
很少有人相信现代数据科学堆栈不能建立在Python之上,但是有这样的先例:)。 Odnoklassniki堆栈由多年的程序员组成,他们转向数据科学,但仍然紧跟产品,因此它基于JVM堆栈的开放技术:Hadoop,Spark,Kafka,Cassandra等。 这可以帮助我们减少投入模型的时间和成本,但有时会带来困难。 例如,在为SNA Hackathon 2019参与者准备基本解决方案时,他们不得不压缩自己的意志力并投身于动态打字领域。 详细信息(并且易于拖曳):)
安装方式

几乎所有开发机器上都有某种python。 他在我的身上被发现,已经是重复的2.7和3.4。 在记忆库中翻阅后,我记得三年前我安装了3.4版,当时参与者在SNA Hackathon 2016上遇到了史诗性的问题,当时试图扩大半GB的内存图(由于一个小型培训视频和一个单独的比赛 ),但是今天经济在道德上已经过时,需要更新。
在Java世界中,每个项目在组装过程中都会表明它要整合到自己中的所有内容,并在此基础上继续发展。 从理论上讲,一切都是简单而优美的,但是实际上,当您需要库A和库B时,肯定会发现它们都需要C库,并且具有两个不兼容的版本:)。 为了打破这种恶性循环而徒劳的尝试,一些库将所有依赖关系打包在了自己的手中,对其余部分隐藏,而其余部分则尽可能地旋转。
python这是怎么回事? 没有这样的项目,但是有一个“环境”,并且在每个环境中,可以由某些版本的软件包形成一个独立的生态系统。 同时,有一些用于惰性的工具 ,借助这些工具 ,与分散的Clauder或Horton异构集群相比,管理本地Python环境并不困难。 但是软件包版本之间的相互冲突不会消失,我立即面对这样一个事实,即Pandas 0.24版本将私有的_maybe_box_datetimelike方法转移到了公共API,突然发现很多人以以前的形式使用了它,现在掉下来了:)(是的,在Java世界是相同的 )。 但最终,除了可怕的关于新的depriycheyshin的警告之外,所有东西都得到了修复,并且一切正常。
协作基准

SNA Hackathon 2019的任务分为三个区域-关于日志,文本和图片的建议。 让我们从日志开始(扰流器-具有stackoverflow的巨型模式Cmd + C / Cmd + V也适用于python)。 数据是从现场制作中收集的-每个用户在不称重的情况下随机获得了来自其周围环境的一些饲料,此后在展示时和最终反应中记录了所有迹象。 小菜一碟:我们做个标志,我们推个logg ,赢利!
但是该计划在读取数据的第一阶段就出现了。 从理论上讲,有一个很棒的Apache Arrow程序包,该程序包旨在统一处理不同生态系统中的数据,尤其是允许从Python读取“ parquet”文件而不会产生火花。 实际上,事实证明。 即使阅读简单的嵌套结构,他仍然有问题 ,而我们美丽的层次结构已变成扁平的squalor :(。
但是也有积极的方面。 总的来说 , Jupyter很高兴,它几乎舒适,尽管不像齐柏林飞艇那么漂亮。 甚至还有一个岩心 ! 好吧,对内存中一小部分数据进行逻辑回归的速度令人愉悦-它无法达到分布式选项的功能,但可以立即从四个符号和数十万个示例中学习。
但是,随之而来的热情受到了沉重打击:如果必要的数据转换(按键分组并组装成列表)不在标准列表中,而是出现应用或映射,则速度下降了几个数量级。 结果,基线的80%的时间不是读取数据,联接,模型训练和排序,而是列表的平庸汇编。
顺便说一句,正是由于这个功能,我一直对pySpark用户感到惊讶-毕竟,几乎所有标准功能都可以通过Spark SQL形式获得,Spark SQL在python和rock中是相同的,并且在第一个类似python的yudf-in之后带有个人十核功能簇变成南瓜...
但是最后,所有的障碍都被克服了, 九分就足以获得0.65分!
文字基线

好吧,现在我们的任务更加复杂-如果可以在所有平台的数百种实现中找到logreg,那么将有更多种工具可以在python下处理文本。 幸运的是,这些文本不仅已经以原始形式发送,而且已经由我们基于Spark和Lucene的常规预处理系统进行处理。 因此,您可以立即获取标记列表,而不必担心标记化/语法化/词干化。
一段时间以来,我怀疑该采取什么措施:国产BigARTM或进口Gensim 。 结果,我选择了第二个,并复制了doc2vec教程 :)。 我希望BigARTM团队的同事能够抓住机会,在比赛中展示他们图书馆的优势。
我们再次有一个简单的计划:我们从测试中获取所有文本,训练Doc2Vec模型,然后在训练中进行推断,并学习logreg的结果(堆叠就是我们的一切!)。 但是,像往常一样,问题立即开始。 尽管训练样本中的文本量相对较少(只有一个半GB),但是当试图将它们拖到坡道上时,Python却吃了20(20 Karl!)GB的内存,进行了交换并且没有返回。 我不得不部分吃掉一头大象。
阅读时,我们总是指示要从地板上抬起哪些列,这使我们不读取内存中的原始文本。 这样可以节省一半的使用时间,并且将测试集的文档加载到内存中进行培训而不会出现问题。 用这样的技巧训练集是不够的,因此一次我们上传的文件不超过一个。 接下来,在下载的文件中,我们仅保留要用于培训的日期的ID,并且我们已经推断出它们。
以最快的速度登录,最后得到14个段落 ,得分为0.54 :)
图片基线
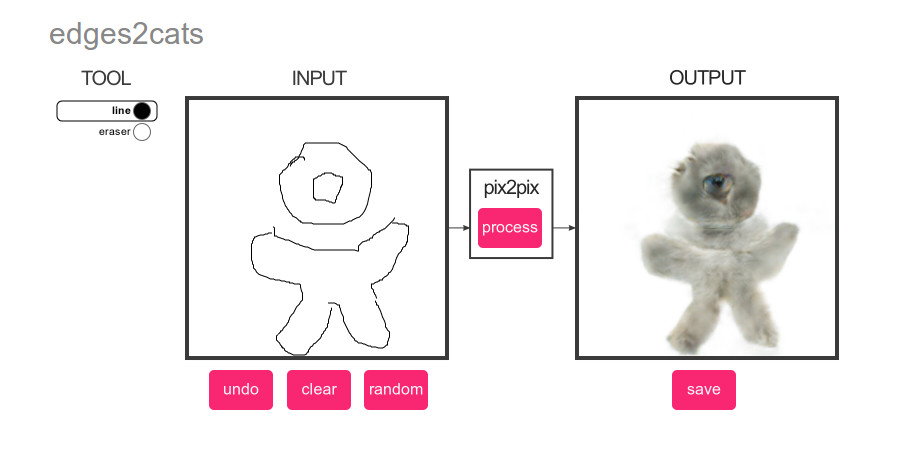
还有什么比深度学习更受欢迎? 只有猫! 因此,对于基线图片,我们制定了一个非常简单的计划:对测试集中的图片运行猫检测器,然后根据得分对内容进行排名:)
再次有很多选择。 分类还是检测? pyTorch或Tensorflow? 主要标准是通过复制粘贴方法实现的简便性。 赢家是MXNet上的YOLOv3 :)。 演示的简洁性一见钟情,但随后,像往常一样,问题开始了。
大数据通常从什么开始呢? 具有性能估计和必要的机器时间! 我想使基线尽可能自治,因此他们教它可以直接与tar文件一起使用,并很快意识到以每秒从tar到tmpfs提取200张照片的速度,大约需要半小时才能处理352,758张图像。 添加照片的加载和预处理-每秒100张,所有内容和规范大约需要一个小时。 添加神经网络的计算-每秒20张照片,5个小时,好吧……好吧,添加结果提取-每秒1张照片,每周,WTF?
经过几个小时的铃鼓跳舞后,人们了解到,我们观察到的NDArray绝不会麻木,而MXNet的内部结构则懒惰地进行所有计算。 宾果! 怎么办 任何新手汲取知识的人都知道,这一切都与批次的大小有关! 如果MXNet懒惰地计算分数,那么如果我们首先要求他们提供几十张照片,然后我们开始提取它们,那么可能会批量处理照片? 是的,在以每秒10张照片的速度添加批处理之后,我设法找到了所有的猫:)。
然后我们应用著名的工程,在10段中我们得到0.504的分数:)。
结论

当一个明智的老师被问到:“谁会赢,合气道大师还是空手道?”,他回答“大师会赢。” 通过这个实验,我们得出了几乎相同的结论:没有而且不可能在所有情况下都是理想的语言。 使用Python,您可以从现成的块中快速组装一个解决方案,但是如果尝试使用足够多的数据来远离它们,则会带来很多麻烦。 在Java和Scala中,您还可以找到许多现成的工具并轻松实现自己的想法,但是语言本身对代码质量的要求更高。
当然,祝所有SNA Hackathon 2019会员好运!