嗨%habrauser%!
今天,我想向您介绍一个很好的
Moleculer微服务框架。

最初,该框架是用Node.js编写的,但后来以Java,Go,Python和.NET等其他语言出现在端口上,并且很可能在不久的将来
出现其他实现。 大约一年以来,我们已经将它用于多种产品的生产中,很难用言语描述他在使用Seneca和我们的自行车后对我们的幸福程度。 我们开箱即用地提供了我们需要的一切:收集指标,缓存,平衡,容错,选择传输,参数验证,日志记录,简洁的方法声明,多种服务间交互方式,mixin等。 现在按顺序。
引言
实际上,该框架由三个组件组成(实际上,没有,但是您将在下面了解更多信息)。
运输者
负责发现服务和它们之间的通信。 这个接口非常需要您可以实现自己,也可以使用框架本身一部分的现成实现。 包装盒中提供7种传输方式:TCP,Redis,AMQP,MQTT,NATS,NATS Streaming,Kafka。
在这里您可以看到更多。 我们使用Redis传输,但是我们计划从实验状态退出时切换到TCP。
实际上,在编写代码时,我们不会与此组件进行交互。 您只需要知道他是什么。 使用的传输在配置中指定。 因此,要从一种传输方式切换到另一种传输方式,只需更改配置即可。 仅此而已。 像这样:
数据默认为JSON格式。 但是您可以使用任何东西:Avro,MsgPack,Notepack,ProtoBuf,Thrift等。
服务专区
我们在编写微服务时从中继承的类。
这是没有方法的最简单的服务,但是,其他服务会检测到该方法:
服务经纪人
框架的核心。

夸张地说,我们可以说这是运输和服务之间的一层。 当一个服务想要以某种方式与另一个服务交互时,它通过代理进行操作(下面将给出示例)。 代理从事负载平衡(支持几种策略,默认情况下包括自定义策略-循环),同时考虑实时服务,这些服务中的可用方法等。 为此,ServiceBroker在幕后使用了另一个组件-注册表,但是我不会在此赘述,因为我们不需要相识。
拥有经纪人给我们带来了极为方便的事情。 现在,我将尝试解释,但我不得不稍稍退后一步。 在框架的上下文中,存在诸如节点之类的东西。 简单来说,节点是操作系统中的一个进程(例如,当我们在控制台中输入“ node index.js”时会发生什么)。 每个节点都是具有一组一个或多个微服务的ServiceBroker。 是的,您没听错。 我们可以按照自己的意愿建立服务堆栈。 为什么这样方便? 为了进行开发,我们启动了一个节点,在该节点中一次启动所有微服务(每个微服务一个),例如,系统中只有一个进程能够非常轻松地连接hotreload。 在生产中-每个服务实例的单独节点。 好吧,或者混合使用,当一部分服务在一个节点中,一部分在另一节点中,依此类推(尽管我不知道为什么这样做,只是为了了解您也可以这样做)。
这就是我们的index.js的样子 const { resolve } = require('path'); const { ServiceBroker } = require('moleculer'); const config = require('./moleculer.config.js'); const { SERVICES, NODE_ENV, } = process.env; const broker = new ServiceBroker(config); broker.loadServices( resolve(__dirname, 'services'), SERVICES ? `*/@(${SERVICES.split(',').map(i => i.trim()).join('|')}).service.js` : '*/*.service.js', ); broker.start().then(() => { if (NODE_ENV === 'development') { broker.repl(); } });
在没有环境变量的情况下,将加载目录中的所有服务,否则将通过掩码加载。 顺便说一句,broker.repl()是框架的另一个便捷功能。 在开发模式下启动时,我们在控制台中在那里有一个用于调用方法的接口(例如,您将通过微服务中的邮递员通过http进行通信),这在这里更加方便:该接口位于同一控制台中他们在npm开始的地方。
服务间交互
它以三种方式执行:
叫
最常用的。 发出请求,收到响应(或错误)。
如上所述,通话会自动平衡。 我们只增加了所需的服务实例数,框架本身将进行平衡。

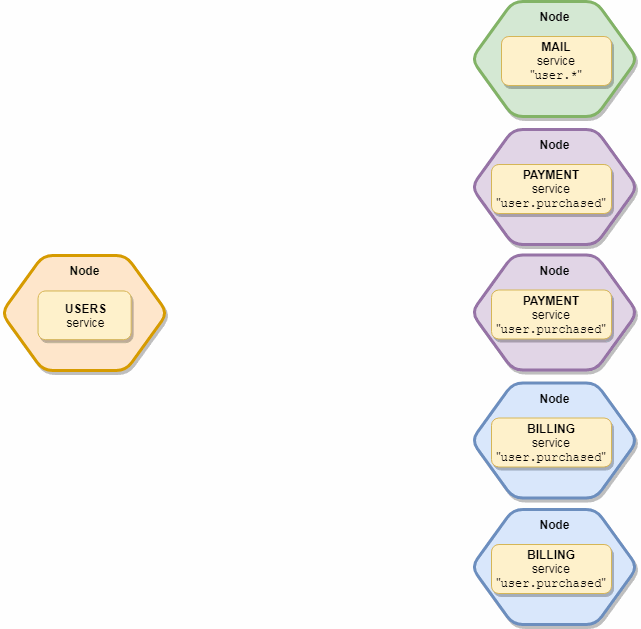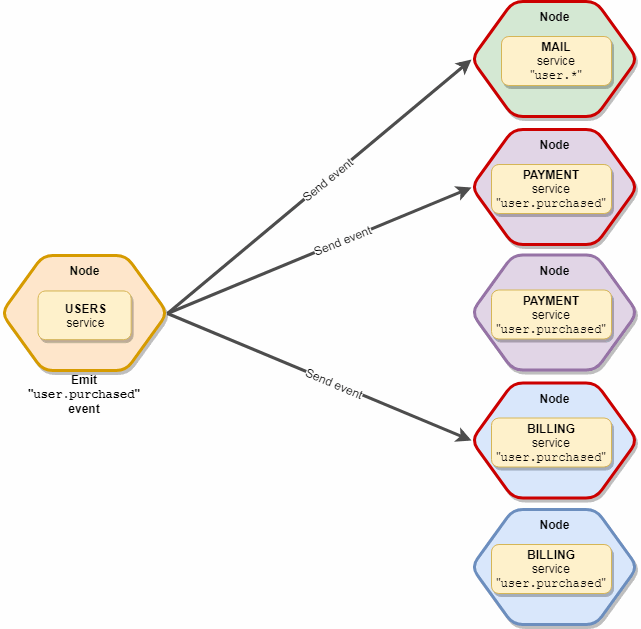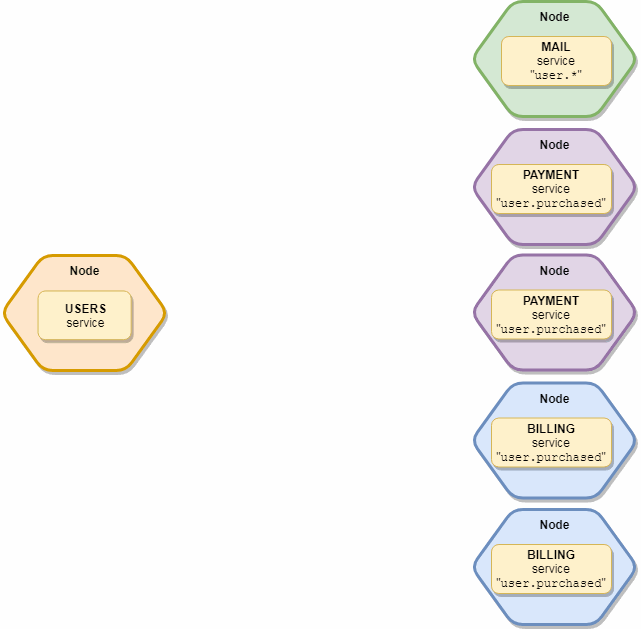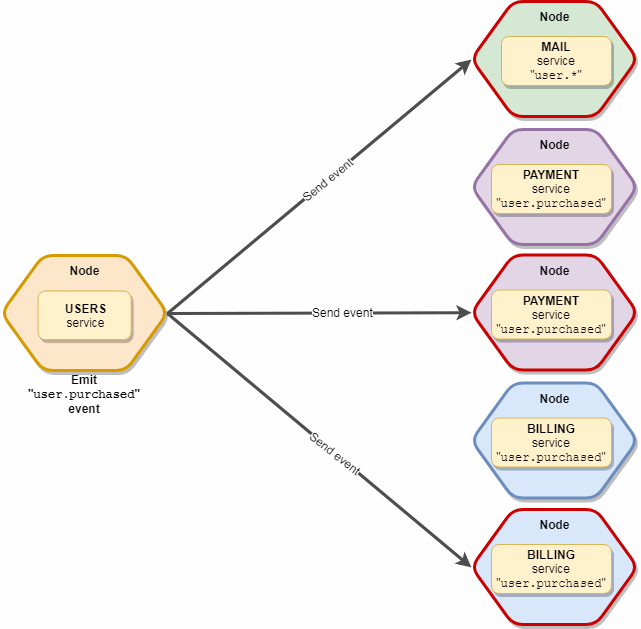
发射
当我们只想通知其他服务某个事件但不需要结果时使用。
其他服务可以订阅此事件,并做出相应的响应。 (可选)第三个参数,您可以显式设置可用于接收此事件的服务。
重要的一点是,该事件将仅接收每种服务类型的一个实例,即 如果我们有10个“邮件”和5个“订阅”服务订阅了此事件,那么实际上只有2个副本将收到它-一个“邮件”和一个“订阅”。 示意图如下所示:
广播的
与发出相同,但没有限制。 所有10个邮件和5个订阅服务都将捕获此事件。
参数验证
默认情况下,
最快验证器用于验证参数,这似乎非常快。 但是,如果您需要更高级的验证,则没有其他方法可以阻止使用其他任何方法,例如使用同一个joi。
当我们编写服务时,我们继承自Service基类,在其中声明带有业务逻辑的方法,但是这些方法是“私有的”,除非我们明确地想要在内部声明它们,否则不能从外部(从另一个服务)调用它们。服务初始化期间的特殊操作部分(在框架上下文中,服务的公共方法称为操作)。
带有验证的方法声明的示例 module.exports = class JobService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'job', actions: { update: { params: { id: { type: 'number', convert: true }, name: { type: 'string', empty: false, optional: true }, data: { type: 'object', optional: true }, }, async handler(ctx) { return this.update(ctx.params); }, }, }, }); } async update({ id, name, data }) {
混合蛋白
例如,用于初始化数据库连接。 避免服务之间的代码重复。
示例mixin初始化与Redis的连接 const Redis = require('ioredis'); module.exports = ({ key = 'redis', options } = {}) => ({ settings: { [key]: options, }, created() { this[key] = new Redis(this.settings[key]); }, async started() { await this[key].connect(); }, stopped() { this[key].disconnect(); }, });
在服务中使用mixin const { Service, Errors } = require('moleculer'); const redis = require('../../mixins/redis'); const server = require('../../mixins/server'); const router = require('./router'); const { REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, } = process.env; const redisOpts = { host: REDIS_HOST, port: REDIS_PORT, password: REDIS_PASSWORD, lazyConnect: true, }; module.exports = class AuthService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'auth', mixins: [redis({ options: redisOpts }), server({ router })], }); } }
快取
方法调用(动作)可以通过几种方式进行缓存:LRU,内存,Redis。 (可选)您可以指定将缓存哪些键调用(默认情况下,对象哈希用作缓存键)以及使用哪个TTL。
缓存方法声明示例 module.exports = class InventoryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'inventory', actions: { getInventory: { params: { steamId: { type: 'string', pattern: /^76\d{15}$/ }, appId: { type: 'number', integer: true }, contextId: { type: 'number', integer: true }, }, cache: { keys: ['steamId', 'appId', 'contextId'], ttl: 15, }, async handler(ctx) { return true; }, }, }, }); }
缓存方法是通过ServiceBroker配置设置的。
记录中
但是,这里的一切也非常简单。 有一个相当不错的内置记录器,可以写入控制台,可以指定自定义格式。 没有什么可以阻止窃取任何其他流行的记录器了,无论是温斯顿还是本扬。 详细的手册在
文档中 。 就个人而言,我们使用内置的记录器,将垃圾邮件进入JSON控制台的几行代码的自定义格式化程序在产品中截断,然后使用docker日志驱动程序进入Graylog。
指标
如果需要,您可以收集每种方法的指标,并使用zipkin进行跟踪。 这
是可用的出口商
的完整列表。 当前有五个:Zipkin,Jaeger,Prometheus,Elastic和Console。 声明方法(动作)时,它与缓存一样配置。
可以在Github中的
此链接上查看使用
elastic-apm-node模块的elasticsearch + kibana捆绑包的可视化示例。
当然,最简单的方法是使用console选项。 看起来像这样:

容错能力
该框架具有内置的断路器,可通过ServiceBroker设置进行控制。 如果任何服务失败,并且这些失败的次数超过特定阈值,那么它将被标记为不正常,对它的请求将受到严格限制,直到不再出错为止。
另外,如果我们假设该方法可能会失败,例如,发送缓存的数据或存根,则每个方法(操作)还可以分别进行调整。
结论
对我来说,这个框架的引入使人呼吸新鲜,节省了大量的代码(除了微服务架构是一个大的事实)和循环,使编写下一个微服务变得简单而透明。 它没有多余的内容,它既简单又非常灵活,您可以在阅读文档后一两个小时内编写第一个服务。 如果这些材料对您有用,我将很高兴,并且在您的下一个项目中,您将像我们一样尝试这个奇迹(并且从未后悔)。 对所有人都好!
另外,如果您对此框架感兴趣,请加入Telegram中的聊天室-
@moleculerchat