
哈Ha! 我的名字叫Stanislav Semenov,我正在研究从R&D ABBYY中的文档中提取数据的技术。 在本文中,我将讨论我们最近使用且现在正在使用的半结构化文档(发票,现金收据等)的基本处理方法。 我们将讨论机器学习方法如何适用于解决此问题。
我们将发票视为单据,因为 在世界范围内,它们非常广泛,并且在数据提取方面需求最大。 顺便说一句,发票的自动处理是我们外国客户中最受欢迎的方案之一。 例如,在ABBYY FlexiCapture的帮助下,美国百事可乐成像技术公司
减少了处理发票
的时间和由于手工输入而导致的错误数量,欧洲零售商Sportina
开始将帐户中的
数据输入会计系统的
速度提高了2倍 。
发票是在国际商业惯例中使用的文件,对业务而言非常重要。 例如,与俄罗斯的发票类似的是运货单。 这些文件中的数据属于各种会计系统,并且不欢迎在这里出现错误。
普通发票可以认为是结构合理的;它包含两个主要的对象类别:
- 标头中的各个字段(文档编号,日期,发件人,收件人,总计等),
- 表格数据是商品和服务的列表(数量,价格,说明等)。
看起来是这样的:
每年要花费数百万工时来处理发票。 而且非常昂贵。 根据各种估算,对于一家公司而言,处理一张纸质发票的成本从10美元到40美元不等,其中很大一部分是用于输入和核对数据的体力劳动。
有一些公司每月处理数百万张发票。 为此,他们包含数百名员工,有时甚至数千名员工。 容易估计,识别准确性或数据提取效率仅提高1%,每年就可以减少大公司的成本数十万甚至数百万美元。
另一方面,文档数量巨大。 2017年,Billentis
估计全球每年产生的发票总数为4000亿张。 其中,只有约10%是电子的,其余则需要完全手动输入或需要大量人员参与。 如果您在标准A4纸上打印4,000亿个文档,那么每天便有数千个纸车,或者每秒有一叠人类高度的纸!
关于技术如何发展的几句话

许多公司正在开发可以识别文档并从中提取数据的专用软件。 但是发票处理的质量仍然不完美。 “怎么了?” -你问。
这都是关于各种各样的发票。 发票没有标准,每个公司都可以自由创建自己的单据版本:字段的类型,结构和位置。
通过关键字查找字段
最初提取数据的尝试归结为在所有公认的单词中找到特殊的关键字,例如发票编号或总计,然后在这些单词的一小部分(例如右侧或底部)自行查找含义。
发票编号在不同发票中的位置(可单击):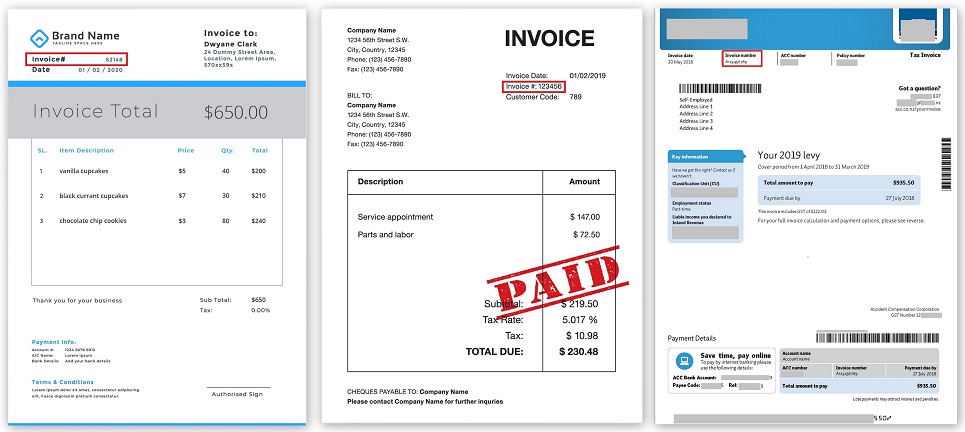
整个逻辑都经过编程,有如此之类的字段,它们都在文档的如此之类的位置,它们周围还有其他距离的字段。 这种方式一直有效,直到其他公司出现,该公司开始以完全不同的形式发送其文档。 或以前的公司突然更改了格式,一切都停止了工作。
模式
每次为此重新编程时,与之作斗争都是不合理的。 因此,一个新的范式得以应用-模板的使用。
模板是需要在文档中找到的一组字段,以及关于如何查找这些字段的一组规则。 这里的主要优点是模板是可视创建的。 例如,我们要搜索“发票编号”和“总计”,选择这些字段并配置参数,使诸如此类的字段位于诸如此类的关键字之后,该关键字位于文档的顶部,并包含数字和标点符号。
开发了专门的工具,即所谓的模板编辑器,在这种工具下,已经高级的用户无需程序员的帮助即可快速手动设置某种逻辑。 新格式的文档一到,就会为其创建一个模板,并且一切或多或少开始起作用。
样本模板(可点击):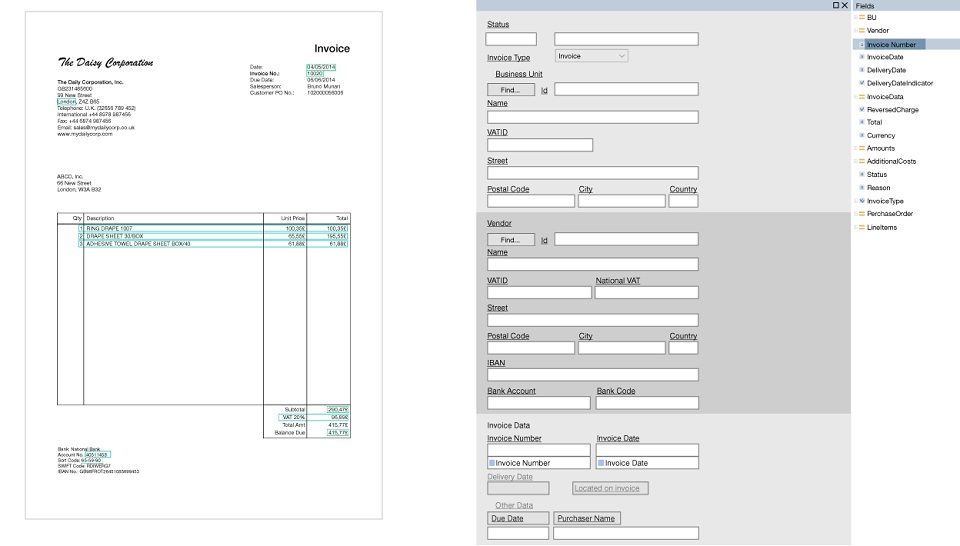
但是仅制作一个模板是不够的,需要将它们制作成数百甚至数千个。 因此,为每个客户设置产品有时会花费很多时间。 不可能事先创建涵盖所有发票的“通用”模板。
使用模板,可以显着提高表检索的质量。 但是通常会发现复杂的表结构,具有非标准的数据表示形式,多层嵌套,在这些情况下,模板并不总是能很好地完成工作。 同样,您必须编写一些脚本,其中包含许多手动选择的参数,条件,异常等。
使用机器学习
当今的技术并没有停滞不前,并且随着机器学习的发展,将从文档中提取数据的任务转移到神经网络成为可能。
如今,实践中使用了几种基本方法:
- 第一种方法是直接处理文档的输入图像。 即,将图像(图片)或片段馈送到网络输入,网络学习找到需要的字段所在的小区域,然后使用经典的OCR(光学字符识别)技术识别这些区域中的文本。 这是一个可以快速实施的端到端解决方案。 您可以使用现成的网络来搜索图像中的对象,例如YOLO或Faster R-CNN,并在标记有文档的图片中对其进行训练。
这种方法的缺点不是提取数据的最佳质量和提取表的难度。 实际上,这种方法在某种程度上类似于在图像中找到正确单词的任务(单词发现),这是计算机视觉领域的一个基本问题,但是在这里我们不是在寻找单词,而是在寻找必要的领域。 - 第二种方法是处理从文档中提取的文本。 这可以是PDF中的文本,也可以是整页OCR文档。 它使用自然语言处理(NLP)技术。 行是由单个单词组合而成的,文本的各种片段,段落或列是由行组成的,在网络中,他们已经在学习区分各种命名实体NER(命名实体识别)。
形成文本片段的各种方式都是可能的。 您可以结合第一种和第二种方法,训练一个网络以查找图像中带有某些信息的大块,例如,有关发件人的数据或有关收件人的数据,这些信息立即包含名称,地址,详细信息等,然后传输每个此类块的文本到第二个NER网络。
事实证明,这种方法的质量要比第一种方法高,但是要建立有效的模型却相当困难。 如今,有相当先进的模型,例如用于NER的LSTM-CRF,它可以标记文本中的单词并定义实体。 - 第三种方法是在不参考文档类型的情况下建立文档的语义表示。 当我们不知道文档在我们面前时,但是我们尝试在处理过程中理解它。 一组具有各种属性的文档单词(例如,单词仅包含字母还是数字),单词的几何排列(坐标,缩进)以及在图像分析过程中标识的各种定界符和连接,将输入到网络输入,并获得以下输出:每个词都有其特定的特征集。 基于获得的特征,形成可能的字段或表的各种假设集,将其进一步分类并由其他分类器评估。 然后,选择文档结构和内容的最可靠假设。
从技术上来说,这已经是最困难的解决方案,但是您可以解决从文档中提取数据的一般问题。
我们如何使用神经网络
我们在ABBYY不仅密切监视科学技术的成就,而且还创造自己的先进技术并将其应用于各种产品中。
下图显示了使用神经网络的解决方案的一般架构。
可点击的图片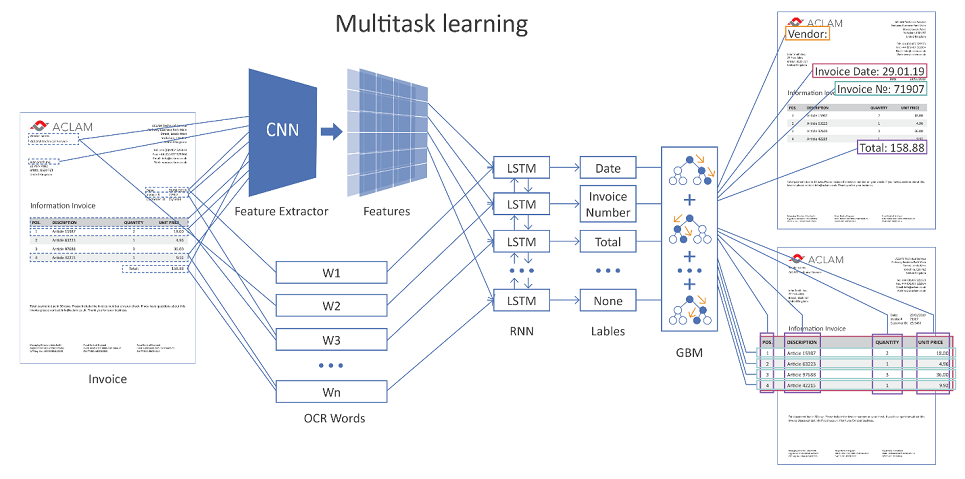
整个文档页面被馈送到网络输入。 使用卷积层(CNN),可以形成各种几何特征,例如,单词相对于彼此的相对位置。 此外,这些符号与已识别单词的矢量表示(单词嵌入)组合在一起,并在循环(LSTM)和完全连接的层上使用。 有几个不同的输出层(多任务学习),每个输出解决了自己的问题:
- 确定单词可以对应的字段类型,
- 表边界的假设
- 表行,列边界等的假设
如果文档是多页的,则网络对每个单独的页面进行预测,然后将结果合并。
接下来,在单独训练的回归函数的帮助下,由字段和表的可能排列构成假设,并对它们进行评估,最有把握的假设获胜。
为了提高数据提取的准确性,除了按类型(支票,发票,合同等)分隔文档外,还会根据其他特征在其类型内进行其他聚类。
例如,对于发票,它可以是供应商,也可以只是外观(根据字段位置的相似程度)。 然后,根据特定的组(集群),应用特定的算法设置。 从技术上讲,具有为不同组正确标记发票的示例,在用户端可以重新培训评估和选择正确假设的机制。
为了配置算法和神经网络的各种参数,我们使用了差分进化方法,该方法在实践中已被证明非常出色。
我们的机器学习结果

- 在许多情况下,使用机器学习从结构化文档中提取数据的已开发方法显示出比基于启发式的编程解决方案更好的结果。 在各种可度量实体中,各种指标的质量增益范围从几个单位到百分之几十。
- 与传统方法相比,有一个不可否认的优势-在新数据上重新训练网络的能力。 对于各种形式的文档,现在这不是问题,而是需要。 它们越多越好; 网络的概括能力越强,质量越高。
- 当用户仅安装产品(实际上是经过培训的网络),并且一切立即开始以可接受的结果运行时,就有机会“即开即用”地发布所谓的解决方案。 无需编写任何程序,只需长时间繁琐地自定义模板,选择各种参数即可。
我还要提到的一个重要细节是数据。 没有高质量的数据,就不会发生机器学习。 仅当有足够数量的标记数据时,机器学习才能提供比知识工程更好的结果。 就发票而言,这些是成千上万个带有手动标签的文档,并且这个数字还在不断增长。
此外,我们使用先进的数据增强机制,更改组织的名称,地址,商品清单以及表格中的服务类型,日期,各种定量特征,例如价格,数量,成本等。 我们还更改了文档中各种实体的顺序,这使我们最终可以生成数百万个完全不同的文档进行培训。
而不是结论
总而言之,我们可以说编程当然并没有消失,而是在逐渐改变其作用。 随着每一天的到来,机器学习开始逐渐适应各种行业中分配给它的任务,从而淘汰了经典方法。 机器学习在效率方面的不可否认的优势:数十个人年的智力工作现在花费了数十个机器小时的学习时间。 因此,在不久的将来,我们将在我们所有的发展中看到网络的更大发展和适用性。 如果您有兴趣,我们将随时欢迎您的建议与
合作 。