我们都知道祖国是如何开始的,深度学习是从数据开始的。 没有它们,就不可能训练模型,评估模型并真正使用它。 从事研究工作,通过有关新的神经网络体系结构和实验的文章来提高Hirsch指数,我们依靠最简单的本地数据源。 通常是各种格式的文件。 它可以工作,但是最好记住一个包含数TB不断变化数据的战斗系统。 这意味着您需要简化和加速生产中的数据传输,并能够处理大数据。 这是Apache Ignite出现的地方。
Apache Ignite是一个以内存为中心的分布式数据库,也是用于缓存和处理与事务,分析和流负载相关的操作的平台。 该系统能够以RAM的速度研磨PB级数据。 本文将重点介绍Apache Ignite与TensorFlow之间的集成,该集成使您可以将Apache Ignite用作训练神经网络和推理的数据源,以及经过训练的模型的存储库和用于分布式学习的集群管理系统。
分布式RAM数据源
Apache Ignite允许您在分布式集群中存储和处理所需数量的数据。 要在TensorFlow中训练神经网络时利用此Apache Ignite的优势,请使用
Ignite Dataset 。
注意:Apache Ignite不仅是数据库或数据仓库与TensorFlow之间的ETL管道中的链接之一。 Apache Ignite本身就是
HTAP (用于事务/分析数据处理的混合系统)。 选择Apache Ignite和TensorFlow,您将获得一个用于事务处理和分析处理的单一系统,并且同时具有使用操作和历史数据来训练神经网络和推理的能力。
以下基准测试表明,Apache Ignite非常适合将数据存储在单个主机上的方案。 如果数据仓库和客户端位于同一节点上,则这样的系统可使您实现超过850 Mb / s的吞吐量。 如果存储位于远程主机上,则吞吐量约为800 Mb / s。
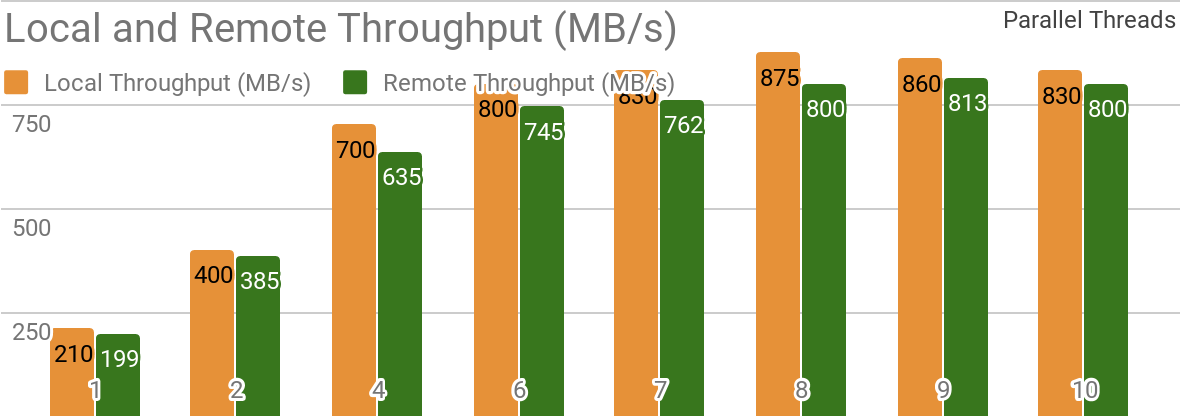
该图显示了单个本地Apache Ignite节点的Ignite数据集的带宽。 这些结果是在具有16GB RAM的2x Xeon E5-2609 v4 1.7GHz处理器和带宽为10GB / s的网络上获得的(每个记录的大小为1MB,页面大小为20MB)。
另一个基准测试演示了Ignite Dataset如何与分布式Apache Ignite群集一起使用。 当使用Apache Ignite作为HTAP系统时,默认情况下会选择此配置,它允许您在带宽为10 Gb / s的群集上为单个客户端实现超过1 GB / s的吞吐量。
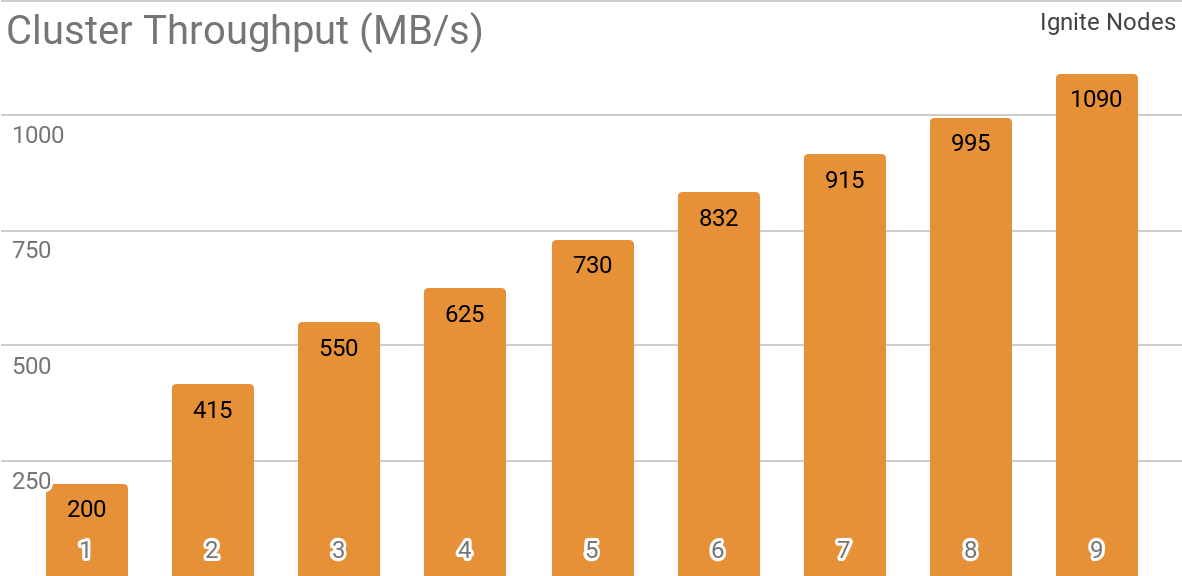
该图显示了具有不同数量节点(从1到9)的分布式Apache Ignite集群的Ignite数据集吞吐量。 这些结果是在具有16GB RAM的2x Xeon E5-2609 v4 1.7GHz处理器和带宽为10GB / s的网络上获得的(每个记录的大小为1MB,页面大小为20MB)。
测试了以下场景:Apache Ignite缓存(在第一组测试中具有可变数量的分区,在第二组测试中具有2048个分区)填充了10K行,每行1 MB,然后TensorFlow客户端使用Ignite Dataset读取数据。 该群集由具有2个Xeon E5-2609 v4 1.7 GHz,16 GB内存的计算机构建,并通过以10 GB / s的速度运行的网络连接。 在每个节点上,Apache Ignite都使用
标准配置 。
Apache Ignite易于用作具有SQL接口的经典数据库,同时又可用作TensorFlow的数据源。
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
结构化对象
Apache Ignite允许您存储可以在任何层次结构中构建的任何类型的对象。 您可以通过Ignite数据集使用它。
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
神经网络训练和其他计算需要预处理,如果使用Ignite数据集,则可以作为
tf.data管道的一部分进行
预处理 。
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
分布式培训
TensorFlow是一个机器学习框架,
支持分布式神经网络学习,推理和其他计算。 如您所知,神经网络训练基于损失函数的梯度计算。 在分布式训练的情况下,我们可以在每个分区上计算这些梯度,然后对其进行汇总。 通过这种方法,您可以为存储数据的各个节点计算梯度,对其进行汇总,最后更新模型参数。 并且,由于我们摆脱了训练样本数据在节点之间的传输,因此网络不会成为系统的“瓶颈”。
Apache Ignite使用水平分区(分片)将数据存储在分布式集群中。 通过创建Apache Ignite缓存(或用SQL表示的表),您可以指定将在其之间分发数据的分区数。 例如,如果一个Apache Ignite集群由100台计算机组成,并且我们创建了一个具有1000个分区的缓存,则每台计算机将负责约10个包含数据的分区。
Ignite Dataset允许您将这两个方面用于神经网络的分布式训练。 Ignite数据集是构成TensorFlow体系结构基础的
计算图节点。 而且,就像图中的任何节点一样,它可以在集群中的远程节点上运行。 这样的远程节点能够覆盖Ignite Dataset参数(例如
host ,
port或
part ),为工作流设置适当的环境变量(例如
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT或
IGNITE_DATASET_PART )。 使用这种覆盖,可以为每个群集节点分配一个特定的分区。 然后,一个节点负责一个分区,同时用户收到数据集的单个工作立面。
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
Apache Ignite还允许使用TensorFlow高级
Estimator API库进行分布式学习。 该功能基于TensorFlow中所谓
的分布式学习的
独立客户端模式 ,其中Apache Ignite充当数据源和集群管理系统。 下一篇文章将完全致力于该主题。
学习控制点存储
除了数据库功能外,Apache Ignite还具有分布式
IGFS文件系统。 从功能上讲,它类似于Hadoop HDFS文件系统,但仅在RAM中。 IGFS文件系统连同其自己的API一起实现了Hadoop FileSystem API,并且可以透明地连接到已部署的Hadoop或Spark。 Apache Ignite上的TensorFlow库提供了IGFS和TensorFlow之间的集成。 集成基于TensorFlow自己的
文件系统插件和Apache Ignite
本机IGFS API 。 有多种使用场景,例如:
- 状态检查点存储在IGFS中,以确保可靠性和容错能力。
- 学习过程通过将事件文件写入TensorBoard监视的目录来与TensorBoard交互。 即使TensorBoard在另一个进程或另一台机器上运行,IGFS仍可确保此类通信正常运行。
此类功能出现在TensorFlow 1.13.0.rc0的发行版中,并且还将成为TensorFlow 2.0发行版中
tensorflow / io的一部分。
SSL连接
Apache Ignite允许您使用
SSL和身份验证来保护数据通道。 Ignite Dataset支持带有或不带有身份验证的SSL连接。 有关更多详细信息,请参见
Apache Ignite SSL / TLS文档。
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Windows支援
Ignite Dataset与Windows完全兼容。 它可以在Windows工作站以及Linux / MacOS系统上用作TensorFlow的一部分。
自己尝试
以下示例将帮助您开始使用该模块。
点燃数据集
开始使用Ignite Dataset的最简单方法是使用Apache Ignite启动
Docker容器并下载
MNIST数据,然后使用Ignite Dataset对其进行操作。 Docker Hub中提供了这样的容器:
dmitrievanthony / ignite-with-mnist 。 您需要在计算机上运行容器:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
之后,您可以按以下方式使用它:
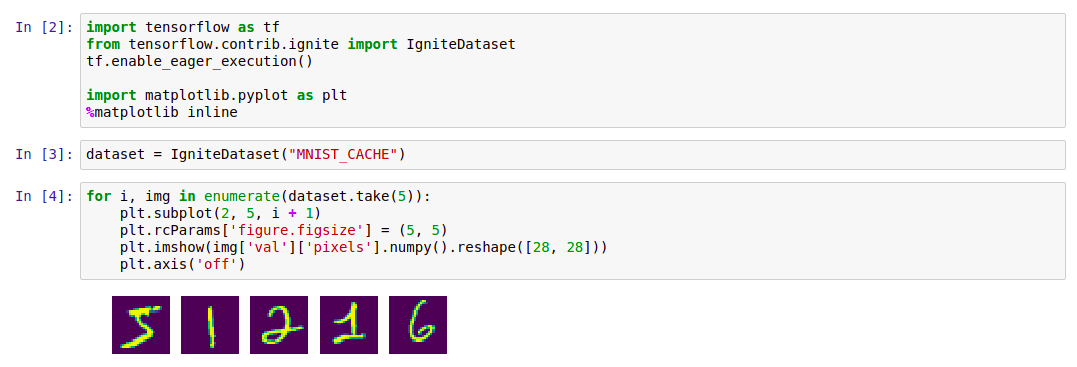
代号 import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
TensorFlow IGFS支持出现在TensorFlow 1.13.0rc0版本中,并且也将是TensorFlow 2.0中的
tensorflow / io版本的一部分。 要在TensorFlow上尝试IGFS,最简单的启动
Docker容器的方法是使用Apache Ignite + IGFS,然后使用TensorFlow
tf.gfile对其进行
操作 。 Docker Hub中提供了这样的容器:
dmitrievanthony / ignite-with-igfs 。 该容器可以在您的机器上运行:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
然后,您可以像这样使用它:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
局限性
当前,当使用Ignite数据集时,假定缓存中的所有对象都具有相同的结构(同质对象),并且缓存中至少包含一个检索架构所需的对象。 另一个限制与结构化对象有关:Ignite Dataset不支持UUID,地图和对象数组,它们可能是对象的一部分。 消除这些限制以及稳定和同步TensorFlow和Apache Ignite的版本是正在进行的开发的任务之一。
预期的TensorFlow 2.0版本
TensorFlow 2.0即将进行的更改将在
tensorflow / io模块中突出显示这些功能。 之后,可以更灵活地构建与他们的合作。 示例将有所变化,这将在gihab和文档中得到反映。