
今天,我们将发起2019年Rekko挑战赛 ,这是Okko在线电影院的机器学习竞赛。
我们建议您根据俄罗斯最大的在线电影院之一的真实数据构建推荐系统。 我们相信,无论对于初学者还是有经验的专家,这项任务都会很有趣。 我们试图保持最大的创造力范围,同时不要让具有数百个预先计算的功能的千兆字节数据集超载。
在下面阅读有关Okko,任务,数据,奖品和规则的更多信息。
挑战赛
您可以在N天(N> 60)的时间内访问用户对“已存储”电影和系列的所有观看,评级和添加的数据,以及有关内容的所有元信息。 有必要预测用户在未来60天内将通过订阅购买或观看哪些电影和系列。
在下一节中,我们试图描述您需要了解的有关在线电影院的最少知识,以便快速了解数据并开始对其进行分析。 如果此信息与您无关,则可以立即进行数据描述 。
关于我们的服务
如果用户想要合法地在Internet上观看电影,则可以采用以下三种主要方式。
第一种方法是免费观看广告,并不断打断广告( AVOD ,点播广告视频)。 第二种是购买电影供您收藏或租借( TVOD ,按需交易视频)。 第三是订阅一定期限( SVOD ,按需订阅视频)。
Okko仅适用于TVOD和SVOD模型。 我们的服务完全没有广告。
总体而言,该服务拥有超过10,000部电影和系列电影,其中约有6,000部可以通过订阅获得,其余仅用于购买或租赁。 同时,几乎所有订阅内容都可以购买。 例如, Amediateka电视节目是一个例外,只能通过订阅观看这些节目 。
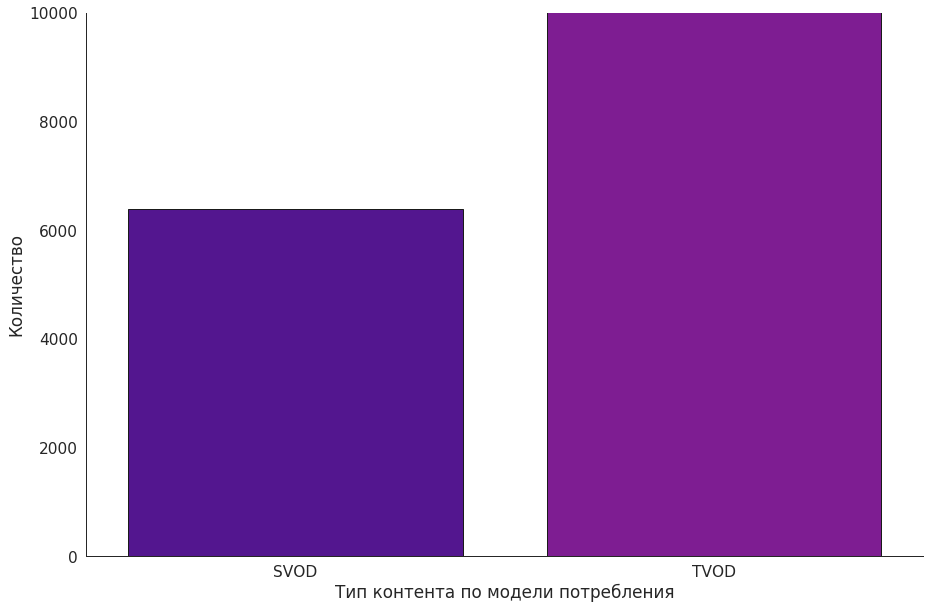
根据电影的发行模式,很大程度上取决于拥有版权的电影制片厂。 他们与在线电影院签订了合同,其中规定了何时以及获得该电影的版权。 通常,所有市场参与者的条件都是相同的,但有时制片厂对某些电影院做出让步或为提供更多资金提供更有利的条件。 所以有独家。
例如,主要的全球创新不会立即进入订阅,而只会在出现在服务中的2-3个月后进入。 而且,在最初的几周内甚至无法租用它们,只有永远购买的机会才可用。 但俄罗斯电影发行后可能立即可以订阅,有时甚至可以在离线电影院开始租借的同时订购。
合同到期时,电影将不可用-直到到期合同的延长或新合同的签订为止。
在视图数量的图表上可以清楚地看到缺乏内容权的时期。 例如,下面是电影“约翰·威克2”的图表。 首先,看似轻快的东西似乎要休息了几个月,但没有:权利结束了。
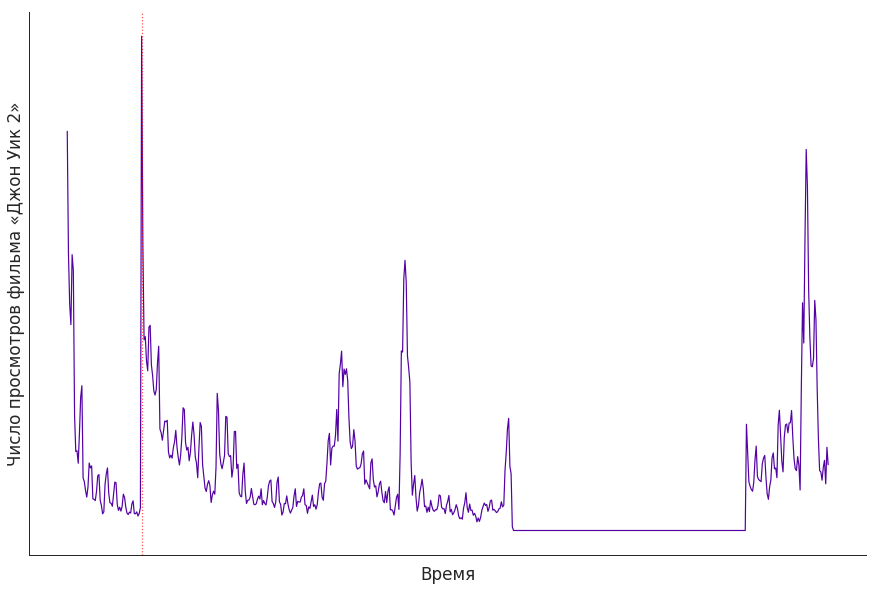
上图中的最高峰(标有竖线)与将电影添加到订阅的日期重合:对于高调新颖的作品,这是非常典型的行为。 我们的服务有12个订阅:
- 八大主题
- 电视连续剧Amediateka,
- 电视连续剧ABC,
- START服务中的俄罗斯电影和电视剧,
- 4K电影。
还有两个订阅包:Optimal(包括所有主题订阅)和Optimal + Amediateka。
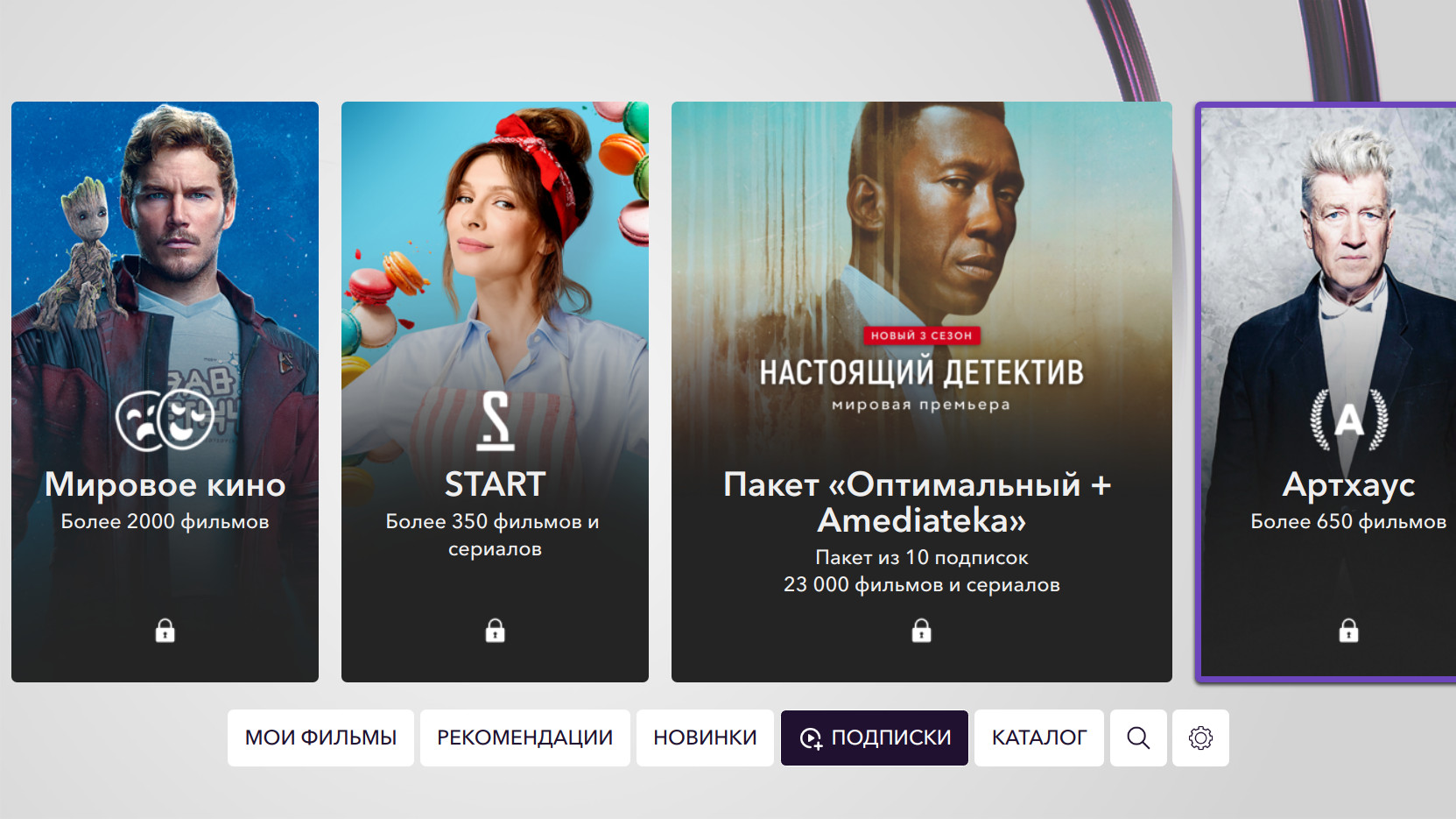
当然,最受欢迎的是meta包。 在主题订阅中,用户更喜欢World Cinema和Our Cinema。

很少有用户仅按订阅观看电影,大多数用户只是购买电影或订阅以外购买。
用户通常会选择购买新的物品,用于当前的租金和去年的主要首映式。
该应用程序中最受欢迎的购买来源是“建议”部分,其次是“搜索”,“新闻”和“目录”。 用户从“相似”和“记忆”中购买部分电影。

我们在Okko积极应对的主要问题之一是用户选择内容的问题。 如果您查看购买可能性与您在服务中花费的时间之间的关系图(上一年的数据),可以清楚地看到用户已经准备好在开始的10分钟之内选择和购买电影,那么购买的可能性就会迅速降低。 同时,仍有相当一部分用户在该服务中花费了半个小时到一个小时,而他们无法选择适合自己的内容。
10分钟-没那么多。 在此期间,用户完全无法从物理上详细研究目录并选择自己喜欢的内容。
这是Okko在线电影院的内部推荐系统Rekko出现的地方。 Rekko目前在服务的两个部分中运作-“建议”和“类似”。
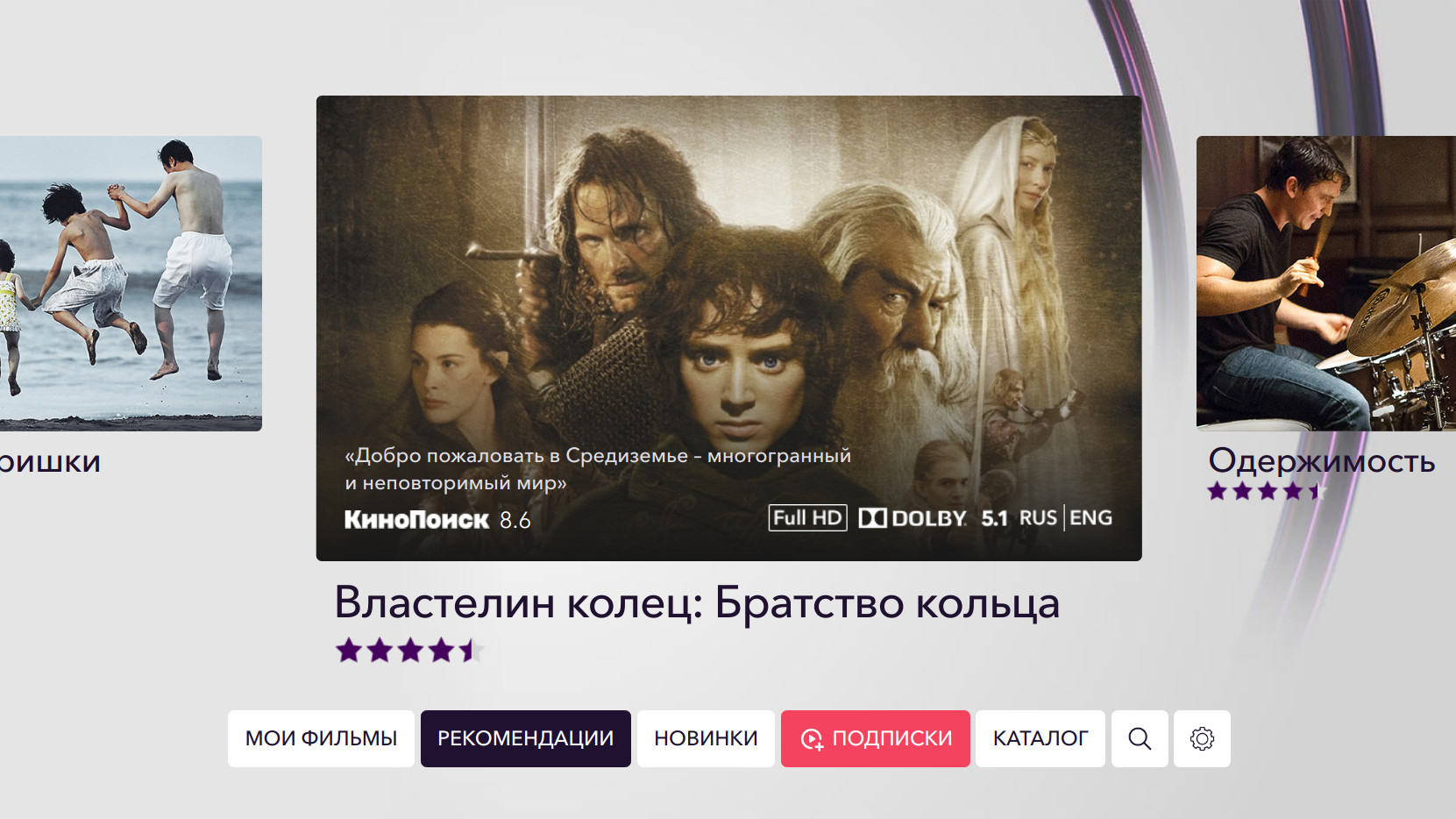
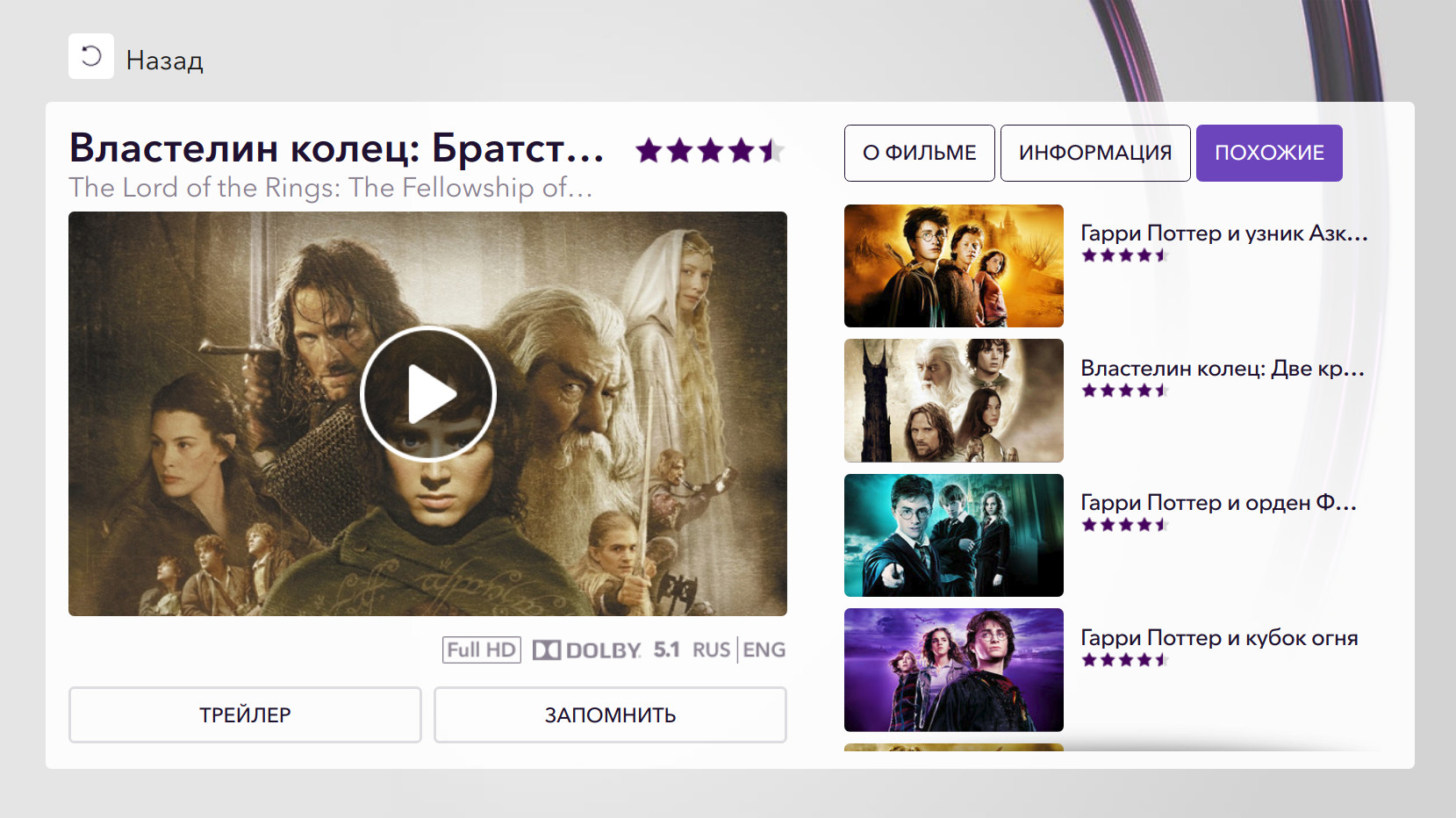
为了评估用户对内容的满意度,我们分析了购买的事实,按订阅观看的次数,观看时间,添加到已存储和用户评分。
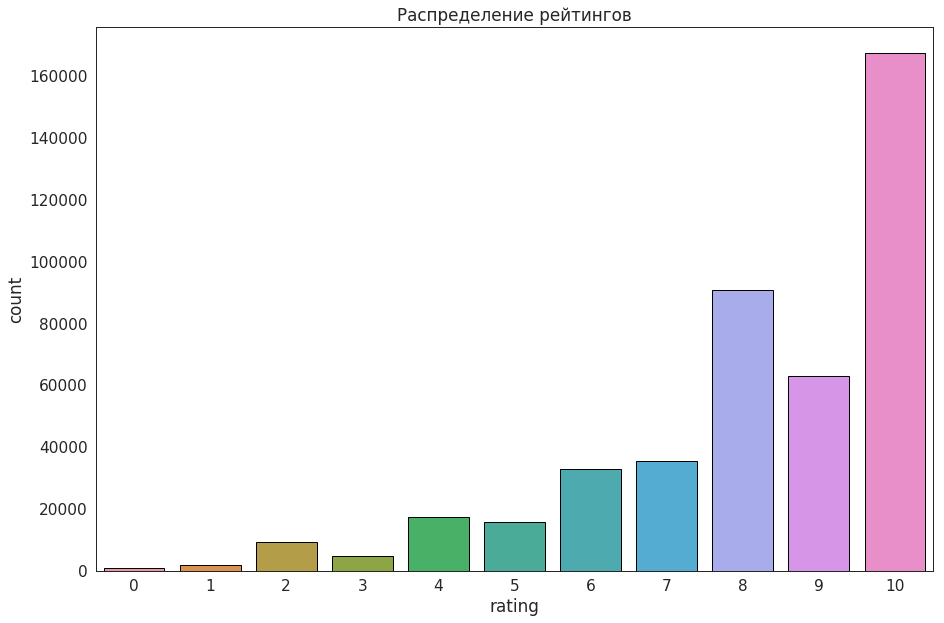
Okko的评分等级由五个星号(半数除法)表示:它采用0到10之间的整数值。
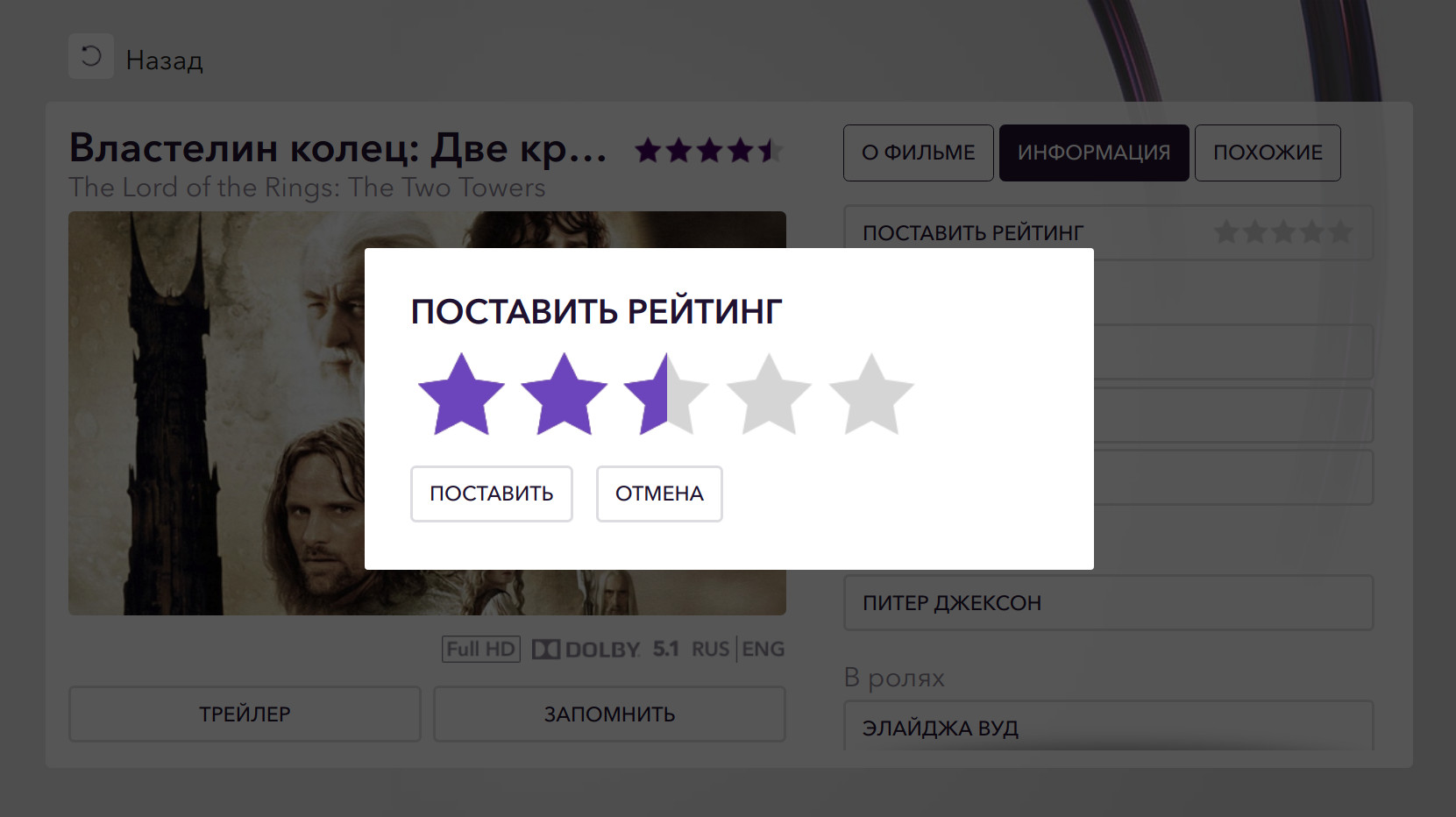
不论购买或观看的事实如何,用户都可以在任何时候对电影进行评分。 分数可以无限次更改,但无法撤消。
您可以随时“记住”电影,然后该电影将显示在用户个人资料的“已记住”中。 同样,可以从那里删除它。

关于Rekko的工作恰好在一年前开始,目前,根据A / B测试,它使我们可以将平均购买次数增加4%,将交易收入增加3%,将订阅转换为5%,并且用户开始选择电影的速度提高了18% 。

资料
除观看时间和收视率外,所有数据均被匿名化或失真。 时间以抽象单位表示,保留了顺序和距离的关系。
Transactions.csv
在培训期间,记录所有交易和内容视图。 此处的交易是永久购买电影,以出租或通过订阅开始观看。
element_uid元素标识符user_uid用户IDconsumption_mode类型( P购买, R租金, S按订阅查看)ts交易时间watched_time用户为此事务观看的秒数(秒)device_type进行交易的设备的匿名类型device_manufacturer进行交易的设备的匿名制造商

rating.csv
有关培训期间用户评分的信息。 信息是汇总的,即 如果用户更改了评分,则表中只会显示最后一个值。
element_uid元素标识符user_uid用户IDrating -用户定义的等级(从0到10 )ts排名时间
bookmarks.csv
用户将影片添加到“已记住”的事实。 信息是汇总的,即 如果用户从“已保存”中删除了电影,则在表中将没有添加电影的记录。
element_uid元素标识符user_uid用户IDts将影片添加到“已记住”的时间
catalogue.json
有关所有推荐元素的元信息:电影,连续电影和系列电影。
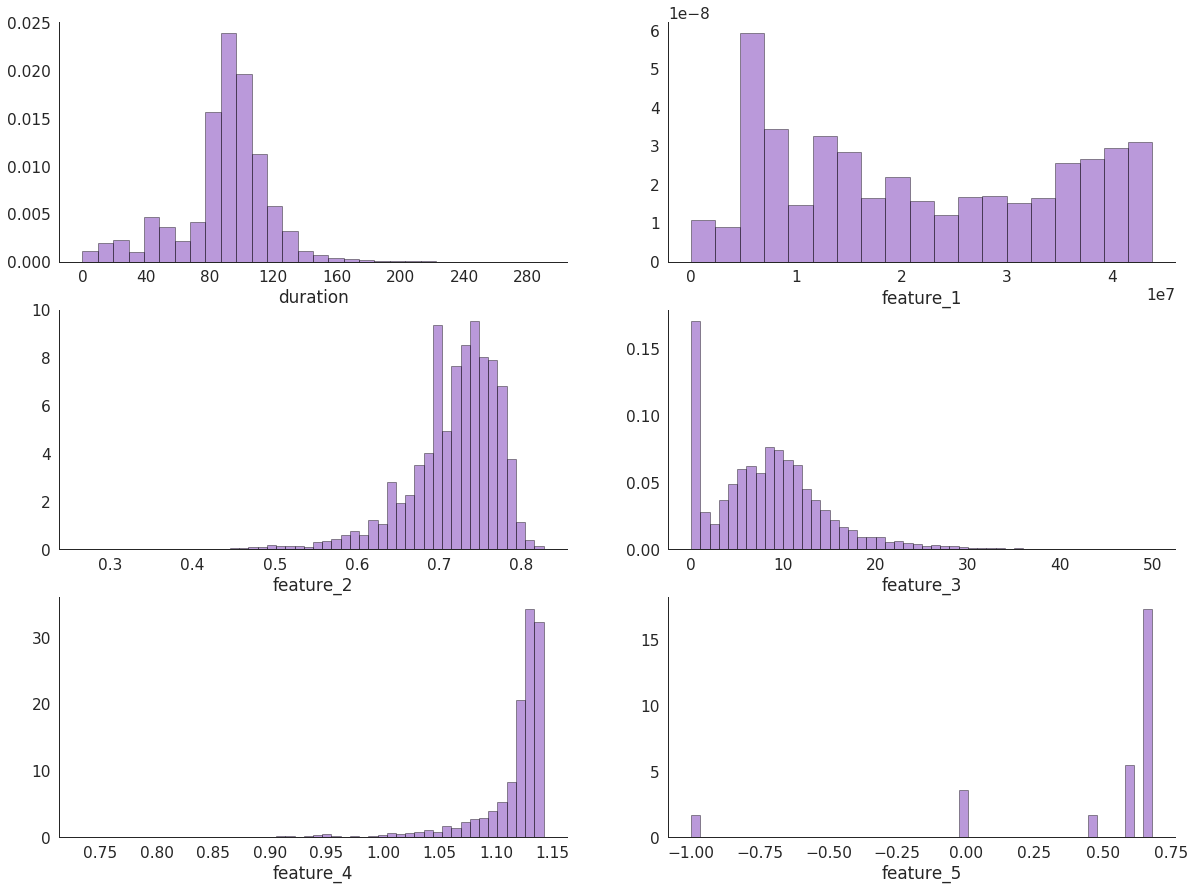
{ "1983": { "type": "movie", "availability": ["purchase", "rent", "subscription"], "duration": 140, "feature_1": 1657223.396513469, "feature_2": 0.7536096584, "feature_3": 39, "feature_4": 1.1194091265, "feature_5": 0.0, "attributes": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ...] }, "2166": { "type": "movie", "availability": ["purchase", "rent"], "duration": 110, "feature_1": 36764165.87817783, "feature_2": 0.7360206399, "feature_3": 11, "feature_4": 1.1386044027, "feature_5": 0.6547073468, "attributes": [16738, 13697, 1066, 1089, 7, 5318, 308, 54, 170, 33, ...] }, ... }
type -接受movie , multipart_movie或series的值duration -以分钟为单位的持续时间,四舍五入为数十(连续剧和系列电影的连续剧的持续时间)availability -内容的可用权利(可能包含purchase , rent和subscription )attributes -一些匿名属性的袋子feature_1..5五个匿名材质和顺序特征
在培训期结束和测试开始时会指出可用权利。
重要提示:在json中,字典键只能是字符串,因此,如果您将表中的标识符读取为数字,请确保将其转换为数字(这样做可以节省内存)。
公制
作为度量标准,我们对20个元素使用了平均平均精度(MAP),但略有修改。 在测试期间,用户可以消耗少于20部电影。 如果在这种情况下,我们考虑使用诚实的MAP,则指标的上限将小于1,并且值将较小。 因此,如果用户消耗的元素少于20个,我们将按其数量而不是20个进行归一化。
-位于 用户在测试期间消耗的元素集中的第一个预测元素 , 是这套的大小。 如果突然忘记了排名质量指标,那么中心上会有一篇关于它们的出色文章
Cython中的公制代码 def average_precision( dict data_true, dict data_predicted, const unsigned long int k ) -> float: cdef: unsigned long int n_items_predicted unsigned long int n_items_true unsigned long int n_correct_items unsigned long int item_idx double average_precision_sum double precision set items_true list items_predicted if not data_true: raise ValueError('data_true is empty') average_precision_sum = 0.0 for key, items_true in data_true.items(): items_predicted = data_predicted.get(key, []) n_items_true = len(items_true) n_items_predicted = min(len(items_predicted), k) if n_items_true == 0 or n_items_predicted == 0: continue n_correct_items = 0 precision = 0.0 for item_idx in range(n_items_predicted): if items_predicted[item_idx] in items_true: n_correct_items += 1 precision += <double>n_correct_items / <double>(item_idx + 1) average_precision_sum += <double>precision / <double>min(n_items_true, k) return average_precision_sum / <double>len(data_true) def metric(true_data, predicted_data, k=20): true_data_set = {k: set(v) for k, v in true_data.items()} return average_precision(true_data_set, predicted_data, k=k)
奖品和规则
奖金为60万卢布:
- 30万将获得冠军,
- 20万-第二名的参与者
- 10万-第三名的参与者。
规则是标准的:请勿破坏平台,仅使用一个帐户,避免与其他参与者交换私人代码且不能成为Okko和Rambler的雇员。
如何开始
即使是经验丰富的专业人士也可能很难开始参加比赛:您需要快速找出新的领域,理解和分析数据并整理新的库。
我们希望本文能够使您沉浸在在线电影的主题中,并充分详细地描述数据。 在包含任务的档案中,您将找到baseline.ipynb文件,该文件包含用于加载数据的代码以及使用K最近邻居算法的简单解决方案的示例。
如果对数据和域域的描述有任何不清楚之处,我们将很乐意在评论中回答您的问题。 您也可以在电报频道@boosterspro中提问 -有关比赛的主要讨论将在此处进行。
那么如何开始:
- 注册boosters.pro并加入@boosterspro ;
- 在比赛页面或这里下载数据;
- 打开
baseline.ipynb ,安装必要的软件包,执行所有代码并下载您的第一个解决方案; - 尝试修改基准以提高性能;
- 实验!
Rekko挑战赛将于2月18日开始。 直到莫斯科时间4月18日23:59:59才做出决定。
我们正在等待大家,祝你好运!
顺便说一句, 我们正在寻找员工 。 包括推荐系统的开发者。
UPD 02/26/2019:发现测试数据形成中的错误,将其替换为文件test_users.json 。 给所有参与者其他尝试。