
在任何时候,紧迫的问题之一就是准备报告的问题。 由于Julia是一门语言,其用户直接与数据分析任务联系在一起,使用计算和报告的结果编写文章和精美的演示文稿,因此无法忽略此主题。
最初,本文计划了一组用于生成报告的方法,但是在报告旁边是文档主题,与报告生成器有很多交集。 因此,这包括用于判断是否可以将Julia可执行代码嵌入带有某些标记的模板中的标准的工具。 最后,我们注意到该评论包括均由Julia本身实现的报告生成器,以及用其他编程语言编写的工具。 好吧,当然,朱莉娅语言本身的一些关键点并没有被忽略,没有它们,在什么情况下以及应该使用什么手段可能不清楚。
Jupyter笔记本
也许应该将此工具归因于参与数据分析的人员中最受欢迎的工具。 由于具有连接各种计算核心的能力,它受到习惯于特定编程语言的研究人员和数学家的欢迎,Julia是其中之一。 Julia语言的相应模块已为Jupyter Notebook完全实现。 这就是为什么在这里提到笔记本。
Jupyter Notebook的安装过程并不复杂。 有关顺序,请参见https://github.com/JuliaLang/IJulia.jl。如果已经安装了Jupyter Notebook,则只需安装Ijulia软件包并注册相应的计算核心。
由于Jupyter笔记本产品众所周知,因此没有详细介绍,因此我们仅提及几点。 Jupyter Notebook中的记事本(我们将使用记事本术语)由块组成,每个块可以包含各种形式的代码或标记(例如Markdown)。 处理的结果是标记的可视化(文本,公式等),或者是最后操作的结果。 如果将分号放在代码行的末尾,则不会显示结果。
例子 下图显示了执行之前的笔记本:

下图显示了其实现的结果。
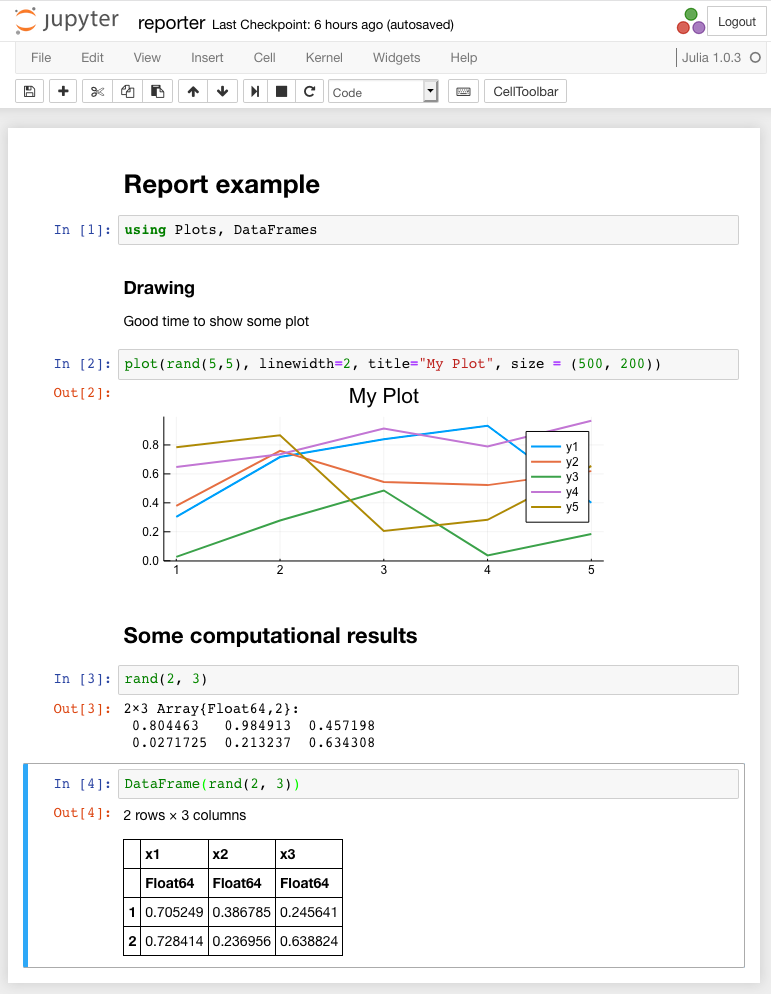
记事本包含图形和一些文本。 请注意,要输出矩阵,可以使用DataFrame类型,对于该结果,结果将以带有明显边框和滚动条的html表的形式显示(如有必要)。
Jupyter笔记本可以将当前笔记本导出为html文件。 如果安装了转换工具,则可以转换为pdf。
要根据某些法规构建报告,可以使用nbconvert模块和以下命令,该命令根据计划在后台调用:
jupyter nbconvert --to html --execute julia_filename.ipynb
执行冗长的计算时,建议添加一个指示超时的选项--- --ExecutePreprocessor.timeout=180
从该文件生成的html报告将出现在当前目录中。 --execute选项在这里意味着强制重新开始计数。
有关一整套nbconvert模块nbconvert请参见
https://nbconvert.readthedocs.io/en/latest/usage.html
转换为html的结果几乎与上图完全一致,不同之处在于它没有菜单栏或按钮。
文字
一个相当有趣的实用程序,可让您将以前创建的ipynb注释转换为Markdown文本或Julia代码。
我们可以使用以下命令转换先前考虑的示例
jupytext --to julia julia_filename.ipynb
结果,我们获得了julia_filename.jl文件,带有Julia代码和注释形式的特殊标记。
# --- # jupyter: # jupytext: # text_representation: # extension: .jl # format_name: light # format_version: '1.3' # jupytext_version: 0.8.6 # kernelspec: # display_name: Julia 1.0.3 # language: julia # name: julia-1.0 # --- # # Report example using Plots, DataFrames # ### Drawing # Good time to show some plot plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
注意块分隔符只是双换行。
我们可以使用以下命令进行逆变换:
jupytext --to notebook julia_filename.jl
结果,将生成一个ipynb文件,然后可以对其进行处理并将其转换为pdf或html。
查看详细信息https://github.com/mwouts/jupytext
jupytext和jupyter笔记本的一般缺点是报告的“美观”受到这些工具功能的限制。
自行生成的HTML
如果出于某种原因我们认为Jupyter Notebook太重了,需要安装大量的第三方软件包,这些软件包对于Julia的工作不是必需的,或者不够灵活来构建我们需要的报告表单,那么另一种方法是手动生成html页面。 但是,在这里您将不得不深入研究成像功能。
对于Julia,将某些内容输出到输出流的典型方法是使用Base.write函数,并Base.show(io, mime, x)进行装饰。 此外,对于请求的各种哑剧输出方法,可能会有各种显示选项。 例如, DataFrame在显示为文本时由伪图形表显示。
julia> show(stdout, MIME"text/plain"(), DataFrame(rand(3, 2))) 3×2 DataFrame │ Row │ x1 │ x2 │ │ │ Float64 │ Float64 │ ├─────┼──────────┼───────────┤ │ 1 │ 0.321698 │ 0.939474 │ │ 2 │ 0.933878 │ 0.0745969 │ │ 3 │ 0.497315 │ 0.0167594 │
如果mime指定为text/html ,则结果为HTML标记。
julia> show(stdout, MIME"text/html"(), DataFrame(rand(3, 2))) <table class="data-frame"> <thead> <tr><th></th><th>x1</th><th>x2</th></tr> <tr><th></th><th>Float64</th><th>Float64</th></tr> </thead> <tbody><p>3 rows × 2 columns</p> <tr><th>1</th><td>0.640151</td><td>0.219299</td></tr> <tr><th>2</th><td>0.463402</td><td>0.764952</td></tr> <tr><th>3</th><td>0.806543</td><td>0.300902</td></tr> </tbody> </table>
也就是说,使用为相应的数据类型(第三个参数)和相应的输出格式定义的show函数的方法,可以确保以任何所需的数据格式形成文件。
图像的情况更加复杂。 如果需要创建一个单独的html文件,则图像应嵌入到页面代码中。
考虑实现它的示例。 该文件的输出将由Base.write函数执行,为此我们定义了适当的方法。 所以代码:
#!/usr/bin/env julia using Plots using Base64 using DataFrames # p = plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # , , @show typeof(p) # => typeof(p) = Plots.Plot{Plots.GRBackend} # , 3 # abstract type Png end abstract type Svg end abstract type Svg2 end # Base.write # # — , # Base64-. # HTML img src="data:image/png;base64,..." function Base.write(file::IO, ::Type{Png}, p::Plots.Plot) local io = IOBuffer() local iob64_encode = Base64EncodePipe(io); show(iob64_encode, MIME"image/png"(), p) close(iob64_encode); write(file, string("<img src=\"data:image/png;base64, ", String(take!(io)), "\" alt=\"fig.png\"/>\n")) end # Svg function Base.write(file::IO, ::Type{Svg}, p::Plots.Plot) local io = IOBuffer() show(io, MIME"image/svg+xml"(), p) write(file, replace(String(take!(io)), r"<\?xml.*\?>" => "" )) end # XML- , SVG Base.write(file::IO, ::Type{Svg2}, p::Plots.Plot) = show(file, MIME"image/svg+xml"(), p) # DataFrame Base.write(file::IO, df::DataFrame) = show(file, MIME"text/html"(), df) # out.html HTML open("out.html", "w") do file write(file, """ <!DOCTYPE html> <html> <head><title>Test report</title></head> <body> <h1>Test html</h1> """) write(file, Png, p) write(file, "<br/>") write(file, Svg, p) write(file, "<br/>") write(file, Svg2, p) write(file, DataFrame(rand(2, 3))) write(file, """ </body> </html> """) end
要创建图像,默认情况下使用Plots.GRBackend引擎,该引擎可以执行光栅或矢量图像输出。 根据show函数的mime参数中指定的类型,将生成相应的结果。 MIME"image/png"()形成png格式的图像。 MIME"image/svg+xml"()生成一个svg图像。 但是,在第二种情况下,您应注意形成了一个完全独立的xml文档的事实,该文档可以作为单独的文件编写。 同时,我们的目标是在HTML页面中嵌入图片,只需在HTML5中插入SVG标记即可完成。 这就是为什么Base.write(file::IO, ::Type{Svg}, p::Plots.Plot)方法Base.write(file::IO, ::Type{Svg}, p::Plots.Plot)切出xml标头的原因,否则会违反HTML文档的结构。 虽然,即使在这种情况下,大多数浏览器也能够正确显示图像。
关于Base.write(file::IO, ::Type{Png}, p::Plots.Plot) ,此处的实现功能是我们只能将二进制数据插入Base64格式的HTML中。 我们使用<img src="data:image/png;base64,"/>构造方法来执行此操作。 对于转码,我们使用Base64EncodePipe 。
Base.write(file::IO, df::DataFrame)方法Base.write(file::IO, df::DataFrame)以DataFrame对象的html表格式提供输出。
结果页面如下:
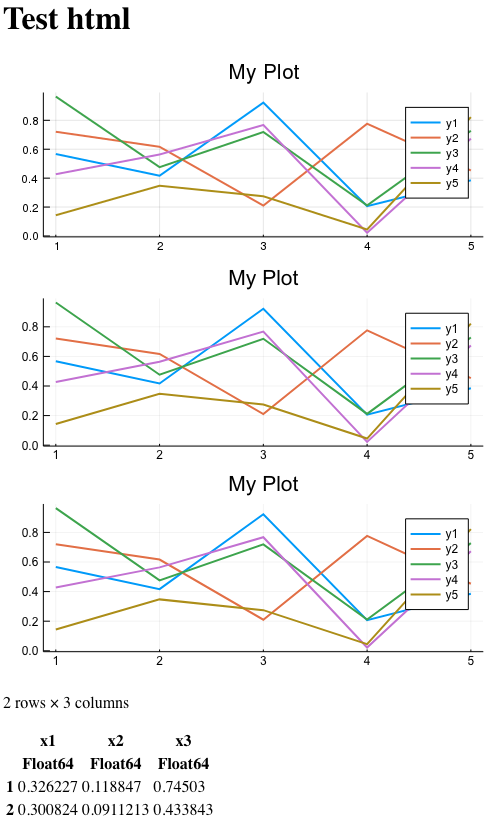
在图像中,所有三张图片看起来都大致相同,但是请记住,从HTML的角度来看,其中一张未正确插入(额外的xml标头)。 一种是栅格,这意味着在不损失细节的情况下不能增加栅格。 并且只有其中之一作为正确的svg片段插入HTML标记中。 而且可以轻松缩放,而不会丢失细节。
自然,该页面非常简单。 但是CSS可以进行任何视觉增强。
例如,当显示的表数是由实际数据而不是模板确定时,这种生成报告的方法很有用。 例如,您需要按某个字段对数据进行分组。 并为每个组形成单独的块。 由于形成页面时,结果取决于对Base.write的调用Base.write ,因此很明显,将所需的块包装到循环中,使输出依赖于数据等没有问题。
代码示例:
using DataFrames # ptable = DataFrame( Symbol = ["H", "He", "C", "O", "Fe" ], Room = [:Gas, :Gas, :Solid, :Gas, :Solid] ) res = groupby(ptable, [:Room]) # open("out2.html", "w") do f for df in (groupby(ptable, [:Room])) write(f, "<h2>$(df[1, :Room])</h2>\n") show(f, MIME"text/html"(), DataFrame(df)) write(f, "\n") end end
该脚本的结果是HTML页面的一部分。

请注意,不需要装饰/格式转换的所有内容都直接通过Base.write函数显示。 同时,所有需要转换的内容都通过Base.show输出。
编织
Weave是由Julia实现的科学报告生成器。 使用生成器Pweave,Knitr,rmarkdown,Sweave的思想。 它的主要任务是以任何一种提议的语言(Noweb,Markdown,脚本格式)将源标记导出为LaTex,Panddoc,Github markdown,MultiMarkdown,Asciidoc,reStructuredText格式。 而且,即使在IJulia笔记本中,反之亦然。 在后一部分,它类似于Jupytext。
也就是说,Weave是一种工具,允许您编写包含各种标记语言的Julia代码的模板,并在输出时编写具有另一种语言的标记(但具有执行Julia代码的结果)。 这是专门针对研究人员的非常有用的工具。 例如,您可以准备一篇关于Latex的文章,该文章将在Julia上插入,并自动计算结果及其替换。 Weave将为最终文章生成一个文件。
使用相应的插件https://atom.io/packages/language-weave支持Atom编辑器。 这使您可以开发和调试标记中嵌入的Julia脚本,然后生成目标文件。
如前所述,Weave的基本原理是解析包含带有文本标记的模板(公式等),并将代码粘贴到Julia上。 代码执行的结果可以显示在最终报告中。 文本,代码的输出,结果的输出,图形的输出-所有这些都可以单独配置。
要处理模板,您需要运行一个外部脚本,该脚本会将所有内容收集到一个文档中,并将其转换为所需的输出格式。 也就是说,分别使用模板和处理程序。
这样的处理脚本的示例:
# : # Markdown weave("w_example.jmd", doctype="pandoc" out_path=:pwd) # HTML weave("w_example.jmd", out_path=:pwd, doctype = "md2html") # pdf weave("w_example.jmd", out_path=:pwd, doctype = "md2pdf")
文件名中的jmd是Julia Markdown。
采取与我们先前工具相同的示例。 但是,我们将插入一个标题,其中包含Weave可以理解的有关作者的信息。
--- title : Intro to Weave.jl with Plots author : Anonymous date : 06th Feb 2019 --- # Intro ## Plot ` ``{julia;} using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``julia rand(2, 3) ` `` ` ``julia DataFrame(rand(2, 3)) ` ``
转换为pdf的片段看起来像这样:

乳胶用户很好地认识了字体和布局。
对于每一段嵌入式代码,您都可以确定该代码的处理方式以及最终显示的内容。
例如:
- echo = true-将显示代码
- eval = true-将显示代码执行的结果
- 标签-添加标签。 如果使用Latex,则它将用作图:标签
- fig_width,fig_height-图像大小
- 依此类推
有关noweb和脚本格式以及有关此工具的更多信息,请参见http://weavejl.mpastell.com/stable/
Literate.jl
当该软件包的作者被问到为什么要使用Literate时,指的是Donald Knutt的Literate Programming范式。 该工具的任务是基于Julia代码生成文档,其中包含markdown格式的注释。 与之前检查过的Weave工具不同,他无法使用执行结果来制作文档。 但是,该工具是轻量级的,主要侧重于文档代码。 例如,帮助编写可以放在任何markdown平台上的漂亮示例。 通常在其他文档工具链中使用,例如,与Documenter.jl一起使用。
输出格式有三个可能的选项-降价,笔记本和脚本(纯Julia代码)。 它们都不执行已执行的代码。
带有Markdown注释(在第一个字符#之后)的示例源文件:
#!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd()) # documenter=true # # Intro # ## Plot using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
如果未明确禁用它们的生成,那么他的工作结果将是Markdown文档和Documenter指令。
` ``@meta EditURL = "https://github.com/TRAVIS_REPO_SLUG/blob/master/" ` `` ` ``@example literate_example #!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd(), documenter=true) ` `` # Intro ## Plot ` ``@example literate_example using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``@example literate_example rand(2, 3) DataFrame(rand(2, 3)) ` `` *This page was generated using [Literate.jl](https://github.com/fredrikekre/Literate.jl).*
故意在markdown内插入代码,在第一个和后续的撇号之间留一个空格,以免在文章发表时弄乱。
查看更多详细信息https://fredrikekre.imtqy.com/Literate.jl/stable/
Documenter.jl
文档生成器。 其主要目的是为以Julia编写的软件包形成可读的文档。 Documenter转换带有Markdown标记和嵌入的Julia代码的html或pdf示例以及模块源文件,以提取Julia-docstrings(Julia自己的注释)。
典型文档的示例:

在本文中,我们将不讨论文档的原理,因为以一种好的方式,这应该作为有关模块开发的单独文章的一部分来完成。 但是,我们将在这里查看Documenter的某些方面。
首先,值得一提的是屏幕分为两部分-左侧包含一个交互式目录。 实际上,右侧是文档的文本。
具有示例和文档的典型目录结构如下:
docs/ src/ make.jl src/ Example.jl ...
docs/src目录是markdown文档。 在src共享源目录的某处可以找到示例。
Docuementer的密钥文件是docs/make.jl 该文件的内容适用于Documenter本身:
using Documenter, DocumenterTools makedocs( modules = [Documenter, DocumenterTools], format = Documenter.HTML( # Use clean URLs, unless built as a "local" build prettyurls = !("local" in ARGS), canonical = "https://juliadocs.imtqy.com/Documenter.jl/stable/", ), clean = false, assets = ["assets/favicon.ico"], sitename = "Documenter.jl", authors = "Michael Hatherly, Morten Piibeleht, and contributors.", analytics = "UA-89508993-1", linkcheck = !("skiplinks" in ARGS), pages = [ "Home" => "index.md", "Manual" => Any[ "Guide" => "man/guide.md", "man/examples.md", "man/syntax.md", "man/doctests.md", "man/latex.md", hide("man/hosting.md", [ "man/hosting/walkthrough.md" ]), "man/other-formats.md", ], "Library" => Any[ "Public" => "lib/public.md", hide("Internals" => "lib/internals.md", Any[ "lib/internals/anchors.md", "lib/internals/builder.md", "lib/internals/cross-references.md", "lib/internals/docchecks.md", "lib/internals/docsystem.md", "lib/internals/doctests.md", "lib/internals/documenter.md", "lib/internals/documentertools.md", "lib/internals/documents.md", "lib/internals/dom.md", "lib/internals/expanders.md", "lib/internals/mdflatten.md", "lib/internals/selectors.md", "lib/internals/textdiff.md", "lib/internals/utilities.md", "lib/internals/writers.md", ]) ], "contributing.md", ], ) deploydocs( repo = "github.com/JuliaDocs/Documenter.jl.git", target = "build", )
如您所见,此处的关键方法是makedocs和deploydocs ,它们确定未来文档的结构以及放置位置。 makedocs提供了从所有指定文件中形成markdown标记的方法,包括执行嵌入式代码和提取文档字符串注释。
Documenter支持许多用于插入代码的指令。 他们的格式是`` @something
@docs , @autodocs链接到从Julia文件中提取的文档字符串文档。@ref , @meta , @index , @contents链接,索引页面的指示等。@example , @repl , @eval嵌入式Julia代码的执行模式。- ...
实际上,指令@example, @repl, @eval的存在决定了是否在此概述中包括Documenter。 而且,前面提到的Literate.jl可以自动生成这样的标记。 也就是说,使用文档生成器作为报告生成器没有任何基本限制。
有关Documenter.jl的更多信息,请参见https://juliadocs.imtqy.com/Documenter.jl/stable/
结论
尽管Julia语言很年轻,但已经为它开发的软件包和工具使我们可以谈论在高负载服务中的充分使用,而不仅仅是试用项目的实施。 如您所见,已经提供了生成各种文档和报告的功能,包括文本和图形形式的代码执行结果。 此外,根据报告的复杂性,我们可以在创建模板的简便性和生成报告的灵活性之间进行选择。
本文不考虑来自Genie.jl包的Flax生成器。 Genie.jl是尝试在Rails上实现Julia的尝试,而Flax是eRubis的一种类似形式,为Julia插入了代码。 但是,Flax不作为单独的软件包提供,并且Genie不包含在主软件包存储库中,因此此审阅未将其包括在内。
另外,我想提到Makie.jl和Luxor.jl软件包 ,它们提供了复杂的矢量可视化的形式。 他们的工作结果也可以用作报告的一部分,但与此相关的另一篇文章也应写成。
参考文献