哈勃!
该站点的许多普通读者和作者可能考虑了此处发布的文章的生命周期。 并且虽然从直觉上讲这或多或少很清楚(例如,显而易见的是,首页上的文章具有最大的视图数),但是具体是多少?
为了收集统计信息,我们将使用Python,Pandas,Matplotlib和Raspberry Pi。
那些对它的结果感兴趣的人,请注意。
资料收集
首先,让我们决定指标-我们想知道的内容。 一切都很简单,每篇文章在页面上显示4个主要参数-这是视图,喜欢,书签和评论的数量。 我们将对其进行分析。
那些想立即看到结果的人可以转到第三部分,但是现在它将是关于编程的。
总体计划:我们将从网页上解析必要的数据,将其保存为CSV,然后查看几天后会得到什么。 首先,加载文章的文本(为清楚起见,省略了异常处理):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
现在我们需要从data_str行提取数据(当然,它是HTML格式)。 在浏览器中打开源代码(删除了非原理性元素):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
显而易见,我们需要的文本位于块'<ul class =“ post-stats post-stats_post js-user_>”中,并且必要的元素位于名称中,名称为voting-wjt__counter,bookmark__counter,post-stats__views-count和post- stats__comments-count。 顾名思义,一切都是显而易见的。
我们将继承str类,并向其中添加提取位于两个标签之间的子字符串的方法:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
您可以在没有继承的情况下进行操作,但这将允许您编写更简洁的代码。 有了它,所有数据提取都可以分为4行:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
但这还不是全部。 如您所见,注释或视图的数量可以存储为字符串,例如“ 12.1k”,该字符串不会直接转换为int。
添加一个将这样的字符串转换为数字的函数:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
它仅保留添加时间戳,您可以将数据保存在csv中:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
由于我们有兴趣分析几篇文章,因此我们增加了通过命令行指定链接的功能。 我们还将通过文章ID生成日志文件名:
link = sys.argv[1]
而最后一步。 我们取出函数中的代码,然后在循环中轮询数据,并将结果写入日志。
delay_s = 5*60 while True:
如您所见,数据每5分钟更新一次,以免在服务器上造成负载。 我将程序文件保存为habr_parse.py,启动时它将保存数据,直到程序关闭。
此外,建议将数据保存至少几天。 因为 我们不愿意将计算机打开几天,而是使用Raspberry Pi –它足以完成此任务,并且与PC不同,Raspberry Pi不产生噪音,几乎不消耗电力。 我们通过SSH并运行我们的脚本:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
关闭控制台后,nohup命令将脚本保留在后台。
另外,您可以通过输入命令“ nuhup python -m SimpleHTTPServer 8000&”在后台运行http服务器。 这将使您可以随时在浏览器中直接查看结果,打开形式为
http://192.168.1.101:8000的链接(地址当然可能有所不同)。
现在,您可以将Raspberry Pi保持打开状态,并在几天后返回该项目。
资料分析
如果一切都正确完成,那么输出应该类似于以下日志:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
让我们看看如何处理它。 首先,将csv加载到pandas数据框中:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
添加用于转换和平均的函数,并提取必要的数据:
def to_float(s):
平均是必要的,因为站点上的视图数以100为增量显示,这导致“残缺”的计划。 原则上,这不是必需的,但通过平均它看起来会更好。 代码中还添加了莫斯科时区(Raspberry Pi上的时间原来是GMT)。
最后,您可以显示图表并查看发生了什么。
import matplotlib.pyplot as plt
结果
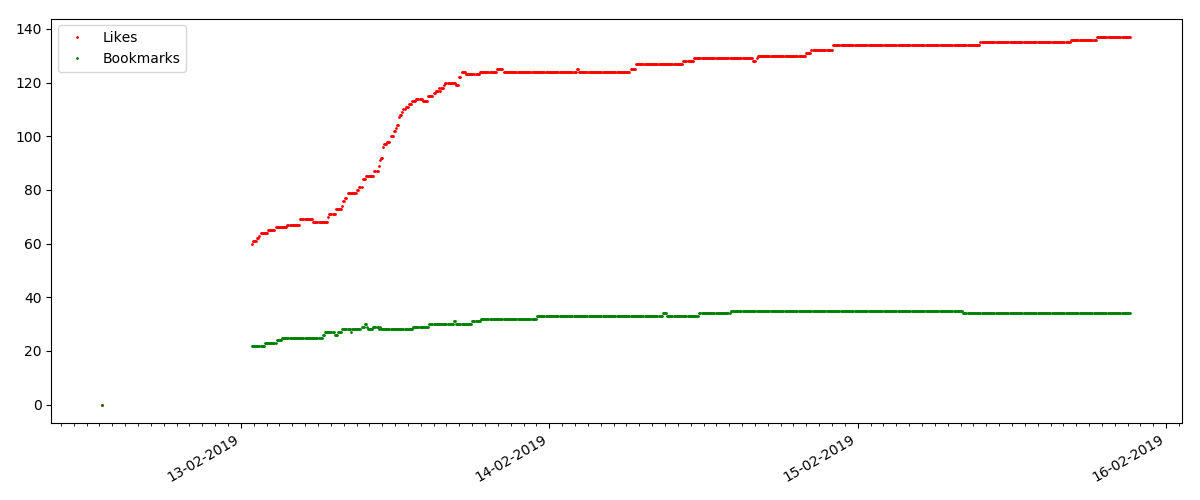
在每个图的开始处都有一个空白空间,这很简单地解释了-启动脚本时,文章已经发布,因此数据不是从头开始收集的。 从文章发表时间的描述中手动添加了“零”点。
所有布局的图表都是由matplotlib和上面的代码生成的。
根据结果,我将调查的文章分为3组。 该划分是有条件的,尽管它仍然具有一定意义。
热门文章
本文是关于某个热门且相关主题的,标题为“ MTS如何扣款”或“ Roskomnadzor阻止
色情 git hub”。
这样的文章有很多观点和评论,但是“炒作”最多持续几天。 您还可以看到白天和晚上的观看次数增长略有差异(但并不像预期的那样重要-显然,几乎所有时区都读取了Habr)。
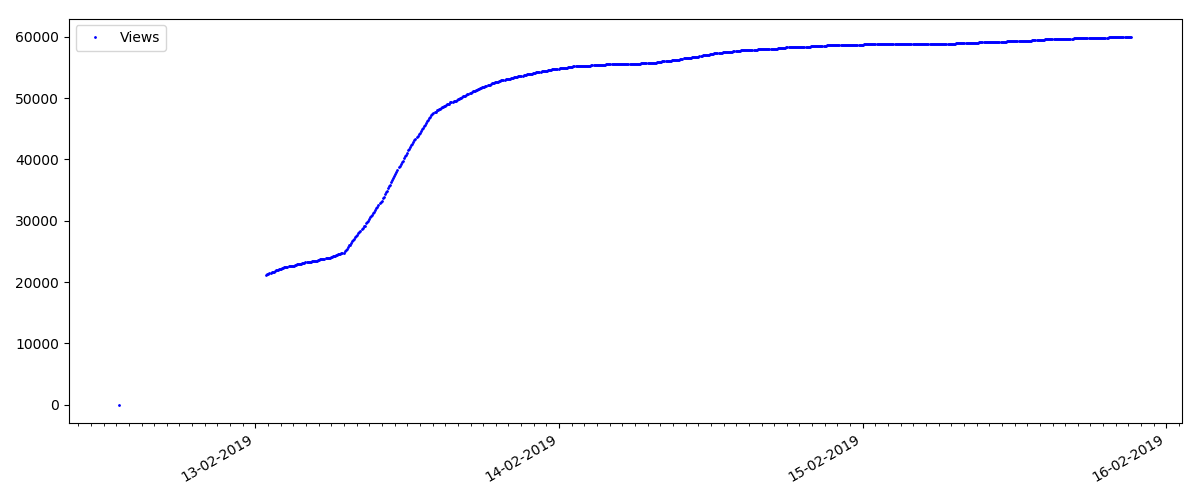
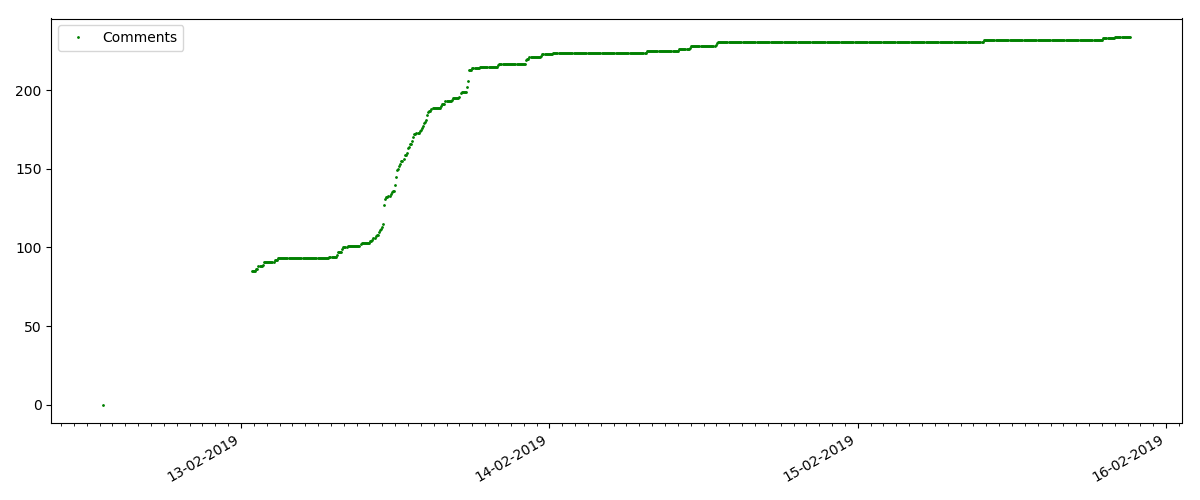
“喜欢”的数量增长非常明显,而书签的数量增长明显慢。 这是合乎逻辑的,因为 可能有人喜欢这篇文章,但是文本的特殊性使得根本不需要将其添加为书签。
观点和喜欢的比率大致相同,约为400:1:
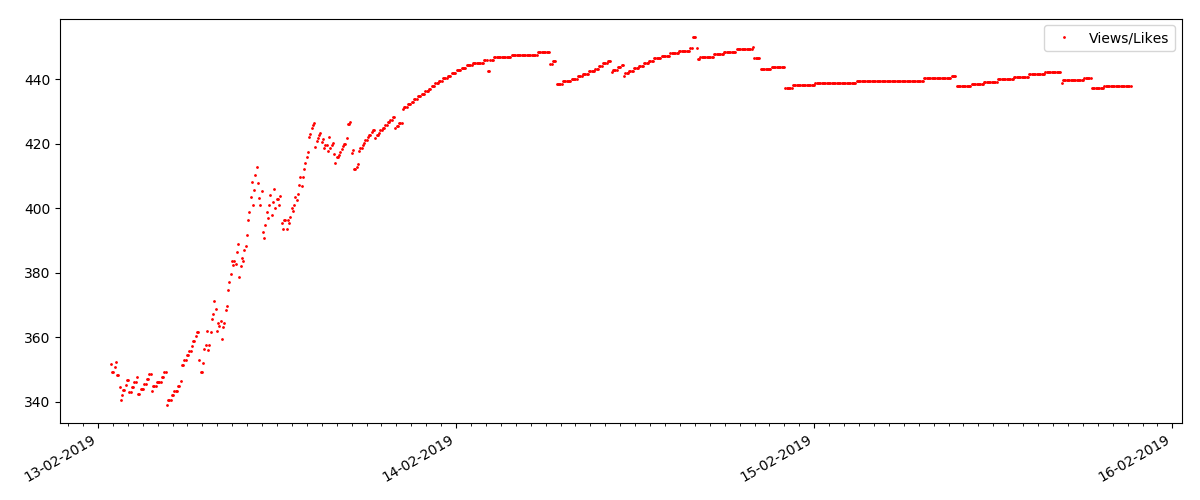
“技术”文章
这是一篇更专业的文章,例如“为Node JS设置脚本”。 当然,这样的一篇文章获得的意见比“热门”文章少很多倍,评论的数量也明显减少(在这种情况下,只有4条)。
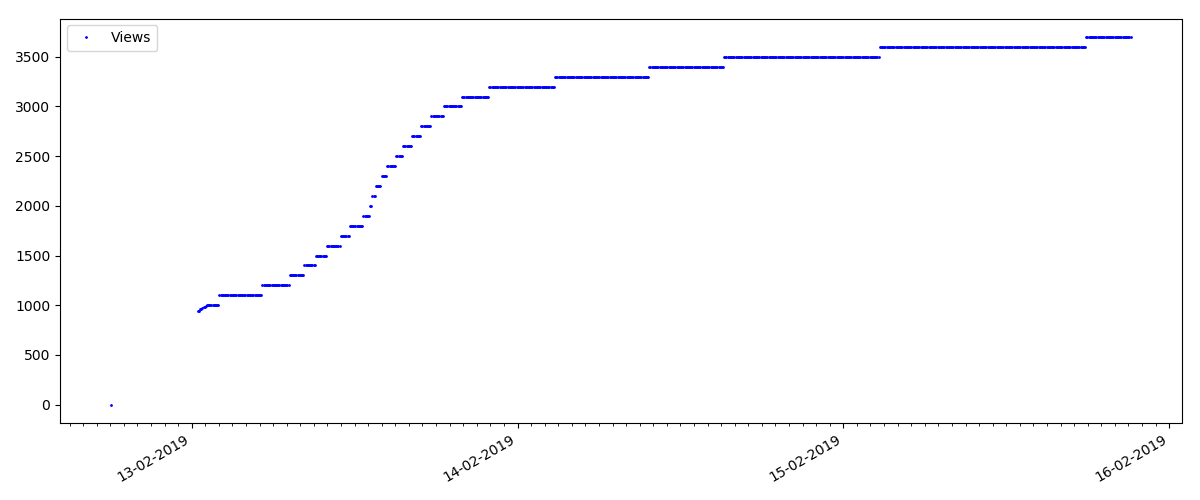
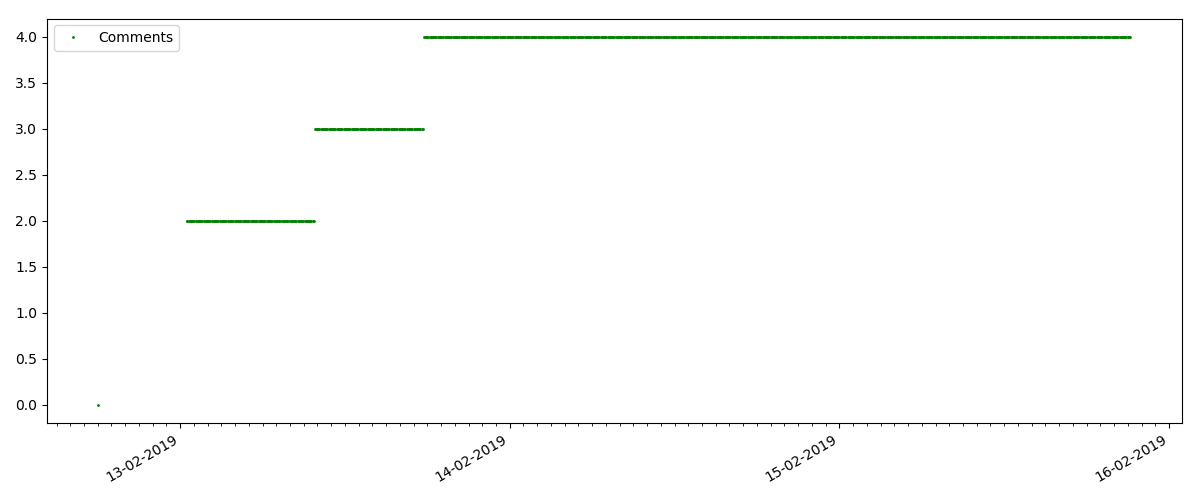
但是,下一点更有趣:此类文章的“喜欢”数量增长明显慢于“书签”数量。 与以前的版本相比,这里是相反的情况-许多人认为该文章对将来保存很有用,但是读者根本不需要单击“赞”。
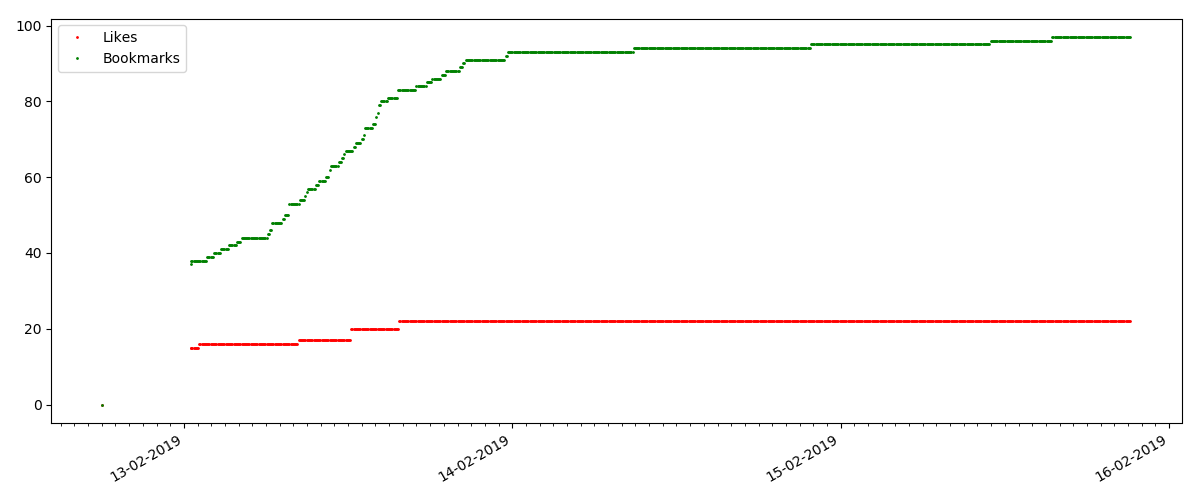
顺便说一句,在这一点上,我想引起站点管理员的注意-在计算文章评分时,您应该将书签与点赞并行计数(例如,按OR组合集合)。 否则,当一个著名的文章有很多书签(也就是说,读者肯定喜欢它)时,这会导致评分出现偏差,但是这些人忘记了或者太懒了,无法单击“喜欢”。
最后,观看和喜欢的比率:您可以看到它明显高于第一实施例,大约为150:1,即 内容的质量也可以间接地视为较高。
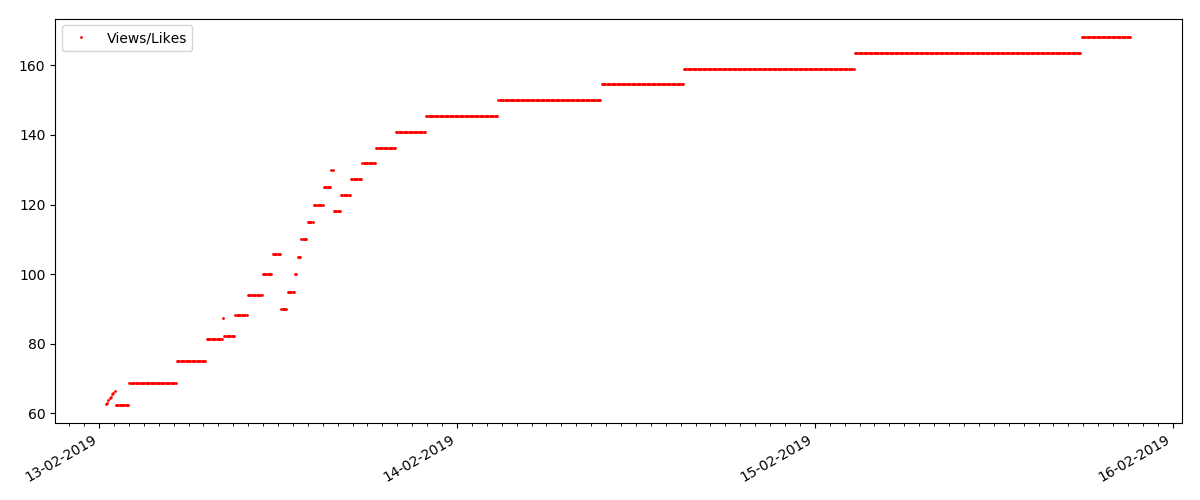
“可疑”文章(但这不准确)
对于检查的下一篇文章,“喜欢”的数量在5分钟的间隔内增加了三分之一(立即增加了10个,在所有几天中总共获得了30分)。
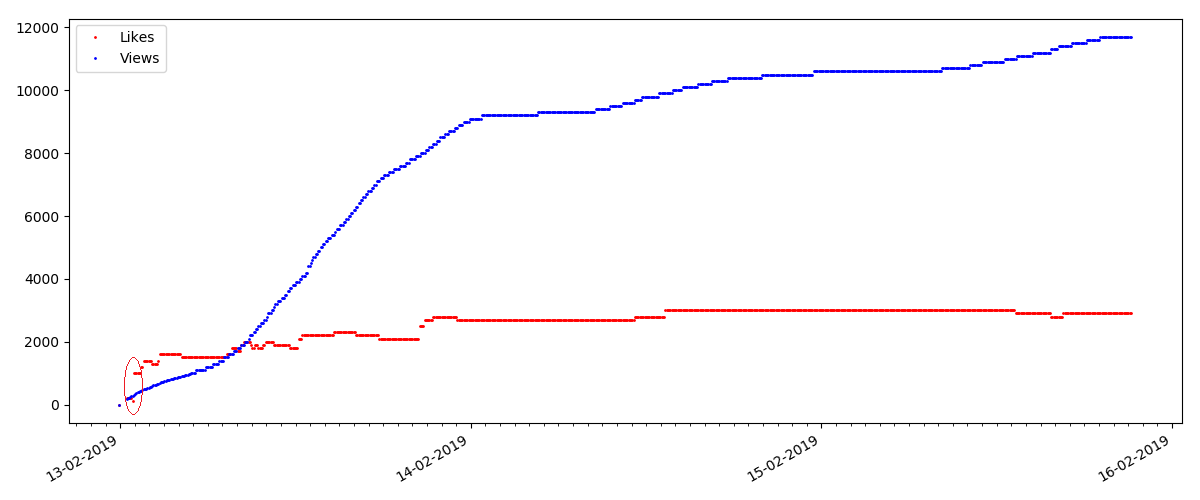
人们可能会怀疑是作弊,但原则上“排队论”却允许这种浪潮。 或者,也许作者只是将链接发送给了他的所有10个朋友,当然,这些规则也不是禁止的。
结论
主要结论是,一切都是衰变和玛雅。 即使是最流行的材料,也能获得成千上万的观看次数,并且只需3-4天即可“过去”。 a,现代互联网的特性,乃至整个现代媒体行业的整体。 而且我敢肯定,显示的数字不仅是针对Habr的,而且还针对任何类似的Internet资源。
否则,这种分析本质上更可能是“星期五”,并且当然不假装是认真的研究。 我也希望有人在使用Pandas和Matplotlib中找到新的东西。
谢谢您的关注。