
朋友,大家好!
本文主要是前端开发人员感兴趣的,尤其是那些对GraphQL主题感兴趣的开发人员,但是与此同时,我希望对后端开发人员有所帮助,并帮助他们通过前端的眼光理解GraphQL的好处。
关于我自己的几句话: 我是8base的技术副总裁。 我们开发的工具允许前端和移动开发人员快速创建高质量的业务应用程序。
我们提供了一个平台,足以通过我们的UI定义数据模型并获得现成的GraphQL API以与数据进行交互。 用户将收到一台配置好的服务器,该服务器具有角色,访问权限,使用文件的能力,部署无服务功能,CI等的能力。 为了加快开发速度,我们还为React提供了SDK和现成的组件库。 我们在Node.js上编写后端由于我们系统的主要用户是前端和移动开发人员,因此我们决定押注GraphQL,它在我们看来最初比REST更灵活,并在前端提供了更多机会。 好吧,既然我们已经从最终用户那里收到了足够的反馈,那么可以说它非常适合。
毕竟为什么是GraphQL?
与REST不同,每个GraphQL API提供的架构都包含有关输入和输出数据类型,它们的字段以及类型之间的关系的信息。 这使您可以使用具有API中关系的数据模型,并进行独立于特定客户端应用程序中的表示形式的灵活查询(查询)和数据更改(变异)。
此外,GraphQL API允许客户端开发人员显式确定返回的数据,包括在每个查询中引用相关对象,从而避免过度提取和提取不足以及减少API请求的数量。
比较GraphQL和REST
让我们将GraphQL和REST与一个简单的示例进行比较-创建一个在线博客。 显示单独的博客文章时,我们需要显示文章的内容,作者的头像和姓名,评论列表以及每个评论者的头像和姓名。
如果使用REST,我们将需要以下API请求:
GET /articles/:id — ; GET /users/:id — URL ; GET /articles/:id/comments — ( - , 4); GET /users/:id — URL .
注意抓取不足(当一个请求没有返回所需的所有内容时)和抓取过度(例如,当请求/用户/:id返回的数据多于将要显示的数据)以及前端中更复杂的代码的问题需要组织一系列API请求。
在GraphQL中,只要API的开发人员已指出GraphQL API架构中的文章,用户和注释之间的关系,就可以在单个查询中获得所有信息。 此外,API的响应将仅包含请求的字段,这将减少其体积。
这是一个GraphQL查询的示例,该查询将一次返回一次查询中的所有信息: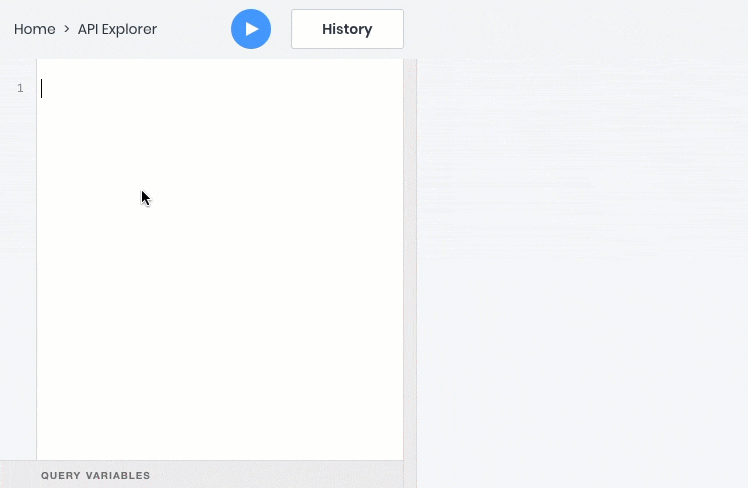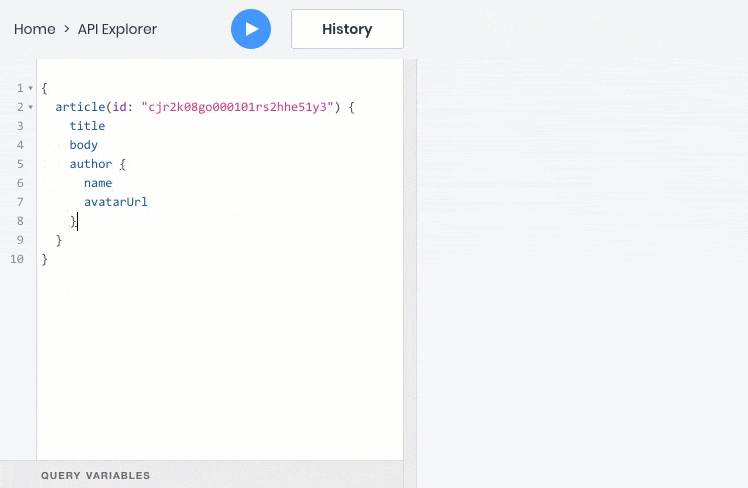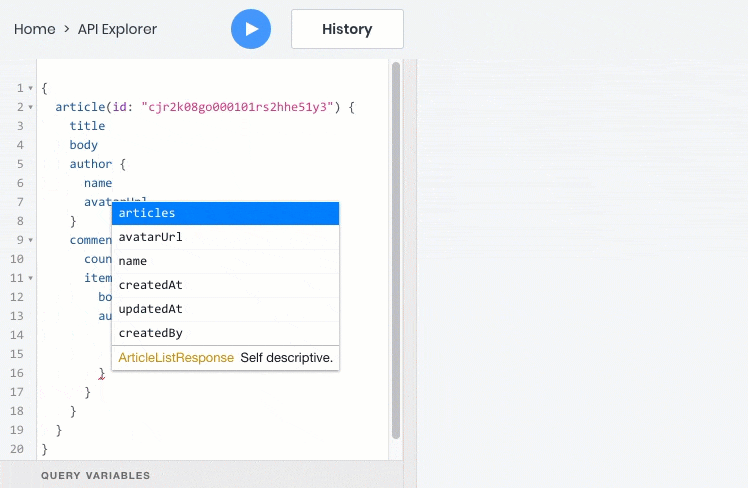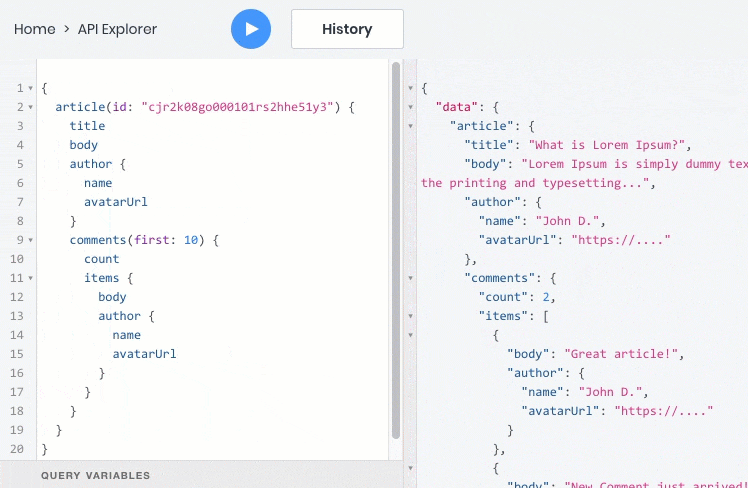
要在REST中实现此功能,后端开发人员将需要创建一个特殊的端点API,该API会返回此信息。 但是,对于每种情况,都必须通过显示相关表中的数据来完成相同的工作,并且,同时,一旦前端需要其他字段,就更新API。
该示例说明了GraphQL如何使“力量平衡”有利于前端开发人员,使他们可以请求任何必要的数据,并为后端开发人员提供了实现API的机会,使其涵盖整个主题领域,而不是针对客户端的特定演示。
所有这一切,再加上一组库和工具,将前端开发人员的质量和可用性提升到一个新的水平-这就是GraphQL在开发团队中日益流行的原因。
在实践中看起来像什么
GraphQL的缺点之一是其实现比REST更复杂。 为了以方便各种客户端应用程序的形式显示数据,后端需要进行大量工作。 为每种数据类型实现CRUD操作,链接,过滤器,排序和分页非常繁琐。 组织诸如数据访问权限之类的重要功能并将文件附加到数据对象也不是那么简单。
现在,我将在我们的实现示例中展示使用GraphQL带来的可能性:
- 通过标识符或任何唯一字段获取一个对象
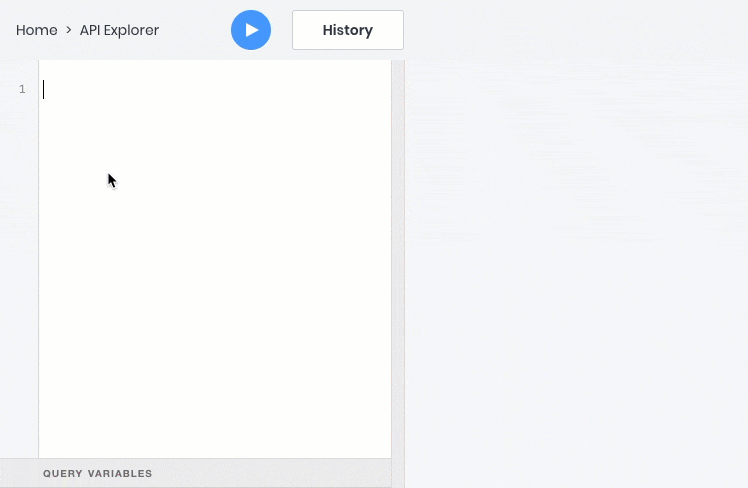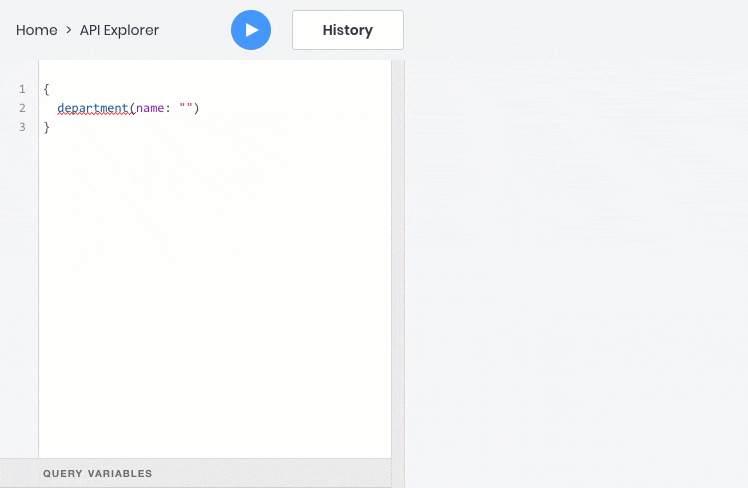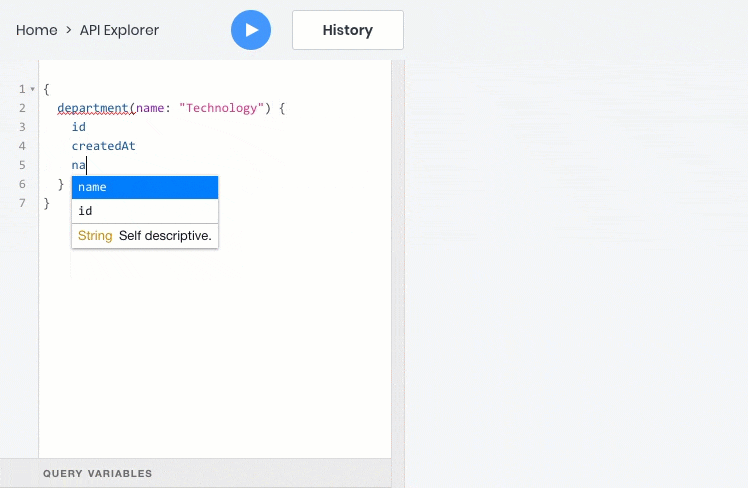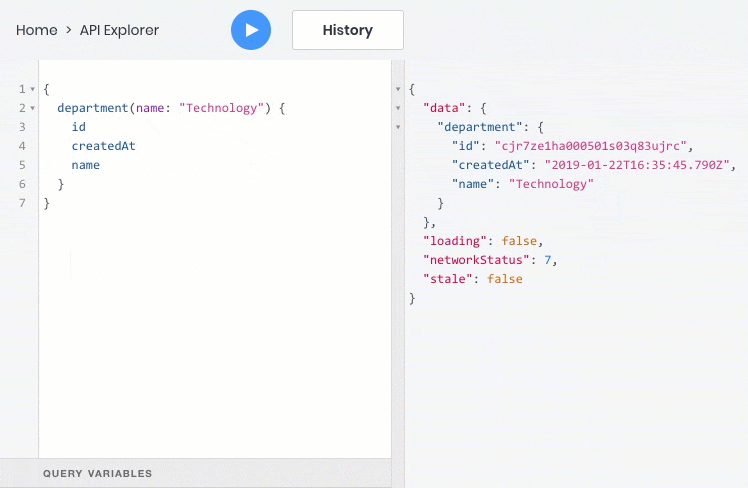
- 根据过滤器,排序,分页和全文搜索条件获取对象列表

- 创建,更新或删除对象

- 通过Web套接字订阅实时数据事件
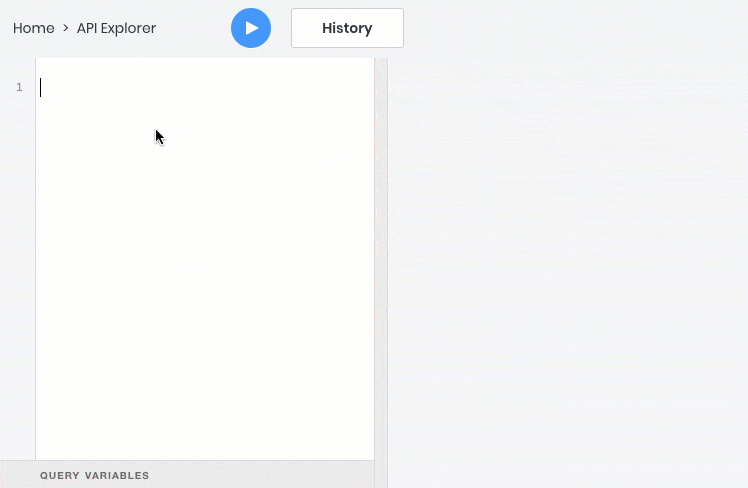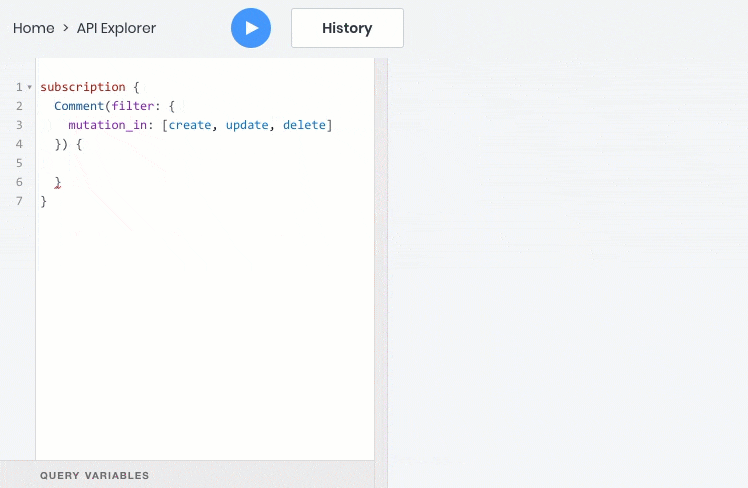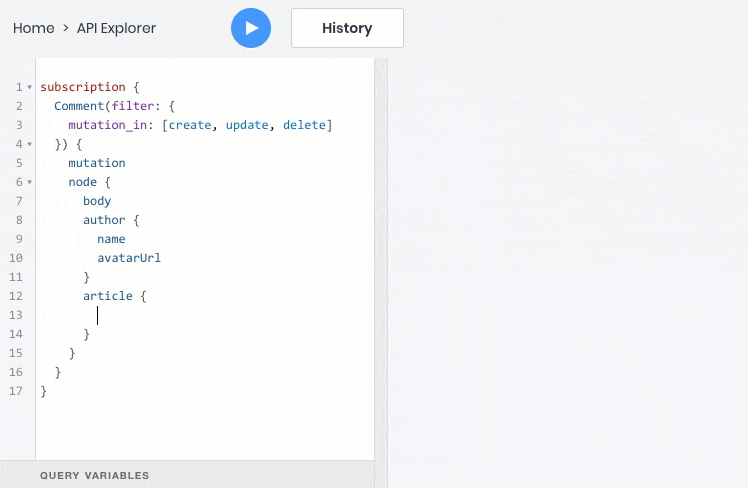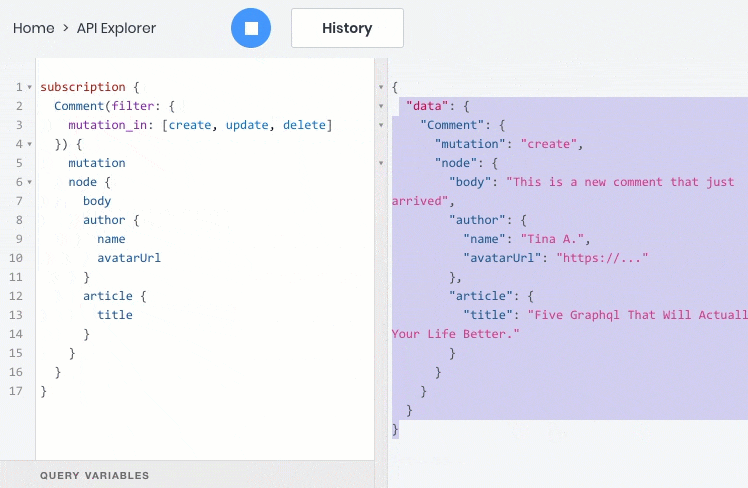
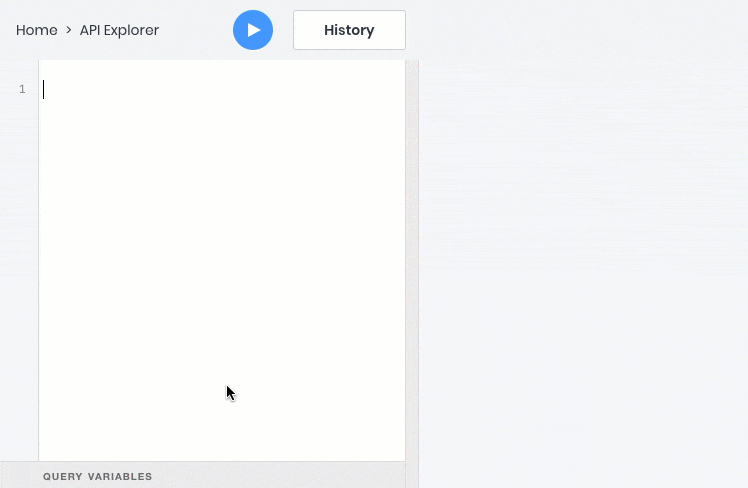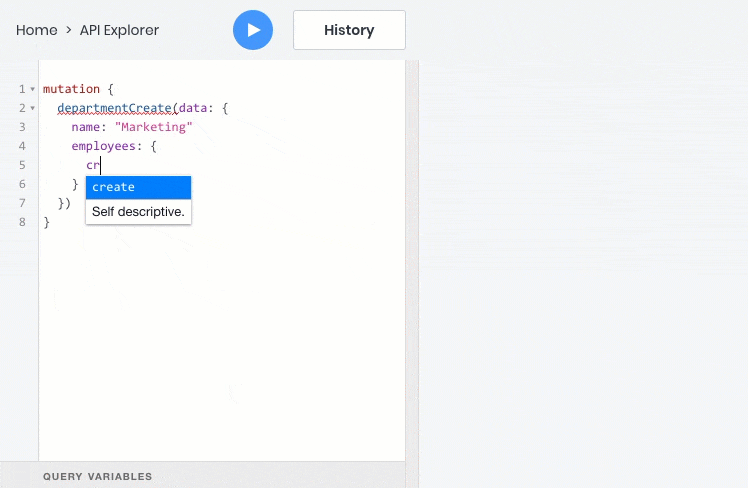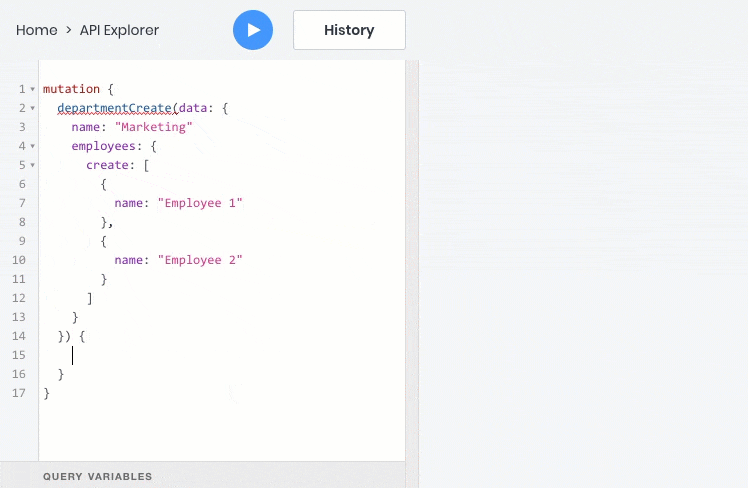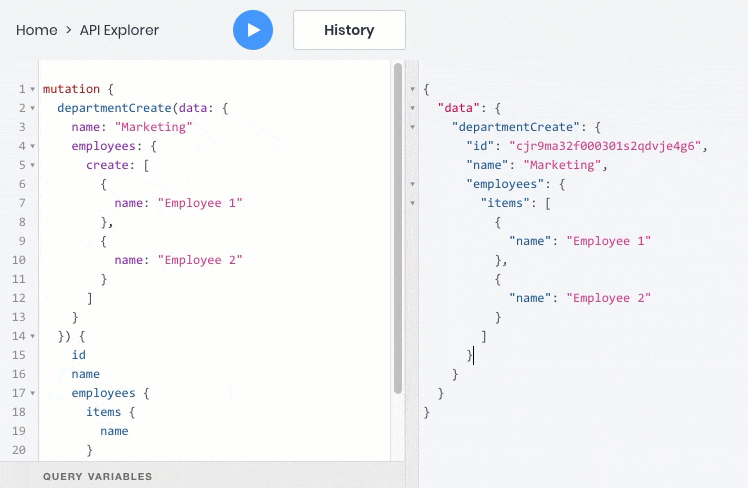
- 所有这些操作都可以完美地处理对象之间的关系,因此您可以查询,创建和更新子对象及其父对象:
总结
感谢您的关注! 我很想听听您对GraphQL或其使用经验,问题的看法,并且我也很乐意回答问题。
另外,朋友,也许您会感兴趣阅读一系列有关我们堆栈的技术文章,或者还有其他内容?
PS:您可以在后端开发人员Andrei Gorinov的演讲视频中了解有关GraphQL对前端开发人员的好处以及我们如何使用GraphQL的更多信息。