
一个小问题/答案:
是给谁用的? 很少或没有分布式系统经验的人,以及对了解如何构建它们,存在哪些模式和解决方案感兴趣的人。
怎么会这样 他自己对什么以及如何变得感兴趣。 我从各种来源收集了信息,因此决定将其集中发布,因为一次我希望看到类似的作品。 实际上,这是我个人投掷和思考的文字说明。 此外,知识渊博的人的评论中可能会有许多更正,而部分地目的是以文章的形式撰写所有这些内容。
问题陈述
如何进行聊天? 这应该是一件微不足道的任务,大概每隔一个贝克汉姆就自己看一眼,就像游戏开发者制作俄罗斯方块/蛇之类的东西。活跃的用户,总体来说非常酷。 显然,对分布式体系结构的需求来自于此,因为要拥有一台能够容纳所有假想数量的客户的当前容量是不现实的。 我坚定地着手研究分布式系统这一主题,而不仅仅是坐等量子计算机的出现。
值得注意的是,快速响应非常重要,众所周知的实时是聊天 ! 不是鸽子邮件传递。
% 关于俄罗斯帖子的随机笑话 %
我们将使用Node.JS,它是原型制作的理想选择。 对于套接字,请使用Socket.IO。 在TypeScript上编写。
所以我们想要什么:
- 这样用户可以互相发送消息
- 知道谁在线/离线
我们如何想要它:
单服务器
对于代码,没有什么特别要说的。 声明消息接口:
interface Message{ roomId: string,// message: string,// }
在服务器上:
io.on('connection', sock=>{ // sock.on('join', (roomId:number)=> sock.join(roomId)) // // sock.on('message', (data:Message)=> io.to(data.roomId).emit('message', data)) })
在客户端上,类似:
sock.on('connect', ()=> { const roomId = 'some room' // sock.on('message', (data:Message)=> console.log(`Message ${data.message} from ${data.roomId}`)) // sock.emit('join', roomId) // sock.emit('message', <Message>{roomId: roomId, message: 'Halo!'}) })
您可以使用以下在线状态进行操作:
io.on('connection', sock=>{ // // , - // sock.on('auth', (uid:string)=> sock.join(uid)) //, , // // sock.on('isOnline', (uid:string, resp)=> resp(io.sockets.clients(uid).length > 0)) })
在客户端上:
sock.on('connect', ()=> { const uid = 'im uid, rly' // sock.emit('auth', uid) // sock.emit('isOnline', uid, (isOnline:boolean)=> console.log(`User online status is ${isOnline}`)) })
注意:代码未运行,我仅以内存为例
就像柴火一样,我们动摇着卑鄙的真实授权,房间管理(消息历史记录,添加/删除参与者)和利润。
但是! 但是,我们将接管世界和平,这意味着现在不是停止的时候,我们正在迅速前进:
Node.JS集群
在官方网站上可以找到在许多节点上使用Socket.IO的示例。 其中包括一个本地Node.JS集群,在我看来这不适用于我的任务:它使我们能够在整个计算机上扩展应用程序,但并没有超出其范围,因此我们肯定会错过它。 我们最终需要超越一块铁的界限!
分发和骑自行车
怎么做? 显然,我们需要以某种方式连接我们的实例,这些实例不仅在地下室的家中启动,而且在相邻的地下室中启动。 首先想到的是:我们进行某种中间链接,该链接将充当我们所有节点之间的总线:
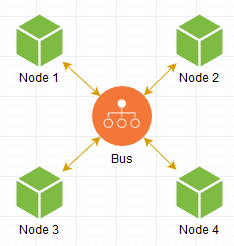
当一个节点想要向另一个发送消息时,它向总线发出请求,并且已经将其转发到必要的地方,一切都很简单。 我们的网络已经准备就绪!
FIN。
...但这不是那么简单吗?)
使用这种方法,我们会遇到此中间链接的性能,并且确实希望直接联系必要的节点,因为有什么比直接通信更快的呢? 因此,我们朝这个方向前进!
首先需要什么? 实际上,将一个实例合法化为另一个实例。 但是第一个如何了解第二个的存在呢? 但是我们希望有无限数量的它们,可以任意提高/删除! 我们需要一个主服务器,其地址已知,每个人都可以连接到它,因此它知道网络中所有现有节点并与每个人共享此信息。
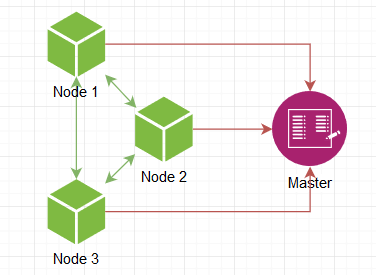
节点上升,告诉主机它的唤醒状态,它给出其他活动节点的列表,我们连接到它们,就是这样,网络已经准备就绪。 主人可能是领事或类似的人,但是由于我们正在骑自行车,所以主人必须是自制的。
太好了,现在我们有了自己的天窗! 但是,目前聊天中的实现不再适用。 让我们实际提出以下要求:
- 当用户发送消息时,我们需要知道他向谁发送消息,即可以访问会议室中的参与者。
- 当我们收到参与者时,我们必须向他们传递消息。
- 我们需要知道哪个用户现在在线。
- 为了方便起见-给用户提供订阅其他用户在线状态的机会,以便他们实时了解其更改
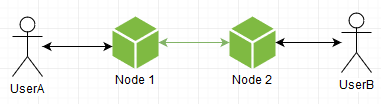
让我们与用户打交道。 例如,您可以使主节点知道哪个节点连接到哪个节点。 情况如下:
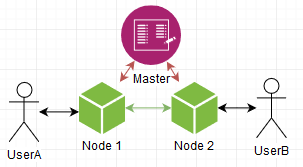
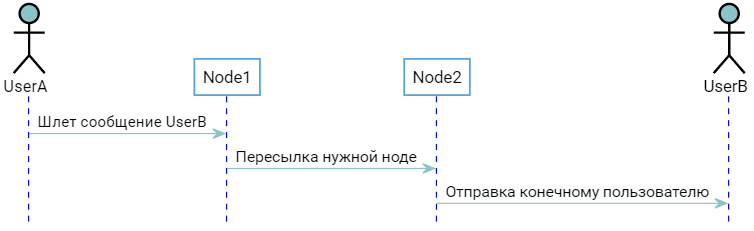
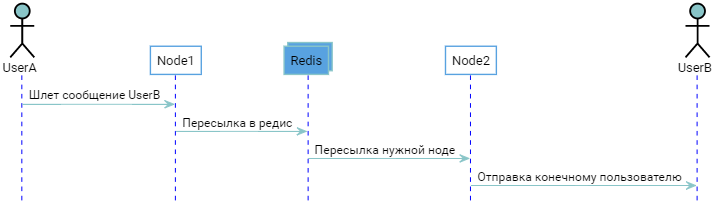
两个用户连接到不同的节点。 主机知道这一点,节点知道主机知道什么。 当UserB登录时,Node2通知主机,该主机“记住” UserB已连接到Node2。 当UserA要发送UserB消息时,您会收到以下图片:
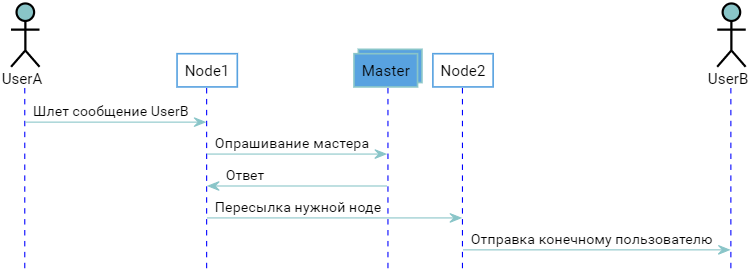
原则上,一切正常,但我想避免以询问主机的方式进行额外的回合,直接与正确的节点直接联系会更经济,因为这就是一切的开始。 如果他们告诉每个人周围有哪些用户连接到他们,每个人都成为向导的一个自给自足的模拟,并且向导本身就变得不必要,这是可以做到的,因为比率“ User => Node”的列表对每个人都是重复的。 在节点开始时,足以连接到任何已经运行的节点,将其列表拉到自己身上,瞧,它也已准备好进行战斗。
但是权衡取舍,我们得到了一个重复的列表,尽管它是“用户ID-> [主机连接]”的比率,但是如果有足够的用户数量,它将在内存中变得相当大。 通常,自行切割-很明显,这是自行车行业的劣迹。 代码越多,潜在的错误就越多。 也许我们冻结此选项,然后看看已经准备好了什么:
消息经纪人
实现上述相同“总线”(即“中间链接”)的实体。 它的任务是接收和传递消息。 我们作为用户可以订阅并发送自己的信息。 一切都很简单。
有经过验证的RabbitMQ和Kafka:它们只是完成传递消息的工作-这是他们的目的,塞满了所有必要的功能。 在他们的世界中,无论如何都必须传达信息。
同时,还有Redis及其pub / sub -与前面提到的家伙一样,但更多的是橡树:它只是愚蠢地接收消息并将其传递给订户,而没有任何队列和其他开销。 他绝对不关心消息本身,如果订阅者挂断消息,消息将消失-他将其丢弃并拿起一个新消息,好像它们会将炽热的扑克牌扔到他的手中,希望您能更快地摆脱。 另外,如果他突然摔倒-所有消息也会与他一起沉没。 换句话说,毫无疑问可以保证交货。
...这就是您所需要的!
好吧,真的,我们只是聊天。 不是某种紧急资金服务或太空飞行控制中心,而是...只是聊天。 风险在于有条件的Pete每年一次不会收到千分之一的消息-如果作为回报,我们获得了生产力的增长,并且与他在同一天的用户数保持不变,那么就可以忽略他的一切荣耀。 而且,同时,您可以在某种持久性存储库中保留消息历史记录,这意味着Petya通过重新加载页面/应用程序仍会看到丢失的消息。 这就是为什么我们将重点放在Redis pub / sub上的原因,或者更确切地说:查看办公室文章中提到的 SocketIO的现有适配器。 网站 。
那是什么
Redis适配器
https://github.com/socketio/socket.io-redis
有了它的帮助,一个普通的应用程序通过几行和最少的手势操作就可以变成真正的分布式聊天! 但是如何? 如果您向里看 -事实证明,每一百行只有一个文件。
在我们发出消息的情况下
io.emit("everyone", "hello")
它被放入萝卜中,传输到我们聊天的所有其他实例,这些实例又将其本地发布在套接字上
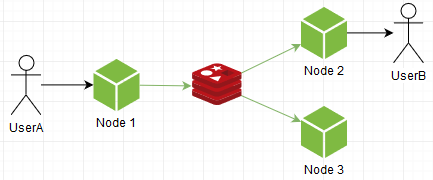
即使我们发布给特定用户,该消息也将分布在所有节点上。 也就是说,每个节点都接受所有消息,并且已经知道是否需要它。
此外,还实现了一个简单的rpc(调用远程过程),它不仅可以发送,而且可以接收答案。 例如,您可以远程控制套接字,例如“谁在指定房间中”,“命令套接字加入房间”等。
该怎么办? 例如,使用用户ID作为房间名称(用户ID ==房间ID)。 授权时,将其连接到插座,以及当我们想向用户发送消息时,只需戴上头盔即可。 同样,我们可以查看用户是否在线,只需查看指定房间中是否有插座即可。
原则上,我们可以在这里停下来,但是一如既往,这对我们来说还不够:
- 一个萝卜实例中的瓶颈
- 冗余,我希望节点仅接收他们需要的消息
以第一段为代价,看一下这样的事情:
Redis集群
它连接了几个萝卜实例,然后它们作为一个整体工作。 但是他是怎么做到的呢? 是的,像这样:
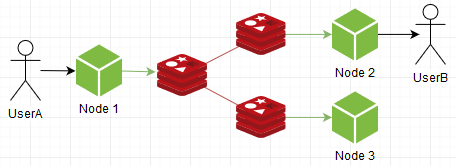
...,我们看到消息已复制到所有集群成员。 也就是说,这并不是要提高生产率,而是要提高可靠性,这肯定是必要的,但对于我们而言,它没有价值,也不会以任何方式解决瓶颈问题,总之甚至会浪费资源。

我是一个初学者,我不太了解,有时候我必须回到干草叉,我们会这样做。 不,让我们离开萝卜,这样萝卜就不会滑落,但是您需要考虑一下具有体系结构的东西,因为当前的体系不好。
走错路
我们需要什么? 提高整体吞吐量。 例如,让我们尝试愚蠢地产生另一个实例。 想象一下,socket.io-redis可以连接到多个,当推送一条消息时,它会随机选择并订阅所有内容。 原来是这样的:
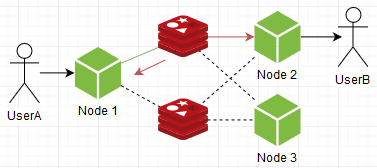
瞧! 通常,问题已解决,萝卜不再是瓶颈,您可以生成任意数量的副本! 但是它们成为节点。 是的,是的,我们的聊天实例仍会消化所有不希望发送给他们的消息。
反之亦然:随机订阅一个,这将减少节点上的负载并推送所有内容:
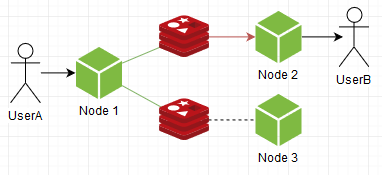
我们看到了相反的情况:节点感觉更平静,但是萝卜实例上的负载增加了。 这也没有好处。 您需要骑自行车一点。
为了抽出我们的系统,我们将只留下socket.io-redis软件包,尽管它很酷,但我们需要更多的自由。 因此,我们连接萝卜:
// : const pub = new RedisClient({host: 'localhost', port: 6379})// const sub = new RedisClient({host: 'localhost', port: 6379})// // interface Message{ roomId: string,// message: string,// }
设置我们的消息传递系统:
// sub.on('message', (channel:string, dataRaw:string)=> { const data = <Message>JSON.parse(dataRaw) io.to(data.roomId).emit('message', data)) }) // sub.subscribe("messagesChannel") // sock.on('join', (roomId:number)=> sock.join(roomId)) // sock.on('message', (data:Message)=> { // pub.publish("messagesChannel", JSON.stringify(data)) })
目前,结果就像在socket.io-redis中一样:我们监听所有消息。 现在我们将修复它。
我们按照以下方式组织订阅:记住“用户ID ==房间ID”的概念,当用户出现时,我们在萝卜中订阅相同名称的频道。 因此,我们的节点将仅接收发往它们的消息,而不会收听“整个广播”。
// sub.on('message', (channel:string, message:string)=> { io.to(channel).emit('message', message)) }) let UID:string|null = null; sock.on('auth', (uid:string)=> { UID = uid // - // UID sub.subscribe(UID) // sock.join(UID) }) sock.on('writeYourself', (message:string)=> { // , UID if (UID) pub.publish(UID, message) })
太棒了,现在我们可以确定节点仅收到针对他们的消息,仅此而已! 但是,应该注意的是,订阅本身现在要大得多,这意味着它们将吃掉年比岁的内存,以及更多的订阅/取消订阅操作,这些操作相对昂贵。 但是无论如何,这给我们带来了一定的灵活性,您甚至可以在此时停止并重新访问所有以前的选项,并且已经考虑了节点的新属性,即更具选择性,更纯洁的接收消息形式。 例如,节点可以订阅几个萝卜实例之一,并在推送时向所有实例发送消息:
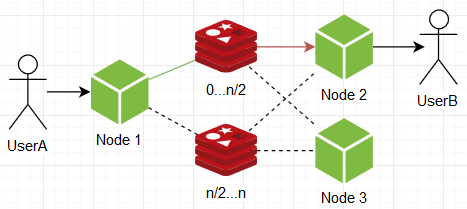
……但是,无论怎么说,它们仍然没有以合理的开销提供无限的可扩展性,您需要生出其他选择。 在某一时刻,我想到了以下方案:如果将萝卜实例分为A和B组,每个实例两个,该怎么办? 订阅时,节点由每个组中的一个实例签名,推送时,它们将消息发送到单个随机组的所有实例。
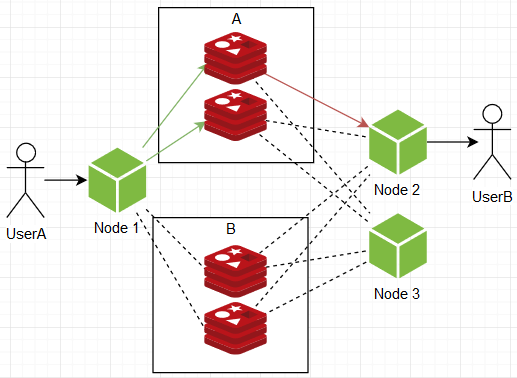
因此,我们实时获得了具有无限扩展潜力的运行结构,单个节点在任何时候的负载都不取决于系统的大小,因为:
- 总带宽在组之间分配,即,随着用户/活动的增加,我们仅比较其他组。
- 用户管理(订阅)在组内划分,即,当增加用户/订阅时,我们仅增加组内的实例数。
...一如既往,只有一个“ BUT”:获得的越多,获得下一个收益就需要越多的资源,在我看来,这是一个过高的折衷方案。
通常,如果您考虑一下,上述插件是由于不知道哪个用户位于哪个节点上而产生的。 好吧,的确,如果我们掌握了这些信息,就可以将消息推送到所需的位置,而不必进行不必要的重复。 我们一直在尝试做什么? 他们试图使系统无限扩展,同时又没有明确的寻址机制,这不可避免地会导致死胡同或不合理的冗余。 例如,您可以回忆起充当“通讯簿”的向导:
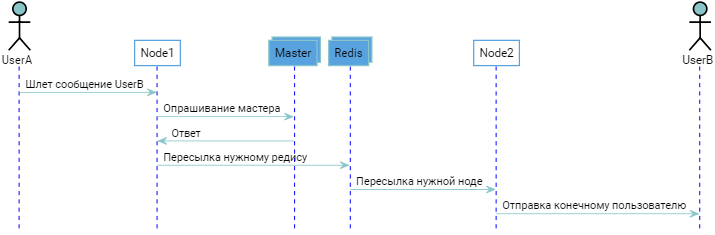
类似的事情告诉这个家伙:
为了获得用户的位置,我们进行了一次额外的往返,原则上可以,但是在我们的情况下不行。 似乎我们在往错误的方向挖掘,我们还需要其他一些东西...
哈希强度
有一个像哈希这样的东西。 它具有一定范围的值。 您可以从任何数据中获取它。 但是,如果在萝卜实例之间划分此范围,该怎么办? 好吧,我们获取用户ID,生成一个哈希,并取决于它被预订/推送到一个特定实例的范围。 也就是说,我们事先不知道哪个用户存在,但是收到它之后,我们可以放心地说它在n实例inf 100中。
function hash(val:string):number{/**/}// -, const clients:RedisClient[] = []// const uid = "some uid"// //, // const selectedClient = clients[hash(uid) % clients.length]
瞧! 现在,我们通常不依赖于单词的实例数,我们可以在不产生开销的情况下任意扩展规模! 好吧,说真的,这是一个绝妙的选择,唯一的不足是在更新萝卜实例的数量时需要完全重新启动系统。 有诸如标准环和分区环之类的东西可以让您克服这一点,但是它们不适用于消息传递系统。 好的,您可以进行在实例之间迁移订阅的逻辑,但是仍然要花费额外的一段难以理解的代码,而且我们知道-代码越多,错误越多,我们不需要它了,谢谢。 在我们的情况下,停机是可以接受的折衷方案。
您还可以查看RabbitMQ及其插件 ,该插件可让您执行与我们相同的操作,并且+提供了订阅的迁移(正如我上文所述-它与从头到脚的功能联系在一起)。 原则上,您可以将其安然入睡,但是如果有人为了进行实时调整而感到困惑,那么只会留下带有哈希环的功能。
将存储库充斥在github上。
它实现了我们所提供的最终版本。 此外,还有其他用于处理房间(对话框)的逻辑。
总的来说,我很满意,可以四舍五入。
合计
您可以做任何事情,但是有资源之类的东西,它们是有限的,因此您需要努力。
首先,我们完全不了解分布式系统如何以或多或少的具体模式工作,这很好。