哈Ha! 在本文中,我们将在Linux下使用Apache Kafka在Spring Boot 2上编写一个应用程序,从安装JRE到工作的微服务应用程序。
看到该文章的前端开发部门的同事抱怨说,我没有解释Apache Kafka和Spring Boot是什么。 我相信任何需要使用上述技术来组装完成项目的人都知道它是什么以及为什么需要它。 如果对读者而言,问题并不闲着,那么这是有关Habr的优秀文章,
Apache Kafka和
Spring Boot是什么 。
我们无需对Kafka,Spring Boot和Linux是什么进行冗长的解释,而是在Linux机器上从头开始运行Kafka服务器,编写两个微服务,并使其中一个向其他人发送消息-通常,配置完整的微服务架构。

该职位将包括两个部分。 在第一个中,我们在Linux机器上配置并运行Apache Kafka,第二个中,我们用Java编写了两个微服务。
在我以程序员的职业生涯开始的创业公司中,Kafka上有微服务,我的一个微服务也通过Kafka与其他人一起工作,但是我不知道服务器本身是如何工作的,无论是作为应用程序编写的还是已经完全装箱的产品。 当我发现Kafka仍然是盒装产品时,我感到惊讶和失望,我的任务不仅是用Java编写客户端(我喜欢这样做),还将完成的应用程序部署和配置为devOps(我讨厌做)。 但是,即使我可以在不到一天的时间内将其在Kafka虚拟服务器上提出,也确实非常简单。 这样啊
我们的应用程序将具有以下交互结构:
与往常一样,在文章末尾,将有指向带有工作代码的git的链接。
在虚拟机上部署Apache Kafka + Zookeeper
我试图在本地Linux,罂粟和远程Linux上提高Kafka。 在两种情况下(Linux),我很快就成功了。 对于罂粟,什么也没发生。 因此,我们将在Linux上安装Kafka。 我选择了Ubuntu 18.04。
为了让Kafka工作,她需要一个Zookeeper。 为此,必须在启动Kafka之前下载并运行它。
这样啊
0.安装JRE
这是通过以下命令完成的:
sudo apt-get update sudo apt-get install default-jre
如果一切正常,那么您可以输入命令
java -version
并确保已安装Java。
1.下载Zookeeper
我不喜欢Linux上的魔术团队,尤其是当他们只给出一些命令并且不清楚他们在做什么时。 因此,我将描述每个动作-它的确切作用。 因此,我们需要下载Zookeeper并将其解压缩到一个方便的文件夹中。 建议将所有应用程序都存储在/ opt文件夹中,也就是说,在我们的示例中,它将是/ opt / zookeeper。
我用下面的命令。 如果您认为其他Linux命令可以使您更正确地执行此操作,请使用它们。 我是开发人员,而不是开发人员,并且我与“山羊本身”级别的服务器进行通信。 因此,下载应用程序:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
该应用程序被下载到您指定的文件夹中,我创建了文件夹/ home / xpendence / downloads,以下载我需要的所有应用程序。
2.解压Zookeeper
我使用了命令:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
此命令将归档文件解压缩到您所在的文件夹中。 然后,您可能需要将应用程序转移到/ opt / zookeeper。 您可以立即进入它,并从那里已经解压缩了存档。
3.编辑设定
在文件夹/ zookeeper / conf /中有一个文件zoo-sample.cfg,我建议将其重命名为zoo.conf,JVM将在启动时查找该文件。 最后应在文件中添加以下内容:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
另外,创建/ var / zookeeper目录。
4.启动Zookeeper
转到/ opt / zookeeper文件夹,并使用以下命令启动服务器:
bin/zkServer.sh start
应该出现“开始”。
之后,我建议检查服务器是否正常运行。 我们写:
telnet localhost 2181
应显示一条消息,说明连接成功。 如果服务器性能较弱,但未出现该消息,请重试-即使出现STARTED,应用程序也将在更晚的时候开始监听该端口。 当我在一台弱小的服务器上尝试所有这些操作时,它每次都发生在我身上。 如果一切都已连接,请输入命令
ruok
这是什么意思:“你还好吗?” 服务器应响应:
imok ( !)
并断开连接。 因此,一切都按计划进行。 我们继续启动Apache Kafka。
5.在Kafka下创建一个用户
要使用Kafka,我们需要一个单独的用户。
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6.下载Apache Kafka
有两种分布-二进制和源。 我们需要一个二进制文件。 在外观上,带有二进制文件的归档文件大小不同。 二进制文件重59 MB,重6.5 MB。
使用下面的链接将二进制文件下载到该目录中:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7.解压Apache Kafka
解压过程与Zookeeper的相同。 我们还将压缩文件解压缩到/ opt目录中,并将其重命名为kafka,以便/ bin文件夹的路径为/ opt / kafka / bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8.编辑设定
设置在/opt/kafka/config/server.properties中。 添加一行:
delete.topic.enable = true
此设置似乎是可选的,没有它就可以工作。 此设置使您可以删除主题。 否则,您根本无法通过命令行删除主题。
9.我们授予访问用户kafka目录Kafka的权限
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10.期待已久的Apache Kafka发布
我们输入命令,然后启动Kafka:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
如果常规操作(Kafka用Java和Scala编写)没有溢出到日志中,那么一切正常,您可以测试我们的服务。
10.1。 服务器问题弱
为了在Apache Kafka上进行实验,我选择了一个性能较弱的服务器,该服务器具有一个内核和512 MB RAM(仅需99卢布),这对我来说是几个问题。
内存不足。 当然,您无法使用512 MB超频,并且由于内存不足,服务器无法部署Kafka。 事实是,默认情况下,Kafka占用1 GB的内存。 难怪他失踪了:)
我们转到kafka-server-start.sh,zookeeper-server-start.sh。 已经有一条调节内存的行:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
更改为:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
这将降低Kafka的胃口,并允许您启动服务器。
计算机性能低下的第二个问题是没有足够的时间连接到Zookeeper。 默认情况下,这是6秒。 如果铁很弱,那当然是不够的。 在server.properties中,我们增加了与zukipper的连接时间:
zookeeper.connection.timeout.ms=30000
我定了半分钟。
11.测试Kafka服务器
为此,我们将打开两个终端,其中一个将启动生产者,而另一个将启动消费者。
在第一个控制台中,输入一行:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
应显示此图标,表明生产者已准备好发送垃圾邮件:
>
在第二个控制台中,输入命令:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
现在,在生产者控制台中键入内容,当您按Enter键时,它将出现在消费者控制台中。
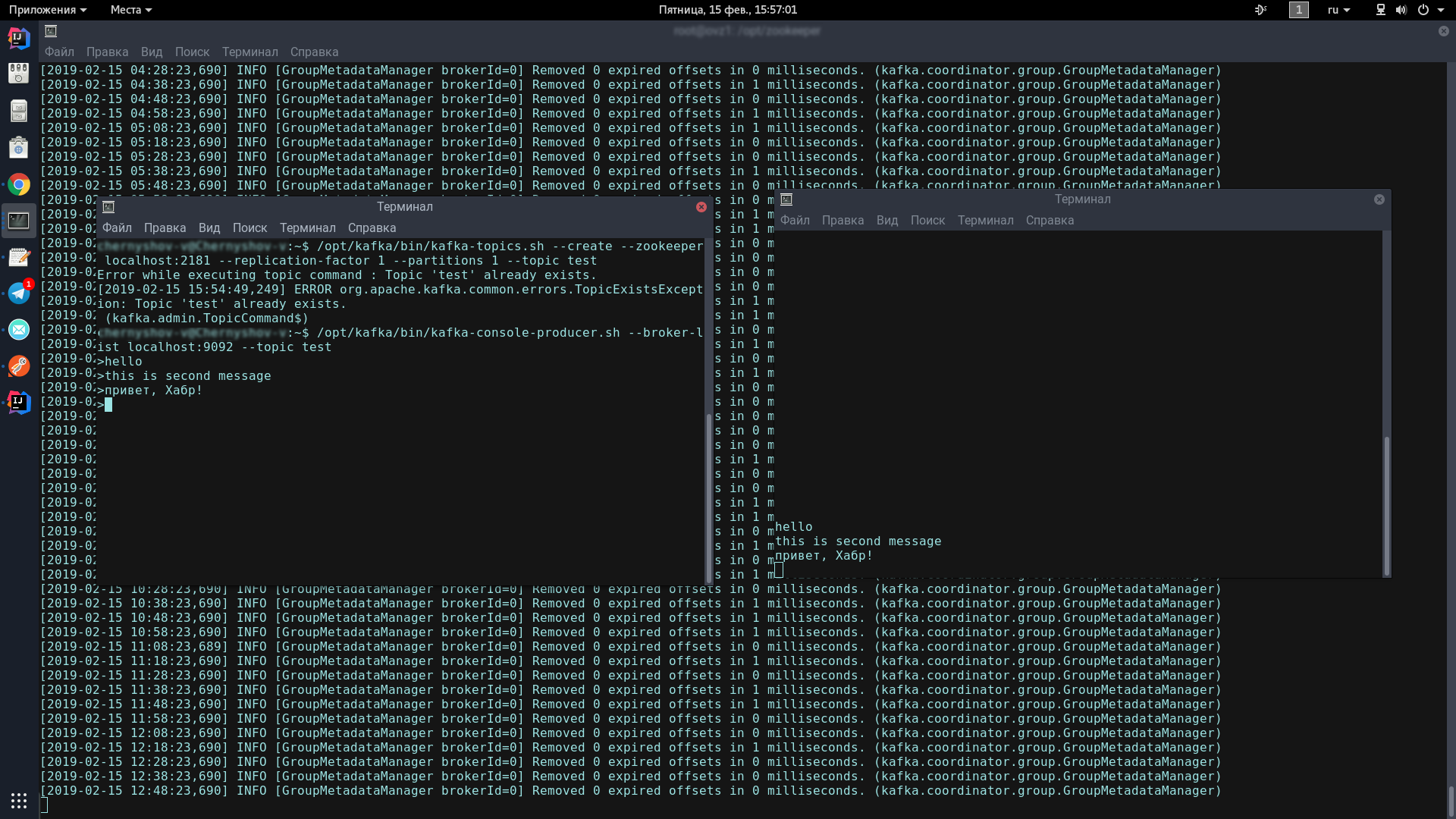
如果您在屏幕上看到的画面与我大致相同-恭喜,最糟糕的时刻已经过去!
现在我们只需要在Spring Boot上编写几个客户端即可通过Apache Kafka相互通信。
在Spring Boot上编写应用程序
我们将编写两个应用程序,它们将通过Apache Kafka交换消息。 第一条消息称为kafka-server,将包含生产者和消费者。 第二个称为kafka-tester,其设计目的是使我们拥有微服务架构。
卡夫卡服务器
对于通过Spring Initializr创建的项目,我们需要Kafka模块。 我添加了Lombok和Web,但这只是一个口味问题。
Kafka客户端由两个部分组成-生产者(他将消息发送到Kafka服务器)和消费者(他听着Kafka服务器并从那里接收有关他所订阅主题的新消息)。 我们的任务是编写两个组件并使它们工作。
消费者:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
我们需要使用来自kafka.properties的静态数据初始化的2个字段。
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server是服务器挂起的地址,在这种情况下为本地。 默认情况下,Kafka侦听端口9092。
kafka.group.id是一组使用者,在其中传送消息的一个实例。 例如,您在一个小组中有三个快递员,他们都听同一个话题。 服务器上出现带有该主题的新消息后,该消息就会立即传递给组中的某人。 其余两个使用者没有收到该消息。
接下来,我们为消费者创建工厂-ConsumerFactory。
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
通过我们所需的属性进行初始化,它将在将来成为消费者的标准工厂。
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
ConsumerConfigs只是Map配置。 我们提供服务器地址,组和反序列化器。
此外,对于消费者而言,最重要的一点之一。 消费者可以接收单个对象和集合,例如StarshipDto和List。 而且,如果将StarshipDto作为JSON获取,则将List大致作为JSON数组获取。 因此,我们至少有两个消息工厂-用于单个消息和用于数组。
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
我们实例化ConcurrentKafkaListenerContainerFactory,分别键入Long(消息键)和AbstractDto(抽象消息值),并使用属性初始化其字段。 当然,我们用我们的标准工厂(已经包含Map配置)初始化工厂,然后标记为我们不侦听数据包(相同的数组),并指定一个简单的JSON转换器作为转换器。
当我们为包/数组(批处理)创建工厂时,主要区别(除了标记为监听包的事实)是,我们指定了一个特殊的包转换器作为转换器,它将转换包含以下内容的包从JSON字符串。
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
还有一件事。 初始化Spring Bean时,名称kafkaListenerContainerFactory下的bin可能不会被计数,并且该应用程序将被破坏。 当然,可以使用更优雅的选项来解决问题,在注释中写下它们,因为现在我刚刚创建了一个卸载了具有相同名称功能的垃圾箱:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
消费者成立。 我们传递给生产者。
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
在静态变量中,我们需要kafka服务器的地址和生产者ID。 他可以是任何人。
如我们所见,在配置中,没有什么特别的。 几乎一样。 但是就工厂而言,有很大的不同。 我们必须为将要发送到其对象的每个类注册一个模板,并为其注册一个工厂。 我们有一对这样的对,但可以有数十对。
在模板中,我们标记为将序列化JSON中的对象,这也许就足够了。
我们有一个消费者和一个生产者,它仍然需要编写一项服务来发送和接收消息。
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
我们的服务只有两种方法,它们足以让我们解释客户的工作。 我们自动连接所需的模式:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
生产者方法:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
向服务器发送消息所需要做的只是在模板上调用send方法,然后在其中传输主题(主题)和我们的对象。 该对象将以JSON序列化,并将在指定主题下跳转到服务器。
侦听方法如下所示:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
我们用@KafkaListener批注标记该方法,在其中注明我们喜欢的任何ID,已收听的主题以及将接收到的消息转换为所需内容的工厂。 在这种情况下,由于我们接受一个对象,因此我们需要一个singleFactory。 对于列表<?>,指定batchFactory。 结果,我们使用send方法将对象发送到kafka服务器,并使用消耗方法将其获取。
您可以在5分钟内编写一个测试,以演示Kafka的全部功能,但我们会走得更远-花10分钟编写另一个应用程序,该应用程序将向服务器发送消息,这是我们第一个应用程序将侦听的消息。
卡夫卡测试仪
具有编写第一个应用程序的经验,我们可以轻松编写第二个应用程序,尤其是如果我们复制粘贴和dto包,仅注册生产者(我们将仅发送消息)并将唯一的send方法添加到服务中。 使用下面的链接,您可以轻松下载项目代码,并确保其中没有复杂的代码。
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
在最初的10秒后,kafka-tester开始每5秒将带有星舰名称的消息发送到Kafka服务器(图片是可单击的)。
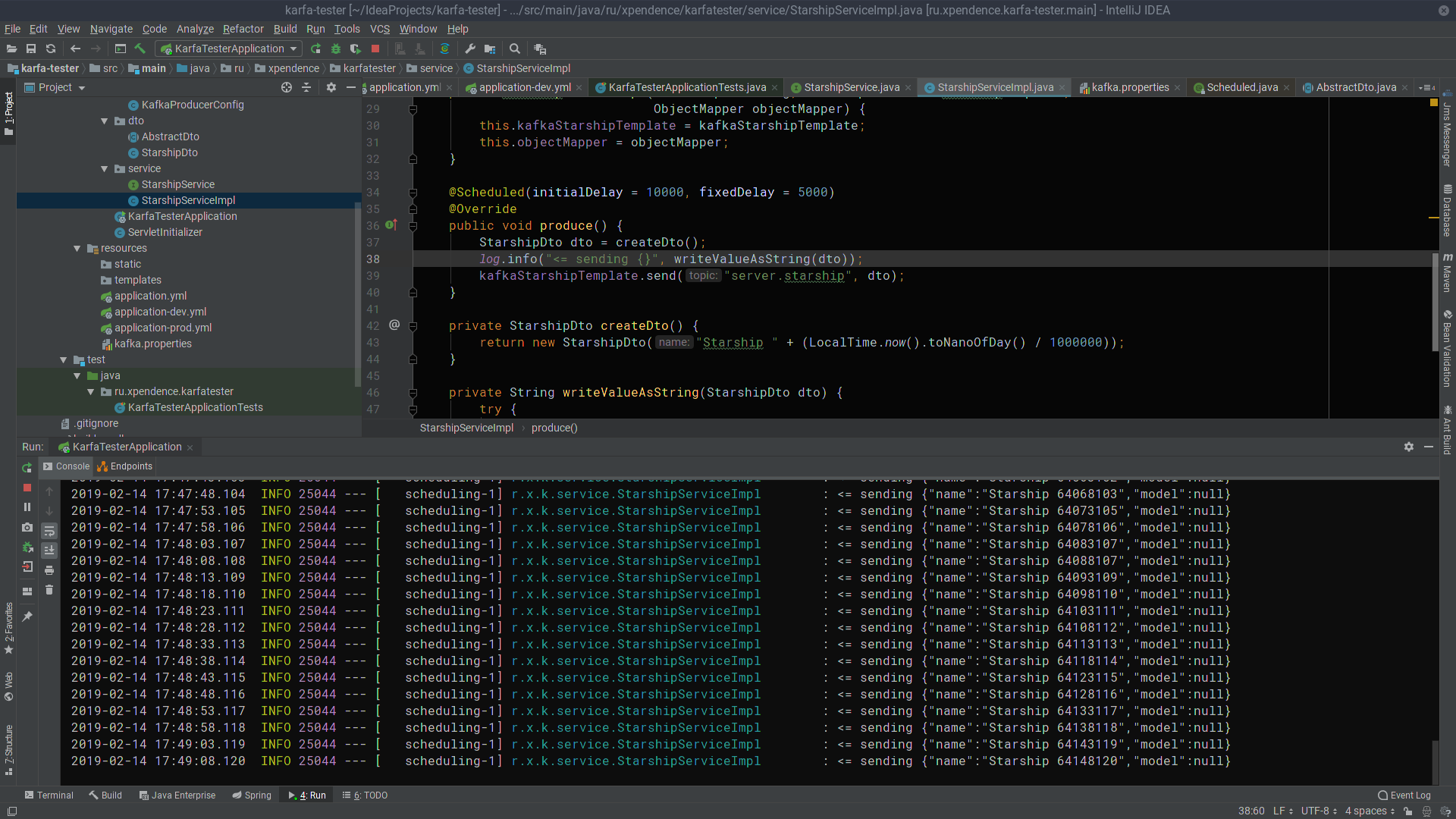
在那里,kafka-server会收听和接收它们(图片也可单击)。

我希望那些梦想开始在Kafka编写微服务的人能够像我一样轻松地成功。 这是项目的链接:
→
kafka服务器→
卡夫卡测试仪