我们是MTS的大数据,这是我们的第一篇文章。 今天,我们将讨论什么技术允许我们存储和处理大数据,以便始终有足够的资源进行分析,并且购买铁的成本不会高得离谱。
他们考虑在2014年在MTS上创建大数据中心:有必要扩展经典的分析存储和基于它的BI报告。 当时,数据处理和BI引擎是SAS-历史上曾经发生过。 尽管存储业务需求已经关闭,但随着时间的流逝,BI的性能和分析存储之上的即席分析功能增长得如此之快,以至于有必要解决生产力不断提高的问题,因为多年来用户数量增长了十倍并持续增长。
竞赛的结果是,Teradata MPP系统出现在MTS中,满足了当时电信的需求。 这是尝试更流行和开放源代码的动力。
 照片-莫斯科新笛卡尔办公室的大数据MTS团队
照片-莫斯科新笛卡尔办公室的大数据MTS团队 第一个集群有7个节点。 这足以测试几种业务假设并填补了最初的障碍。 努力没有白费:MTS已经存在大数据三年了,现在数据分析涉及几乎所有功能领域。 团队从三人增加到了200人。
我们希望拥有简单的开发流程,快速检验假设。 为此,您需要三件事:一个具有启动思维,轻量级开发流程和已开发基础架构的团队。 您可以在很多地方阅读和收听有关第一和第二的信息,但是值得分别介绍一下已开发的基础架构,因为电信中的传统和数据源在这里很重要。 发达的数据基础设施不仅在构建数据湖,详细的数据层和店面层。 它还包括工具和数据访问接口,用于产品和命令的计算资源隔离,用于以实时和批处理方式将数据传递给消费者的机制。 还有更多。
所有这些工作都在一个单独的领域中脱颖而出,该领域从事实用程序和数据工具的开发。 该区域称为大数据IT平台。
大数据来自MTS的何处
MTS有很多数据源。 主要基站之一是基站;我们为俄罗斯超过7800万用户提供服务。 我们还有许多与电信无关的服务,可让您接收更多功能的数据(电子商务,系统集成,物联网,云服务等-所有“非电信”已经带来了全部收入的20%)。
简而言之,我们的架构可以表示为以下图形:
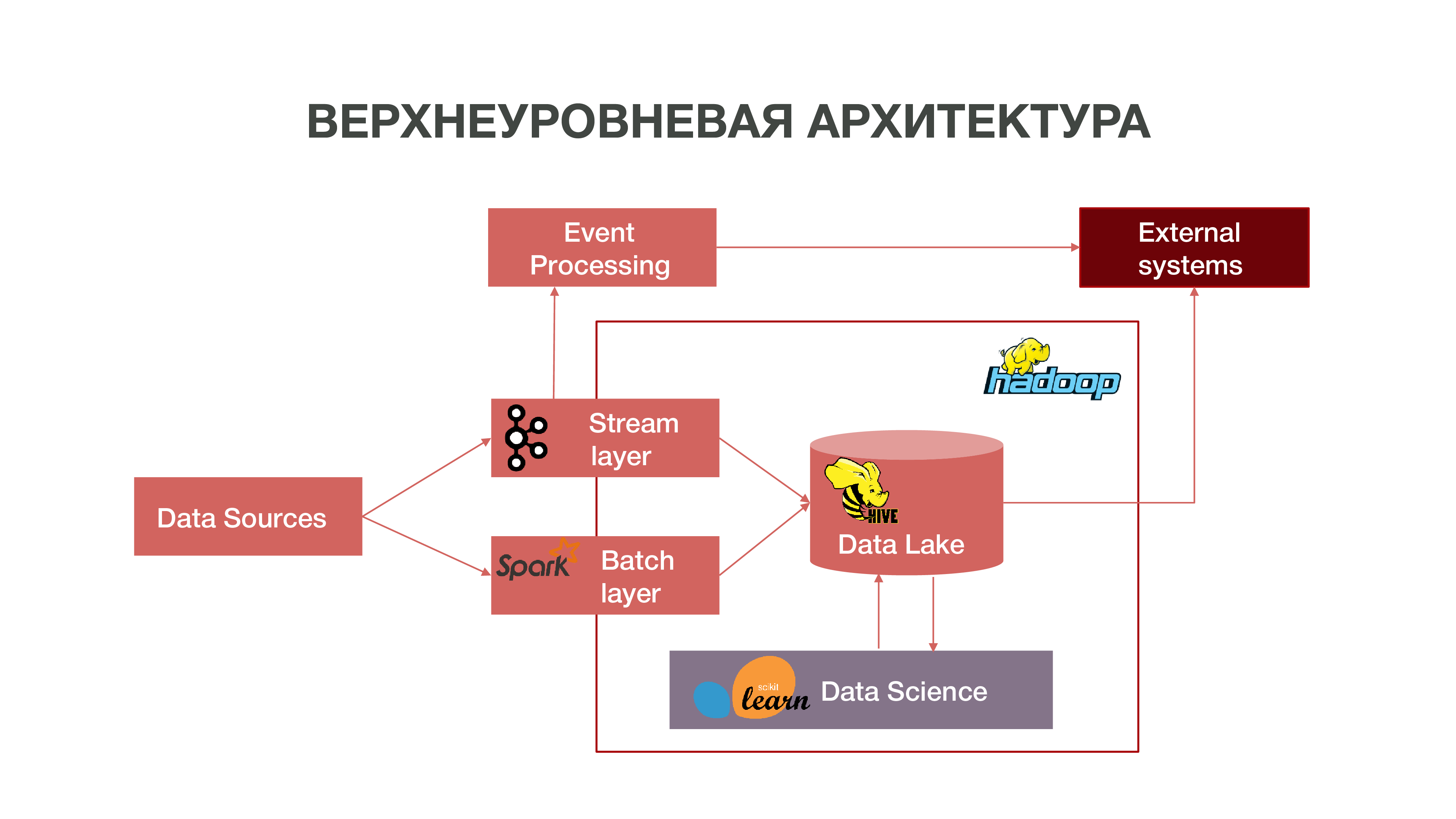
正如您在图表上看到的,数据源可以实时传递信息。 我们使用流层-我们可以处理实时信息,从中提取一些我们感兴趣的事件,并在此基础上进行分析。 为了提供这样的事件处理,我们使用Apache Kafka,Apache Spark和Scala语言的代码开发了一个相当标准的实现(从体系结构的角度来看)。 通过这样的分析获得的信息既可以在MTS内部使用,也可以在将来的外部使用:企业通常对订户的某些行为非常感兴趣。
还有一种批量加载数据的模式-批处理层。 通常,下载会按计划每小时进行一次,我们使用Apache Airflow作为计划程序,而批处理下载过程本身是在python中实现的。 在这种情况下,将大量数据加载到Data Lake中,这是用历史数据填充大数据所必需的,我们应该在该历史数据上训练我们的数据科学模型。 结果,基于关于其网络活动的数据在历史上下文中形成订户简档。 这使我们能够获得预测性统计数据并建立人类行为的模型,甚至创建他的心理肖像-我们拥有如此独立的产品。 该信息对于例如营销公司非常有用。
我们还有大量构成经典存储库的数据。 也就是说,我们汇总有关各种事件的信息-用户和网络。 所有这些匿名数据还有助于更准确地预测对公司重要的用户兴趣和事件,例如,预测可能的设备故障并及时进行故障排除。
Hadoop的
如果回顾过去并回想一下大数据通常是如何出现的,则应注意,基本上是出于营销目的进行数据的累积。 对于大数据是什么,没有明确的定义-千兆字节,太字节,PB级。 不可能画一条线。 对于某些人而言,大数据为数十GB,对于其他人而言,则为PB。
碰巧的是,随着时间的流逝,世界各地积累了许多数据。 为了对这种数据进行某种或多或少的重要分析,自上世纪70年代以来一直在开发的常规存储库已不再足够。 当信息井开始于2000年代,10年代,并且有许多设备可以访问Internet时,当物联网出现时,这些存储库在概念上根本无法应对。 这些存储库的基础是关系理论。 即,存在彼此交互的不同形式的关系。 有一个用于描述如何构建和设计存储库的系统。
当旧技术失败时,就会出现新技术。 在现代世界中,大数据分析问题通过两种方式解决:
创建自己的框架,使您可以处理大量信息。 通常,这是由数十万台服务器(例如Google,Yandex)组成的分布式应用程序,它们创建了自己的分布式数据库,使您可以处理如此大量的信息。
Hadoop技术的发展是一个分布式计算框架,一个可以存储和处理大量信息的分布式文件系统。 数据科学工具主要与Hadoop兼容,并且这种兼容性为高级数据分析打开了许多可能性。 包括我们在内的许多公司正在向开源Hadoop生态系统迈进。
中央Hadoop集群位于下诺夫哥罗德。 它收集了该国几乎所有地区的信息。 就容量而言,现在可以在此处下载大约8.5 PB的数据。 同样在莫斯科,我们有单独的RND集群在这里进行实验。
由于我们在不同地区有大约一千台服务器,我们在其中进行分析并计划扩展,因此出现了为分布式分析系统正确选择设备的问题。 您可以购买足以存储数据但事实证明不适合分析的设备-仅仅是因为节点上没有足够的资源,CPU核心数和可用RAM。 重要的是要找到一个平衡点,以便获得良好的分析机会,而不会花费很高的设备成本。
英特尔为我们提供了有关如何优化分布式系统工作的不同选择,以便以合理的价格获得数据量中的分析数据。 英特尔推动NAND SSD固态硬盘技术 它比普通硬盘快数百倍。 比这对我们有好处:SSD,尤其是具有NVMe接口的SSD,可以提供足够快的数据访问权限。
此外,英特尔还发布了基于新型非易失性内存英特尔3D XPoint的英特尔Optane SSD服务器固态硬盘。 它们可以应对存储系统上的大量混合负载,并且比常规NAND SSD拥有更长的资源。 为什么对我们有好处:英特尔傲腾SSD可让您在重负载下以低延迟稳定运行。 最初,我们将NAND SSD视为传统硬盘的替代品,因为我们在硬盘和RAM之间移动了大量数据-我们需要优化这些流程。
第一次测试
我们在2016年进行的首次测试。 我们只是尝试将HDD替换为快速NAND SSD。 为此,我们订购了新的英特尔驱动器的样品-当时是DC P3700。 他们还对Hadoop进行了标准测试-Hadoop是一个生态系统,可让您评估不同条件下性能的变化。 这些是TeraGen,TeraSort,TeraValidate的标准化测试。

TeraGen允许您“生成”一定数量的人工数据。 例如,我们占用了1 GB和1 TB。 使用TeraSort,我们在Hadoop中排序了此数据量。 这是相当耗费资源的操作。 最后一个测试-TeraValidate-使您可以确保数据以正确的顺序排序。 也就是说,我们第二遍。

作为一项实验,我们只将汽车与SSD配合使用-也就是说,Hadoop仅安装在SSD上而不使用硬盘驱动器。 在第二个版本中,我们使用SSD来存储临时文件HDD来存储基本数据。 在第三个版本中,两者都使用了硬盘驱动器。
这些实验的结果使我们感到不满意,因为性能指标的差异不超过10-20%。 也就是说,我们意识到Hadoop在存储方面对SSD并不十分友好,因为最初创建该系统是为了在HDD上存储大数据,而没有人针对快速而昂贵的SSD对其进行优化。 并且由于当时SSD的成本非常高,因此我们到目前为止决定不讨论这个故事,而开始使用硬盘驱动器。
第二次测试
然后,英特尔推出了基于3D XPoint内存的新型服务器端英特尔Optane SSD。 它们于2017年底发布,但样本较早提供给我们。 3D XPoint内存功能可以将Intel Optane SSD用作服务器中RAM的扩展。 由于我们已经意识到在块存储设备级别解决IO Hadoop性能问题并不容易,因此我们决定尝试一个新选项-使用英特尔内存驱动技术(IMDT)扩展RAM。 在今年年初,我们是世界上第一个对其进行测试的公司。
比这对我们有好处:它比RAM便宜,这使您可以收集具有TB级RAM的服务器。 而且由于RAM足够快,因此您可以将大数据集加载到其中并进行分析。 让我提醒您,我们分析过程的独特之处在于我们多次访问数据。 为了进行某种分析,我们需要将尽可能多的数据加载到内存中,并多次“滚动”对这些数据进行某种分析。
Swindon的英特尔英语实验室为我们分配了一个由三台服务器组成的集群,在测试过程中,我们将它们与MTS的测试集群进行了比较。

从图中可以看出,根据测试结果,我们得到了相当不错的结果。
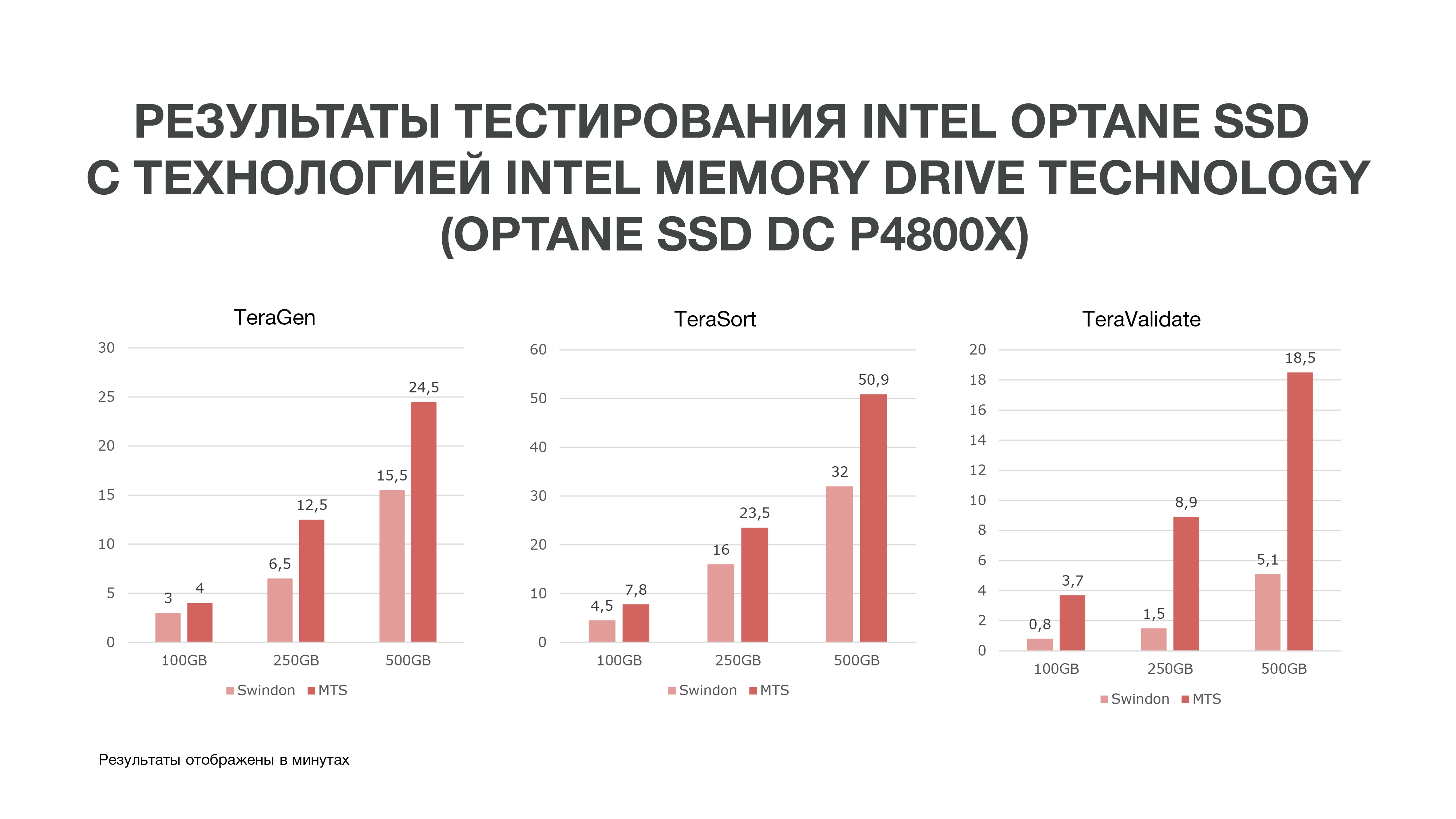
同一款TeraGen的生产率提高了将近两倍,即TeraValidate-提高了75%。 这对我们非常有用,因为正如我所说,我们多次访问了内存中的数据。 因此,如果我们获得了这样的性能提升,它将特别有助于我们进行数据分析,尤其是实时分析。
我们在不同条件下进行了三个测试。 100 GB,250 GB和500 GB。 我们使用的内存越多,采用Intel内存驱动技术的Intel Optane SSD的性能就会更好。 也就是说,我们分析的数据越多,效率越高。 在更多节点上进行的分析可以在更少节点上进行。 而且,我们在计算机上还获得了大量内存,这对于执行数据科学任务非常有用。 根据测试结果,我们决定购买这些驱动器以在MTS上工作。
如果您还必须选择和测试用于存储和处理大量数据的硬件,对于我们来说,阅读遇到的困难以及最终的结果将是一件很有趣的事情:在注释中写上。
作者:
MTS大数据部门应用架构能力中心主管Grigory Koval grigory_koval
大数据MTS部门数据管理部主管Dmitry Shostko zloi_diman