目的是创建一个可以识别图像和视频代码的mac应用程序。
我想确保即使使用大量代码,也能在不到一秒钟的时间内识别出文本。
编写代码的语言始终是英语,并且所有字母之间的宽度都相同(等宽字体)-这是用于编程的语言,在这些字体中很容易看到1和I,0和O等之间的差异,这使问题变得更加容易。
简而言之,任务分为两部分:
1.查找带有边界的字母本身
苹果的新框架Vision在其中做得很好。
2.在给定范围内识别字母
我决定不费力地检查正方形的某些像素,在该像素的边界内有字母(比方说:中心,角,边),并从是否存在字母开始对字母进行分类。
说明性示例:

这是那棵树的样子这是一部分,因为所有内容都不适合,因此没有必要。
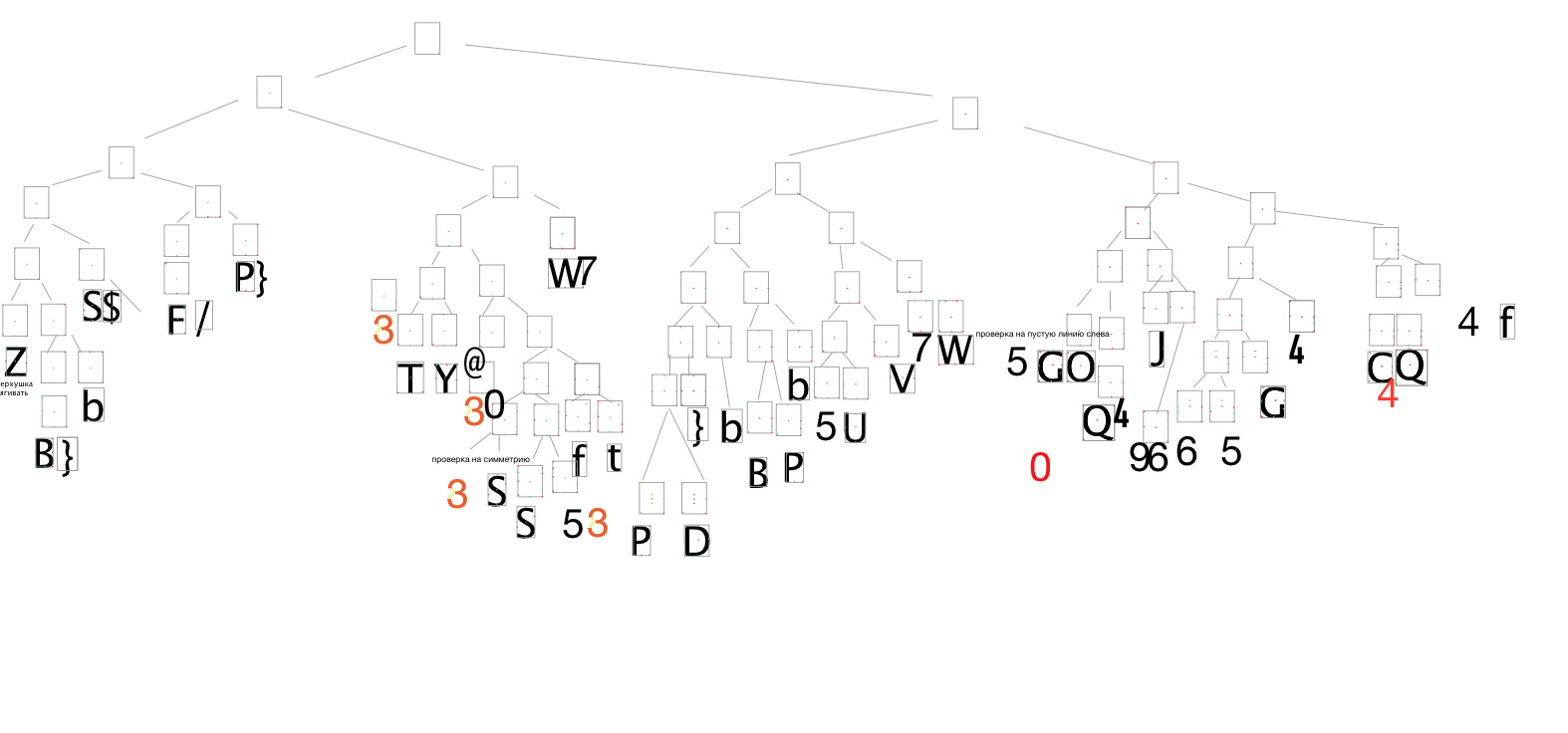
怎样将这个原理图转换为代码,以免在代码中钻洞,以至于变得如此明显?
这就是二叉树的解救之道。 这是它的框架。
enum Tree<Node, Result> {
现在,基于此,我们可以将整个图形传输到代码中。
这就是一块木头看起来更大的样子。

您可以非常直观地分解所有内容,并轻松找到所需的字母。
最后一刻,这就是模型本身的外观,其中所有工作都在其中进行。
extension Tree where Node == OCROperations, Result == String { func find(_ colorChecker: LetterExistenceChecker, with frame: CGRect) -> String? { switch self { case .empty: return nil case .r(let element): return element case let .n(operation, left, right): let exist = operation.action(colorChecker, frame) return (exist ? left : right).find(colorChecker, with: frame) } } }
在这棵树中,我们传递了LetterExistenceChecker类,该类负责检查所需正方形边界内特定点的字母像素是否存在。 当然,我省略了许多细节,否则这篇文章太麻烦了。 在这里,不仅是本文提到的这两个阶段,而且还有很多,但它们被省略了,因为目标是展示如何使用二叉树和枚举。
这是该程序工作方式的演示,请注意,由于目标是仅识别带有代码的文本,因此我决定忽略所有非代码文本,以便该程序仅查找带有代码的文本。
我很高兴听到您的评论和批评。