
在“科学家”时代,有很多高手,其中之一涉及竞争性机器学习。 Kaggle的成功是否真的显示出专家解决典型工作任务的能力? Arseny
arseny_info (研发团队负责人@
WANNABY ,
Kaggle大师 ,稍后在
A. )和Arthur
n01z3 (
X5零售集团X5零售集团的计算机视觉负责人,
Kaggle Grandmaster ,后来在
N. )将单足动物的水平提升到一个新的水平:他们在聊天室里带了麦克风,并
在会议上进行了
公开讨论 ,并以此为依据。
指标,内核,页首横幅
答:我想从一个预期的论点开始,即Kaggle在典型的科学家约会工作中没有教授最重要的事情-问题的陈述。 正确设置的任务已经包含了解决方案的一半,而通常这一半是最困难的,编写一些模型并对其进行训练要容易得多。 Kaggle提供了理想世界中的一项任务-数据已准备好,指标已准备好,可以接受并可以训练。
出乎意料的是,即使这样,也会出现问题。 当“ kagglers”看到一个陌生的/难以理解的指标时,会感到困惑,这并不难发现很多例子。
N:是的,这就是kaggle的本质。 组织者认为,确定任务的形式,收集数据集并确定度量标准。 但是,如果一个人具有批判性思维的开端,那么他会想到的第一件事就是为什么他们认为所选指标或建议的目标是最佳的。
强大的参与者通常会自己重新定义任务并提出更好的目标。
当他们弄清楚度量标准,确定目标并收集数据时,kagglers最擅长的是优化度量标准。 在每次比赛之后,客户都可以充满信心地相信参加者以最快的速度展示了理想算法的“天花板”。 为此,kaggler尝试了许多不同的方法和想法,并通过快速迭代对其进行了验证。
这种方法直接转换为成功完成实际任务的工作。 此外,经验丰富的骗子可以立即立即直观地或从过去的经验中选择一系列值得首先获得最大利润的想法。 在这里,kaggle社区的整个武器库都可以救援:文章,松弛,论坛,内核。
 答:
答:您提到了“内核”,我对此有另外的投诉。 许多竞争已经变成了内核驱动的开发。 我不会关注因成功启动公共脚本而获得金牌的简陋情况。 但是,即使在深度学习竞赛中,您也几乎可以不用编写代码就可以获得某种奖章。 您可以做出一些公共决策,尤其是不了解某些参数的扭曲,在排行榜上进行自我测试,取平均结果并获得良好的指标。
以前,即使在“图片”竞赛中取得了一定的成功(例如,获得一枚铜牌,即获得最终评分的前10%),也表明一个人有能力-您必须至少从头到尾编写一条正常的管道,防止重大错误。 现在,这些成功已被贬值:Kaggle正在用强大的力量和主要力量来推广其核心平台,这降低了进入门槛,并使您能够以某种方式进行试验而没有意识到是什么。
 N:
N:铜牌从未被引用过。 这是“我在那里发布了一些东西,并且从中学到了东西”的水平。 而且还不错。
由于内核和其中存在GPU而降低了输入级别,这会产生竞争,并提高总体知识水平。 如果一年前可以使用香草Unet来获得黄金,那么现在如果没有5种以上的修改和技巧就无法做到。 这些技巧不仅适用于Kaggle,而且适用范围更广。 例如,在
高空飞翔的Inria,我们来自ods.ai的家伙们站了起来,仅仅用Kaggle开发的强大分段管道就展示了最先进的技术。 这表明了这种方法在实际工作中的适用性。
 答:
答:问题在于,
在实际任务中没有排行榜 。 通常,没有一个数字可以表明一切都出错了,或者相反,一切都很好。 通常有几个数字,它们彼此矛盾,将它们链接到一个系统中是另一个挑战。
N:但是指标在某种程度上很重要。 它们显示了该算法的客观性能。 如果没有度量标准超过某个可用阈值的算法,就不可能创建基于ML的服务。
答:但是,只有当它们诚实地反映出产品的状态时,情况并非总是如此。 碰巧您需要将指标拖到某个卫生最小值,并且
“技术”指标的进一步改进不再对应于产品改进 (用户不会注意到这些+0.01 IoU),该指标与用户感觉之间的相关性会丢失。
另外,增加度量标准的经典kaggle方法不适用于正常工作。 无需搜索“面孔”,无需复制标记并通过文件的哈希找到正确的答案。

可靠的验证和大胆模型的整合
N:Kaggle会教您正确验证,包括由于面部的存在。 您需要非常清楚排行榜上的速度是如何提高的。 如果我们谈论的是实际工作,也
有必要建立一个具有代表性的本地验证 ,以反映排行榜的私有部分或生产中数据的分布。
Kagglers经常被怪的另一件事是合奏。 Kaggle解决方案通常由一堆模型组成,并且不可能拖入产品中。 但是,他们忘记了,如果没有强大的单一模型,就不可能提供强大的解决方案。 为了赢得胜利,您不仅需要整体,而且还需要各种强大的单一模型的整体。
“将所有内容连续混合”的方法永远不会得到令人满意的结果。 答:
答:Kaggle聚会和生产环境中的“简单单一模型”的概念可能大不相同。 在竞赛的框架内,这将是一种经过5/10倍训练,带有扩展编码器的架构,您可以及时预期测试时间的增加。 按照竞争标准,这是一个非常简单的解决方案。
但是生产通常
需要轻松得多几个数量级的解决方案 ,尤其是在移动应用程序或物联网方面。 例如,在我的情况下,Kaggle模型通常占用100兆以上的字节,而在该模型的工作中,通常甚至不考虑超过几兆字节的数据。 对推断率的要求也有类似的差距。
N:但是,如果科学家知道如何训练一个沉重的网格,那么所有相同的技术也都适用于训练轻型模型。 初步近似,您可以轻松获得类似网格物体或相同体系结构的移动版本。 规模量化和修剪超出了Kagglers的能力-毫无疑问,这里。 但是这些已经是非常具体的技能,远远不是生产中急需的技能。
但是实际问题中更常见的情况是,有一个很小的
(如您的裤子)标记的数据集,或者是大多数未分配的数据,或者是连续不断的新数据流。 在这里,焊接大型而准确的整体的能力非常适合。 使用它,您可以进行伪变暗或蒸馏以训练轻量模型。 以这种方式增加数据集可确保改善任何模型的性能。
答:伪轻描淡写是有用的,但在比赛中它并不能过上美好的生活-仅仅是因为无法调整数据大小。 使用伪调光获得的数据尽管改进了度量标准,但不如手动重新标记丢失的数据有用。
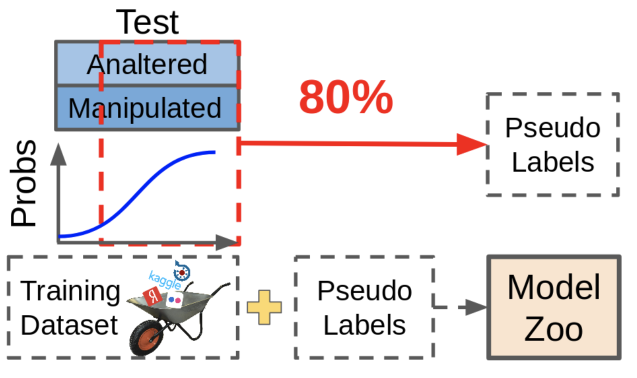
什么是假涂抹? 我们采用现有模型,查看它们在何处给出可靠的预测,然后将这些样本与预测一起放入我们的数据集中。 在这种情况下,模型难以处理的样本仍未标记,因为 这些预测现在还不够好。 恶性循环!
实际上,查找导致网络产生不确定预测的样本并调整其大小会更加有用。 它需要大量的体力劳动,但效果值得。
关于代码和团队合作的美
答:另一个问题是代码质量和开发文化。 Kaggle不仅不教您如何编写代码,而且还提供了许多不良示例。 大多数内核是结构不良,不可读且效率低下的代码,因此会被无意识地复制。 一些流行的Kaggle人物甚至练习将其代码上传到Google云端硬盘而不是存储库中。

人们擅长于无监督学习。 如果您经常查看错误的代码,则可以习惯这种情况。 对于初学者来说,这尤其危险,因为对于Kaggle来说,这是很多危险。
N:我同意,代码的质量是问题的关键。 但是,我也遇到了写非常有价值的管道的人,这些管道可以重用于其他任务。 但这是一个例外:在激烈的争夺中,牺牲了代码的质量来支持快速检查新想法,尤其是在比赛快要结束时。
但是Kaggle教团队合作。 没有什么能像一个共同的事业和一个可以理解的共同目标那样团结人们。 您可以尝试与一群不同的人竞争,参与其中并发展软技能。
 答:
答:Kaggle风格的团队也非常不同。 如果确实通过角色,建设性的互动将任务进行某种分离,并且每个人都做出贡献,那是很好的。 不过,每个人都在自己的大球上挣扎的团队,在比赛的最后几天,所有这些都疯狂地混合在一起,也足够了,而且这也没有教给任何东西-真正的软件开发(包括数据科学)很长时间没有做。
总结
让我们总结一下。
毫无疑问,参加比赛会带来可用于日常工作的额外奖励:首先,它是一种快速迭代的能力,可以在指标框架内将所有数据从数据中挤出,并且毫不犹豫地使用最新技术。
另一方面,滥用Kaggle方法通常会导致无法读取的代码欠佳,工作优先级可疑,并带来一些麻烦。
但是,科学家知道的任何日期,要成功创建一个集成体,您都需要组合多种模型。 因此,在一个团队中
,值得将具有不同技能的人组合在一起 ,并且一两个经验丰富的Kagglers对几乎所有团队都是有用的。