几十年来,检测攻击一直是信息安全中的重要任务。 IDS实施的第一个已知示例可以追溯到1980年代初。
几十年后,整个攻击检测工具行业形成了。 当前,有各种类型的产品,例如IDS,IPS,WAF,防火墙,其中大多数提供基于规则的攻击检测。 使用异常检测技术来基于生产统计信息检测攻击的想法似乎不像过去那样现实。 还是一样?
Web应用程序中的异常检测
1990年代初,专门设计用于检测Web应用程序攻击的第一批防火墙开始出现在市场上。 从那时起,攻击方法和防御机制都发生了重大变化,攻击者可以随时领先一步。
当前,大多数WAF尝试如下检测攻击:反向代理服务器中内置了一些基于规则的机制。 最引人注目的示例是mod_security,它是Apache Web服务器的WAF模块,该模块于2002年开发。 使用规则识别攻击有几个缺点。 例如,规则无法检测到零日攻击,而专家可以轻松检测到相同的攻击,这不足为奇,因为人脑根本不像一组正则表达式那样工作。
从WAF的角度来看,攻击可以分为我们可以通过请求序列检测到的攻击,以及可以解决一个HTTP请求(响应)的攻击。 我们的研究重点是检测后面的攻击类型-SQL注入,跨站点脚本,XML外部实体注入,路径遍历,OS命令,对象注入等。
但是首先,让我们测试一下自己。
专家看到以下查询时会怎么想?
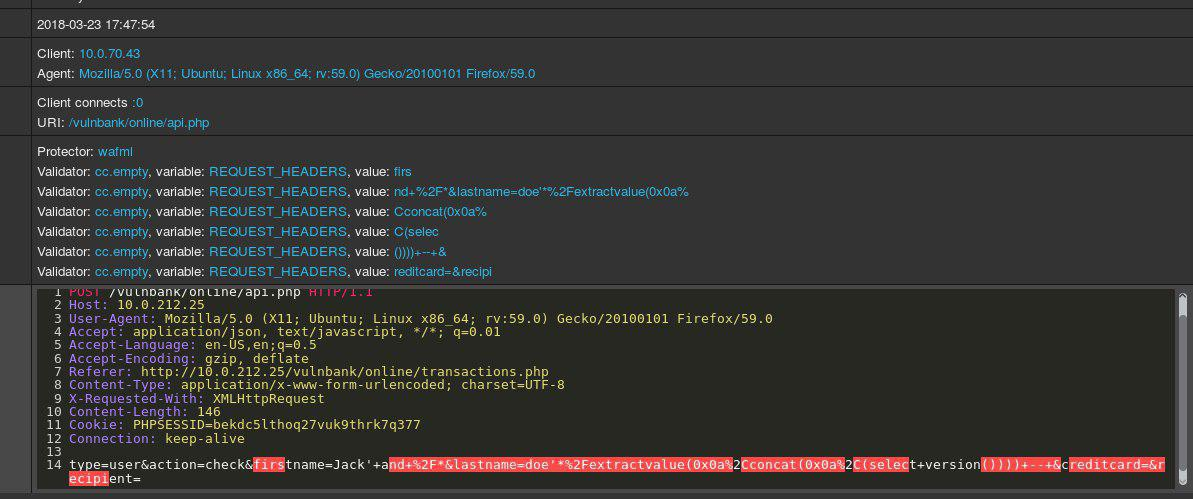
看一下对应用程序的HTTP请求示例:
如果您承担了检测对应用程序的恶意请求的任务,则很可能您希望观察一段时间的通常用户行为。 通过检查应用程序多个端点的查询,您可以大致了解非危险查询的结构和功能。
现在,您将获得以下查询以进行分析:

显而易见,这里有些问题。 这将需要一些时间来了解此处的真实情况,一旦您确定了请求中看起来异常的部分,就可以开始考虑攻击的类型。 从本质上讲,我们的目标是使我们的“检测攻击的人工智能”以与人类思维相似的方式发挥作用。
显而易见的是,乍一看似乎有些恶意的流量对于特定网站可能是正常的。
例如,让我们考虑以下查询:
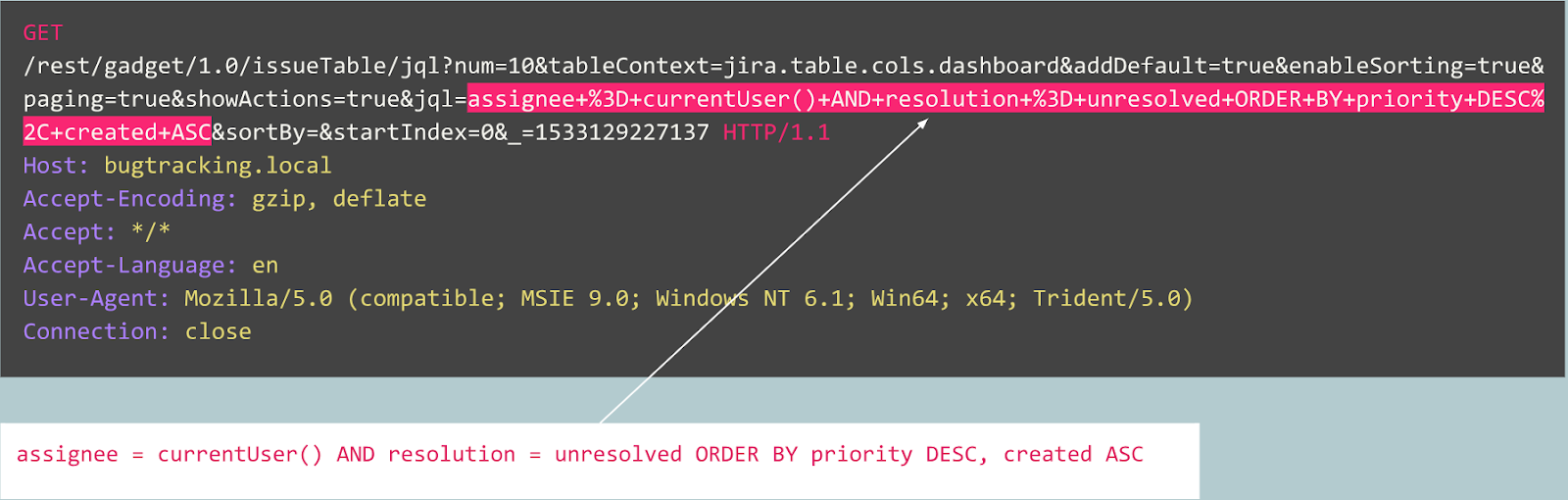
该查询是否异常?
实际上,此请求是Jira跟踪器中的错误的发布,并且是此服务的典型代表,这意味着该请求是正常的。
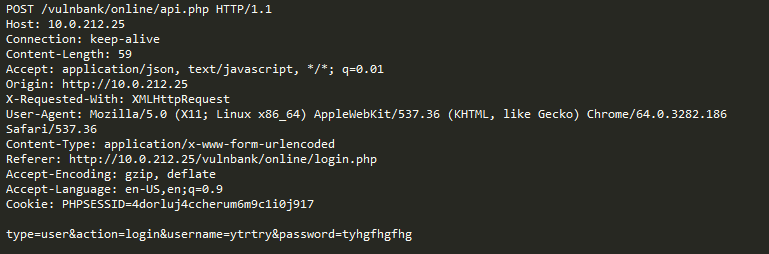
现在考虑以下示例:

乍一看,该请求看起来像是在基于Joomla CMS的网站上的普通用户注册。 但是,请求的操作是user.register而不是通常的registration.register。 第一个选项已过时,并且包含一个允许任何人注册为管理员的漏洞。 此漏洞的利用称为Joomla <3.6.4帐户创建/权限提升(CVE-2016-8869,CVE-2016-8870)。

我们从哪里开始
当然,首先,我们研究了该问题的现有解决方案。 数十年来,已经进行了各种尝试来创建基于统计信息或机器学习的攻击检测算法。 最受欢迎的方法之一就是解决分类问题,例如当类是“预期查询”,“ SQL注入”,XSS,CSRF等类时。通过这种方式,您可以使用分类器为数据集获得一定的准确性但是,从我们的角度来看,这种方法并不能解决非常重要的问题:
- 班级选择是有限的和预定的 。 如果您的模型在学习过程中由“正常查询”,SQLi和XSS三个类表示,并且在系统运行期间遇到CSRF或零时差攻击,该怎么办?
- 这些类的含义 。 假设您需要保护十个客户端,每个客户端运行完全不同的Web应用程序。 对于大多数用户而言,您不知道其应用程序的SQL注入实际上是什么样的。 这意味着您必须以某种方式人为地创建训练数据集。 这种方法不是最佳方法,因为最终您将学习分布与实际数据不同的数据。
- 模型结果的可解释性 。 好了,该模型产生了SQL Injection结果,现在呢? 您,更重要的是,您的客户(第一个看到警告的人,通常不是Web攻击专家)必须猜测模型中请求的哪一部分被认为是恶意的。
牢记所有这些问题,我们决定无论如何都要尝试训练分类器模型。
由于HTTP协议是文本协议,因此很明显,我们需要研究一下现代文本分类器。 一个众所周知的例子是IMDB电影评论数据集中的情感分析。 一些解决方案使用RNN对评论进行分类。 我们决定尝试使用RNN架构的类似模型,但有一些细微差异。 例如,自然语言RNN架构使用单词的向量表示,但是不清楚哪个单词以非自然语言(例如HTTP)出现。 因此,我们决定将符号的矢量表示用于我们的任务。
现成的表示方法不能解决我们的问题,因此我们使用了简单的字符映射到带有几个内部标记(例如
GO和
EOS数字代码。
在完成模型的开发和测试之后,所有以前预测的问题都变得显而易见,但是至少我们的团队从无用的假设转变为某些结果。
接下来是什么?
接下来,我们决定对模型结果的可解释性采取一些措施。 在某个时候,我们遇到了“注意力”注意力机制,并开始在我们的模型中实现它。 它给出了可喜的结果。 现在,我们的模型不仅开始显示类标签,而且还显示了传递给模型的每个字符的注意因素。
现在,我们可以可视化并在Web界面中显示检测到SQL注入攻击的确切位置。 这是一个很好的结果,但是列表中的其他问题仍未解决。
显然,我们应该继续朝着从注意力机制中受益的方向前进,而不是远离分类任务。 在阅读了有关序列模型的大量相关研究(关于注意力机制[2],[3],[4],关于矢量表示,关于自动编码器的体系结构)和实验数据之后,我们能够创建异常检测模型,最终会或多或少地像专家一样工作。
自动编码器
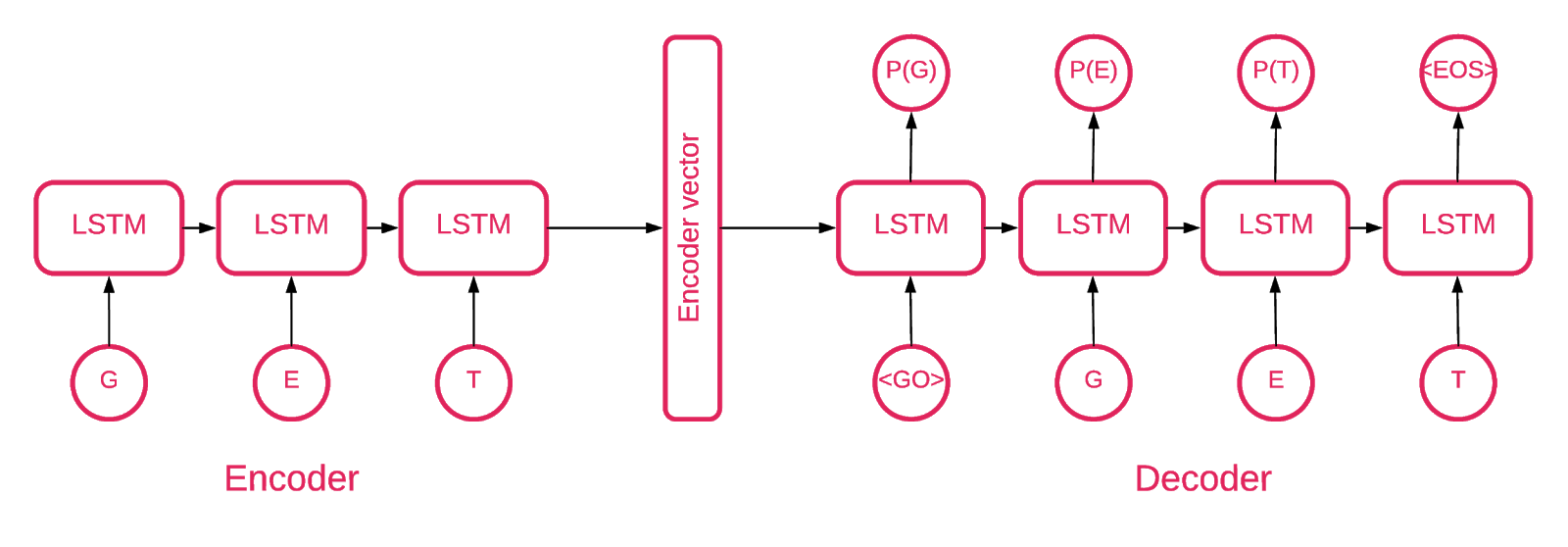
在某个时候,很明显,Seq2Seq [5]的体系结构最适合我们的任务。
Seq2Seq模型[7]由两个多层LSTM组成-编码器和解码器。 编码器将输入序列映射到固定长度的向量。 解码器使用编码器输出解码目标向量。 在训练中,自动编码器是一种模型,其中目标值设置为与输入值相同。
这个想法是要教网络解码它所看到的事物,或者换句话说,使身份更接近。 如果为受过训练的自动编码器指定了异常模式,则可能会以很高的错误率重新创建它,这仅仅是因为从未发现过。
解决方案
我们的解决方案包括几个部分:模型初始化,训练,预测和验证。 我们希望,存储库中的大多数代码都不需要解释,因此,我们将仅关注重要部分。
该模型是作为Seq2Seq类的实例创建的,该类具有以下构造函数参数:
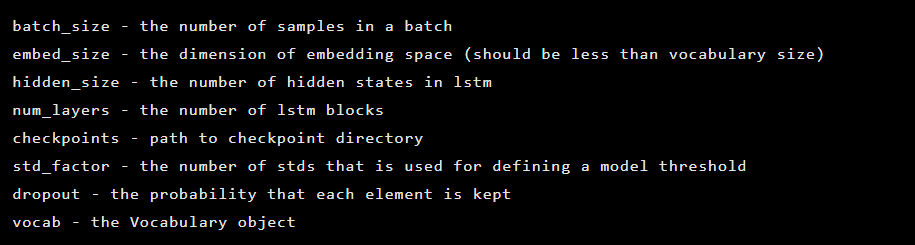
接下来,初始化自动编码器层。 第一个编码器:
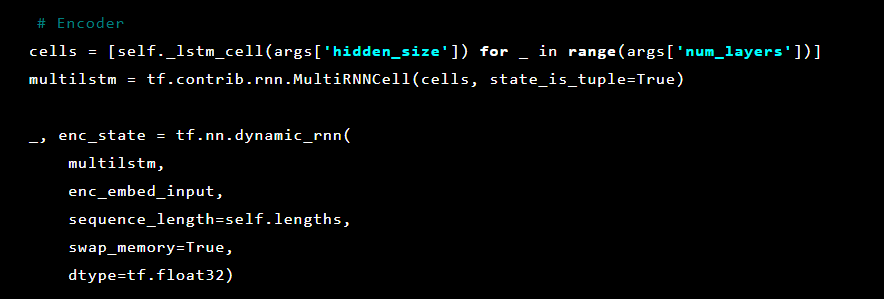
然后解码器:
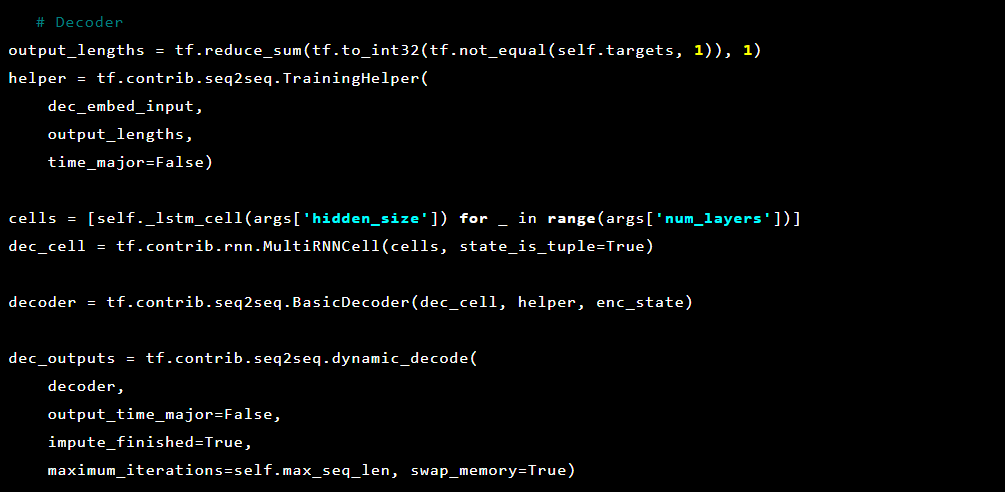
由于我们要解决的问题是检测异常,因此目标值和输入是相同的。 所以我们的feed_dict看起来像这样:
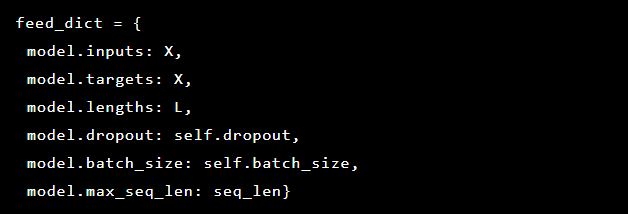
在每个时代之后,将最佳模型保存为参考点,然后可以下载该参考点。 为了进行测试,创建了一个Web应用程序,我们使用一个模型进行防御,以检查实际攻击是否成功。
受注意力机制的启发,我们尝试将其应用于自动编码器模型以标记此查询的异常部分,但注意到从最后一层派生的概率工作得更好。

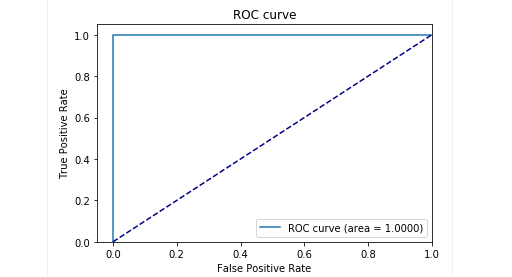
在延迟样品的测试阶段,我们获得了很好的结果:精度和召回率接近0.99。 ROC曲线趋向于1。看起来很棒,不是吗?
结果
Seq2Seq自动编码器的建议模型能够以非常高的准确性检测HTTP请求中的异常。
该模型的行为就像一个人:它仅研究Web应用程序的“正常”用户请求。 并且当它检测到请求中的异常时,它会选择请求的确切位置,它将其视为异常。
我们在测试应用程序的一些攻击下测试了该模型,结果令人鼓舞。 例如,上图显示了我们的模型如何检测Web表单中分为两个参数的SQL注入。 此类SQL注入称为分段式攻击:部分攻击有效载荷以几个HTTP参数传递,这使得很难检测基于规则的WAF,因为它们通常分别测试每个参数。
模型代码以及培训和测试数据以Jupyter笔记本电脑的形式发布,以便每个人都可以重现我们的结果并提出改进建议。
总结
我们认为,我们的任务相当艰巨。 我们希望以最小的努力(首先是避免由于解决方案的复杂性而导致的错误),找到一种检测攻击的方法,就像魔术一样,它学会了决定好与坏。 其次,我想避免人为因素引起的问题,因为专家可以准确地确定什么是攻击的迹象,什么不是攻击的迹象。 总结一下,我想指出的是,我们认为和我们的问题一样,具有Seq2Seq架构的自动编码器在搜索异常问题上也表现出色。
我们还想解决数据可解释性的问题。 使用复杂的神经网络架构通常非常困难。 在一系列转换中,最后很难说到底数据的哪一部分最能影响决策。 但是,在重新考虑模型进行数据解释的方法之后,事实证明这足以让我们从最后一层获得每个符号的概率。
应当注意,这不是生产版本。 我们无法在实际产品中披露此方法的实现细节,并且我们要警告,仅将这种解决方案嵌入到某些产品中是行不通的。
GitHub存储库:
goo.gl/aNwq9U作者 :Alexandra Murzina(
murzina_a ),Irina Stepanyuk(
GitHub ),Fedor Sakharov(
GitHub ),
Arseniy Reutov(
Raz0r )
参考文献:
- 了解LSTM网络
- 注意和增强递归神经网络
- 注意就是您所需要的
- 注意就是您所需要的(带注释)
- 神经机器翻译(seq2seq)教程
- 自动编码器
- 神经网络的序列到序列学习
- 在Keras中构建自动编码器