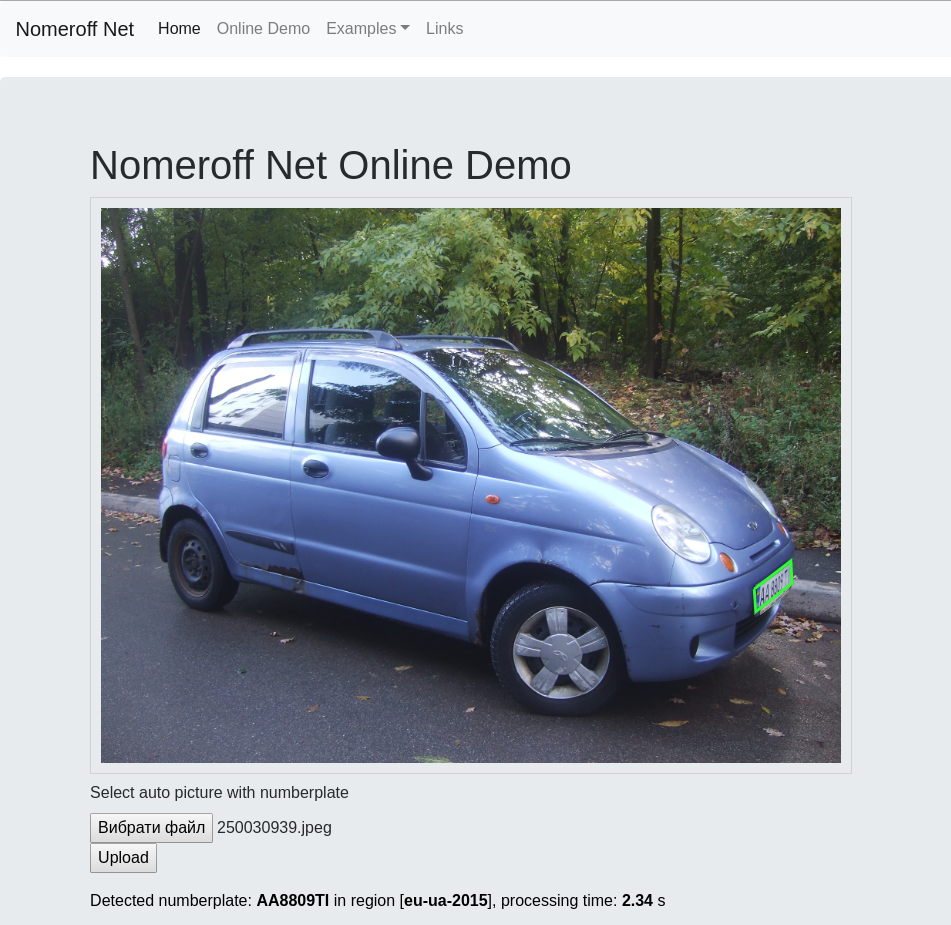
我们继续讲述如何为那些可以用python编写hello world应用程序的人识别车牌的故事! 在这一部分中,我们将学习如何训练正在寻找给定对象区域的模型,并且还将学习如何编写一个简单的RNN网络,该网络将比一些商业同行更好地应对读数。
在这一部分中,我将告诉您如何训练Nomeroff Net的数据,如何获得较高的识别质量,如何配置GPU支持并以一个数量级的速度加速所有工作...
我们训练Mask RCNN来找到带有数字的区域
当然,您不仅可以找到数字,还可以找到需要查找的任何其他对象。 例如,您可以类推地查找信用卡并阅读其详细信息。 通常,在图像中找到对象所在的蒙版称为“实例分割”任务(我已经在第一部分中对此进行了介绍)。
现在我们将弄清楚如何训练网络来解决这个问题。 实际上,这里几乎没有编程,所有这些都归结为单调,乏味,统一的数据标记。 是的,是的,在您标记出第一百个之后,您将理解我的意思:)
因此,数据准备算法如下:
要在实践中测试经过训练的模型,在
项目示例中,将
MASK_RCNN_MODEL_PATH替换为模型的路径。
根据您的要求改进车牌分类器
找到带有牌照的区域后,您需要尝试确定我们可以识别的州/号码类型。 在此,普遍化会影响识别的质量。 因此,理想情况下,您需要训练一个分类器,该分类器不仅要确定数字是哪个国家,而且还要确定该数字的设计类型(字符的位置,给定数字类型的符号选项)。
在我们的项目中,我们实施了支持识别乌克兰,俄罗斯联邦和整个欧洲的数字。 欧洲号码的识别质量稍差一些,因为存在设计不同的数字,并且发现的字符数量也有所增加。 也许随着时间的流逝,将有用于“ eu-ee”,“ eu-pl”,“ eu-nl”,...的单独的识别模块。
在对车牌进行分类之前,您需要将其“裁剪”出图像并进行归一化,换句话说,将所有变形最大程度地消除,然后得到一个整洁的矩形,将对其进行进一步的分析。 事实证明,这项任务非常艰巨,我什至不得不回忆起学校的数学知识,并编写了k-means :)聚类算法:)的专门实现。 处理此问题的模块称为RectDetector,这是归一化数字的外观,我们将对其进行进一步分类和识别。

为了以某种方式使创建用于分类数字的数据集的过程自动化,我们
在nodejs上开发了一个
小型管理面板 。 使用此管理面板,您可以在车牌上标记该铭文及其所属的类别。
可以有几个分类器。 在我们的案例中,根据数字的类型以及是否在照片中进行草绘/绘制。
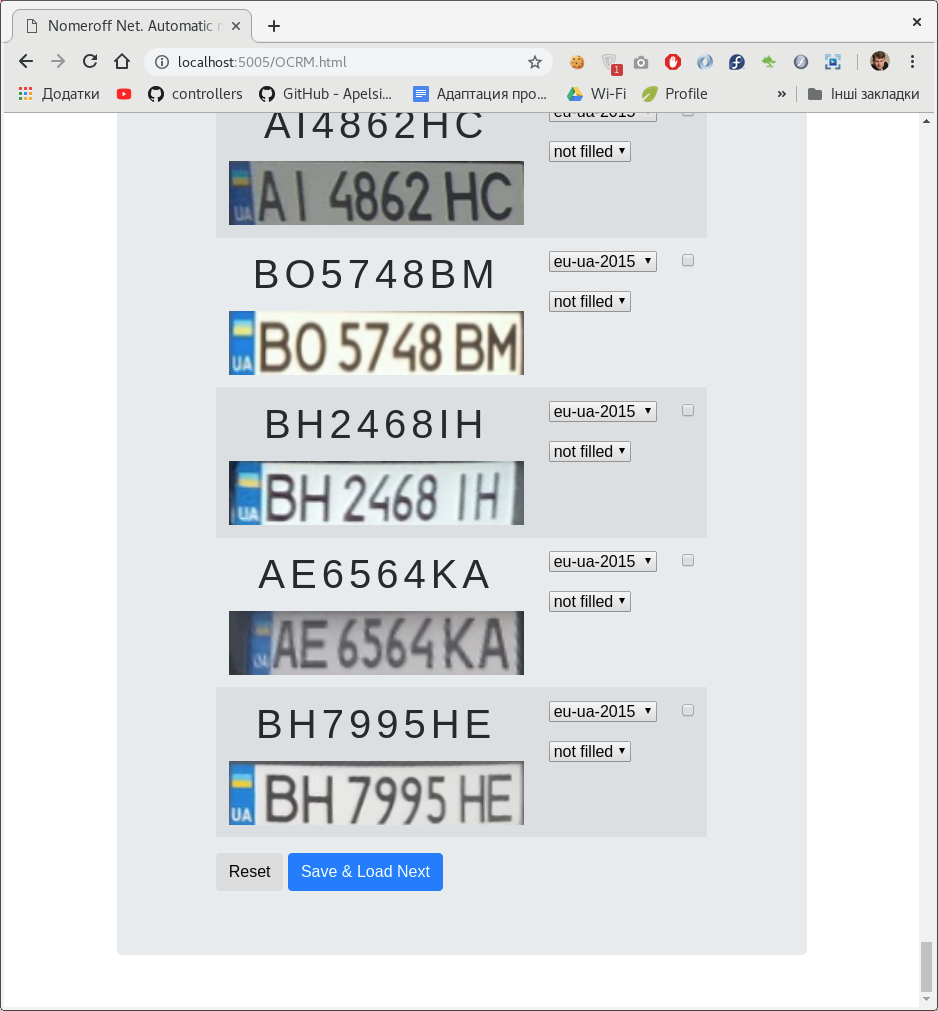
标记数据集后,我们将其分为训练,验证和测试样本。 作为示例,请下载我们的autoriaNumberplateOptions3Dataset-2019-05-20.zip
数据集,以查看那里的一切
工作原理 。
由于选择已被标记(已审核),因此您需要在随机json文件中将“ isModerated”:1更改为“ isModerated”:0,然后启动管理面板 。
我们训练分类器:
培训脚本
train / options.ipynb将帮助您获取模型版本。 我们的示例显示,对于区域/车牌类型的分类,对于“数字是否涂满?”的分类,我们的准确性为
98.8% 。 在我们的数据集中
占99.4% 。 同意,结果很好。
训练您的OCR(文本识别)
好吧,我们找到了带有数字的区域,并将其标准化为一个包含带有数字的铭文的矩形。 我们如何阅读文字? 最简单的方法是通过FineReader或Tesseract运行它。 质量将不是“很好”,但是具有良好分辨率的区域和数字可以使您获得80%的精度。 实际上,这的准确性还不错,但是,如果我告诉您,您可以获得
97%的资源,同时又大大减少了计算机资源的使用量? 听起来不错-试试吧。 略有不同寻常的体系结构适合于这些目的,其中同时使用了卷积层和循环层。 该网络的架构如下所示:
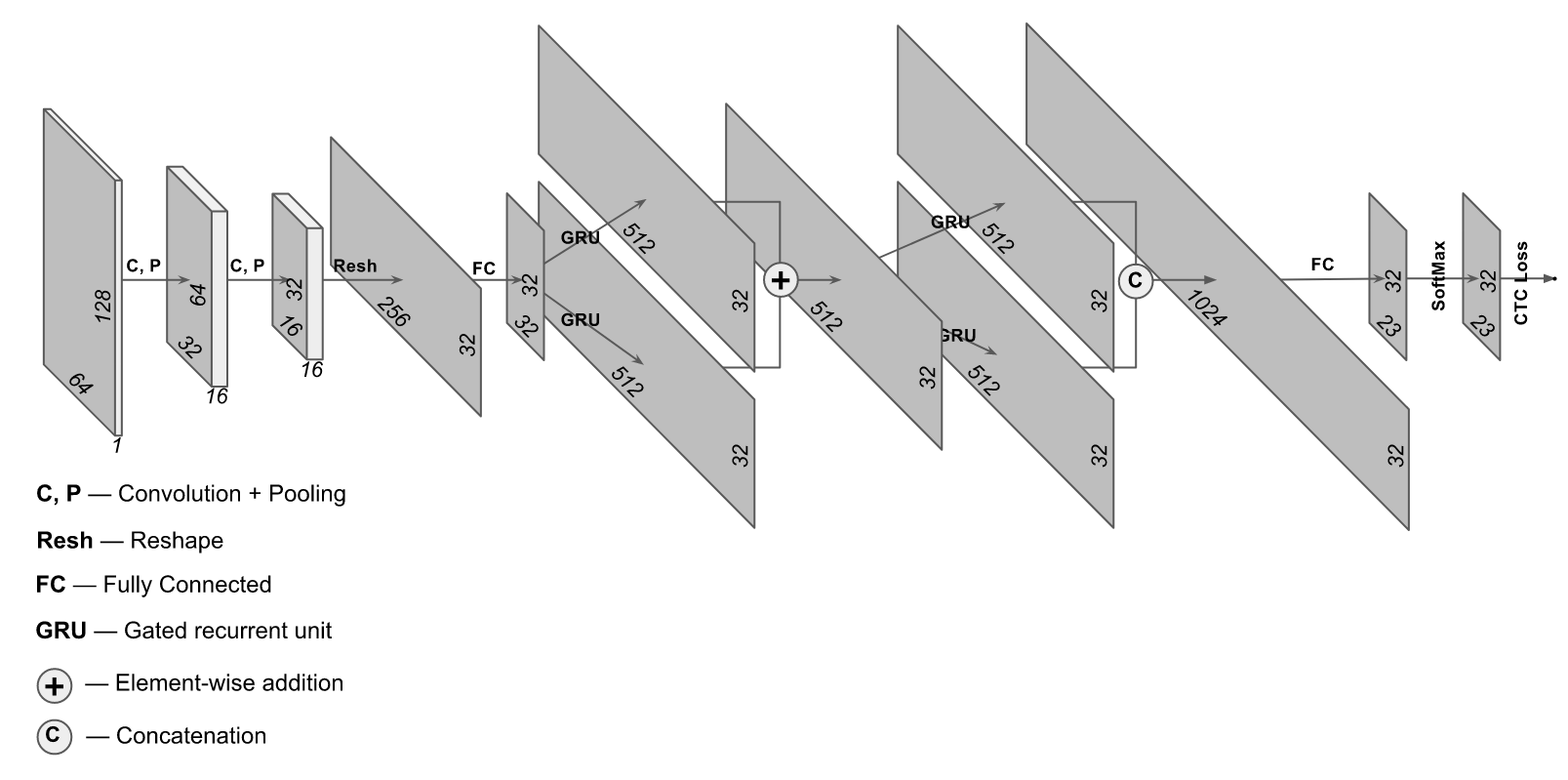
该实现取自
https://supervise.ly/网站,我们对其进行了一些修改,以训练真实照片(在监督网站上,可以选择进行合成采样)
现在开始有趣的部分,至少标记5,000个数字:)。 我们
用“旧”设计划出了大约
100,000乌克兰人 ,
〜50,000乌克兰人 ,
〜6,500欧洲人 ,
〜10,000 RF 。 这是开发中最困难的部分。 您甚至都无法想象我在电脑椅上睡着了多少次,每天要花几个小时来调节下一部分数字。 但是标记的真正英雄是
dimabendera-他标记了所有内容的2/3,(如果您了解完成所有工作的无聊性,请给他加分:)
您可以尝试以某种方式使该过程自动化,例如,先前已使用Tesseract识别了每张图像,然后使用
我们的管理面板更正错误。
请注意:同一管理面板用于在数字上标记分类器和OCR。 当然,您可以在此处和那里加载相同的数据,除了草绘的数字。
如果您至少标记了5000个数字并可以训练您的OCR,请随时与上级为自己安排奖品,我相信此测试不适合is弱的人!
入门培训
train / ocr-ru.ipynb脚本为俄罗斯数字训练模型,其中有
乌克兰和
欧洲的示例。
请注意,在训练设置中只有一个时代(一次通过)。
训练此类数据集的功能是每次尝试都会有非常不同的结果,在每次训练之前,数据会以随机顺序混合,有时对于训练而言“不太好”。 我建议您尝试至少5次,同时控制测试数据的准确性。 通过不同的发射尝试,我们的准确性可能从
87% “跳升”
到97% 。
一些建议 :
- 无需以新的方式初始化所有内容,只需重新启动line model = ocrTextDetector.train(mode = MODE),直到获得预期的结果
- 准确性差的原因之一是数据不足。 如果您不喜欢它,我们会一次又一次地对其进行标记,有时质量会停止增长,对于每个数据集不同的情况,您可以关注10,000个带有标签的示例的数量
- 如果您安装了NVIDIA CuDNN驱动程序,则训练会更快,在训练脚本中更改MODE =“ gpu”值,将连接CuDNNGRU而不是GRU层,这将导致三倍加速。
关于为NVIDIA GPU设置张量流的一些知识
如果您是NVIDIA GPU的满意所有者,则可以不时加快处理速度:模型训练和推理(识别模式)编号。 问题是要正确安装和编译所有内容。
我们在ML服务器上使用Fedora Linux(这是历史上发生的)。
对于使用此操作系统的用户,大概的操作顺序如下:
如果您无法使用gpu支持构建tensorflow,则可以通过docker启动所有内容,除了docker外,还需要安装nvidia-docker2软件包。 在docker容器中,您可以运行jupyter notebook,然后在其中运行所有内容。
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
有用的链接
我还要感谢2expres,
glassofkvass habrausers为照片提供了编号,并为
dimabendera写了大部分代码并标记了Nomeroff Net项目的大部分数据。
UPD1:由于Dmitri和我在个人标准问题上写了有关数字识别,一堆带有gpu的tensorflow等问题。 我和Dmitry给出了相同的答案,我想以某种方式优化此过程。
我们建议使评论中的信函更加结构化,并按主题划分。 GitHub上为此提供了便利的功能。 将来,请不要在评论中提出问题,而应在
github Nomeroff Net上的
主题问题中提出问题UPD2:随着时间的推移,数据集也出现了:
哈萨克数 ,
格鲁吉亚数