整个MIPS处理器核心测试系统的托管人。 Baldwyn Chieh(中心)是Wave中新一代类似处理器的元素的设计师。 鲍德温曾经是高通公司的高级设计师。 这是
HotChips会议上有关Wave设备的
幻灯片 :


每个硅谷公司的纳米级数字创新AI都必须拥有自己的金发美女。 这是Wave中的一个女孩。 她的名字叫雅典娜(Athena),是一名受过教育的社会学家,在办公室工作:

这是办公室的外观,以及它作为一家创新罐头厂以来的百年历史:


现在的问题是:如何理解架构,微架构,数字电路,AI芯片的设计原理并参与此类活动? 最简单的方法是研究David Harris和Sarah Harris的教科书“数字电路和计算机体系结构”,然后去Wave Computing担任暑期实习生(计划在夏季雇用15名实习生)。 我希望在从事类似开发的俄罗斯微电子公司(ELVIS,Milander,Baikal Electronics,IVA Technologies等)中也能做到这一点。 从理论上讲,这可以在基辅的Melexis公司完成,该公司与KPI合作。
前几天,哈里斯(Harris)和哈里斯(Harris)教科书有了新的,经过最终纠正的版本,该书应该在这里免费提供:
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 ,但是该链接对我不起作用,当它起作用时,我将为此撰写另一篇文章。 在苹果,英特尔,AMD的采访中,以及在本教科书的哪几页(以及其他来源)中询问问题时,您可以看到答案。