
丑闻,重要且非常酷的材料每天都不会在媒体上发布,而且没有任何编辑者会承诺以100%的准确性预测文章的成功。 团队拥有的最大直觉是说“强”的材料或“普通”的材料。 仅此而已。 然后开始媒体的不可思议的魔力,借助它,该文章可以与其他出版物的数十个链接一起到达搜索结果的顶部,否则该材料将被忽略。 就发表冷酷的文章而言,媒体网站会定期受到用户的大量涌入,我们将其谦虚地称为“ habraeffect”。
今年夏天,
共和国出版网站成为其作者专业精神的受害者:有关养老金改革,学校教育和适当营养的文章总共吸引了数百万读者。 上述每种材料的出版都导致了如此之高的负担,以致直到共和国网站倒台之前,绝对只剩下“一点点空间”。 主管部门意识到必须进行一些更改:有必要更改项目的结构,使其可以对工作条件的变化(主要是外部负载)做出强烈反应,同时保持功能齐全,即使在出席人数急剧增加的情况下也可以被读者使用。 在这种时候,共和党技术团队的手动干预将是最少的,这是一个很大的收获。
根据与共和国专家就实施心愿清单的各种选择进行的共同讨论的结果,我们决定将出版物的网站转移到Kubernetes *。 关于这一切使我们所有人付出了什么,并将成为我们今天的故事。
*在行动中,没有一名共和党技术专家受伤总体上看起来如何
当然,这一切都始于有关如何“现在”和“以后”发生一切的谈判。 不幸的是,IT市场中的现代范式意味着,只要一家公司愿意提供某种基础架构解决方案,他们就会将其转为总承包服务价格表。 看来这项工作是“交钥匙的”-有条件的董事或企业主会比这更好吗? 我付了钱,我的头没有受伤:规划,开发,支持-一切都在那里,在承包商方面,企业只能赚钱才能支付如此愉快的服务。
但是,从长远来看,IT基础架构的完全转移并不总是适合客户。 从各个角度来看,作为一个大团队工作更正确,因此,在项目完成之后,客户可以了解如何进一步使用新的基础架构,并且车间的同事们不会提出“哦,但是您在这里做了什么?”的问题。 签署完工证明和结果证明后。 共和党人持相同意见。 结果,我们用了两个月的时间将四个人降落到客户那里,客户不仅实现了我们的想法,而且在共和国方面也接受了技术培训的专家,以进一步开展工作并在Kubernetes的现实中生存。
各方都从中受益:我们迅速完成了工作,使我们的专家为取得新成就做好了准备,并让Republic作为我们自己的工程师提供咨询支持的客户。 另一方面,该出版物获得了适应“ habraeffects”的新基础设施,自己保留的技术专家队伍以及在需要时寻求帮助的能力。
我们正在准备桥头堡
“摧毁-不建造。” 这句话适用于所有事物。 当然,最简单的解决方案似乎是前面提到的劫持客户基础设施并把客户,客户与自己联系起来,或者对现有员工进行超频以及要求聘请新技术专家的人质。 我们走了第三种方法,而不是今天最受欢迎的方法,并从共和党工程师的培训开始。
大约在一开始,我们就看到了一种解决方案来确保站点的正常运行:
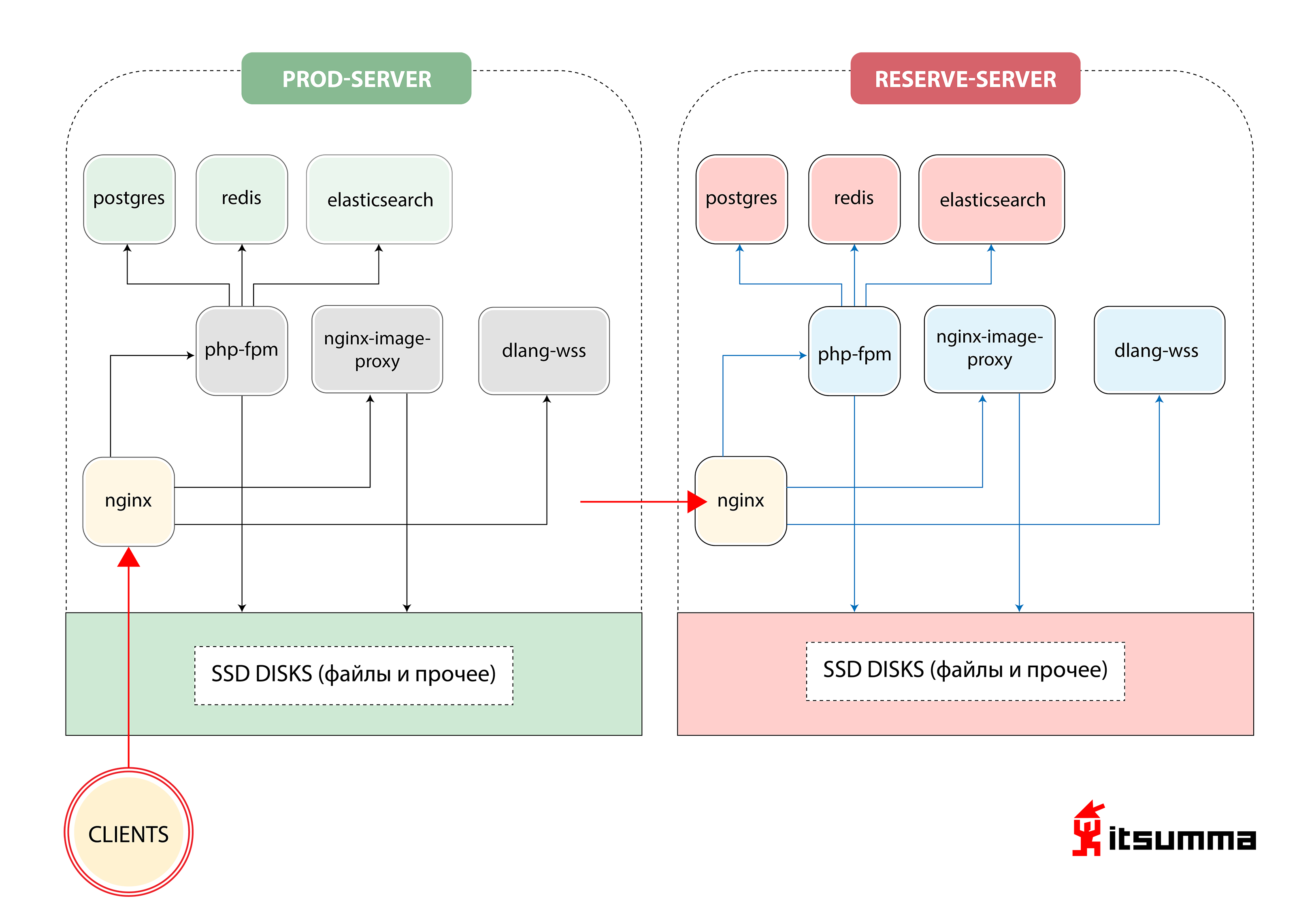
也就是说,Republic只有两个铁服务器-主服务器和备份服务器。 对我们来说,最重要的事情是实现客户技术专家的思维方式的转变,因为他们之前处理的是非常简单的NGINX,PHP-fpm和PostgreSQL。 现在他们面临着Kubernetes的可扩展容器架构。 因此,首先,我们将本地Republic开发切换到docker-compose环境。 而这仅仅是第一步。
在我们着陆之前,Republic开发人员将其本地工作环境保留在通过Vagrant配置的虚拟机中,或者通过sftp直接与dev服务器一起使用。 根据虚拟机的一般基本映像,每个开发人员都“为自己”“预先”配置了他的计算机,这导致了整套不同的配置。 这种方法的结果是,团队中新人的加入成倍地增加了他们进入项目的时间。
在新的现实中,我们为团队提供了更加透明的工作环境结构。 它声明性地描述了项目需要什么软件和哪个版本,服务(应用程序)之间的连接和交互顺序。 此说明已上传到单独的git存储库,以便可以方便地进行集中管理。
所有必需的应用程序都开始在单独的Docker容器中运行-这是一个具有nginx,许多静态函数,用于处理图像的服务(调整大小,优化等)的常规php网站,以及针对以D编写的Web套接字的单独服务所有配置文件(nginx-conf,php-conf ...)也成为项目代码库的一部分。
因此,完全“重新创建”了本地环境,与当前服务器基础结构完全相同。 因此,减少了在开发人员的本地计算机和产品上维护相同环境所需的时间。 反过来,这极大地避免了由每个开发人员的手写本地配置引起的完全不必要的问题。
结果,在docker-compose环境中提出了以下服务:
- php-fpm应用程序的网站;
- nginx;
- impproxy和cairosvg(用于处理图像的服务);
- Postgres
- 重做
- 弹性搜索
- 喇叭(与D上的Web套接字相同的服务)。
从开发人员的角度来看,使用代码库的工作保持不变-将代码库从单独的目录(带有站点代码的基本存储库)安装在必要的服务中:必要的服务:nginx服务中的public目录,php-fpm服务中的所有php应用程序代码。 从单独的目录(包含所有组合环境配置)中,将相应的配置文件安装在nginx和php-fpm服务中。 具有数据postgres,elasticsearch和redis的目录也安装在开发人员的本地计算机上,因此,如果必须重建/删除所有容器,这些服务中的数据将不会丢失。
为了使用应用程序日志-也在docker-compose环境中-提出了ELK堆栈的服务。 以前,部分应用程序日志是用标准的/ var / log / ...编写的,php应用程序日志和执行是用Sentry编写的,并且这种“分散式”日志存储选项的使用极为不便。 现在,已经对应用程序和服务进行了配置和改进,以与ELK堆栈进行交互。 使用日志变得更加容易;开发人员现在拥有一个方便的界面来搜索和过滤日志。 将来(已经在多维数据集中)-您可以查看该应用程序特定版本的日志(例如,前一天启动的kronzhoba)。
此外,共和国队开始了短暂的适应。 团队需要了解和学习如何在新的开发范例中工作,其中应考虑以下内容:
- 应用程序变为无状态,并且它们随时可能丢失数据,因此,应对数据库,会话和静态文件进行不同的构建。 PHP会话应集中存储并在所有应用程序实例之间共享。 它可能继续是文件,但是由于其易于管理,因此经常将Redis用于这些目的。 数据库容器应“装载”数据目录,或者数据库应在容器基础结构之外运行。
- 大约50-60 GB的图像文件存储不应位于“ Web应用程序内部”。 为此,必须使用一些外部存储,cdn系统等。
- 现在,所有应用程序(数据库,应用程序服务器...)都是单独的“服务”,并且应相对于新名称空间配置它们之间的交互。
在Republic开发团队习惯了创新之后,我们开始将出版物的销售基础架构转移到Kubernetes。
这是Kubernetes
在为本地开发的docker-compose环境构建的基础上,我们开始将项目转换为“多维数据集”。 我们将所有在本地构建项目的服务都“打包到容器中”:我们组织了一个线性且易于理解的过程来构建应用程序,存储配置,编译静态函数。 从开发的角度来看,他们将我们需要的配置参数删除到环境变量中,开始将会话存储在文件中而不是萝卜中。 我们提出了测试环境,在该环境中部署了可行的网站版本。
由于这是一个以前的整体项目,因此很明显前端和后端版本之间分别存在着艰难的关系,并且这两个组件是同时部署的。 因此,我们决定以这样的方式构建Web应用程序的Pod,以使两个容器可以旋转到一个Pod中:php-fpm和nginx。
我们还构建了自动缩放功能,以便Web应用程序在流量高峰时最多可扩展到12个,并设置某些活动/就绪测试,因为该应用程序至少需要运行2分钟(因为您需要预热缓存,生成配置...)
当然,立即有各种各样的浅滩和细微差别。 例如:对于分发它的Web服务器和fpm上的应用程序服务器来说,编译的静态文件都是必需的,它们在运行时会生成某种图片,而svg会直接将其提供给代码。 我们意识到,为了避免起床两次,我们需要创建一个中间的构建容器,并通过多阶段容器化最终组件。 为此,我们创建了几个中间容器,分别从中拉出依赖项,然后分别收集静态变量(css和js),然后将其放入两个容器(在nginx和fpm中),它们是从中间构建容器中复制的。
我们开始
为了在第一次迭代中使用文件,我们创建了一个公共目录,该目录同步到所有工作计算机。 所谓“同步”一词,我的意思是您首先想到的就是恐怖-rsync一圈。 显然是一个错误的决定。 结果,我们在GlusterFS上获得了所有磁盘空间,并设置了图片处理功能,以便始终可以从任何计算机上访问它们,并且不会降低速度。 为了使我们的应用程序与存储系统(postgres,elasticsearch,redis)进行交互,在k8s中创建了externalName服务,例如,在紧急切换到备份数据库的情况下,请在一处更新连接参数。
crones的所有工作都交给了新的k8s实体-cronjob,它可以根据特定的时间表运行。
结果,我们得到了以下架构:
 可点击
可点击哦好难
这是第一个版本的发布,因为与基础架构的完整重组同时,该站点仍在进行重新设计。 该网站的一部分是使用一些参数(用于静态参数和其他所有参数)构建的,而另一部分是使用其他参数构建的。 有必要...温和地...将所有这些多级容器弄乱,以不同顺序复制它们的数据,等等。
我们还必须围绕CI \ CD系统与铃鼓共舞,以教导所有这些内容,以便从不同的存储库和不同的环境进行部署和控制。 毕竟,您需要对应用程序版本进行持续控制,以便您可以了解何时部署服务或服务以及这些错误或错误开始于哪个版本的应用程序。 为此,我们建立了正确的日志记录系统(以及日志记录区域性本身)并实现了ELK。 同事学会了设置某些选择器,了解哪个cron生成哪些错误,通常如何执行,因为在执行cron容器后的“多维数据集”中,您将不再陷入困境。
但是对我们来说,最困难的事情是重新设计和修改整个代码库。
让我提醒您,Republic是一个已有10年历史的项目。 它从一个团队开始,到现在正在发展,并且很难发现所有可能存在错误和错误的源代码。 当然,此时此刻,我们的四人登陆聚会将团队其他成员的资源连接起来:我们点击并测试了整个站点,甚至测试了自2016年以来人们从未去过的那些部分。
任何地方都不会失败
在星期一的清晨,当人们带着摘要去大众邮寄时,我们所有人都有所涉足。 罪魁祸首很快被发现:cronjob开始并疯狂地开始给过去一周内希望获得新闻精选的每个人发送信件,一路吞噬了整个集群的资源。 我们无法忍受这种行为,因此我们很快对所有资源设置了严格的限制:容器可以消耗多少处理器和内存等等。
共和国的开发人员团队如何应对
我们的活动带来了很多变化,我们对此有所了解。 实际上,我们不仅重绘了出版物的基础架构,还没有重新绘制通常的“主备份服务器”捆绑包,而是实施了一个容器解决方案,可以根据需要连接其他资源,而且完全改变了进一步开发的方法。
一段时间后,这些家伙开始理解这不是直接使用代码,而是使用抽象应用程序。 有了CI \ CD流程(基于Jenkins构建),他们开始编写测试,他们获得了成熟的dev-stage-prod环境,可以在其中实时地测试其应用程序的新版本,查看出现问题的地方,并学习生活在其中。新的理想世界。
客户得到了什么
首先,共和国终于有了受控的部署流程! 过去是这样的:在共和国,有一个负责任的人去了服务器,手动启动了所有东西,然后收集了静态信息,用手检查了一切都没有落下……现在建立了部署过程,以便开发人员参与开发,而不会在其他任何事情上浪费时间。 负责人现在有一项任务-监视发布的总体情况。
在自动或通过“按钮式”部署(有时由于某些业务需求,自动部署被禁用)推送到master分支之后,Jenkins陷入了竞争:项目的组装开始。 首先,组装所有docker容器:在准备容器中安装依赖项(composer,yarn,npm),如果在部署过程中所需库的列表未更改,则可以加快构建过程; 然后收集php-fpm,nginx和其他服务的容器,类似于docker-compose环境,仅将代码库中必要的部分复制到其中。 此后,将启动测试,如果成功通过测试,则将映像推送到私有存储,并且实际上将部署部署到多维数据集中。
通过将Republic转移到k8s,我们得到了一个由三台真实计算机组成的群集的体系结构,在该群集上可以同时“旋转”最多十二个Web应用程序副本。 同时,系统本身根据当前的负载来决定当前需要多少份副本。 我们从带有静态主服务器和备用服务器的“有效-无效”彩票中抽出Republic,并为它们构建了灵活的系统,以准备雪崩般的站点负载增加。
此时,可能会出现一个问题“伙计们,您将两块铁换成同一块铁,但是通过虚拟化,有什么好处,您还好吗?” 当然,这将是合乎逻辑的。 但只是部分。 结果,我们不仅获得了具有虚拟化功能的硬件。 我们有一个稳定的工作环境,无论是食品还是处女。 对所有项目参与者进行集中管理的环境。 同样,我们获得了一种用于组装整个项目并推出发行版的机制,对每个人来说都是相同的。 我们有一个方便的项目编排系统。 一旦Republic团队注意到他们通常不再拥有足够的当前资源以及超高负载的风险(或者当它已经发生并且一切都已经解决时),他们便只用了另一台服务器,在10分钟内推出了群集节点在其上的角色,然后进行操作一切又美好又美好。 先前的项目结构根本没有建议采用这种方法;解决此类问题既没有慢速解决方案,也没有快速解决方案。
其次,出现了无缝部署:访问者可以使用该应用程序的旧版本,也可以使用新版本。 内容可能是新的,但是样式却旧了,这与以前不同。
结果,企业感到满意:各种新事物现在可以更快,更频繁地完成。
从“但让我们尝试”到“完成”,该项目总共花费了2个月的时间。 我们这支队伍是4个人的英勇登陆+在验证代码和测试过程中对“基地”的支持。
用户得到了什么
访客原则上没有看到这些变化。 RollingUpdate策略的部署过程是“无缝地”构建的。 推出新版本的网站绝不会伤害用户,在测试通过和活跃/就绪测试之前,新版本的网站将不可用。 他们只是看到该网站正在运行,并且在发布精彩文章后也不会因此而崩溃。 通常,这是任何项目所需要的。