大家好! 我向您介绍了Analytics Vidhya文章的译文,并概述了2018和2019年趋势中的AI / ML事件。 材料很大,因此分为两部分。 我希望本文不仅会引起专业人士的兴趣,也会引起对AI主题感兴趣的人的兴趣。 祝您阅读愉快!
引言
在过去的几年中,对于AI爱好者和机器学习专业人员的追求已经过去了。 这些技术已经不再是利基市场,已经成为主流,并且现在已经影响着数百万人的生活。 AI部委是在不同的国家/地区建立的[
更多详细信息 -大约 人]和预算分配以跟上这场比赛。
数据科学专业人员也是如此。 几年前,您知道一些工具和技巧就感到很自在,但这一次已经过去了。 数据科学领域最近发生的事件数量之多,以及跟上这一领域的时代发展所需要的知识量,真是令人惊讶。
我决定退后一步,从数据科学专家的角度来看人工智能领域中一些关键领域的发展。 发生了什么突破? 2018年发生了什么,2019年会发生什么? 阅读本文以获得答案!
PS与任何预测一样,以下是我的个人结论,这些结论是基于将各个片段组合成整体的尝试。 如果您的观点与我的观点不同,我将很高兴得知您对2019年数据科学可能发生哪些变化的看法。
本文将涉及的领域是:
-自然语言处理(NLP)
-计算机视觉
-工具和库
-强化学习
-人工智能中的道德问题
自然语言处理(NLP)
强迫机器解析单词和句子似乎总是个白日梦。 语言中的许多细微差别和功能有时甚至对于人们来说也难以理解,但是对于NLP来说,2018年是一个真正的转折点。
我们看到了一个又一个了不起的突破:ULMFiT,ELMO,OpenAl Transformer,Google BERT,但这还不完整。 迁移学习的成功应用(将预训练的模型应用于数据的艺术)为NLP在各种任务中打开了大门。
转移学习-允许您使用相对少量的数据使预训练的模型/系统适应您的特定任务。
让我们更详细地了解其中的一些关键发展。
超低价
ULMFiT由Sebastian Ruder和Jeremy Howard(fast.ai)开发,是今年首个接受转学的框架。 对于初学者来说,缩写ULMFiT代表“通用语言模型精调”。 杰里米(Jeremy)和塞巴斯蒂安(Sebastian)在ULMFiT中正确添加了“通用”一词-该框架几乎可以应用于任何NLP任务!
关于ULMFiT的最好的事情是您不需要从头开始训练模型! 研究人员已经为您完成了最艰巨的任务-接受并申请您的项目。 在六个文本分类任务中,ULMFiT优于其他方法。
您可以
阅读 Pratek Joshi
的教程[Pateek Joshi-大约。 [翻译]。如何开始将ULMFiT用于任何文本分类任务。
艾莫
猜猜ELMo的缩写是什么意思? 语言模型嵌入的首字母缩写[语言模型的附件-大约。 跨]。 发布后,ELMo引起了ML社区的关注。
ELMo使用语言模型来接收每个单词的附件,还考虑了单词适合句子或段落的上下文。 上下文是NLP的关键方面,大多数开发人员以前都曾在其中失败过。 ELMo使用双向LSTM创建附件。
长短期记忆(LSTM)是递归神经网络的一种架构,由Sepp Hochreiter和JürgenSchmidhuber于1997年提出。 像大多数递归神经网络一样,LSTM网络是通用的,因为它具有足够数量的网络元素,可以执行常规计算机能够执行的任何计算,这需要适当的权重矩阵才能视为程序。 与传统的递归神经网络不同,LSTM网络非常适合于在重要事件被不确定的持续时间和边界所分隔的情况下,对分类,处理和预测时间序列的问题进行训练。
- 来源。 维基百科
像ULMFiT一样,ELMo在解决大量NLP任务(例如分析文本的语气或回答问题)方面也大大提高了生产率。
Google的BERT
许多专家指出,BERT的发行标志着NLP进入了一个新时代。 继ULMFiT和ELMo之后,BERT发挥了领导作用,展示了高性能。 正如最初的公告所言:“ BERT在概念上很简单,在经验上也很强大。”
BERT在11个NLP任务中显示了出色的成绩! 查看SQuAD测试中的结果:
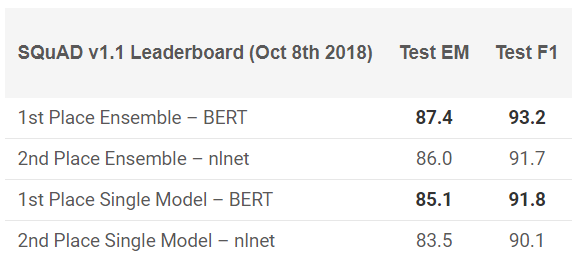
要尝试吗? 您可以在PyTorch或Google的TensorFlow代码上使用重新实现,然后尝试在计算机上重复执行该结果。
Facebook PyText
Facebook如何远离这场比赛? 该公司提供了自己的称为PyText的开源NLP框架。 根据Facebook发布的一项研究,PyText将对话模型的准确性提高了10%,并减少了培训时间。
PyText实际上落后于Facebook自己的几种产品,例如Messenger。 因此,与他一起工作将为您的投资组合和毫无疑问地获得的宝贵知识锦上添花。
您可以自己尝试,
从GitHub下载代码 。
Google双工
很难相信您还没有听说过Google Duplex。 这是一个长时间以来在标题中闪现的演示:
由于这是Google产品,因此几乎没有机会将代码迟早发布给所有人。 当然,该演示提出了许多问题:从道德到隐私问题,但是我们稍后会讨论。 现在,请尽情享受近年来ML带来的成就。
2019 NLP趋势
谁能比塞巴斯蒂安·鲁德(Sebastian Ruder)本人更好地了解NLP在2019年的发展方向? 这是他的发现:
- 预先训练的语言投资模型的使用将变得广泛。 没有支持的高级模型将非常罕见。
- 将显示经过预训练的视图,该视图可以编码补充语言模型附件的专业信息。 我们将能够根据任务要求对不同类型的预训练演示文稿进行分组。
- 更多工作将出现在多语言应用程序和多语言模型领域。 特别是,依靠单词的中间语言嵌入,我们将看到深度预训练的中间语言表示形式的出现。
电脑视觉

如今,计算机视觉已成为深度学习领域中最受欢迎的领域。 似乎已经获得了该技术的初步成果,并且我们正处于积极发展的阶段。 无论是图像还是视频,我们都看到了许多可以轻松解决计算机视觉问题的框架和库的出现。
这是我今年可以看到的最佳解决方案列表。
BigGANs出
Ian Goodfellow在2014年设计了GAN,该概念催生了各种各样的应用。 年复一年,我们观察到最初的概念是如何最终确定以用于实际案例的。 但是直到今年一件事都没有改变-计算机生成的图像太容易区分了。 框架中总是出现某种不一致的地方,这使得区别非常明显。
近几个月来,已经朝着这个方向出现了变化,并且随着
BigGAN的
创建 ,这些问题可以一劳永逸地解决。 查看此方法生成的图像:

没有显微镜,很难说出这些图像出了什么问题。 当然,每个人都会自己决定,但是毫无疑问,GAN改变了我们感知数字图像(和视频)的方式。
供参考:这些模型首先在ImageNet数据集上进行训练,然后在JFT-300M上进行训练,以证明这些模型已从一个数据集很好地转移到另一个数据集。 这是GAN邮件列表中
指向页面的
链接,该页面解释了如何可视化和理解GAN。
Fast.ai模型在ImageNet上接受了18分钟的培训
这是一个非常酷的实现。 人们普遍认为,要执行深度学习任务,您将需要TB级的数据和大型计算资源。 从零开始在ImageNet数据上训练模型也是如此。 在Fast.ai上的一些人无法向所有人证明相反之前,我们大多数人都以相同的方式思考。
他们的模型以令人印象深刻的18分钟显示了93%的准确性。 他们使用的硬件
在其博客上进行了详细
描述 ,包括16个公共AWS云实例,每个实例均带有8个NVIDIA V100 GPU。 他们使用fast.ai和PyTorch库构建了算法。
组装的总成本仅为40美元! 杰里米在
这里更详细地描述了他们的
方法和方法 。 这是共同的胜利!
NVIDIA的vid2vid
在过去的五年中,图像处理取得了长足进步,但是视频呢? 从静态帧转换为动态帧的方法比预期的要复杂一些。 您能否从视频中提取一系列帧并预测下一帧会发生什么? 以前已经进行过此类研究,但出版物充其量是含糊的。

NVIDIA决定于今年初[2018-大约 per。],得到了社会的积极评价。 vid2vid的目的是从给定的输入视频派生显示功能,以便创建输出视频,该输出视频以惊人的精度传输输入视频的内容。
您可以在PyTorch上尝试其实现,将其
转到GitHub此处 。
2019年机器视觉趋势
正如我之前提到的,在2019年,我们更有可能看到2018年趋势的发展,而不是新的突破:自动驾驶汽车,面部识别算法,虚拟现实等。 如果您有不同的观点或意见,可以与我不同意,与我们分享,我们在2019年还能期待什么?
在政治家和政府批准之前,无人机问题可能最终在美国获得批准(印度在此问题上远远落后)。 我个人希望在现实世界中进行更多研究。
CVPR和
ICML之类的会议很好地介绍了该领域的最新成就,但是这些项目与现实之间的距离还不是很清楚。
期待已久的“视觉问答”和“视觉对话系统”可能最终面世。 这些系统缺乏泛化能力,但是可以预期,我们很快就会看到集成的多模式方法。
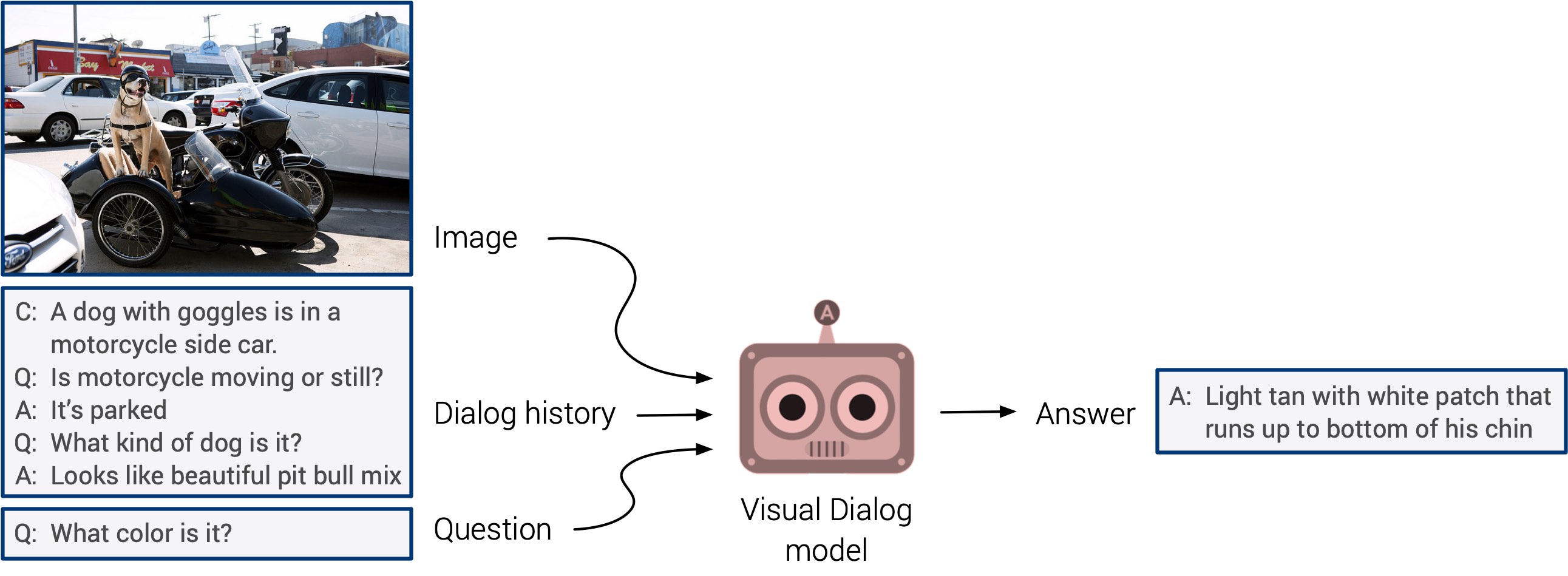
自我训练在今年崭露头角。 我敢打赌,明年它将在更多的研究中得到应用。 这是一个非常酷的方向:直接根据输入数据确定符号,而不是浪费时间手动标记图像。 让我们保持手指交叉!