您是否碰巧遇到某种简单的游戏,以为人工智能可以应付这种情况? 过去,我决定尝试创建这样的机器人播放器。 此外,现在有许多用于计算机视觉和机器学习的工具,可让您在不深入了解实现细节的情况下构建模型。 普通凡人可以从头开始构建几个月的神经网络而无需建立神经网络。

在裁减下,您将找到为Clash Royale游戏创建概念验证机器人的过程,其中我使用了Scala,Python和CV库。 利用计算机视觉和机器学习,我试图为像现场玩家一样互动的游戏创建一个机器人。
我的名字叫Sergey Tolmachev,是Waves Platform的首席Scala开发人员,并在Binary District教授
Scala课程 ,并且在业余时间学习其他技术,例如AI。 我想通过一些实践经验来增强所学技能。 与AI竞赛不同,在您的机器人与其他用户的机器人进行对抗的情况下,Clash Royale可以与人对抗,这听起来很有趣。 您的机器人可以学习击败真正的玩家!
大逃杀的游戏机制
游戏的机制非常简单。 您和您的对手有三座建筑物:一座堡垒和两座塔。 游戏开始前,玩家会收集套牌-8个可用单位,然后用于战斗。 它们具有不同的级别,可以进行抽水,收集更多这些单元的卡并购买更新。
游戏开始后,您可以将可用单位与敌方塔保持安全距离,同时消耗法力单位,在游戏中缓慢恢复魔法值。 单位被送到敌人的建筑物,并被沿途遇到的敌人分散注意力。 玩家只能控制单位的初始位置-他只能通过设置其他单位来影响其进一步的移动和损坏。
仍然有可以在野外任何地方使用的咒语,它们通常以不同的方式对单位造成伤害。 咒语可以克隆,冻结或加速一个区域中的单位。
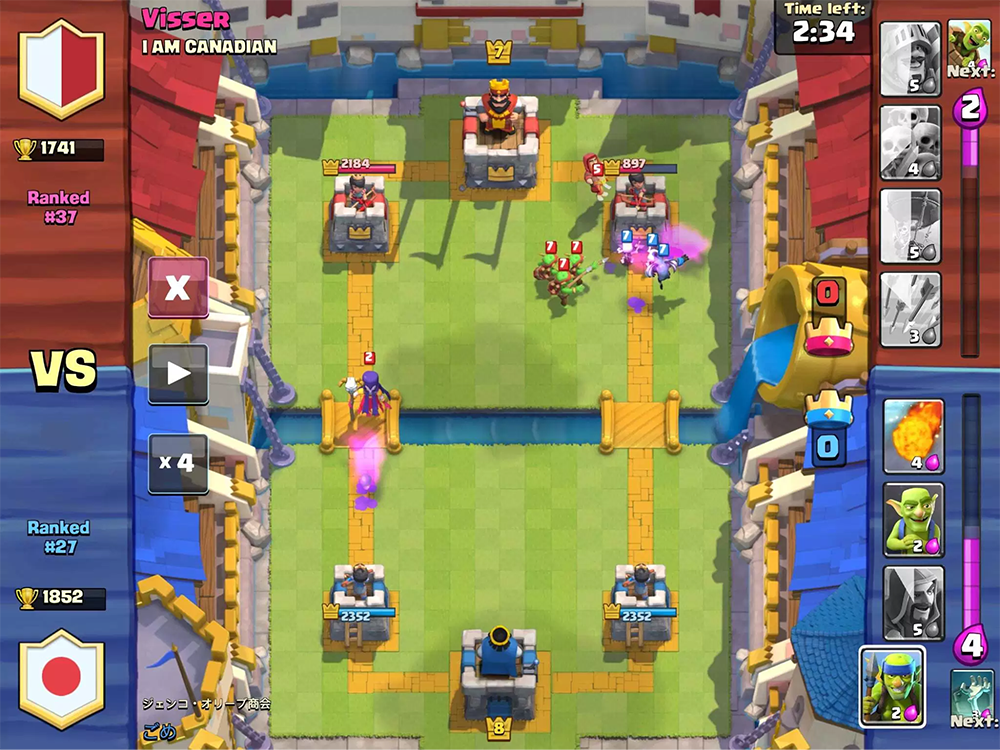
游戏的目标是摧毁敌人的建筑物。 为了获得完全的胜利,您必须摧毁堡垒,或者在游戏两分钟后摧毁更多建筑物(规则取决于游戏模式,但总体来说听起来像这样)。
在游戏过程中,您需要考虑单位的移动,可能的法术力数量和当前敌方牌。 您还需要考虑设备的安装如何影响比赛场地。
建立解决方案
Clash Royale是一款手机游戏,因此我决定在Android上运行该游戏,并通过ADB与之互动。 这将支持模拟器或真实设备的工作。
我决定像其他许多游戏AI一样,该机器人应在Perception-Analysis-Action算法上运行。 游戏中的整个环境都显示在屏幕上,并且通过单击屏幕可以与游戏进行交互。 因此,该机器人应该是一个程序,其输入内容描述游戏的当前状态:单位和建筑物的位置和特征,当前可能出现的卡牌和法力值。 在输出端,机器人应给出一个将单元粘贴在其中的坐标数组。
但是在创建机器人本身之前,有必要解决从屏幕截图中提取有关游戏当前状态信息的问题。 总的来说,本文的其他内容专门用于此任务。
为了解决此问题,我决定使用Computer Vision。 也许这不是最佳解决方案:没有大量经验和资源的简历显然有局限性,无法在人的层面上认清一切。
从内存中获取数据会更准确,但是我没有这种经验。 根是必需的,总的来说,此解决方案看起来更复杂。 如果您在设备内部查找带有堆JVM的对象,是否在此处也可以实现实时速度还不清楚。 另外,我想解决的不仅仅是简历问题。
从理论上讲,可以制造一个代理服务器并从那里获取信息。 但是游戏的网络协议经常变化,Internet上的代理服务器遇到了,但是很快就过时了,不受支持。
可用的游戏资源
首先,我决定熟悉游戏中的可用材料。 我找到了一个
工匠俱乐部,他们抽出了丰富的游戏资源
[1] [2] 。 首先,我对单位的图片感兴趣,但是在未包装的游戏包中,它们以图块地图(单位组成的碎片)的形式呈现。
我还发现了单元动画帧的粘贴脚本(虽然不是很完美)-它们对于训练识别模型很有用。

另外,在资源中,您可以找到带有各种游戏数据的csv-HP量,对不同等级单位的损坏等。这在创建机器人逻辑时非常有用。 例如,从数据中可以清楚地看到,该字段被划分为18 x 29个像元,并且只能在其上放置单位。 也有所有单位图的图像,这将在以后对我们有用。
懒人的计算机视觉
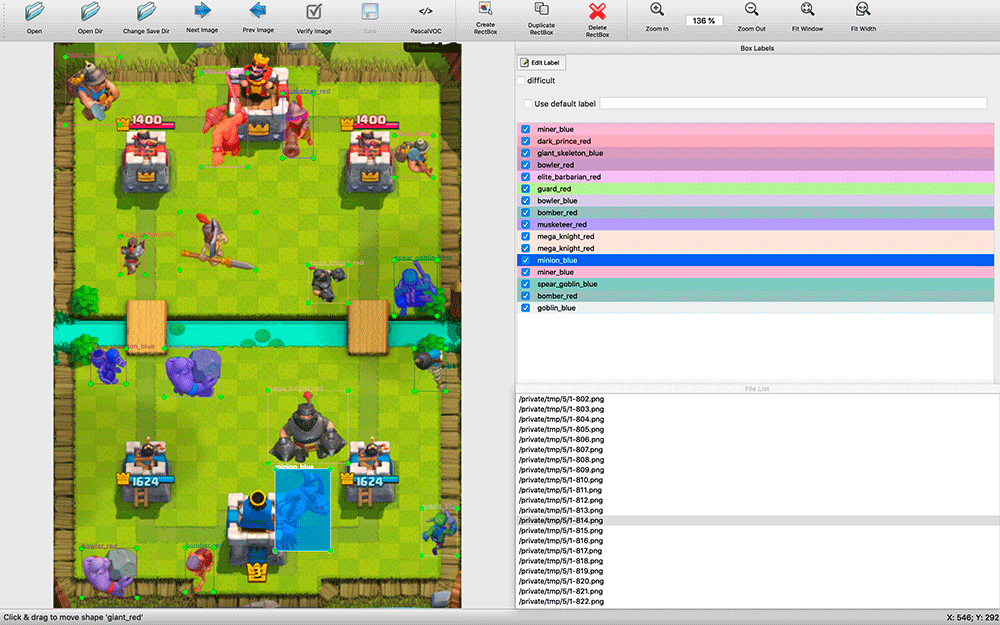
在搜索了可用的CV解决方案之后,很明显,无论如何,都必须在标记的数据集上对它们进行训练。 我已经截取了屏幕截图,并且已经准备好用双手标记出一定数量的屏幕截图。 事实证明这是一个挑战。
寻找可用的识别程序需要一些时间。 我选择了
labelImg 。 我发现的所有注释应用程序都是相当原始的:许多不支持键盘快捷键,对象选择及其类型的方便程度远不及labelImg。
在标记期间,事实证明拥有应用程序的源代码很有用。 我每两秒钟拍摄一次屏幕截图。 屏幕截图中有很多对象(例如,一群骷髅),我对labelImg进行了修改-默认情况下,在标记下一张图像时,将采用上一张图像的标签。 通常,只需将它们移动到单元的新位置,删除死单元并添加一些出现的单元,而不是从头开始标记。

事实证明,该过程非常耗资源-在安静模式下的两天内,我发布了约200张屏幕截图。 该样本看起来很小,但我决定开始进行实验。 您总是可以添加更多示例,并提高模型的质量。
在进行标记时,我不知道我将使用哪种培训工具,因此我决定将标记结果保存为VOC格式-一种保守且看似通用的格式。
可能会出现问题:为什么不仅仅通过完全一致的方式查找单位的逐像素图像? 问题在于,为此,必须寻找大量不同单位动画的不同帧。 这几乎行不通。 我想制定一个支持不同权限的通用解决方案。 此外,根据对它们施加的效果(冻结,加速),设备可以具有不同的颜色。
我为什么选择YOLO
我开始探索可能的图像识别解决方案。 我研究了各种算法的应用:OpenCV,TensorFlow,Torch。 我想尽快识别,甚至牺牲准确性,并尽快获得POC。
阅读
文章之后 ,我意识到我的任务不适合HOG / LBP / SVM / HAAR / ...分类器。 尽管它们很快,但根据每个单位的分类器,它们将不得不多次应用,然后逐一应用到图片中进行搜索。 此外,它们的工作原理在理论上将得出较差的结果:例如,单元在左右移动时可以具有不同的形状。
从理论上讲,使用神经网络可以一次将其应用于图像,并获得不同类型的所有单位及其位置,因此我开始研究神经网络。 TensorFlow已发现对卷积神经网络(CNN)的支持。 原来,没有必要从头开始训练神经网络-您可以
重新训练现有的强大网络 。
然后,我找到了一种更实用的YOLO算法,该算法可以降低复杂度,因此必须提供一种高速搜索算法,而又不牺牲太多准确性(在某些情况下,它会超过其他模型)。
YOLO网站承诺使用微小的模型和更小的优化网络可以实现巨大的速度差异。 YOLO还允许您为任务重新训练完成的神经网络,而
Darknet是一个使用本机开发了YOLO的各种神经元的开源框架,它是一个简单的本机C应用程序,所有与它相关的工作都通过其参数调用进行。
TensorFlow是用Python编写的,实际上是一个Python库,并且使用了自己编写的脚本来使用,您需要弄清楚这些脚本或对其进行优化以适合您的需求。 对于某些人来说,TensorFlow的灵活性可能是一个加号,但是如果不进行详细介绍,几乎不可能快速使用它并使用它。 因此,在我的项目中,选择权落在了YOLO上。
模型制作
为了进行模型训练,我安装了Ubuntu 18.10,提供了组件包,NVIDIA的OpenCL包和其他依赖项,并构建了Darknet。
Github的一
节中有简单的步骤来重新训练YOLO模型 :您需要下载模型和配置,进行更改并开始重新训练。
首先,我想尝试重新训练一个简单的YOLO模型,然后尝试Tiny进行比较。 但是,事实证明,要训练简单的模型,您需要4 GB的视频卡内存,而我只购买了3 GB的NVIDIA GeForce GTX 1060图形卡用于游戏。 因此,我只能立即训练Tiny模型。
我在图像上标记的单位是VOC格式,YOLO使用其自己的格式,因此我使用
convert2Yolo实用程序转换注释文件。
经过一夜的200张屏幕截图训练后,我得到了第一个结果,它们使我感到惊讶-该模型确实能够正确识别某些东西! 我意识到自己朝着正确的方向前进,因此决定做更多的教学示例。

我不想继续布置屏幕截图,我想起了有关单元动画中的帧的信息。 我用他们的班级标记了所有小图片,并尝试在此背景上训练网络。 结果非常糟糕。 我认为该模型无法从小图片中选择正确的图案以用于大图片。
之后,我决定将它们放置在战场的现成背景中,并以编程方式创建VOC标记文件。 事实证明,这样的合成屏幕截图具有100%自动准确的布局。
我在Scala中编写了一个脚本,该脚本将屏幕截图分为16个4x4正方形,并将单位设置在其中心,这样它们就不会彼此相交。 该脚本还允许我自定义培训示例的创建-遭受损坏时,单位以其团队的颜色(红色/蓝色)绘制,并且在分类期间我分别识别不同颜色的单位。 除了弄脏外,受到损坏的不同团队的单位在衣服上也略有不同。 另外,我随机增加和减少了一些单位,因此该模型学会了在很大程度上不依赖单位的大小。 结果,我学会了如何创建成千上万个与真实屏幕截图大致相似的训练示例。
一代并不完美。 通常,单位会放置在建筑物的顶部,尽管在游戏中它们会在建筑物的后面。 尽管在游戏中这种情况并非罕见,但没有重叠部分的例子。 但是到目前为止,我决定忽略它。

经过数天的训练后,每天对200个真实屏幕截图和5000张生成的图像进行混合训练后获得的模型,每天对这些屏幕截图进行测试时,每天在训练过程中重新生成这些图像,结果均不理想。 这并不奇怪,因为生成的图片与真实图片有很多差异。
因此,我将结果模型重新训练在一个平均样本上,其中我的屏幕截图只有200个。 之后,她开始工作得更好。
该死的耻辱我为处理“好得多”这类不科学的措施表示歉意,但我不知道如何快速对图像进行交叉验证,因此我尝试了一组非训练集的屏幕截图,以查看结果是否令我满意。 这是最重要的。 我们很懒,我们正在制作原型,对吧?
改进模型的下一步是可以理解的-用手标记更多真实的屏幕截图,并在模型上训练它们,并在生成的屏幕截图上进行预训练。
让我们开始吧
我决定用Python编写一个机器人-它具有许多可用于ML的工具。 我决定将我的模型与OpenCV一起使用,该模型从
3.5开始就学会了使用神经网络模型 ,甚至找到了一个
简单的示例 。 在尝试使用ADB的几个库之后,我选择了
pure-python-adb-我所需的一切都在这里简单地实现:屏幕捕获功能和在shell设备上的操作; 我使用“输入水龙头”进行水龙头。
因此,在收到游戏的屏幕截图,识别游戏中的单元并在屏幕上戳戳之后,我继续致力于识别游戏状态。 除单位外,我还需要识别当前的法术力等级和可供玩家使用的牌。
游戏中的法术力等级显示为进度条和数字。 我三思而后行,开始使用
pytesseract削减数字,
求逆并识别。
为了确定可用的卡及其位置,我使用了
OpenCV的
关键点检测器KAZE 。 到目前为止,我不想再次学习神经网络,我选择了一种更快,更轻松的方法,尽管最终,在需要搜索许多对象的情况下,它的准确性最低。
启动机器人时,我计算了所有卡片图片的关键点(总共有几十个),并且在游戏过程中,我查找了所有卡片与玩家卡片区域的匹配情况,以减少错误数量并提高速度。 它们按照准确性和
x坐标进行排序,以获得地图的顺序-有关它们在屏幕上的位置的信息。
尽管使用了一些参数,但实际上我遇到了很多错误,尽管某些复杂的卡片图片有时被算法误认为是其他图片,但它们的识别准确度很高。 我必须添加三个元素的缓冲区:如果连续三个识别我们得到相同的值,那么我们有条件地相信我们可以信任它们。

收到所有必要的信息(单位及其大致位置,可用法术力和牌)后,您可以做出一些决定。
首先,我决定做一些简单的事情:例如,如果可访问的牌上有足够的法术力,则在场上使用。 但是该机器人仍然不知道如何“玩”牌-它知道我们拥有哪些牌,该字段在哪里,您需要单击所需的卡,然后单击该字段中的所需单元。
了解了屏幕截图的分辨率,您可以了解地图的坐标和所需的现场单元格。 现在,我已经绑定了确切的屏幕分辨率,但是如果需要,我可以忽略这一点。 决策函数将返回一系列需要在不久的将来完成的抽头。 通常,我们的机器人将是一个无限循环(简化):
: = : ( ) : = () = () = () += (, , , )
到目前为止,该机器人只能将单位放到一个点,但是已经有足够的信息来构建更复杂的策略。
第一个问题
实际上,我遇到了一个意想不到且非常不愉快的问题。 通过ADB创建屏幕截图大约需要100毫秒,这会带来很大的延迟-我指望有这样的最大延迟,要考虑所有的计算和操作的选择,而不是一步一步地创建屏幕截图。 找不到简单快捷的解决方案。 从理论上讲,使用Android模拟器,您可以直接从应用程序窗口中截取屏幕截图,也可以创建实用程序来通过UDP通过压缩从手机流式传输图像并将机器人连接到该机器人,但是我在这里也没有找到快速的解决方案。
所以
在清醒地评估了我的项目状态之后,我决定暂时使用此模型。 我花了几个星期的空闲时间来做这个,单位识别只是游戏的一部分。
我决定逐步开发机器人的各个部分-先建立感知的基本逻辑,然后再进行游戏的简单逻辑以及与游戏的交互,然后才有可能改善机器人的各个辅助部分。 当单位识别模型的级别变得足够高时,添加有关HP和单位级别的信息可以使游戏机器人的开发进入一个全新的阶段。 也许这将是下一个目标,但现在专注于此任务绝对不值得。
Github项目存储库我花了很多时间在项目上,坦率地说,我对此感到厌倦,但是我一点也不后悔-我在ML / CV中有了新的经验。
也许我以后再回去-如果有人加入我,我会很高兴。 如果您有兴趣,请加入
Telegram小组,还可以参加我的
Scala课程 。