机器学习的主题有多复杂? 如果您擅长数学,但是有关机器学习的知识往往为零,那么您在
Kaggle平台上进行的激烈竞争中能走多远?

关于网站和比赛
Kaggle是一个对ML感兴趣的社区(从初学者到很酷的专业人士)和竞赛的场所(通常带有丰厚的奖池)。
为了立即浸入ML的所有魅力,我决定立即选择一场严肃的比赛。 这样才可用:《
两个西格玛:使用新闻来预测股票走势》 。 简而言之,竞赛的实质是根据资产的状态和与该资产有关的新闻来预测各个公司的股价。 比赛的奖金为100,000美元,奖金将分配给前7名。
比赛之所以特别,有两个原因:
- 这是仅限内核的竞赛:您只能在Kaggle内核云中训练模型;
- 最终的席位分配将在决策完成后的六个月内公布; 在此期间,决策将预测当前日期的价格。
关于任务
根据条件,我们必须预测信心
因为资产的回报会增加。 资产收益被视为相对于整个市场收益。 目标指标是自定义的-不是更熟悉的
RMSE或
MAE ,而是
Sharpe比率 ,在这种情况下,该
比率被认为如下:
在哪里
,
-在10天的时间段内,第t天相对于市场的资产收益i,
-一个布尔变量,指示第t天的评估中是否包括第i种资产,
-平均值
,
-标准偏差
。
夏普比率是风险调整后的回报,系数的值表明交易者的有效性:
- 小于1:性能不佳
- 1-2:中等效率
- 2-3:出色的表现,
- 超过3:完美。
市场走势数据- 时间 (datetime64 [ns,UTC])-当前时间(在UTC 22:00的所有行中的行情数据中)
- assetCode (对象)-资产标识符
- assetName (类别)-用于与新闻数据通信的资产组的标识符
- Universe (float64)-一个布尔值,指示在计算得分时是否将这一资产考虑在内
- 交易量(float64)-每日交易量
- 收盘价(float64)-当天收盘价
- 开盘价 (float64)-当天的开盘价
- returnClosePrevRaw1 (float64)-从关闭到前一天的收益
- returnOpenPrevRaw1 (float64)-前一天从开盘到开盘的获利能力
- returnClosePrevMktres1 (float64)-前一天从收盘到收盘的获利能力,相对于整个市场的波动进行了调整
- returnOpenPrevMktres1 (float64)-前一天从开盘到开盘的获利能力,相对于整个市场的波动进行了调整
- returnClosePrevRaw10 (float64)-前10天从关闭到关闭的收益
- returnOpenPrevRaw10 (float64)-前10天从开盘到开盘的获利能力
- returnClosePrevMktres10 (float64)-前10天从收盘到收盘的收益,相对于整个市场的波动进行了调整
- returnOpenPrevMktres10 (float64)-前10天从开盘到开盘的收益率,相对于整个市场的波动进行了调整
- returnOpenNextMktres10 (float64)-未来10天从开盘到开盘的收益率,已针对整个市场的波动进行了调整。 我们将预测该值。
新闻数据- 时间 (datetime64 [ns,UTC])-UTC数据可用性中的时间
- sourceTimestamp (datetime64 [ns,UTC])-UTC发布新闻中的时间
- firstCreated (datetime64 [ns,UTC])-数据的第一个版本的UTC时间
- sourceId (对象)-记录标识符
- 标题 (对象)-标题
- 紧急 (int8)-新闻类型(1:警告,3:文章)
- takeSequence (int16)-参数不是很清楚,以某种顺序编号
- 提供者 (类别)-新闻提供者标识符
- 主题 (类别)-新闻主题代码列表(可以是地理标志,事件,行业等)
- 观众 (类别)-观众代码新闻列表
- bodySize (int32)-新闻正文中的字符数
- companyCount (int8)-新闻中明确提及的公司数量
- headlineTag (对象)-汤森路透的某个标题标签
- marketCommentary (布尔)-该新闻与一般市场状况有关的迹象
- 句话 (Count16)-新闻中的要约数量
- wordCount (int32)-新闻中的单词和标点符号的数量
- assetCodes (类别)-新闻中提到的资产列表
- assetName (类别)-资产组代码
- firstMentionSentence (int16)-首先提及资产的句子:
- 相关性 (float32)-从0到1的数字,显示与资产相关的新闻的相关性
- sentimentClass (int8)-新闻语调类
- sentimentNegative (float32)-音调为负的概率
- sentimentNeutral (float32)-音调为中性的可能性
- sentimentPositive (float32)-密钥为正的概率
- sentimentWordCount (int32)-文本中与资产相关的单词数
- noveltyCount12H (int16)-12小时内的“新颖”新闻,相对于有关该资产的先前新闻进行计算
- noveltyCount24H (int16)-相同,在24小时内
- noveltyCount3D (int16)-同样,在3天内
- noveltyCount5D (int16)-同样,在5天内
- noveltyCount7D (int16)-相同,在7天内
- volumeCounts12H (int16)-12小时内有关此资产的新闻数量
- volumeCounts24H (int16)-相同,在24小时内
- volumeCounts3D (int16)-相同,在3天内
- volumeCounts5D (int16)-相同,持续5天
- volumeCounts7D (int16)-同样,在7天内
该任务本质上是二进制分类的任务,也就是说,我们预测二进制符号将产生增加(1类)或减少(0类)的作用。
关于工具
Kaggle Kernels是一个支持协作的云计算平台。 支持以下类型的内核:
- Python脚本
- R脚本
- Jupyter笔记本
- RMarkdown
每个内核都在其docker容器中运行。 容器中安装了许多软件包,可在
此处找到python的列表。 技术规格如下:
- CPU:4核
- 内存:17 GB,
- 驱动器:5 GB永久性和16 GB临时性,
- 最长脚本运行时间:9小时(比赛开始时为6小时)。
内核中也提供GPU,但是在本次比赛中禁止使用GPU。
Keras是运行在
TensorFlow ,
CNTK或
Theano之上的高级神经网络框架。 这是一个非常方便且易于理解的API,并且可以使用后端API添加网络拓扑,丢失功能等。
Scikit-learn是一个大型的机器学习算法库。 数据预处理和数据分析算法的有用来源,可与更专业的框架一起使用。
模型验证
在提交模型进行评估之前,您需要以某种方式在本地检查其效果-即,提出一种进行本地验证的方法。 我尝试了以下方法:
- 交叉验证与简单按比例划分为训练/测试集;
- 夏普比与 ROC AUC的局部计算。
结果,最奇怪的是,最接近竞争评估的结果显示了比例分区(根据经验选择分区0.85 / 0.15)和AUC的组合。 交叉验证可能不太适合,因为在培训数据的早期阶段和评估阶段,市场行为存在很大差异。 为什么AUC的表现优于夏普比率-我完全不能说。
第一次尝试
由于任务是预测时间序列,因此第一个方法经过了经典解决方案的测试-递归神经网络(
RNN ),或者说是其变体
LSTM和
GRU 。
递归网络的主要原理是,对于每个输出值,不是输入一个样本,而是输入整个序列。 由此得出:
- 我们需要对初始数据进行一些预处理-为每个资产生成这些长度为t天的序列。
- 如果前t天没有数据,则基于递归网络的模型将无法预测输出值。
我每天从t开始生成序列,因此对于相当大的t(从20开始),整个训练样本集不再适合内存。 由于Keras可以将生成器用作训练和预测的输入和输出数据集,因此使用生成器解决了该问题。
数据的最初准备工作是尽可能幼稚的:我们获取整个市场数据,并添加几个功能(星期几,月份,一年中的星期几),而我们完全不涉及新闻数据。
第一个模型使用t = 10,看起来像这样:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
该模型没有任何不足之处,得分接近零(甚至略有减分)。
时间卷积网络
用于时间序列预测的更现代的神经网络解决方案是TCN。 这种拓扑的本质非常简单:我们采用一维卷积网络并将其应用于长度为t的序列。 更高级的选项使用具有不同膨胀的几个卷积层。
从此处复制了TCN实现(有时是在概念级别)(TCN堆栈可视化来自
Wavenet文章 )。
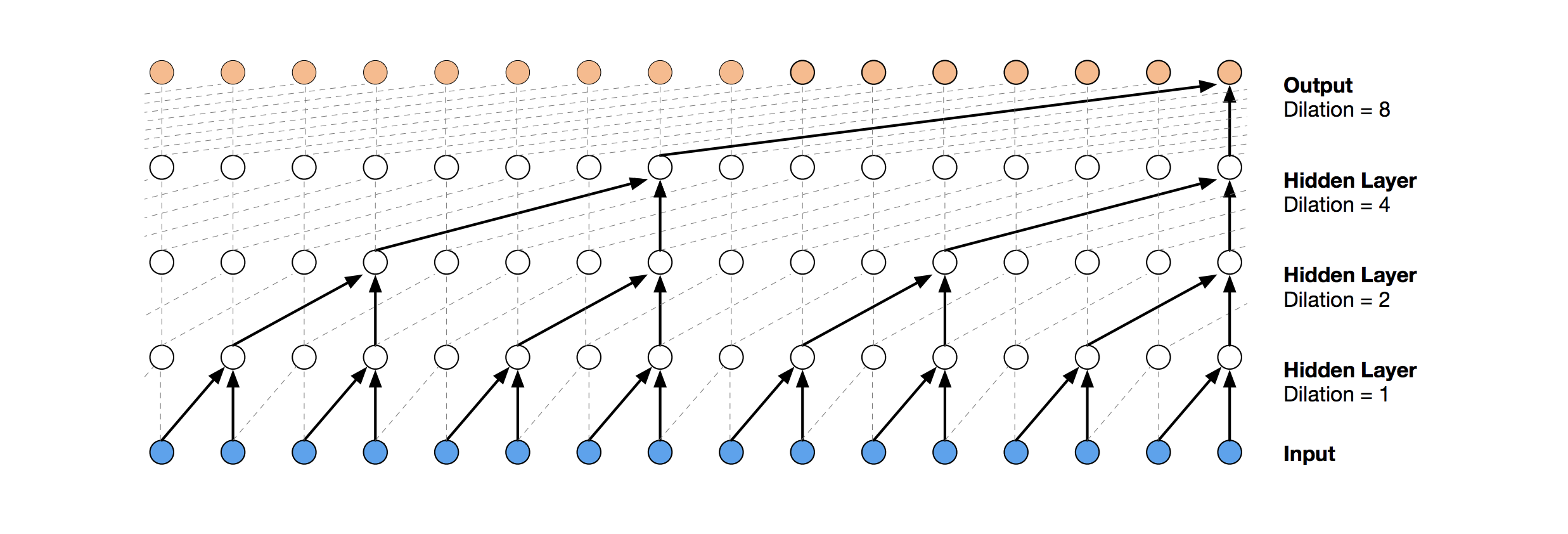
第一个相对成功的解决方案是该模型,该模型在TCN之上包括一个GRU层:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
这样的模型产生得分= 0.27668。 稍加调整(TCN过滤器的数量,批量大小)并将t增加到100,我们已经得到0.41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
接下来,我们添加标准化和辍学:
代号 batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
应用此模型,包括在早期步骤中(t = 1),我们得到的分数= 0.53578。
梯度提升机
在这个阶段,这些想法结束了,我决定一开始就要做一些需要做的事情:看看其他参与者的公共决定。 大多数好的解决方案根本不使用神经网络,而是选择GBM。
梯度提升是一种ML方法,在输出时,我们得到了一组简单的模型(最常见的是决策树)。 由于存在大量此类简单模型,因此优化了损失函数。 例如,您可以
在此处阅读有关梯度增强的更多信息。
在GBM的实现中,使用了
lightgbm-一种Microsoft相当知名的框架。
从这里获取的模型和数据预处理得到的分数约为0.64:
代号 def prepare_data(marketdf, newsdf):
这里的预处理已经包括新闻数据,并将它们与市场数据结合在一起(但是,天真地做,只考虑新闻中提到的所有资产代码之一)。 我将此预处理选项作为所有后续决策的基础。
通过添加一个小功能(firstMentionSentence,marketCommentary,sentimentClass),并用
ROC AUC代替该指标,我们得到0.65389的分数。
合奏
下一个成功的决定是使用由神经网络模型和GBM组成的集合(尽管“集合”是两个模型的大名)。 通过对两个模型的预测取平均值来获得结果预测,从而应用软投票机制。 这项决定使分数为0.66879。
探索性数据分析和特征工程
开始的另一件事是EDA。 阅读了理解功能之间的相关性很重要之后,我们构建了这样一张图片(本节中的图片都是可单击的):
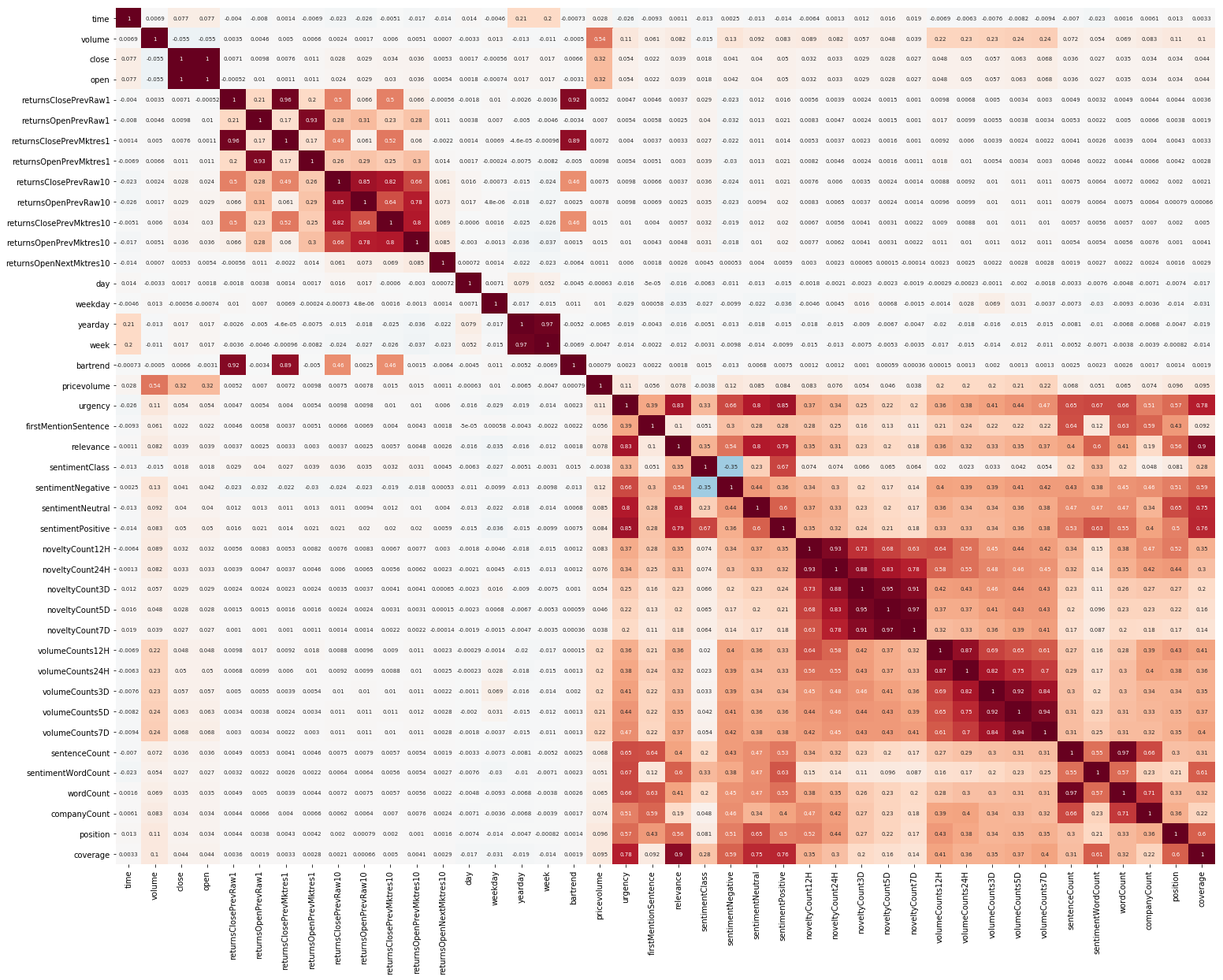
在这里可以清楚地看到,市场和新闻数据之间的相关性很高,但是,至少收益率的值至少与目标值相关。 由于数据表示时间序列,因此还应查看目标值的自相关:
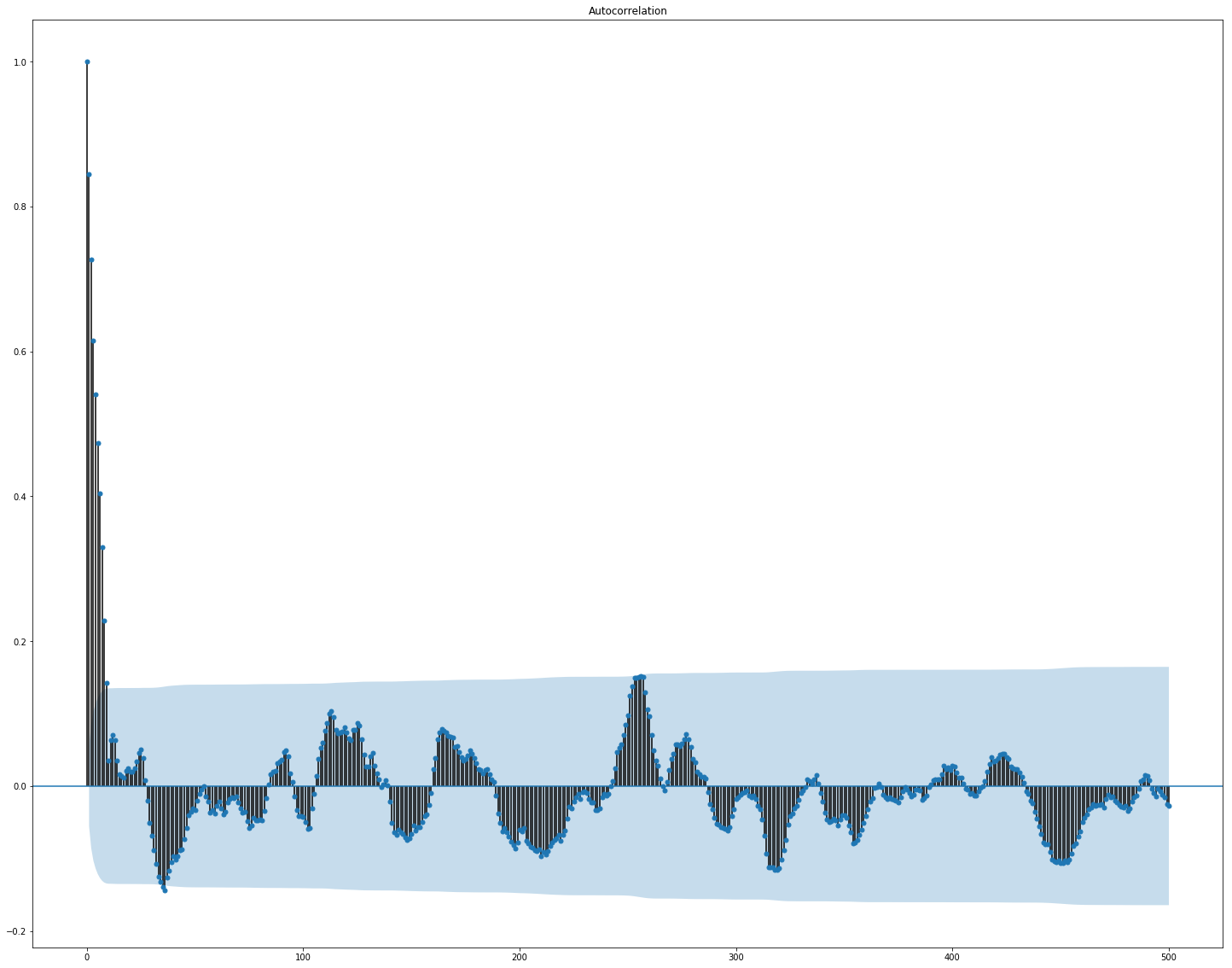
可以看出,在10天的时间之后,依赖性显着下降。 考虑到仅延迟10天的功能(原始数据集中已包含这些功能),这可能是GBM运作良好的原因。
特征选择和预处理对于所有ML算法都是至关重要的。 让我们尝试使用自动方式来提取特征,即
主成分 分析 (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
让我们看一下PCA生成的功能:

我们发现该方法在我们的数据上效果不佳,因为新功能与目标值的最终相关性很小。
微调以及是否需要
许多ML模型都有相当多的超参数,即算法本身的“设置”。 可以手动选择它们,但也有自动选择机制。 对于后者,有一个
hyperopt库,该库实现了两种匹配算法-随机搜索和
树结构Parzen估计器(TPE) 。 我试图优化:
- lightgbm参数(算法类型,叶数,学习率等),
- 神经网络模型的参数( TCN过滤器的数量, GRU内存块的数量,辍学率,学习率,求解器类型)。
结果,使用此优化发现的所有解决方案得分都较低,尽管它们在测试数据上效果更好。 可能是因为这样一个事实:考虑得分的数据与从训练中选择的验证数据不太相似。 因此,对于此任务,微调不是很合适,因为它会导致模型的重新训练。
最终决定
根据比赛规则,参赛者可以在最后阶段选择两种解决方案。 我的最终决定几乎相同,包含
GBM和多层
GRU两个模型的集合。 唯一的区别是,一种解决方案根本不使用新闻数据,而另一种解决方案仅使用神经网络模型使用新闻数据。
新闻数据解决方案:
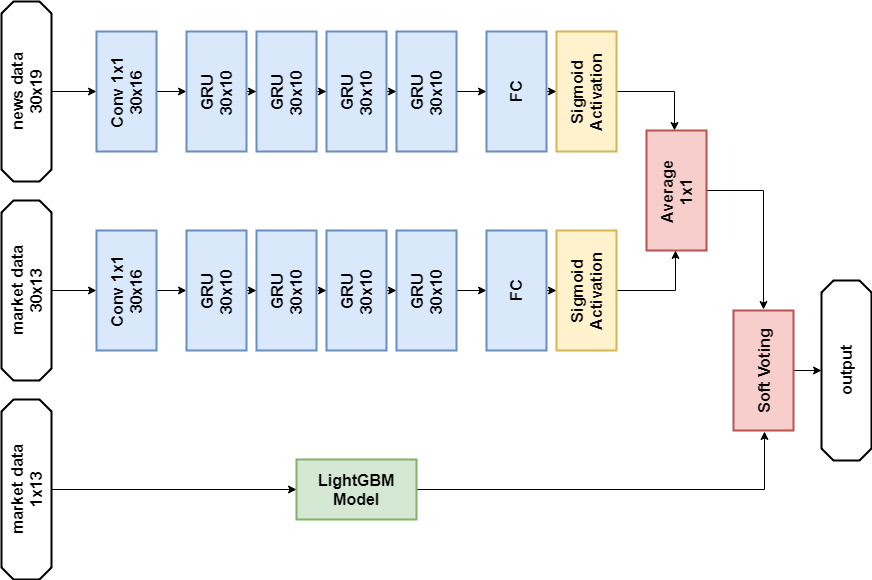
进口货 import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
神经网络模型 def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
GBM模型 def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
培训课程 n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
预言 def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
没有新闻数据的解决方案:

代码(只是一种不同的方法) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
在第一阶段的比赛中,两个决定都给出了相似的结果(约0.69),相当于2,927名中的566名。在新数据发布的第一个月后,参与者列表中的位置被混合使用,新闻数据的解决方案在其余697个团队中排名第65位,结果为3.19251,未来五个月内将会发生什么,没人知道。
我还尝试了什么
自定义指标
由于决策是使用Sharpe比率进行评估的,因此尝试将其用作提前终止培训的指标是合乎逻辑的。
lightgbm的指标:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
验证显示,在此问题上,这种度量比AUC效果更差。
注意机制
注意机制允许神经网络专注于源数据中的“最重要”特征。 从技术上讲,注意力由权重向量表示(最常见的是使用具有
softmax激活的完全连接层获得的权重),再乘以另一层的输出。 我使用了一种将注意力放在时间轴上的实现:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
这个模型看起来很漂亮,但是这种方法并没有增加分数,结果大约是0.67。
没时间做什么
看起来很有希望的几个领域:
结论
我们的冒险之旅已经结束,您可以尝试总结一下。 比赛原来很艰难,但我们无法面对尘土。 这表明进入ML的门槛并不高,但是,就像在任何行业中一样,专业人士已经可以使用真正的魔力(并且在机器学习中有很多魔力)。
结果数量:
- 第一阶段的最高分:〜0.69,而第一名则为〜1.5。 像医院的平均水平一样,0.7被一些人克服了,公共决策的最高分也达到了0.69,比我的略高。
- 处于第一阶段的位置:2927年为566。
- 第二阶段的得分:第一个月后的得分3.19251。
- 第二阶段排名:第一个月后的697分中有65分。
我提请您注意以下事实:第二阶段的数字并没有特别讨论任何问题,因为用于定性评估决策的数据仍然很少。
参考文献
使用新闻的最终解决方案两个西格玛:使用新闻预测股票走势 -比赛页面
Keras-神经
网络框架LightGBM -GBM框架
Scikit-learn-机器学习算法库
Hyperopt-用于优化超参数的库
关于WaveNet的文章