当我们选择一种处理大数据的工具时,我们考虑了不同的选择-专有和开源。 我们评估了技术的快速适应,可访问性和灵活性的可能性。 包括版本之间的迁移。 结果,我们选择了最符合我们要求的Greenplum开源解决方案,但需要解决一个重要问题。

事实是Greenplum数据库文件版本4和5彼此不兼容,因此不可能从一个版本简单升级到另一个版本。 数据迁移只能通过上载和下载数据来完成。 在本文中,我将讨论此迁移的可能选项。
评估迁移选项
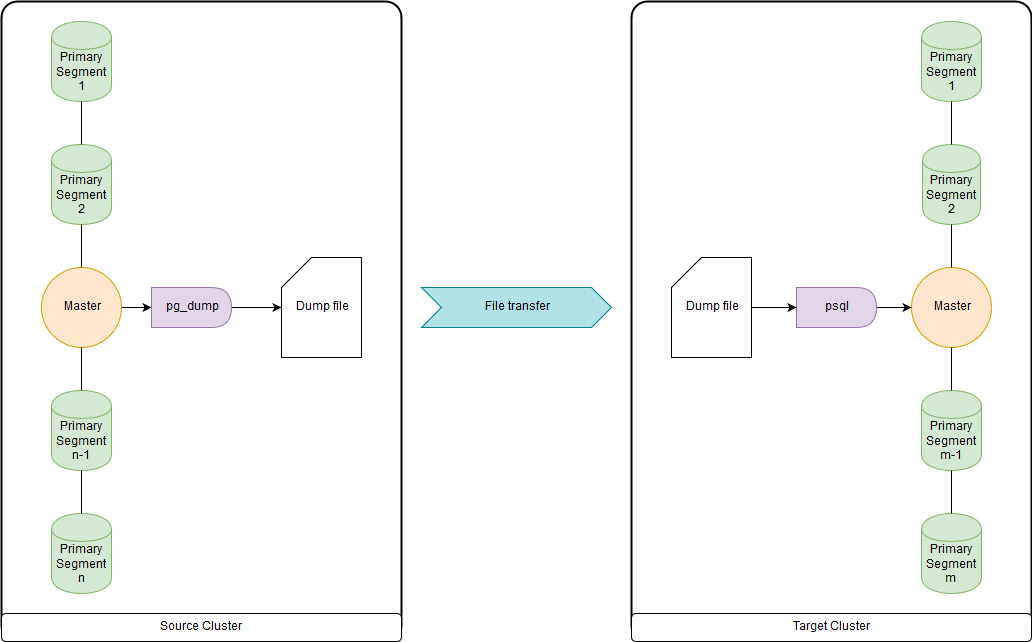
pg_dump和psql(或pg_restore)
当达到数十兆字节时,这太慢了,因为所有数据都是通过主节点上载和下载的。 但是足够快,可以迁移DDL和小型表。 您可以将两者上传到文件,并通过源集群和目标集群上的管道同时运行pg_dump和psql。 pg_dump只需上传到包含DDL命令和COPY数据命令的单个文件中。 可以方便地处理获得的数据,如下所示。
gptransfer
需要版本Greenplum 4.2或更高版本。 源群集和目标群集必须同时工作。 为开源版本迁移大型数据表的最快方法。 但是由于开销大,这种方法在传输空表和小表时非常慢。
gptransfer使用pg_dump传输DDL,使用gpfdist传输数据。 目标群集上的主要段的数量必须不少于源群集上的主机段。 在创建“沙箱”群集时,要考虑是否要将主要群集中的数据传输到它们,并计划使用gptransfer实用程序,这一点很重要。 即使分段主机很少,您也可以在每个分段主机上部署所需数量的分段。 目标群集上的段数可能少于源群集上的段数,但这
将不利地影响数据传输速度。 在群集之间,必须配置证书的ssh身份验证。
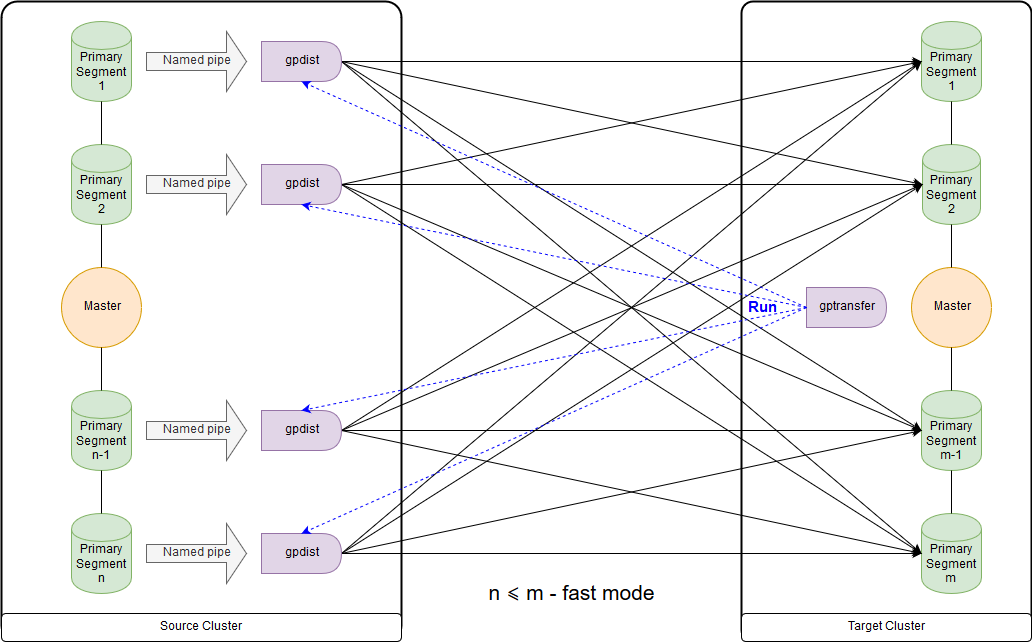
当目标群集上的段数大于或等于源群集上的段数时,这是用于快速模式的方案。 实用程序本身的启动显示在接收器群集的主节点上的图中。 在这种模式下,将在源群集上创建一个外部写表,该表将每个段上的数据写到命名管道。 执行命令INSERT INTO writable_external_table SELECT * FROM source_table。 gpfdist读取命名管道中的数据。 还在目标群集上创建了一个外部表,仅供读取。 该表指示gpfdist通过
同名协议提供的数据。 执行INSERT INTO target_table SELECT * FROM external_gpfdist_table命令。 数据自动在目标群集的各段之间重新分配。
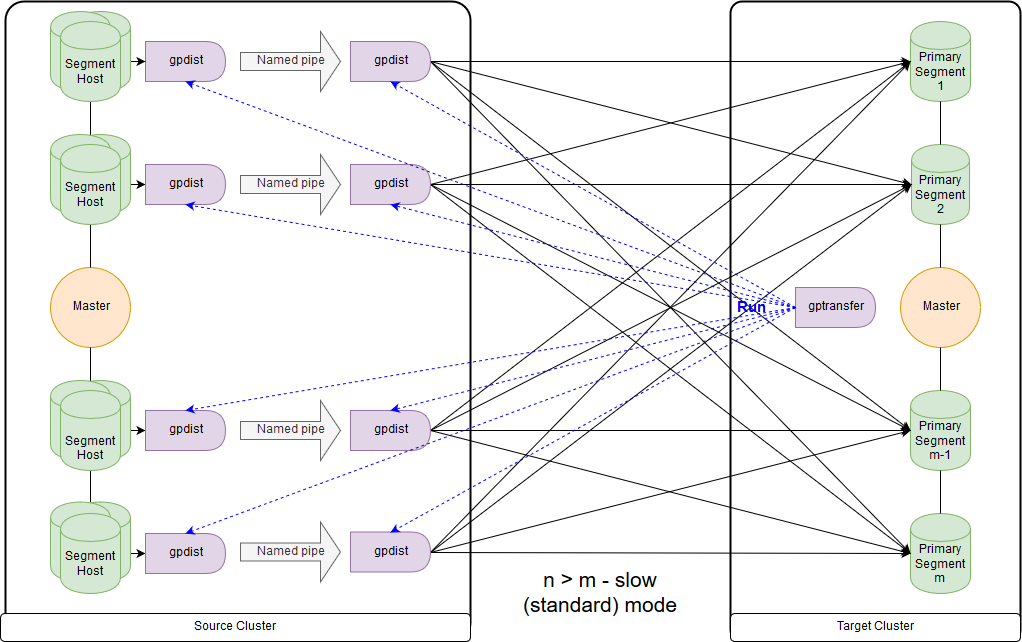
这是慢速模式的方案,或者是gptransfer自己给出的标准模式的方案。 主要区别在于,在源群集的每个分段主机上,都会为该分段主机的所有分段启动一个gpfdist对。 外部记录表是指gpfdist充当数据接收器。 此外,如果在外部表的LOCATION参数中指示要写入的多个值,则在写入数据时,段会被gpfdist平均分配。 主机段上gpfdist之间的数据通过命名管道传递。 因此,数据传输速度较低,但是与仅通过主节点传输数据时相比,它的传输速度仍然更快。
将数据从Greenplum 4迁移到Greenplum 5时,必须在目标群集的主节点上运行gptransfer。 如果在源集群上运行gptransfer,则会得到
pg_catalog.gp_segment_configuration表中缺少
san_mounts字段的错误:
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
您还需要检查GPHOME变量,以便它们在源群集和目标群集之间匹配。 否则,我们将收到一个相当奇怪的
错误 (当源和目标具有不同的GPHOME路径时,gptransfer实用程序将失败)。
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
您可以简单地创建相应的符号链接,并在启动gptransfer的会话中覆盖GPHOME变量。
在目标群集上启动gptransfer时,选项“ --source-map-file”应指向一个文件,其中包含主机列表及其IP地址以及源群集的主要网段。 例如:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
使用选项“ --full”,不仅可以传输表,还可以传输整个数据库,但是,不应在目标群集上创建用户数据库。 您还应该记住,移动外部表时由于语法更改而存在问题。
让我们评估一下额外的开销,例如,使用gptarnsfer复制10个空表(表从big_db.public.test_table_2到big_db.public.test_table_11):
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
结果,传输10张空表大约需要16秒(14:40-15:02),即一张表-1.6秒。 在本例中,使用pg_dump和psql可以下载大约100 MB的数据。
gp_dump和gp_restore
作为一种选择:由于已声明弃用了gp_dump和gp_restore,因此请在gpcrondump和gpdbrestore上使用附加组件。 尽管gpcrondump和gpdbrestore本身在此过程中使用gp_dump和gp_restore。 这是最通用的方法,但不是最快的方法。 使用gp_dump创建的备份文件在主节点上代表一组DDL命令,在主要段上,主要是COPY命令和数据集。 适用于无法同时运行目标群集和源群集的情况。 在Greenplum的旧版本和新版本中都有:
gp_dump和
gp_restore 。
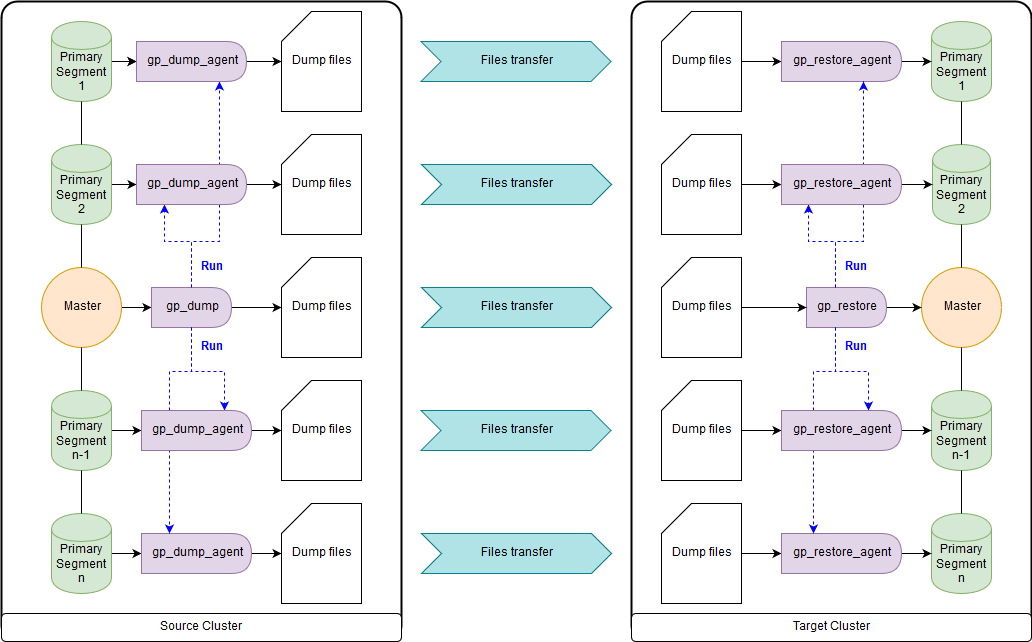
gpbackup和gprestore实用程序
创建以替代gp_dump和gp_restore。 对于他们的工作,需要Greenplum版本最低为4.3.17(
const MINIMUM_GPDB4_VERSION =“ 4.3.17” )。 操作方案类似于gpbackup和gprestore,但是工作速度要快得多。 获取大型数据库的DDL命令的最快方法。 默认情况下,它传输全局对象,要进行恢复,您需要指定“ gprestore --with-globals”。 可选参数“ --jobs”可以设置创建备份时的作业数(以及与数据库的会话)。 由于创建了多个会话,因此在接收到所有锁之前确保数据的一致性非常重要。 还有一个有用的选项“ --with-stats”,它允许您传输有关用于构建执行计划的对象的统计信息。 更多信息
在这里 。
gpcopy实用程序
为了复制数据库,有一个实用程序gpcopy-gptansfer的替代品。 但它仅包含在Pivotal的Greenplum专有版本中,从4.3.26开始-在开源版本中
此实用程序不提供 。 在源集群上工作时,将执行命令COPY source_table TO PROGRAM'gpcopy_helper ...'ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS。 在接收群集端,创建一个临时外部表CREATE EXTERNAL WEB TEMP TABLE external_temp_table(LIKE target_table)EXECUTE'... gpcopy_helper –listen ...',并执行INSERT INTO target_table SELECT * FROM external_temp_table命令。 结果,在目标群集的每个段上都会启动带有–listen参数的gpcopy_helper,它们将从源群集的段中接收来自gpcopy_helper的数据。 由于这种数据传输方案以及压缩,因此传输速度要高得多。 在群集之间,还必须配置证书的ssh身份验证。 我还想指出,对于源群集和目标群集位于同一服务器上的情况,gpcopy有一个方便的选项“ --truncate-source-after”(和“ --validate”)。
数据传输策略
为了确定传输策略,我们需要确定对我们而言更重要的是:快速传输数据,但需要更多的人工,可靠性可能较低(gpbackup,gptransfer或其组合),或者需要较少的人工,但传输速度较慢(gpbackup或gptransfer而不合并)。
最快的数据传输方式-当有源群集和目标群集时-以下内容:
- 使用gpbackup-仅元数据获取DDL,使用psql转换并通过管道加载
- 删除索引
- 使用gptransfer传输大小为100 MB或更大的表
- 使用pg_dump传输大小小于100 MB的表| 如第一段中的psql
- 创建回删除的索引
事实证明,这种方法比gp_dump和gp_restore快至少2倍。 替代方法:使用gptransfer –full,gpbackup和gprestore或gp_dump和gp_restore传输所有数据库。
表大小可以通过以下查询获得:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
必要的转换
Greenplum版本4和5中的备份文件也不完全兼容。 因此,在Greenplum 5中,由于语法的更改,CREATE EXTERNAL TABLE和COPY命令没有INTO ERROR TABLE参数,因此您需要将SET gp_ignore_error_table参数设置为true,以使备份还原不会失败。 设置好参数后,我们会收到一条警告。
此外,第五版引入了与外部pxf表进行交互的不同协议,并且要使用该协议,您需要更改LOCATION参数并配置pxf服务。
还值得注意的是,在主节点和每个主段上的gp_dump和gp_restore备份文件中,SET gp_strict_xml_parse参数都设置为false。 Greenplum 5中没有这样的参数,因此,我们收到一条错误消息。
如果将gphdfs协议用于外部表,则需要在备份文件中'gphdfs://'行中在LOCATION参数中为外部表检查源列表。 例如,应该只有“ gphdfs://hadoop.local:8020”。 如果还有其他行,则需要类似地将它们添加到主节点上的替换脚本中。
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
我们替换主节点(以gp_dump数据文件为例):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
在最新版本中,HdfsTextSimple配置文件名称被
声明为弃用 ,新名称为hdfs:text。
总结
在本文之外,仍然需要显式转换为文本(
隐式文本转换 ),这是一种新的
资源组集群资源管理机制,该机制取代了
GPORCA优化器Resource Queues,Greenplum 5中默认包含该机制,与客户端
无关 。
我期待Greenplum的第六版发布,该版本计划于2019年春季发布:与PostgreSQL 9.4的兼容性级别,全文搜索,GIN索引支持,范围类型,JSONB,zStd压缩。 此外,Greenplum 7的初步计划也广为人知:与PostgreSQL最低9.6的兼容级别,行级安全性,自动主故障转移。 开发人员还承诺可以使用数据库升级实用程序在主要版本之间进行更新,因此使用起来会更加容易。
本文由Rostelecom数据管理团队编写