第2/3部分
第3/3部分
大家好! 在本文中,我想简化信息并分享创建和使用Kubernetes内部集群的经验。
在过去的几年中,这种容器编排技术向前迈了一大步,并已成为成千上万家公司的一种企业标准。 有些人在生产中使用它,其他人只是在项目中对其进行测试,但是无论您怎么说,围绕它的热情都会带着严肃的心情发出。 如果您以前从未使用过它,那么该开始约会了。
0.简介
Kubernetes是一种可扩展的编排技术,可以从在单个节点上安装开始,并基于内部的数百个节点达到巨大的HA群集的大小。 大多数流行的云提供商都提供不同类型的Kubernetes实现-使用和使用。 但是情况有所不同,有些公司不使用云,他们希望获得现代编排技术的所有优势。 接下来是在裸机上安装Kubernetes的过程。

1.简介
在此示例中,我们将创建一个Kubernetes HA群集,该群集具有用于多个主服务器的拓扑,并使用外部群集etcd作为基础层,并在其中使用MetalLB负载均衡器。 在所有工作节点上,我们将GlusterFS部署为简单的内部分布式集群存储。 我们还将尝试使用我们的个人Docker注册表在其中部署几个测试项目。
通常,有多种创建Kubernetes HA群集的方法:流行的kubernetes-the-hard-way文档中描述的困难而深入的路径,或者使用kubeadm实用程序的更简单方法。
Kubeadm是Kubernetes社区创建的工具,专门用于简化Kubernetes的安装并简化过程。 早先,建议仅将Kubeadm用于创建具有一个主节点的小型测试集群。 但是在过去的一年中,已经做了很多改进,现在我们可以使用它来创建具有多个主节点的HA群集。 根据Kubernetes社区新闻,将来,将推荐使用Kubeadm作为安装Kubernetes的工具。
Kubeadm文档提供了两种使用堆栈和外部etcd拓扑实现集群的基本方法。 由于HA群集的容错性,我将选择带有外部etcd节点的第二条路径。
这是Kubeadm文档中的图表,描述了此路径:
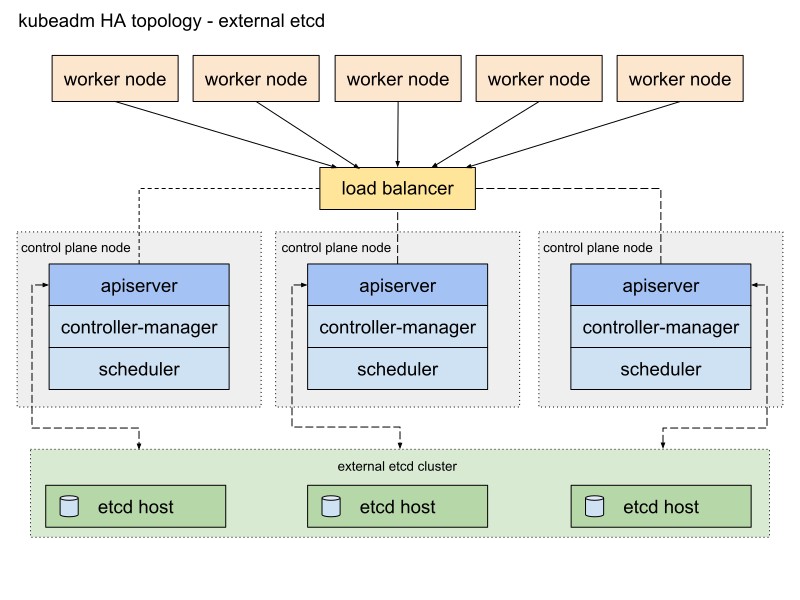
我会稍微改变一下。 首先,我将使用一对HAProxy服务器作为Heartbeat软件包的负载平衡器,该软件包将共享虚拟IP地址。 Heartbeat和HAProxy使用少量的系统资源,因此我将它们放置在一对etcd节点上,以略微减少集群的服务器数量。
对于此Kubernetes集群方案,需要八个节点。 用于外部集群etcd的三台服务器(LB服务也将使用其中的两台),两台用于控制平面的节点(主节点),三台用于工作节点。 它可以是裸机或VM服务器。 在这种情况下,没关系。 如果有很多免费服务器,则可以通过添加更多主节点并将HAProxy with Heartbeat放在单独的节点上来轻松更改方案。 尽管我对于HA群集的第一个实施方案的选择就足够了。
如果需要,可以添加一个安装了kubectl实用程序的小型服务器来管理该集群,或者使用您自己的Linux桌面。
该示例的图表如下所示:
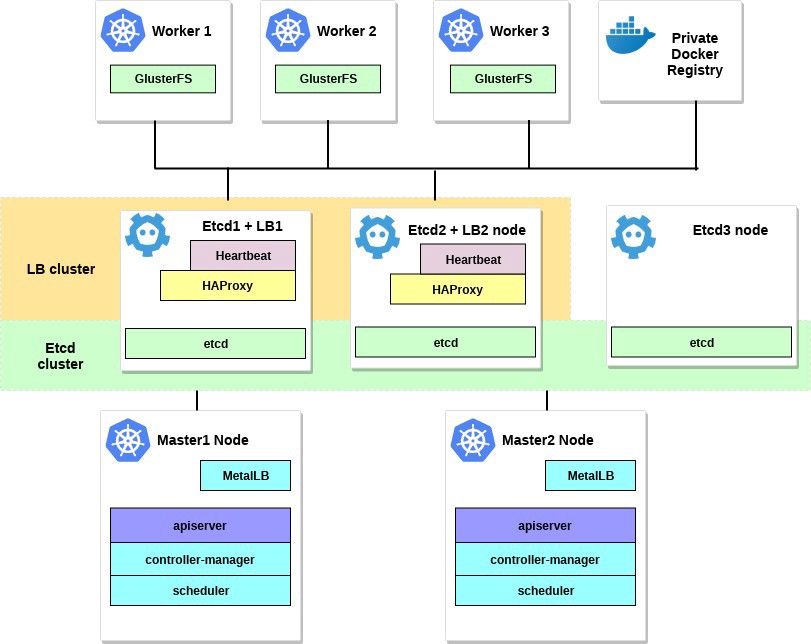
2.要求
您将需要两个具有最低建议系统要求的Kubernetes主节点:根据kubeadm文档的要求,两个CPU和2 GB RAM。 对于工作节点,我建议使用功能更强大的服务器,因为我们将在它们上运行所有应用程序服务。 对于Etcd + LB,我们还可以采用具有两个CPU和至少2 GB RAM的服务器。
为该集群选择一个公共网络或专用网络; IP地址无关紧要; 所有服务器之间以及彼此之间当然都可以访问,这一点很重要。 稍后,在Kubernetes集群内部,我们将建立一个覆盖网络。
此示例的最低要求是:
- 2个服务器,带有2个处理器和2 GB的RAM用于主节点
- 3个服务器,带有4个处理器和4-8 GB RAM用于工作节点
- 3个服务器,带有2个处理器和2 GB的RAM,用于Etcd和HAProxy
- 192.168.0.0/24-子网
192.168.0.1-HAProxy的虚拟IP地址,192.168.0.2-Etcd和HAProxy节点的4个主要IP地址,192.168.0.5-Kubernetes主节点的6个主要IP地址,192.168.0.7-Kubernetes工作节点的9个主要IP地址。
Debian 9数据库已安装在所有服务器上。
还请记住,系统要求取决于群集的大小和功能。 有关更多信息,请参见Kubernetes文档。
3.配置HAProxy和心跳。
我们有多个Kubernetes主节点,因此您需要在它们前面配置一个HAProxy负载均衡器-以分配流量。 这将是一对具有共享虚拟IP地址的HAProxy服务器。 心跳包随附了容错功能。 对于部署,我们将使用前两个etcd服务器。
在第一台和第二台etcd服务器(在此示例中为192.168.0.2–3)上安装并配置带有心跳的HAProxy:
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy
保存原始配置并创建一个新配置:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg
为两个HAProxy添加以下配置选项:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2
如您所见,两个HAProxy服务共享IP地址-192.168.0.1。 该虚拟IP地址将在服务器之间移动,因此我们有点狡猾,并启用net.ipv4.ip_nonlocal_bind参数以允许将系统服务绑定到非本地IP地址。
将此功能添加到/etc/sysctl.conf文件中:
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1
在两个服务器上运行:
sysctl -p
同时在两台服务器上运行HAProxy:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy
确保HAProxy正在运行,并且正在两个服务器上的虚拟IP地址上进行侦听:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
胡德! 现在安装Heartbeat并配置此虚拟IP。
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat
现在该为它创建几个配置文件了:对于第一台和第二台服务器,它们基本上是相同的。
首先创建文件/etc/ha.d/authkeys ,在此文件中,Heartbeat存储用于相互认证的数据。 两个服务器上的文件必须相同:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
该文件只能由root用户访问:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys
现在,在两台服务器上为Heartbeat创建主配置文件:对于每台服务器,它都会略有不同。
创建/etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
通过在两个Etcd服务器上运行uname -n,获取此配置的“ node”参数。 另外,请使用网卡的名称而不是ens18。
最后,您需要在这些服务器上创建/etc/ha.d/haresources文件。 对于两个服务器,文件必须相同。 在此文件中,我们设置公共IP地址并确定哪个节点是默认主节点:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1
一切准备就绪后,在两台服务器上启动Heartbeat服务,并验证我们是否在etcd1 节点上收到了此声明的虚拟IP:
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary
您可以通过在192.168.0.1 6443上运行nc来验证HAProxy是否正常运行。您必须已超时,因为Kubernetes API尚未在服务器端进行侦听。 但这意味着HAProxy和Heartbeat的配置正确。
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded!
4.准备Kubernetes的节点
下一步是准备所有Kubernetes节点。 您需要使用其他一些软件包安装Docker,添加Kubernetes存储库并从中安装kubelet , kubeadm和kubectl软件包。 所有Kubernetes节点(主节点,工作节点等)的此设置均相同
Kubeadm的主要优点是不需要太多其他软件。 在所有主机上安装kubeadm-并使用它; 至少生成CA证书。
在所有节点上安装Docker:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4
之后,在所有节点上安装Kubernetes软件包:
kubeadm :用于加载集群的命令。kubelet :一个组件,它在群集中的所有计算机上运行,并执行诸如启动炉膛和容器的操作。kubectl :与集群通信的util命令行。- kubectl-随意 ; 我经常将其安装在所有节点上,以运行一些Kubernetes命令进行调试。
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}
安装kubeadm和其他软件包后,不要忘记禁用swap。
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab
在其余节点上重复安装。 软件包对于群集中的所有节点都是相同的,并且只有以下配置将确定它们以后将接收的角色。
5.配置HA Etcd群集
因此,在完成准备工作之后,我们将配置Kubernetes集群。 第一个模块将是HA Etcd群集,该群集也使用kubeadm工具进行配置。
在开始之前,请确保所有etcd节点都通过端口2379和2380进行通信。此外,您需要在它们之间配置ssh访问以使用scp 。
让我们从第一个etcd节点开始,然后将所有必需的证书和配置文件复制到其他服务器。
在所有etcd节点上,您需要为kubelet单元添加一个更高优先级的新systemd配置文件:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet
然后,我们将ssh移至第一个etcd节点-我们将使用它为每个etcd节点生成所有必需的kubeadm配置,然后将其复制。
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done
现在使用kubeadm创建主证书颁发机构
etcd1# kubeadm init phase certs etcd-ca
此命令将在/ etc / kubernetes / pki / etcd /目录中创建两个ca.crt和ca.key文件 。
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key
现在,我们将为所有etcd节点生成证书:
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete
然后将kubeadm的证书和配置复制到节点etcd2和etcd3 。
首先在etcd1上生成一对ssh密钥,并将公共部分添加到etcd2和3个 节点上 。 在此示例中,所有命令均代表拥有系统所有权限的用户执行。
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/
在启动etcd集群之前,请确保文件存在于所有节点上:
etcd1上所需文件的列表:
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
对于etcd2节点,这是:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
最后一个节点是etcd3 :
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
当所有证书和配置都就绪后,我们创建清单。 在每个节点上,运行kubeadm命令-为etcd集群生成静态清单:
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
现在,从理论上讲, etcd集群已经配置好并且运行良好。 通过在etcd1 节点上运行以下命令进行验证:
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy
etcd集群已经上升,因此继续前进。
6.配置主节点和工作节点
配置集群的主节点-将这些文件从第一个etcd节点复制到第一个主节点:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:
然后将ssh转到主节点master1并创建具有以下内容的kubeadm-config.yaml文件 :
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
如设置说明所述,将先前复制的证书和密钥移动到master1 节点上的相应目录。
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/
要创建第一个主节点,请执行以下操作:
master1# kubeadm init --config kubeadm-config.yaml
如果以上所有步骤均正确完成,您将看到以下内容:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
将kubeadm初始化的输出复制到任何文本文件,将来在将第二个主节点和工作节点附加到集群时将使用此令牌。
我已经说过Kubernetes集群将为壁炉和其他服务使用某种覆盖网络,因此,此时您需要安装某种CNI插件。 我推荐Weave CNI插件。 经验表明,它更有用且问题更少,但是您可以选择另一个,例如Calico。
在第一个主节点上安装Weave网络插件:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created
请稍等,然后输入以下命令以验证组件炉床是否正在运行:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s
- 建议仅在第一个节点初始化之后才附加控制平面的新节点。
要检查集群状态,请执行以下操作:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1
太好了! 第一个主节点上升。 现在已经准备就绪,我们将完成创建Kubernetes集群的工作-我们将添加第二个主节点和工作节点。
要添加第二个主节点,请在master1上创建一个ssh密钥,并将公共部分添加到master2 。 执行测试登录,然后将一些文件从第一个主节点复制到第二个主节点:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub
在第二个主节点上,将先前复制的证书和密钥移动到适当的目录:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf
将第二个主节点连接到群集。 为此,您需要连接命令的输出,该命令先前是由第一个节点上的kubeadm init传递给我们的。
运行主节点master2 :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane
- 您需要添加
--experimental-control-plane标志。 它可以自动将主数据附加到群集。 没有此标志,通常的工作节点将被简单地添加。
等待一点,直到节点加入集群,然后检查集群的新状态:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1
还要确保所有主节点上的所有pod都正常启动:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m
太好了! Kubernetes集群配置几乎完成了。 最后要做的是添加我们之前准备的三个工作节点。
输入工作节点并执行不带--experimental-control-plane标志的kubeadm join命令。
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
再次检查集群状态:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1
如您所见,我们有一个完全配置的Kubernetes HA群集,其中包含两个主节点和三个工作节点。 它是基于HA etcd群集构建的,在主节点前具有故障安全负载平衡器。 对我来说听起来不错。
7.配置远程集群管理
在本文的第一部分中仍有待考虑的另一项操作是设置用于管理集群的远程kubectl实用程序。 以前,我们从主节点master1运行所有命令,但这仅适合第一次-配置集群时。 最好配置一个外部控制节点。 您可以为此使用笔记本电脑或其他服务器。
登录到该服务器并运行:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1
好的,现在让我们在集群中进行测试,并检查其工作方式。
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s
恭喜你! 您刚刚部署了Kubernetes。 这意味着您的新HA集群已准备就绪。 实际上,使用kubeadm设置Kubernetes集群的过程非常简单且快速。
在本文的下一部分中,我们将通过在所有工作节点上设置GlusterFS,为我们的Kubernetes集群设置内部负载均衡器,以及运行某些压力测试,断开某些节点并检查集群的稳定性来添加内部存储。
后记
是的,在这个例子中,您会遇到很多问题。 无需担心:要撤消更改并使节点返回其原始状态,只需运行kubeadm reset-先前kubeadm所做的更改将被重置,您可以再次进行配置。 另外,不要忘记检查群集节点上的Docker容器的状态-确保它们都已启动并且可以正常运行。 有关损坏的容器的更多信息,请使用docker logs containerid命令 。
今天就这些了。 祝你好运