本文是Uchi.ru的Alexei Vakhov的视频报告的抄本“ Clouds in the cloud”
Uchi.ru是一个用于学校教育的在线平台,超过200万学生,互动课程定期与我们联系。 我们所有的项目都完全托管在公共云中,100%的应用程序都在容器中工作,从最小的容器开始供内部使用,最后以每秒1k +请求的大批量生产结束。 碰巧,我们在五个云提供商中有15个隔离的Docker集群(不是Kubernetes,太棒了!)。 一千五百个用户应用程序,其数量正在不断增长。
我将谈论非常具体的事情:我们如何切换到容器,如何管理基础架构,遇到的问题,有效的方法和无效的方法。
在报告期间,我们将讨论:
- 技术选择和业务功能的动机
- 工具:Ansible,Terraform,Docker,Github Flow,领事,Nomad,Prometheus,Shaman – Nomad的Web界面。
- 使用集群联合来管理分布式基础结构
- NoOps推出,测试环境,应用电路(开发人员实际上是自己进行更改)
- 寓教于乐的故事
谁在乎,请在猫下。
我叫Alexey Vakhov。 我在Uchi.ru担任技术总监。 我们在公共云中托管。 我们积极使用Terraform,Ansible。 从那时起,我们已经完全切换到Docker。 非常满意。 我会告诉你,我们有多幸福,我们有多幸福。

Uchi.ru公司从事学校教育产品的生产。 我们有一个主要平台,儿童可以通过该平台解决俄罗斯,巴西和美国各个学科的互动问题。 我们进行在线奥林匹克竞赛,比赛,俱乐部,训练营。 这项活动每年都在增长。

从工程角度看,经典的Web堆栈(Ruby,Python,NodeJS,Nginx,Redis,ELK和PostgreSQL)。 主要功能是许多应用程序。 应用程序在全球范围内托管。 每天都有产品推出。
第二个特点是我们的方案经常更改。 他们要求提出一个新的应用程序,停止旧的应用程序,为后台作业添加cron。 每2周会有一次新的奥运会-这是一项新的应用程序。 陪同,监视,备份都是必需的。 因此,环境是超动力的。 动力是我们的主要困难。
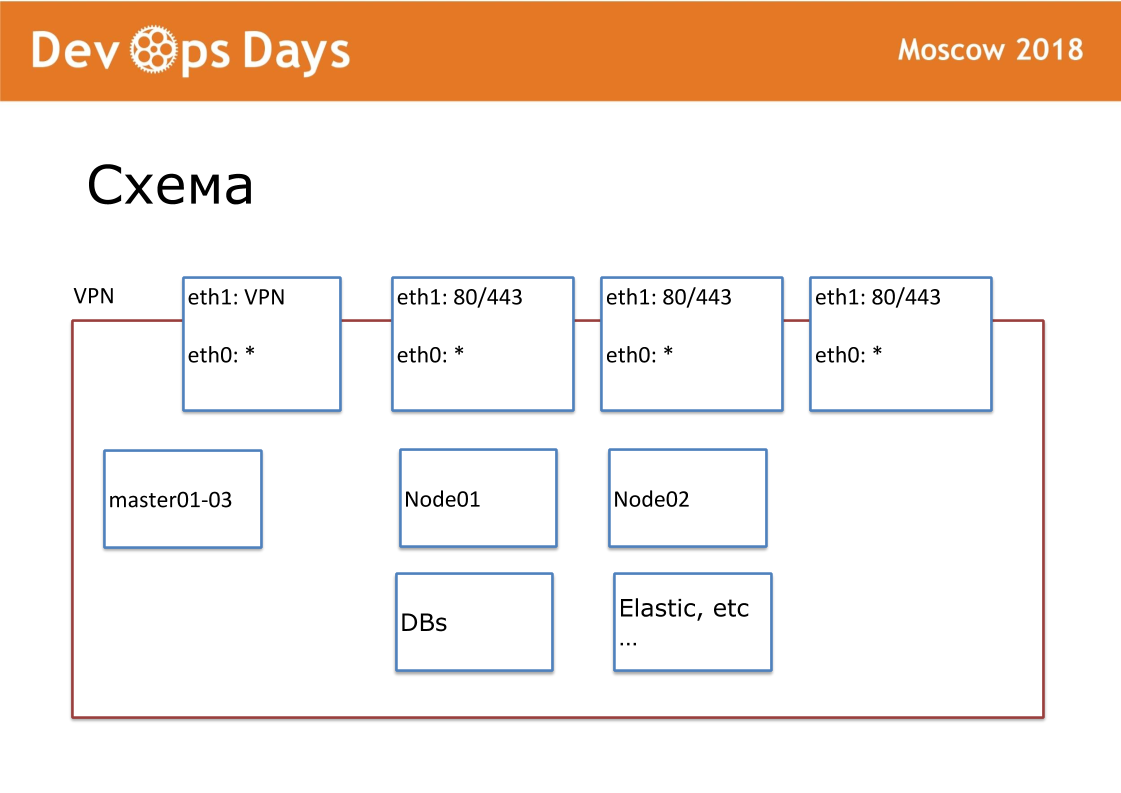
我们的工作单位是现场。 就云提供商而言,这是Project。 我们的网站是一个完全隔离的实体,具有API和专用子网。 进入该国后,我们会寻找当地的云提供商。 并非到处都有Google和Amazon。 有时会发生云提供商没有API的情况。 在外部,我们将VPN和HTTP,HTTPS发布到平衡器。 所有其他服务都在云内部进行通信。

对于每个站点,我们都创建了自己的Ansible存储库。 该存储库包含hosts.yml,剧本,角色和3个秘密文件夹,我将在后面讨论。 这是地形,供应,路由。 我们是标准化的拥护者。 我们的存储库应始终称为“站点的可输入名称”。 我们标准化每个文件名,内部结构。 这对于进一步的自动化非常重要。

我们在一年半之前设置了Terraform,所以我们使用它。 没有模块,没有文件结构(使用平面结构)的Terraform。 Terraform文件结构:1个服务器-1个文件,网络设置和其他设置。 我们使用terraform来描述服务器,驱动器,域,s3-bucket,网络等。 现场的Terraform正在充分准备熨斗。

Terraform创建服务器,然后合奏滚动这些服务器。 由于我们到处都使用相同版本的操作系统,因此我们从头开始编写了所有角色。 Ansible角色通常在Internet上发布,用于无法在任何地方运行的所有操作系统。 我们所有人都扮演了Ansible角色,只留下了我们需要的东西。 标准化的角色。 我们有6种基本的剧本。 启动时,Ansible将安装标准软件列表:OpenVPN,PostgreSQL,Nginx,Docker。 我们不使用Kubernetes。

我们使用领事+游牧。 这些是非常简单的程序。 在每个服务器上运行2个用Golang编写的程序。 领事负责服务发现,运行状况检查和用于存储配置的键值。 Nomad负责计划和部署。 Nomad启动容器,提供部署,包括运行状况检查的滚动更新,使您可以运行边车集装箱。 群集易于扩展,反之亦然。 Nomad支持分布式cron。
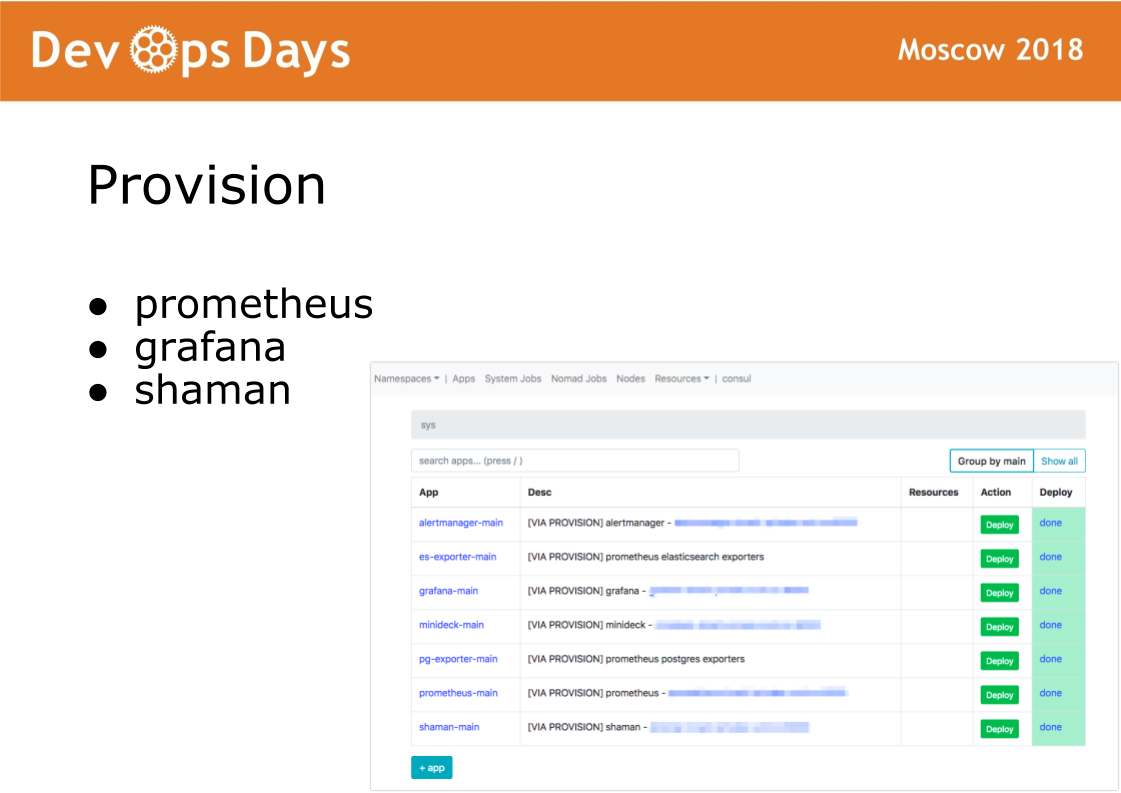
进入站点后,Ansible执行位于供应目录中的剧本。 该目录中的剧本负责在管理员使用的Docker集群中安装软件。 安装prometheus,grafana和秘密萨满软件。
萨满是游牧民族的网络仪表盘。 Nomad是底层的,我真的不想让开发人员加入其中。 在萨满中,我们看到了一个应用程序列表,我们为开发人员提供了一个应用程序部署按钮。 开发人员可以更改配置:添加容器,环境变量,启动服务。
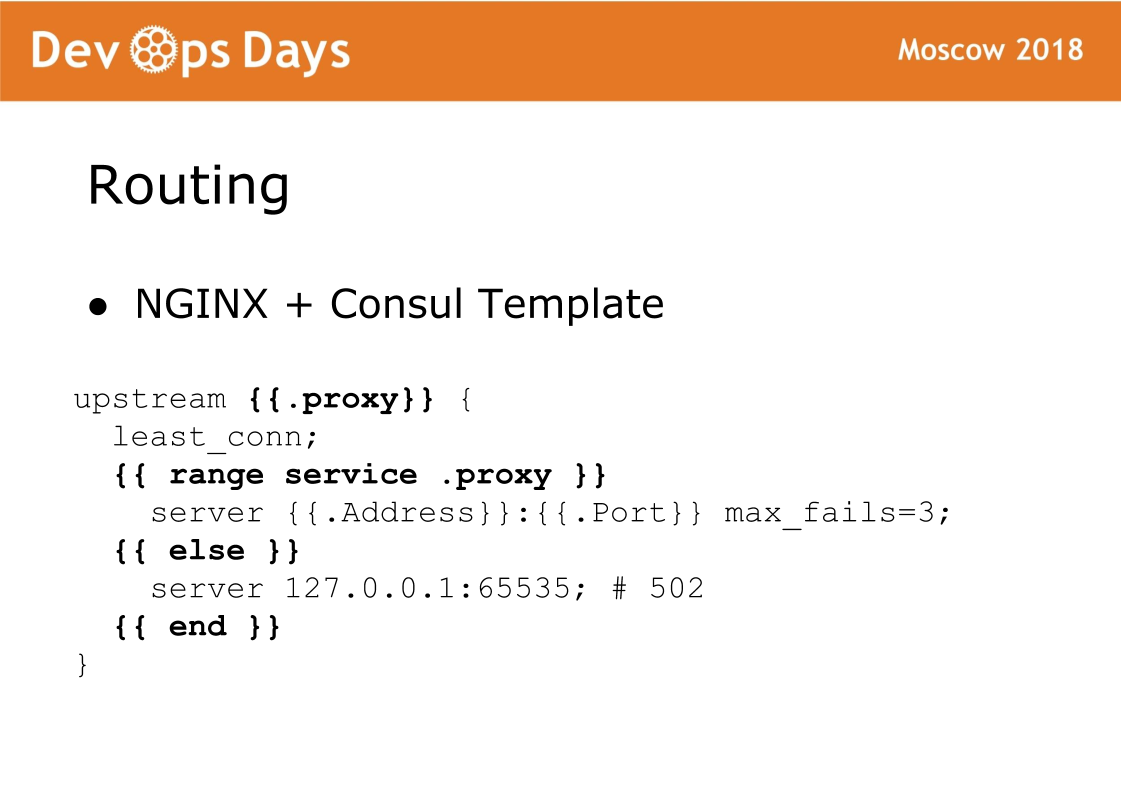
最后,站点的最后组成部分是路由。 路由存储在领事的K / V存储中,即上游,服务,URL等之间存在链接。 在每个平衡器上,都有一个Consul模板,该模板可生成nginx配置并使其重新加载。 非常可靠的事情,我们从来没有遇到过问题。 该方案的特征是流量接受标准的nginx,并且您始终可以看到生成了哪个配置,并且可以像使用标准nginx一样工作。

因此,每个站点由5层组成。 使用terraform,我们可以自定义硬件。 可以,我们执行服务器的基本配置,放置docker-cluster。 供应汇总系统软件。 路由将流量引导到站点内。 应用程序包含用户应用程序和管理员应用程序。
我们调试了这些层很长时间,以使它们尽可能相同。 供应,站点之间路由匹配100%。 因此,对于开发人员而言,每个站点都是绝对相同的。
如果IT专业人员从一个项目切换到另一个项目,他们将陷入完全典型的环境中。 简而言之,我们无法为不同的云提供商提供相同的防火墙和VPN设置。 通过网络,所有云提供商的工作方式都不同。 Terraform无处不在,因为它包含每个云提供商的特定设计。
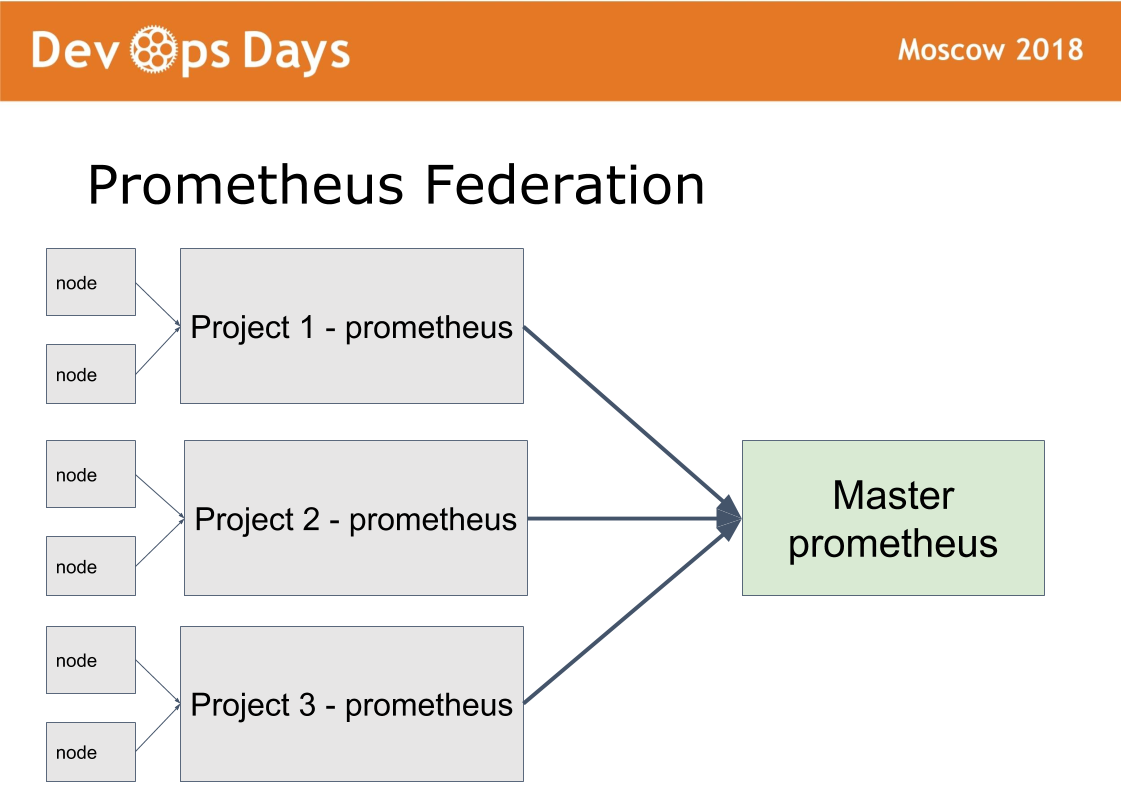
我们有14个生产基地。 问题出现了:如何管理它们? 我们制作了第15个主站点,只允许管理员在其中访问。 她从事联邦计划。
这个想法来自普罗米修斯。 当我们在每个站点中安装prometheus时,prometheus中就有一种模式。 我们通过HTTPS基本身份验证授权发布Prometheus。 Prometheus主站仅从远程Prometheus中获取必要的指标。 这样就可以比较不同云中的应用程序指标,找到下载或卸载次数最多的应用程序。 集中式通知(警报)通过Prometheus主管理员。 开发人员会收到来自本地Prometheus的警报。

萨满巫师的配置方式相同。 通过主站点,管理员可以通过单个界面在任何站点上进行部署,配置。 我们无需离开此主站点即可解决足够多的问题。

我将告诉您我们如何切换到docker。 这个过程很慢。 我们渡过了大约10个月。 在2017年夏季,我们有0个生产容器。 在2018年4月,我们进行了docker化并将最新应用程序推向生产环境。

我们来自红宝石世界。 过去有99%的Ruby on Rails应用程序。 Rails通过Capistrano推出。 从技术上讲,Capistrano的工作方式如下:开发人员启动cap部署,capistrano通过ssh转到所有应用程序服务器,获取最新版本的代码,收集资产,进行数据库迁移。 Capistrano对新版本的代码建立符号链接,并将USR2信号发送到Web应用程序。 在此信号下,Web服务器将获取新代码。
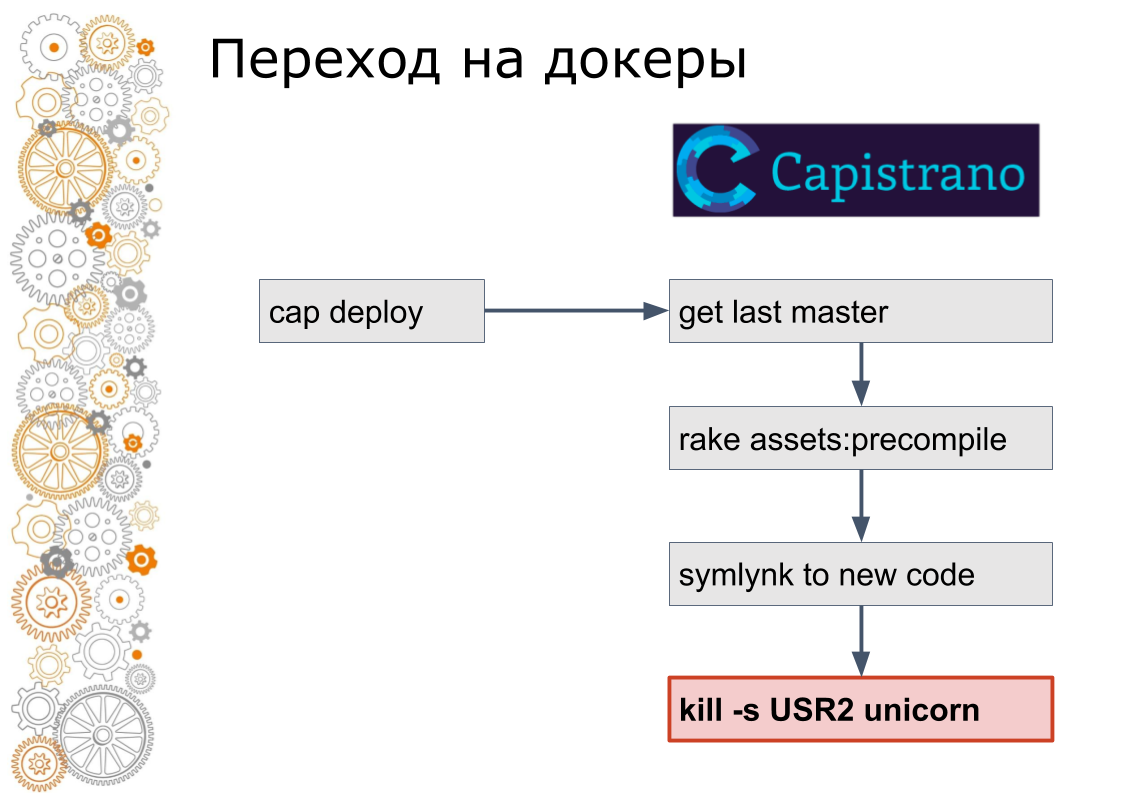
泊坞窗的最后一步不是那样完成的。 在docker中,您需要停止旧容器,然后升高新容器。 这就提出了一个问题:如何切换流量? 在云世界中,服务发现对此负责。

因此,我们向每个站点添加了领事。 加入领事,因为他们使用了Terraform。 我们将所有Nginx配置包装在领事模板中。 正式地,这是同一件事,但是我们已经准备好动态管理站点内的流量。

接下来,我们编写了一个ruby脚本,该脚本在其中一台服务器上收集图像,将其推送到注册表中,然后通过ssh转到每台服务器,拾取新服务器并停止旧容器,然后将它们注册到领事中。 开发人员还继续运行cap deploy,但是服务已经在docker中运行。
我记得该脚本有两个版本,第二个版本相当先进,有一个滚动更新,当少量容器停止运行,新的容器出现后,领事Helfcheki等待并继续前进。

然后他们意识到这是一种死胡同的方法。 脚本增加到600行。 下一步,我们取代了Nomad。 隐藏开发人员的工作细节。 就是说,他们仍然称做帽子部署,但是内部已经是一种完全不同的技术。
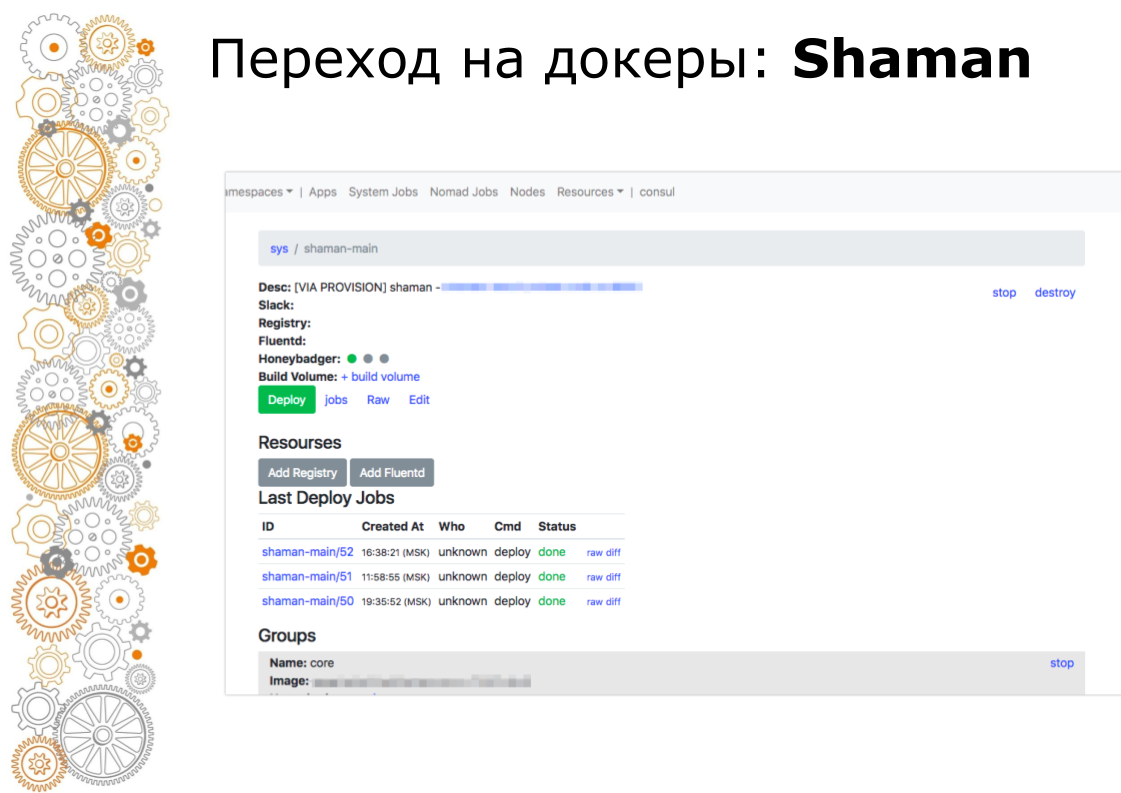
最后,我们将部署移至UI并取消了对服务器的访问,只剩下绿色的部署按钮和控制界面。
原则上,这样的过渡当然会很长,但是我们避免了我遇到过很多次的问题。
有某种传统的堆栈,系统或类似的东西。 Khachennaya已经在拍打。 开始开发新版本。 在几个月或几年之后,根据公司的规模,在新版本中,只有不到一半的必要功能得以实现,而旧版本仍然无法使用。 那个新的东西也变得非常古老。 现在该从头开始创建新的第三版本了。 通常,这是一个无休止的过程。
因此,我们总是将整个堆栈作为一个整体移动。 拐杖拐弯处,小步弯曲,但完全弯曲。 例如,我们无法在一个站点上升级docker引擎。 如果有需要,有必要在所有地方进行更新。

推出。 所有docker指令将10个nginx容器或10个redis容器推出到docker中。 这是一个不好的例子,因为图像已经组合好了,所以图像很亮。 我们将Rails应用程序打包在docker中。 泊坞窗映像的大小为2-3 GB。 它们弹出的速度不会很快。
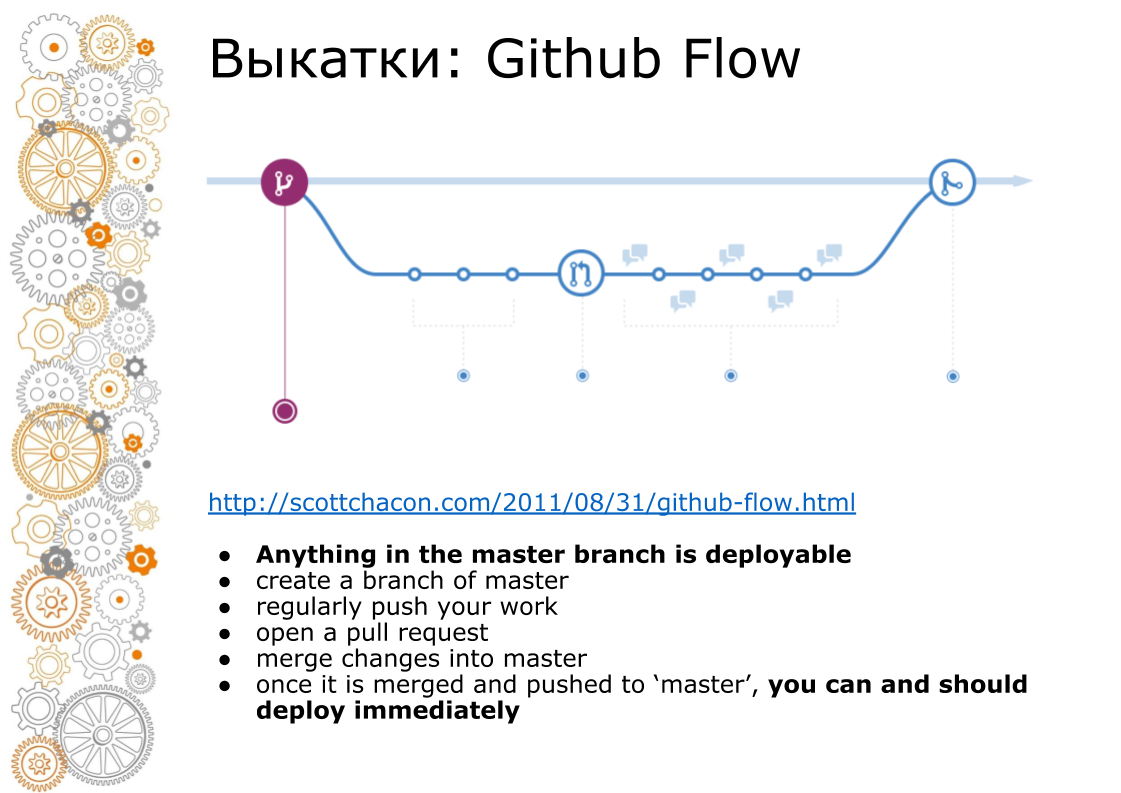
第二个问题来自时髦网站。 时髦网站始终是Github Flow。 2011年,Github Flow指导了一个划时代的职位,因此整个网络都在滚动。 看起来像什么? 主分支始终是生产部门。 添加新功能时,我们进行分支。 合并时,我们进行代码审查,运行测试,提高暂存环境。 看起来分阶段的环境的事务。 在时间X,如果一切成功,则我们将分支合并到master中,并开始生产。
在capistrano上,这很好用,因为它是为此创建的。 Docker总是向我们出售管道。 组装容器。 容器可以转移到显影剂,测试仪上,也可以转移到生产中。 但是在母版中合并时,代码已经不同。 从Feature分支收集的所有docker映像,但不是从master收集的。

我们是如何做到的? 我们收集图像,并将其放入本地docker注册表中。 之后,我们执行其余的操作:迁移,部署到生产。

为了快速组装此映像,我们使用Docker-in-Docker。 在Internet上,每个人都写道这是一个反模式,它崩溃了。 我们什么都没有。 已经有多少人和他一起工作从来没有问题。 我们使用Persistent卷将/ var / lib / docker目录转发到主服务器。 所有中间映像都在主服务器上。 几分钟后即可组装新图像。

对于每个应用程序,我们创建一个本地内部docker注册中心和构建卷。 因为docker将所有层保存在磁盘上,并且很难清理。 现在我们知道了每个本地docker注册表的磁盘利用率。 我们知道它需要多少磁盘。 您可以通过集中式Grafana接收警报并进行清理。 当我们清洁他们的手时。 但是,我们将使其自动化。

还有一点。 收集了Docker映像 现在,需要将此映像分解为服务器。 复制大型Docker映像时,网络无法应对。 在云中,我们有1 Gbit / s。 云中存在全局关闭。 现在,我们正在将docker映像部署到4个重型生产服务器。 在该图上,您可以看到该磁盘可用于1台服务器。 然后部署第二台服务器。 您可以在下面看到渠道的利用情况。 大约1 Gbit / s,我们快要拉了。 那里没有太多的加速度了。

我最喜欢的作品是南非。 有非常昂贵和缓慢的铁。 比俄罗斯贵四倍。 互联网非常糟糕。 调制解调器级别的互联网,但不是越野车。 考虑到缓存的调整,超时参数,我们将在40分钟内推出应用程序。

码头工人联系之前让我担心的最后一个问题是负载。 实际上,负载与没有具有相同熨斗的泊坞窗的负载相同。 我们碰到的唯一细微差别只有一点。 如果您通过内置fluentd驱动程序从Docker引擎收集日志,则负载约为1000 rps时,内部fluentd缓冲区开始变得乱七八糟,请求开始变慢。 我们取出日志记录在杂物箱中。 在游牧民族中,这称为日志运送人。 一个小容器挂在一个大应用程序容器旁边。 唯一的任务是将其拾取并将其发送到集中式存储库。

有什么问题/解决方案/挑战。 我试图分析任务是什么。 我们的问题的特征是:
- 许多独立的应用程序
- 基础设施的不断变化
- Github流和大型Docker映像

我们的解决方案
- Docker集群的联合。 从处理的角度来看,这很困难。 但是Docker擅长在生产中推出业务功能。 我们使用个人数据,并且在每个国家/地区都有认证。 在隔离的站点中,这种认证很容易通过。 在认证过程中,会出现所有问题:您在何处托管,如何拥有云提供商,在何处存储个人数据,在何处备份以及有权访问这些数据。 当一切都孤立时,描述犯罪嫌疑人的圈子要容易得多,监视所有这些事情也要容易得多。
- 编排。 显然,kubernetes。 他无处不在。 但是我想说的是Consul + Nomad是一个完全的生产解决方案。
- 图像组装。 您可以在Docker-in-Docker中快速构建映像。
- 使用Docker时,也可以保持1000 rps的负载。
发展方向向量
现在最大的问题之一是站点上软件版本的不同步。 以前,我们是手动设置服务器的。 然后我们成为了devops工程师。 现在使用ansible配置服务器。 现在我们已经完全统一,标准化。 我们将普通思维引入脑海。 我们无法在服务器上动手修复PostgreSQL。 如果您只需要在1台服务器上进行某种微调,那么我们考虑如何将此设置扩展到任何地方。 如果您不进行标准化,那么将有很多设置。
我很高兴也很高兴我们免费提供了一个非常非常好用的基础架构。

您可以在Facebook上添加我。 如果我们做得很好,我会写它。
问题:
Consul模板比Ansible模板有什么优势,例如,配置防火墙规则等?
答:现在,我们有来自外部平衡器的流量直接流向容器。 两者之间没有人。 在那里形成一个配置,该配置转发群集的IP地址和端口。 此外,我们在领事中以K / V设置所有余额。 我们有一个想法,可以通过安全的界面为开发人员提供路由设置,以使他们不会破坏任何内容。
问题:关于所有位点的同质性。 确实没有来自企业或开发人员的要求,您不需要在此站点上推出一些非标准的东西吗? 例如,tarantool和cassandra。
答:确实发生,但是非常罕见。 这是我们绘制的内部独立工件。 有这样的问题,但是很少。
问题:交付问题的解决方案是在每个站点中使用私有Docker注册表,从那里开始获取Docker映像已经非常快。
答:无论如何,部署将运行到网络中,因为我们将docker镜像同时部署到了15台服务器中。 我们反对网络。 在网络内部,为1 Gbit / s。
问题:那么多Docker容器都基于大致相同的技术堆栈?
答:Ruby,Python,NodeJS。
问题:您多久测试或检查一次Docker映像是否有更新? 您如何解决更新问题,例如在glibc,openssl需要在所有docker中修复的情况下?
答:如果您发现这样的错误和脆弱性,那么我们将坐下来一周并进行修复。 如果您需要部署,那么我们可以从头开始通过联盟部署整个云(所有应用程序)。 我们可以单击所有绿色按钮来部署应用程序,然后喝点茶。
问题:您打算在开源中发布萨满吗?
答:在这里,安德烈(观众中指向人的方向)保证我们会在秋天放置萨满。 但是,您需要在其中添加对kubernetes的支持。 开源应该总是更好。