pudge是用Go标准库编写的可嵌入键/值数据库。
我将详细介绍与现有解决方案的根本区别。
无状态pudge.Set("../test/test", "Hello", "World")
Puj会自动创建测试数据库,包括子目录,或打开它。 无需存储表状态,您可以安全地将值存储在多线程应用程序中。 Pooj是线程安全的。
无类型在puj中,您可以编写字节,字符串,数字或结构。 无需担心将数据转换为二进制表示形式。
type Point struct { X int Y int } for i := 100; i >= 0; i-- { p := &Point{X: i, Y: i} db.Set(i, p) } var point Point db.Get(8, &point) log.Println(point)
查询系统Puj提供了按特定顺序提取键的功能,包括具有限制的选择,缩进,排序和按前缀选择。
keys, _ := db.Keys(7, 2, 0, true)
上面的代码类似于SQL查询:
select keys from db where key>7 order by keys asc limit 2 offset 0
请注意,排序键是“惰性”。 另一方面,密钥存储在内存中,并且运行很快。
平行性像大多数现代数据库一样,Pooj使用非阻塞读取模型,但是写入文件会阻塞所有操作。 但是您可以动态创建/打开文件,从而最大程度地减少锁的数量。 在Puja中没有“数据库已打开”错误。 http路由器中的示例用法:
func write(c *gin.Context) { var err error group := c.Param("group") counter := c.Param("counter") db, err := pudge.Open(group, cfg) if err != nil { renderError(c, err) return } _, err = db.Counter(counter, 1) if err != nil { renderError(c, err) return } c.String(http.StatusOK, "%s", "ok") }
引擎尽管体积很小,但Puj支持两种数据存储模式。 在内存和磁盘上。 默认情况下,puj仅将数据(值)存储在磁盘上。 但是,如果您愿意,可以启用将数据存储在内存中的模式。 在这种情况下,将根据请求或关闭数据库时将它们刷新到磁盘。
现况Pooj在家庭项目和生产中均使用,如下图所示-基于puj的对HTTP服务器的请求数,并且请求数大于20毫秒
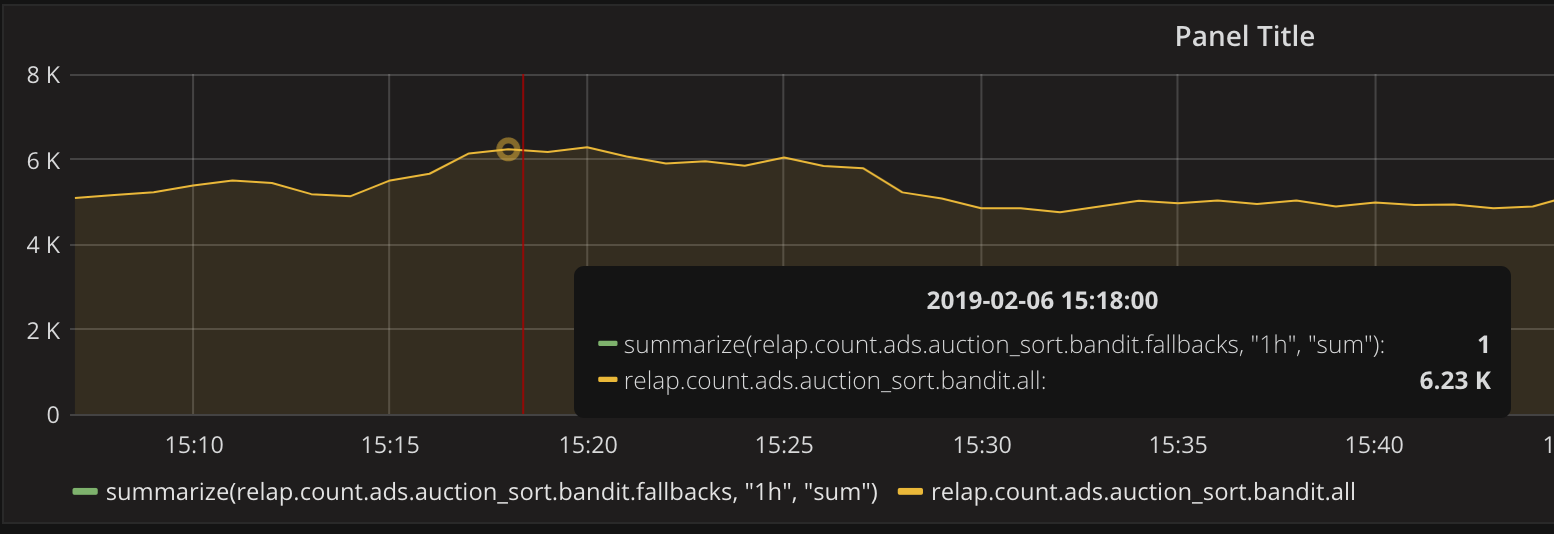
在这种情况下,法会以完全同步模式打开,并且在进行fsync时会发生明显的延迟(超过20 ms)。 但幸运的是,百分比没有那么多。
在
项目页面上,您可以找到更多链接,其中包含将puja集成到各种项目中的示例。
速度在带有基准'y的
存储库中 ,您可以将puj与其他数据库进行比较:
测试1
Number of keys: 1000000 Minimum key size: 16, maximum key size: 64 Minimum value size: 128, maximum value size: 512 Concurrency: 2
| Pogreb
| goleveldb
| 螺栓
| 徽章
| 帕吉
| 慢戳
| 帕吉(记忆)
|
1M(放入+获取),秒
| 187
| 38
| 126
| 34
| 23
| 23
| 2
|
1M推/秒
| 5336
| 34743
| 8054
| 33539
| 47298
| 46789
| 439581
|
1M Get,操作数/秒
| 1782423
| 98406
| 499871
| 220597
| 499172
| 445783
| 1652069
|
文件大小Mb
| 568
| 357
| 552
| 487
| 358
| 358
| 358
|
Pooja在写入速度和读取速度之间的比例上非常平衡。 它不是为读取或写入而优化的高度专业化的数据库。 在高读取速度下-保持相当高的写入速度。 但是,可以通过将记录并行化为不同文件来进一步增加(如在LSM Tree引擎中所做的那样)。
链接到测试中使用的数据库:
他们要求我将其与memcache和redis进行比较,但是由于与数据库数据进行交互时,大部分时间都花在了网络接口上,因此这并不完全公平。 另一方面,尽管Puja由于多线程而获胜,即使它已将数据写入磁盘。
进一步发展- 交易次数 将写入池的写入请求与错误发生时的自动回滚结合起来会很方便。
- 限制密钥寿命的能力(例如内存缓存/ cassandra中的TTL等)
- 缺少服务器。 将Puja嵌入到现有的微服务中很方便,但是很可能会出现一个单独的服务器。 作为单独项目的一部分。
- 手机版。 适用于Android,iOS以及Flutter的插件。