现代硬件和编译器已经准备好将我们的代码颠倒过来,即使它的运行速度更快。 并且他们的制造商会小心地隐藏其内部厨房。 只要代码在一个线程中执行,一切都很好。
在多线程环境中,您可以强制观察有趣的事情。 例如,执行程序指令的顺序与源代码中的顺序不同。 同意,令人讨厌的是,逐行执行源代码只是我们的想象。
但是每个人都已经意识到,因为您必须以某种方式忍受它。 Java程序员甚至生活得很好。 因为Java具有内存模型-Java内存模型(JMM),它提供了用于编写正确的多线程代码的相当简单的规则。
这些规则对于大多数程序来说就足够了。 如果您不了解它们,但是想编写或想用Java编写多线程程序,那么最好尽快熟悉
它们 。 而且,如果您知道,但是您没有足够的背景信息,或者知道JMM的支腿从何而来很有趣,那么本文可以为您提供帮助。
追逐抽象
在我看来,有一个馅饼,或更合适的是有一个冰山。 JMM是冰山一角。 冰山本身就是水下多线程编程的理论。 冰山下是地狱。

冰山是一个抽象;如果泄漏,我们肯定会看到地狱。 尽管那里发生了很多有趣的事情,但在评论文章中,我们不会涉及到这一点。
在本文中,我对以下主题更感兴趣:
- 理论与术语
- JMM如何反映多线程编程理论
- 竞争性编程模型
多线程编程理论使您可以摆脱现代处理器和编译器的复杂性,可以模拟多线程程序的执行并研究其属性。 Roman Elizarov作了出色的
报告 ,目的是为理解JMM提供理论依据。 我向所有对此主题感兴趣的人推荐该报告。
为什么了解理论很重要? 在我看来,我只希望对我来说,一些程序员认为JMM是语言的复杂性,并且是多线程对某些平台问题的修补。 该理论表明,Java并不复杂,但可以简化并使其更可预测,非常复杂的多线程编程。
竞争与并发
首先,让我们看一下术语。 不幸的是,术语上尚无共识-在研究不同的材料时,您可能会遇到竞争和并发的不同定义。
问题在于,即使我们深入了解真相并找到这些概念的确切定义,也仍然不值得期望每个人对这些概念的含义都是相同的。 您
在这里
找不到目的。
Roman Elizarov在一份报告中,针对从业人员的并行编程理论表明,有时这些概念混杂在一起。 并行编程有时被称为一般概念,分为竞争性和分布式。
在我看来,在JMM的上下文中,您仍然需要将竞争和并行性分开,或者甚至理解有两种不同的范式,无论它们如何命名。
通常由Rob Pike引用,他将概念区分如下:
- 竞争是同时解决许多问题的一种方式
- 并发是执行单个任务的不同部分的一种方式。
罗伯·派克(Rob Pike)的观点不是标准,但在我看来,以此为基础进一步研究该问题很方便。 在
此处阅读有关差异的更多信息。
如果我们强调竞争性和并行程序的主要功能,则很有可能会对该问题有更深入的了解。 有很多迹象,认为是最重要的。
竞争的迹象。
- 存在多个控制流(例如,Java中的Thread,Kotlin中的协程),如果只有一个控制流,那么就不会有竞争性执行
- 非确定性结果。 结果取决于随机事件,实现以及同步的执行方式。 即使每个流都是完全确定性的,最终结果也将是不确定性的
并行程序将具有一组不同的功能。
- 可选具有多个控制流程
- 它可能导致确定性的结果,例如,如果将数组中的每个元素并行地乘以一个数,则将其乘以数字的结果不会改变
奇怪的是,可以在单个控制流上甚至在单核体系结构上并行执行。 事实是,我们习惯的任务(或控制流)级别的并行性并不是并行执行计算的唯一方法。
并发可以在以下级别进行:
- 位(例如,在32位计算机上,加法发生在一个动作中,并行处理32位数字的所有4个字节)
- 指令(在一个内核上,在一个线程中,尽管代码是顺序的,处理器仍可以并行执行指令)
- 数据(存在具有并行数据处理(单指令多数据)的体系结构,可以在大型数据集上执行一条指令)
- 任务(意味着存在多个处理器或内核)
指令级的并发性是对代码执行进行优化的一个示例,这些优化对程序员是隐藏的。
可以确保优化的代码在一个线程的框架内与原始代码等效,因为如果它不执行程序员的预期,则不可能编写适当且可预测的代码。
并非所有并行运行的内容都对JMM至关重要。 JMM中不考虑在单个线程内的指令级别上并发执行。
该术语非常不稳定,Roman Elizarov的演讲称为“从业者
并行编程理论”,尽管如果您坚持上述内容,那么关于竞争性编程的更多信息。
在JMM的上下文中,我将坚持竞争一词,因为竞争通常是关于一般状态的。 但是这里您需要注意不要固守术语,而是要了解存在不同的范例。
具有共同状态的模型:“操作旋转”和“之前发生”
Maurice Herlichi(《多处理器编程艺术》的作者)在他的
文章中写道,竞争性系统包含一系列通过共享内存进行通信的顺序过程(在理论上,它的含义与线程相同)。
通用状态模型包括带有消息传递的计算(共享状态是消息队列)和带有共享内存的计算(公共状态是内存中的结构)。
可以模拟每个计算。
该模型基于有限状态机。 该模型仅专注于共享状态,每个流的本地数据被完全忽略。 共享状态上的流的每个动作都是向新状态过渡的函数。
因此,例如,如果有4个线程将数据写入共享变量,那么将有4个函数转换为新状态。 将应用这些功能中的哪一个取决于系统中事件的时间顺序。
消息传递计算以类似的方式建模,只有状态和转换函数取决于发送或接收消息。
如果模型对您来说似乎很复杂,那么在示例中我们将对其进行修复。 这确实非常简单直观。 如此之多,以至于在不知道该模型是否存在的情况下,大多数人仍会按照该模型的建议来分析该程序。
这样的模型
通过交替操作被称为
性能模型(Roman Elizarov在报告中曾听到过这个名字)。
在直观性和自然性之间,您可以放心地写下模型的优势。 您可以使用关键字“
顺序一致性”和Leslie Lamport的
作品而疯狂。
但是,有关此模型有重要的说明。 该模型的局限性在于,对共享状态的所有操作都必须是瞬时的,并且操作不能同时发生。 他们说这样的系统具有
线性顺序 -系统中的所有动作都是有序的。
实际上,这不会发生。 该操作不会立即发生,而是以一定间隔执行;在多核系统上,这些间隔可以相交。 当然,这并不意味着该模型在实践中是无用的,您只需要为其使用创建某些条件即可。
同时,请考虑另一个
模型-“之前发生” ,该
模型不关注状态,而是关注执行(历史)期间的读写存储单元集及其关系。
该模型说,不同流中的事件不是瞬时的和原子的,而是并行的,并且不可能在它们之间建立顺序。 多处理器或多核体系结构上的流中的事件(写入和读取共享数据)实际上是并行发生的。 系统中没有全局时间的概念,我们无法理解某个操作何时结束而另一操作何时开始。
在实践中,这意味着我们可以在一个线程中将一个值写入一个变量,然后在早晨执行此操作,然后在晚上将其从另一个线程中读取该变量的值,而不能说我们肯定会在早晨读取该值。 从理论上讲,这些操作是并行进行的,尚不清楚何时结束和开始另一操作。
很难想象结果是在一天的不同时间执行的简单读取和写入操作是同时发生的。 但是,如果您考虑一下,当我们无法保证会看到录制的结果时,发生读写事件对我们来说真的不重要。
而且我们真的看不到记录的结果,即 在流
P中,将其写入值为
0的变量中
,我们将写入
1 ,在流
Q中 ,将读取此变量。 不管录制后经过多少物理时间,我们仍然可以读取
0 。
这就是计算机的工作方式,模型反映了这一点。该模型是完全抽象的,需要方便的可视化以方便工作。 对于可视化,并且仅对此可视化,使用具有全局时间的模型,但保留的是在证明程序的属性时不使用全局时间。 在可视化中,每个事件都表示为具有开始和结束的时间间隔。
我们发现,事件是并行发生的。 但是,系统仍然具有
部分顺序 ,因为存在一些特殊的事件对,它们具有一定的顺序,在这种情况下,他们说这些事件具有“先于发生”的关系。 如果您首先听说过“以前发生过的”关系,那么可能知道这种关系会安排事件这一事实对您没有多大帮助。
尝试分析Java程序
我们考虑了一些理论上的最低要求,让我们继续尝试并考虑来自具有共同可变状态的两个线程的特定语言-Java的多线程程序。
一个经典的例子。
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
我们需要模拟该程序的执行并获得所有可能的结果-变量x和y的值。 正如我们从理论上回忆的那样,将会有几个结果,这样的程序是不确定的。
我们将如何建模? 我立即想使用操作的交错模型。 但是“之前发生”的模型告诉我们,一个线程中的事件与另一线程中的事件并行。 因此,如果操作之间没有“先发生”的关系,则此处的交替操作模型是不合适的。
每个线程的执行结果始终是确定的,因为一个线程中的事件始终是有序的,请考虑将它们免费获得“先发生”关系。 但是,不同流程中的事件如何才能获得“之前发生”的关系并不完全清楚。 当然,这种关系在模型中形式化,整个模型是用数学语言编写的。 但是,在实践中如何用一种特定的语言处理该方法,尚无法立即理解。
有哪些选择?
忽略约束并模拟交织。 您可以尝试一下,也许不会发生任何不好的情况。
为了了解可以得到什么样的结果,我们简单地列举所有可能的执行变体。
所有可能的程序执行都可以表示为有限状态机。
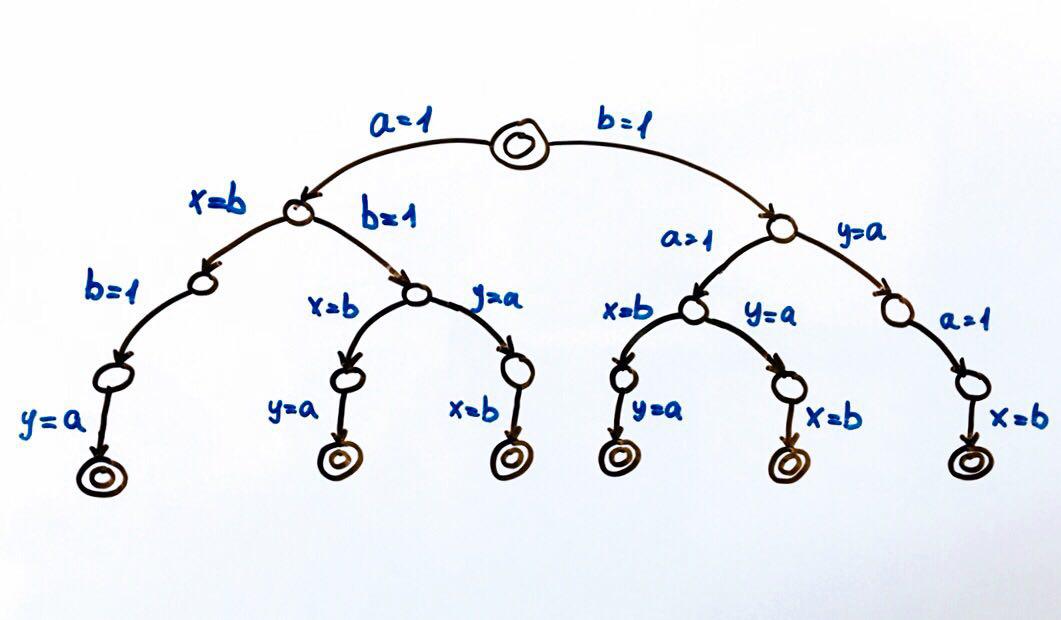
每个圆都是系统的状态,在我们的例子中,变量
a,b,x,y是 。 过渡功能是对状态的操作,它将系统置于新状态。 由于两个流程可以对一般状态执行操作,因此从每个状态会有两次转换。 双圆圈是系统的最终状态和初始状态。
总共可能有6种不同的执行方式,从而产生成对的x,y值:
(1, 1), (1, 0), (0, 1)
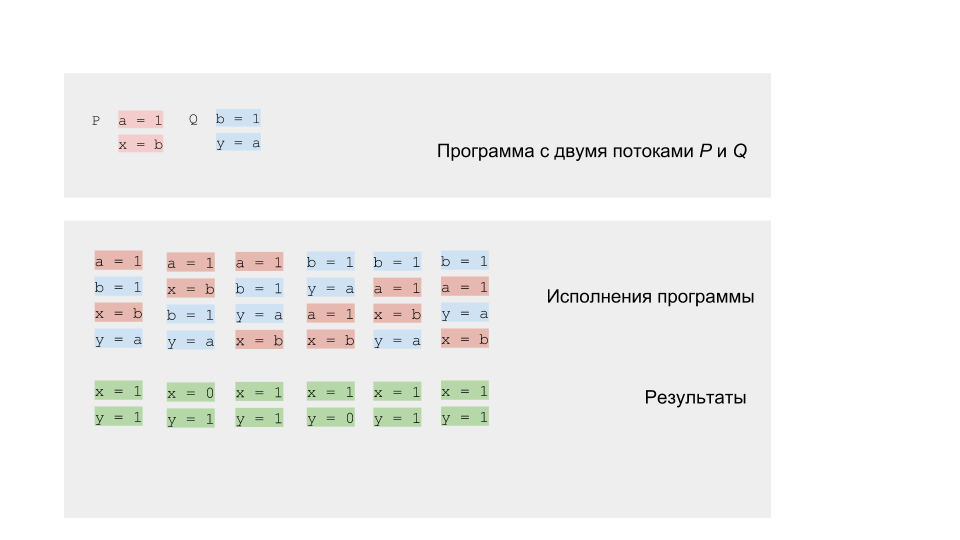
我们可以运行该程序并检查结果。 由于符合竞争性计划,因此将产生不确定性的结果。
为了测试竞争性程序,最好使用特殊工具(
tool ,
report )。
但是您可以尝试运行该程序数百万次,甚至更好,编写一个可以为我们完成此任务的循环。
如果我们在单核或单处理器体系结构上运行代码,则应从期望的集合中获得结果。 旋转模型可以正常工作。 在多核体系结构(例如x86)上,我们可能会对结果感到惊讶-我们可以得到结果(0,0),这与我们的建模不符。
有关此问题的说明,可以在Internet上通过关键字
re -
ordering找到 。 现在,重要的是要了解,
在无法确定访问共享状态的顺序的情况下 ,
交织建模确实不适合 。
竞争编程理论与JMM
现在是时候仔细研究一下“之前发生过的”关系以及它如何与JMM成为朋友。 “之前发生”关系的原始定义可以在分布式系统中的时间,时钟和事件顺序中找到。
语言记忆模型有助于确定具有竞争力的代码,因为它确定哪些操作与“之前发生”有关。
规范中的“发生之前的订单”部分提供了此类操作的列表。 实际上,本节回答了这个问题-在什么条件下我们将看到另一个流中的记录结果。
JMM中有各种订单。 阿列克谢·希普列夫(Alexei Shipilev)在他的
一份报告中非常积极地谈论了规则。
在全局时间模型中,同一线程中的所有操作均按顺序进行。 例如,写和读变量的事件可以表示为两个间隔,然后模型保证这些间隔在单个流的框架内永远不会相交。 在JMM中,此顺序称为程序顺序(
PO )。
PO将动作绑定在单个线程中,并且不说执行顺序,只谈论源代码中的顺序。 这足以保证
每个流的确定性 。
PO可以视为原始数据。
PO总是很容易在程序中排列-单个流中源代码中的所有操作(线性顺序)都将具有
PO 。
在我们的示例中,我们得到如下内容:
P: a = 1 PO x = b写入a而读取b具有PO顺序
Q: b = 1 PO y = a写入b并读取a具有PO顺序
我监视了这种写作形式
w(a,1)PO r(b):0。我真的希望没有人为报告申请专利。 但是,规范具有类似的形式。
但是每个线程单独对我们来说并不是特别有趣,因为线程具有共同的状态,我们对流的交互更感兴趣。 我们想要做的就是确保在其他线程中看到变量的记录。
让我提醒您,这对我们而言并不可行,因为在不同流中写入和读取变量的操作不是瞬时的(分别是相交的段),因此无法解析操作的开始和结束位置。
这个想法很简单-当我们读取流
Q中的变量a时,流
P中相同变量的记录可能尚未结束。 而且,无论这些事件共享多少物理时间-一纳秒或几个小时。
要订购事件,我们需要“之前发生”的关系。 JMM定义了这种关系。 规范将顺序固定在一个线程中:
如果操作x和y在同一线程中并且在PO中 ,则首先发生x,然后是y,则x发生在y之前。
展望未来,我们可以说可以将所有
PO替换为Happens-before(
HB ):
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
但是,我们再次回到一个流的框架中。 在不同线程中发生的操作之间可能会出现
HB ,为应对这些情况,我们将结识其他命令。
同步顺序(
SO )-链接同步操作(
SA ),在规范的17.4.2节中给出了
SA的完整列表。 动作 以下是其中一些:
- 读取volatile变量
- 编写volatile变量
- 监控锁
- 解锁监视器
SO对我们很有趣,因为它具有
SO顺序中的所有读数都可以看到
SO中的最后一个条目的特性。 我提醒您,我们只是在实现这一目标。
在这个地方,我将重复我们正在努力的事情。 我们有一个多线程程序,我们想模拟所有可能的执行并获得它可以提供的所有结果。 有一些模型可以很简单地做到这一点。 但是它们要求对共享状态的所有操作进行排序。
根据
SO属性-如果程序中的所有动作都是
SA,那么我们将实现我们的目标。 即 我们可以为所有变量设置
volatile修饰符 ,并且可以使用交替模型。 如果直觉告诉您这是不值得的,那么您绝对正确。 通过这些操作,我们只是禁止对代码进行优化,当然,有时候这是一个不错的选择,但这绝对不是一般情况。
考虑另一个与命令同步(
SW )-SO命令,用于特定的解锁/锁定,写入/读取易失性对。 这些动作流入什么流都没有关系,主要是它们在同一监视器上,易变变量。
SW提供了线程之间的桥梁。
现在,我们得出了最有趣的顺序-事前发生(
HB )。
HB是
SW和
PO的并集的传递闭包。
PO在流中给出线性顺序,
SW在流之间提供桥梁。
HB是可传递的,即 如果
x HB y y HB z, x HB z
在规范中,有一个
HB关系列表,可以更详细地找到它,以下是一些列表:
在单个线程中,任何操作都发生在源代码中紧随其后的任何操作之前。
在同一监视器上输入同步块/方法之前,要退出同步块/方法。
在读取相同的
易失性字段之前,先写
易 失性字段。
让我们回到我们的例子:
P: a = 1 PO x = b Q: b = 1 PO y = a
让我们回到示例,尝试分析程序,并考虑订单。
使用JMM对程序进行分析是基于提出任何假设并确认或反驳它们。
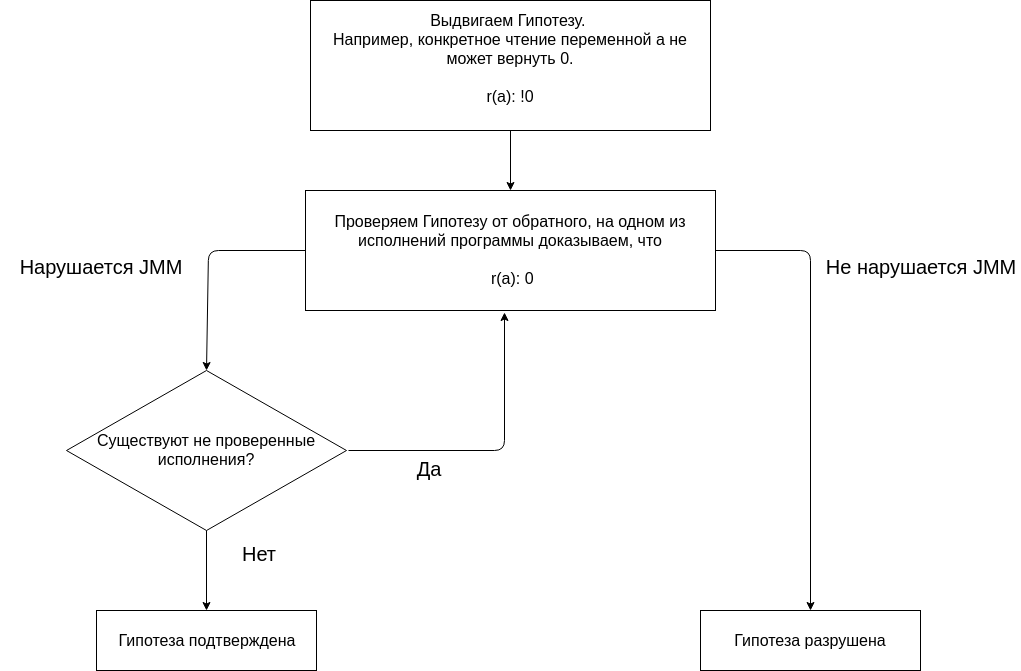
我们以没有单个程序执行会给出结果(0,0)的假设开始分析。 所有执行中都没有结果(0,0)是程序的假定属性。
我们通过建立不同的执行方式来检验假设。
我在
这里发现了该术语(有时会显示它而不是
…带箭头
…字
race ,Alexey自己在报告中使用了箭头和字种族,但警告说JMM中不存在此顺序,为了清楚起见使用了此表示法)。
我们做了一点保留。
由于对公共变量的所有操作对我们都很重要,因此在示例中,公共变量为
a,b,x,y 。 然后,例如,必须将操作x = b视为r(b)和w(x,b),并且
r(b) HB w(x,b) (基于
PO )。 但是由于变量x不会在线程中的任何地方读取(在代码末尾以打印方式读取并不有趣,因为在线程上执行join操作后,我们将看到值x),因此我们无法考虑操作w(x,b)。
检查第一场演出。
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
在流
Q中,我们读取变量a,并将其写入流
P中。 读写之间没有顺序
(PO,SW,HB) 。
如果变量是在一个线程中写入的,而读取是在另一个线程中的,并且操作之间没有
HB关系,则他们说该变量是在竞速下读取的。 在根据JMM进行的比赛中,我们可以读取
HB中最后记录的值,也可以读取任何其他值。
这样的表现是可能的。 执行
不违反JMM 。 读取变量a时,您可以看到任何值,因为读取是在种族下进行的,因此不能保证我们将看到动作w(a,1)。 这并不意味着程序可以正常运行,而仅意味着可以预期得到这样的结果。
考虑到执行的其余部分是没有意义的,因为该
假设已被破坏 。
JMM说,如果程序没有数据争用,那么所有执行都可以视为顺序执行。 让我们摆脱竞争,为此,我们需要简化不同线程中的读取和写入操作。 重要的是要了解,与顺序程序相比,多线程程序具有多个执行。 并且为了说一个程序具有任何属性,需要证明该程序不是在一个执行中而是在所有执行中都具有此属性。
为了证明该程序是非竞赛的,您需要针对所有表演进行此操作。 让我们尝试使
SA并使用
volatile修饰符标记变量a。 易变变量将以v为前缀。
我们提出
了一个新的假设 。 如果将变量a设置为
volatile ,则没有程序执行将给出结果(0,0)。
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
执行
不违反JMM 。 读va发生在种族之下。 任何种族都会破坏HB的传递性。
我们提出
了另一个假设 。 如果将变量b设置为
volatile ,则没有程序执行将给出结果(0,0)。
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
执行不违反JMM。 种族下会出现阅读a的情况。
让我们
测试一下假设 ,如果变量a和b是
volatile ,那么没有程序执行将给出结果(0,0)。
检查第一场演出。
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
由于
SA程序中的所有动作(特别是读取或写入
volatile变量),因此我们获得了所有动作之间的完整
SO顺序。 这意味着r(va)应该看到w(va,1)。 此
执行违反JMM 。
有必要进行下一个执行以确认假设。 但是由于任何执行都会有
SO ,因此您可以偏离形式主义-很明显,任何执行的结果(0,0)都违反了JMM。
要使用旋转模型,您需要为变量a和b添加
volatile 。 这样的程序将给出结果(1,1),(1,0)或(0,1)。
最后,我们可以说非常简单的程序非常易于分析。
但是,具有大量执行和共享数据的复杂程序很难分析,因为您需要检查所有执行。
其他竞争执行模型
为什么要考虑其他竞争性编程模型?
使用线程和同步原语可以解决所有问题。 都是如此,但是问题是我们检查了十几行代码的示例,其中四行代码可以完成有用的工作。
在那里,我们遇到了一堆问题,直到没有规范我们甚至无法正确计算所有可能的结果。 线程和同步原语是一件非常困难的事情,在某些情况下使用它当然是合理的。 基本上,这些情况与性能有关。
抱歉,我经常提及Elizarov,但是如果一个人真的有这个领域的经验,该怎么办。 因此,他还有另一个精彩的
报告, “纯Java每秒百万报价”,其中他说一个不变的状态是好的,但是抱歉,我不会将我的百万报价复制到每个流中。 但并非所有人都有数以百万计的引号,当然还有许多引号的任务比较适中。 有没有任何竞争性的编程模型可以让您忘记JMM并仍然编写安全的,竞争性的代码?
如果您真的对这个问题感兴趣,我强烈推荐Paul Butcher的书“七周内的七个竞争模型”。 我们揭示了流程的秘密。” 不幸的是,无法找到有关作者的足够信息,但是这本书应该使您对新范式敞开心eyes。 不幸的是,我没有许多其他竞争模型的经验,因此我从本书获得了评论。
回答以上问题。 据我了解,有一些竞争性编程模型可以至少大大减少对JMM细微差别知识的需求。 但是,如果存在可变的状态和线程,那么您没有在它们上面拧上什么抽象,那么仍然会有一个地方,这些线程应该同步对状态的访问。 另一个问题是您可能不必自己同步访问,例如,一个框架可以解决这个问题。 但是正如我们已经说过的,迟早会发生抽象。
您可以完全排除可变状态。 在函数式编程领域,这是正常的做法。 如果没有可变结构,那么按照定义,共享内存可能不会有问题。 JVM上有功能语言的代表,例如Clojure。 Clojure是一种混合功能语言,因为它仍然允许您更改数据结构,但是为此提供了更有效,更安全的工具。
函数式语言是使用竞争性代码的绝佳工具。 就我个人而言,我不使用它,因为我的活动领域是移动开发,而那里根本不是主流。 尽管可以采用某些方法。
处理可变数据的另一种方法是防止数据共享。 参与者就是这样的编程模型。 Actor通过不允许同时访问数据来简化编程。 这是通过这样的事实来实现的:一个功能在某一时刻执行工作只能在一个线程中工作。
但是,演员可以更改内部状态。 鉴于在下一个时刻,可以在另一个线程上执行相同的参与者,所以这可能是个问题。 该问题可以通过不同的方法来解决,例如在Erlang或Elixir等编程语言中,参与者模型是该语言的组成部分,您可以使用递归调用具有新状态的参与者。
在Java中,递归可能过于昂贵。 但是,在Java中,有一些使用该模型的便捷框架,可能最受欢迎的是Akka。 Akka开发人员已经处理了所有事情,您可以转到
Akka的文档部分
和Java内存模型,并阅读大约两种情况,它们可能从不同的线程访问共享状态。 但更重要的是,文档指出哪些事件与“之前发生”有关。 即 这意味着我们可以根据需要随意更改actor的状态,但是当我们收到下一条消息并可能在另一个线程中对其进行处理时,我们可以保证看到在另一个线程中所做的所有更改。
为什么线程模型如此流行?
我们研究了竞争性编程的两种模型,实际上,还有更多模型使竞争性编程更容易,更安全。
但是,为什么线程和锁仍然如此流行呢?
我认为原因是这种方法的简便性,当然,一方面,很容易在数据流中犯下许多不明显的错误,使自己陷入困境等等。 但是另一方面
,流程没有什么复杂的,尤其是如果您不考虑后果的话 。
在某个时间点,内核可以执行一条指令(实际上,并发存在于指令级别,但是现在已经无关紧要了),但是由于多任务处理,即使在单核计算机上,也可以同时执行多个程序(当然也可以同时执行伪指令)。
为了使多任务工作,您需要竞争。 正如我们已经知道的那样,没有几个管理流程就不可能进行竞争。
您认为运行在四核手机处理器上的程序需要多少个线程,并且需要尽可能快且响应迅速?
可能有几十个。 现在的问题是,为什么在需要在同一时间仅执行2-4个线程的硬件上运行的程序需要这么多线程?
要尝试回答这个问题,假设只有我们的程序正在设备上运行,而没有其他任何运行。 我们将如何管理提供给我们的资源?
您可以为用户界面提供一个内核,为其他任务提供内核的其余部分。 , , , .
?
Java , , - . , , .
, ( ), , — . , , , Java.
Java , , , Executors, . , . , , .
, , , .
Erlang Clojure , , . , .
结论
JVM, , . . , . , , .
.
JMM . , JMM .
, . JMM, , . , JMM, .
录像带除了上述人士的讲话外,还请注意学术录像带。