本文是原始帖子的授权翻译。 翻译是在PVS-Studio的帮助下完成的。 谢谢你们!鼓励我写这篇文章的原因是大量有关静态分析的材料,最近越来越多地使用这种材料。 首先,这是
PVS-Studio的
博客 ,该
博客积极地宣传自己在开源项目中通过其工具发现的错误对Habr的评论。 PVS-Studio最近实现了对
Java的支持 ,当然,来自IntelliJ IDEA的开发人员也无法幸免,其内置分析器可能是当今Java最先进的分析器。
阅读这些评论时,我感觉到我们在谈论神奇的长生不老药:单击按钮,就在这里-眼前的缺陷列表。 看来,随着分析仪变得越来越先进,将发现越来越多的错误,并且由这些机器人扫描的产品会变得越来越好,而无需我们付出任何努力。
好吧,但是没有魔药。 我想谈谈在“我们的机器人可以找到的东西”之类的帖子中通常不讲的内容:分析器无法执行的操作,它们在软件交付过程中的真正作用和位置以及如何实现分析正确。
 棘齿(来源: Wikipedia )。
棘齿(来源: Wikipedia )。静态分析仪将永远无法做到
从实际角度分析源代码是什么? 我们获取源文件,并在短时间内(比运行的测试要短得多)获得一些有关系统质量的信息。 原则上和数学上无法克服的局限性在于,这种方式我们只能回答关于被分析系统的非常有限的问题子集。
一项最著名的任务示例(无法使用静态分析解决)是一个
停顿的问题 :这是一个定理,证明一个人无法制定出通用算法,该算法将定义具有给定源代码的程序是永久循环还是完成最后的时间。 该定理的扩展是
赖斯定理 ,声称对于可计算函数的任何非平凡属性,确定给定程序是否使用该属性计算函数的问题在算法上是无法解决的。 例如,您不能编写一个分析器,该分析器根据源代码确定所分析的程序是否是特定算法的实现,例如,一种计算整数的算法。
因此,静态分析仪的功能具有不可克服的局限性。 如果没有
void安全性 ,静态分析器将永远无法检测到所有情况,例如语言中的“空指针异常”错误。 或检测动态类型语言中所有出现的“找不到属性”。 最完美的静态分析器所能做的就是捕捉特定情况。 毫不夸张地说,在您的源代码可能出现的所有问题中,它们的数目是沧海一粟。
静态分析不是查找错误
从以上得出的结论是:静态分析不是减少程序中缺陷数量的方法。 我敢宣称以下几点:首先应用到您的项目中,它将在代码中找到“有趣的”位置,但是很可能不会发现任何会影响程序质量的缺陷。
分析器自动发现的缺陷示例令人印象深刻,但是我们不要忘记,这些示例是通过对照相对简单的规则集扫描大量代码库而发现的。 以同样的方式,黑客有机会在大量帐户中尝试几个简单的密码,最终找到具有简单密码的帐户。
这是否意味着没有必要应用静态分析? 当然不是! 出于与您要验证非安全密码的停止列表中的每个新密码相同的原因,应应用该密码。
静态分析比查找错误更重要
实际上,在实践中可以通过分析解决的任务要广泛得多。 因为通常来说,静态分析表示对源代码的任何检查,是在运行源代码之前进行的。 您可以执行以下操作:
- 从最广义的角度检查编码样式。 它既包括格式检查,也包括空/不必要括号的使用搜索,阈值设置(例如,行数/方法的圈复杂度)等指标-所有这些使代码的可读性和可维护性复杂化。 在Java中,Checkstyle在Python-
flake8表示具有这种功能的工具。 这样的程序通常称为“ lints”。 - 不仅可执行代码可以分析。 可以(并且必须!)自动检查JSON,YAML,XML和
.properties文件等资源的有效性。 这样做的原因是,比起在测试执行期间或在运行期间,最好找出这样一个事实,例如,在拉取请求的自动检查的早期阶段,由于未配对的引号导致JSON结构被破坏,因此不是是吗 有一些相关工具,例如YAMLlint , JSONLint和xmllint 。 - 编译(或解析为动态编程语言)也是一种静态分析。 通常,编译器可以发出警告,指出有关源代码质量问题的警告,因此不应忽略它们。
- 有时,编译不仅适用于可执行代码。 例如,如果您拥有AsciiDoctor格式的文档,则在将其编译为HTML / PDF的过程中,AsciiDoctor( Maven插件 )可能会发出警告,例如,内部链接损坏。 这是不接受文档更改而接受拉取请求的重要原因。
- 拼写检查也是一种静态分析。 aspell实用程序不仅可以检查文档中的拼写,而且还可以检查包括C / C ++,Java和Python在内的各种编程语言的程序源代码(注释和文字)。 用户界面或文档中的拼写错误也是一个缺陷!
- 配置测试实际上代表了一种静态分析,因为即使配置测试是作为
pytest单元测试执行的,它们也不会在执行过程中执行源代码。
如我们所见,在此列表中,错误的搜索作用最不重要,使用免费的开放源代码工具时,其他所有功能都可用。
您的项目中应使用哪种静态分析类型? 当然,越多越好! 此处重要的是适当的实现,将在后面进行讨论。
作为多级过滤器的输送管道和第一阶段的静态分析
具有变更流(从源代码的变更到生产交付)的管道是持续集成的经典隐喻。 该管道的标准阶段顺序如下所示:
- 静态分析
- 合编
- 单元测试
- 整合测试
- UI测试
- 手动验证
在管道的第N阶段拒绝的更改不会在第N +1阶段通过。
为什么这样而不是其他呢? 在涉及测试的管道部分中,测试人员会认识到众所周知的测试金字塔:
 测试金字塔。 资料来源:马丁·福勒(Martin Fowler) 的文章 。
测试金字塔。 资料来源:马丁·福勒(Martin Fowler) 的文章 。在此金字塔的底部,有一些易于编写的测试,这些测试执行得更快,并且不会产生误报。 因此,应该有更多的代码,它们应该覆盖大多数代码,并且应该首先执行。 在金字塔的顶部,情况恰好相反,因此应将集成和UI测试的数量减少到必要的最低限度。 此链中的人员是最昂贵,最慢且最不可靠的资源,因此他们位于最末端,只有在前面的步骤没有发现任何缺陷的情况下,他们才能进行工作。 在与测试无关的部分中,管道是按照相同的原理构建的!
我想以多级水过滤系统的形式提出类比。 输入中提供了脏水(有缺陷的变化),作为输出,我们需要获得纯净水,其中不会包含所有不想要的污染物。
 多级过滤器。 资料来源: Wikimedia Commons
多级过滤器。 资料来源: Wikimedia Commons如您所知,净化过滤器的设计使每个后续阶段都能够去除较小尺寸的污染物颗粒。 粗纯化的输入级具有更高的通量和更低的成本。 在我们的类比中,这意味着输入质量的门具有更高的性能,需要更少的启动工作并具有更少的运营成本。 静态分析的作用(如我们现在所了解的)仅能清除最严重的缺陷,而油底壳过滤器作为多级净化器的第一级,其作用是。
静态分析本身并不能提高最终产品的质量,就像“集水槽”不能使饮用水一样。 然而,与其他管道元素一起使用,其重要性显而易见。 即使在多级过滤器中,输出级也可能消除输入级中的所有内容-我们知道,尝试仅使用精制纯化级而没有输入级时会产生的后果。
“集液槽”的目的是从捕获非常粗糙的缺陷中卸载后续阶段。 例如,执行代码检查的人员不应因代码格式错误和违反代码标准而分心(例如多余的括号或嵌套太深的分支)。 诸如NPE之类的错误应通过单元测试捕获,但如果在此之前分析仪指出不可避免地会出现错误,则将大大加快其修复速度。
我想现在很清楚,为什么偶尔使用静态分析并不能提高产品质量,而必须连续应用静态分析来过滤具有严重缺陷的变更。 使用静态分析仪是否会提高产品质量的问题大致等同于“如果我们从脏池塘取水,经过漏勺后其饮用质量会提高吗?”这一问题。
旧版项目简介
一个重要的实际问题:作为“质量门”,如何在持续集成过程中实施静态分析? 如果是自动化测试,那么一切都非常清楚:有一组测试,其中任何一个测试的失败都是一个充分的理由,可以相信构建没有通过质量门。 尝试通过静态分析的结果以相同的方式设置门操作失败:遗留代码上的分析警告过多,您不想完全忽略它们,另一方面,仅由于以下原因就无法停止产品交付:里面有分析仪警告。
对于任何项目,分析仪都会在第一次发出大量警告。 大多数警告与产品的正常功能无关。 全部修复都是不可能的,其中许多根本不需要修复。 最后,我们知道我们的产品甚至在引入静态分析之前就可以正常工作!
结果,许多开发人员只能通过偶尔使用静态分析或仅以信息模式使用自己来限制自己,该模式涉及在构建项目时获取分析器报告。 这相当于没有进行任何分析,因为如果我们已经有很多警告,则在更改代码时仍不会注意到另一个警告的出现(无论多么严重)。
以下是质量门介绍的已知方法:
- 设置警告总数或警告总数的限制,除以代码行数。 它的工作效果很差,因为这样的门会使带有新缺陷的更改一直通过,直到超出其限制为止。
- 在一段时间内将代码中的所有旧警告标记为忽略,并在出现新警告时构建失败。 可以通过PVS-Studio和其他一些工具(例如Codacy)提供此类功能。 我没有碰巧与PVS-Studio合作。 就我对Codacy的经验而言,它们的主要问题是新旧错误的区分是一种复杂且并不总是有效的算法,尤其是在文件发生重大更改或重命名的情况下。 据我所知,Codacy可能会在请求请求中忽略新的警告,同时由于警告而与该PR代码的更改无关,会阻止请求请求。
- 我认为,最有效的解决方案是“ 持续交付 ”书中介绍的“棘轮”方法。 基本思想是,静态分析警告的数量是每个发行版的属性,并且仅允许进行此类更改,而这不会增加警告的总数。
棘轮
它的工作方式如下:
- 在初始阶段,在版本元数据中添加了有关代码分析器发现的许多警告的条目。 因此,在构建主分支时,不仅在存储库管理器中编写了“版本7.0.2”,而且还编写了“版本7.0.2,其中包含100500 Checkstyle-warnings”。 如果您使用的是高级存储库管理器(例如Artifactory),则很容易保留有关您的发行版的此类元数据。
- 构建时,每个拉取请求都会将结果警告的数量与其当前版本中的警告数量进行比较。 如果PR导致此数字增加,则代码不会通过静态分析的质量门。 如果警告数量减少或未更改-则通过。
- 在下一个版本中,重新计算的数字将再次写入元数据。
因此,缓慢但可靠地,警告的数量将收敛为零。 当然,可以通过引入新的警告并更正他人的警告来欺骗该系统。 这是正常的,因为从长远来看,它会产生结果:警告是固定的,通常不是一个接一个地固定,而是按某种类型的组固定,并且所有容易解决的警告都可以很快解决。
此图显示了
我们的
一个OpenSource项目在六个月内发生此类“棘轮事件”时发出的Checkstyle警告总数。 警告的数量已大大减少,并且自然而然地发生在产品开发的同时!
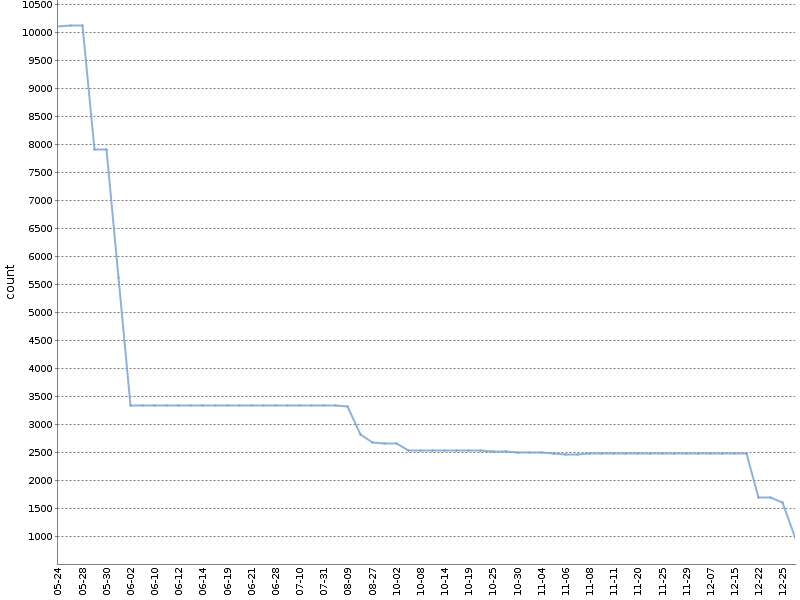
我应用了此方法的修改版本。 我分别为不同的项目模块和分析工具计算警告。 包含有关构建的元数据的YAML文件是这样构成的:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
在任何高级CI系统中,可以为任何静态分析工具实现“棘轮”功能,而无需依赖插件和第三方工具。 每个分析仪都以简单的文本或XML格式发布报告,可以轻松对其进行分析。 此后唯一要做的就是用CI脚本编写所需的逻辑。 您可以
在这里或
这里窥见并在基于Jenkins和Artifactory的源项目中实现它。 这两个示例都依赖于
ratchetlib库:方法
countWarnings()以通常的方式对Checkstyle和Spotbugs生成的文件中的xml标记进行计数,而
compareWarningMaps()实现该棘轮,如果在以下任何情况下发出警告,则抛出错误类别在增加。
“棘轮”实现的一种有趣方式是可以使用aspell分析注释,文本文字和文档的拼写。 如您所知,在检查拼写时,并非标准词典中未知的所有单词都不正确,因此可以将其添加到自定义词典中。 如果将自定义词典作为源代码项目的一部分,则可以按以下方式制定拼写的质量门:使用标准和自定义词典运行aspell
应该不会发现任何拼写错误。
修复分析器版本的重要性
总之,有必要注意以下几点:无论选择哪种方式在交付管道中引入分析,分析器的版本都必须是固定的。 如果让分析器自发更新,那么在构建另一个请求时,可能会出现新的缺陷,这些缺陷与更改的代码无关,而是与新的分析器能够检测到更多缺陷有关。 这将中断您的拉取请求验证过程。 分析仪升级必须是自觉的。 无论如何,每个构建组件的固定版本固定是一个通用要求,也是另一个主题的主题。
结论
- 静态分析不会发现错误,也不会因为单次运行而提高产品质量。 只有在交付过程中持续运行才能产生积极的效果。
- 搜寻错误根本不是主要的分析目标。 开源工具提供了绝大多数有用的功能。
- 通过使用传递代码的“棘轮”,在交付管道的第一阶段通过静态分析的结果介绍质量门。
参考文献
- 持续交付
- Alexey Kudryavtsev:程序分析:您是一名优秀的开发人员吗? 报告不同的代码分析方法,而不仅仅是静态!
原始文章讨论摘录
叶夫根尼(Evgeniy Ryzhkov)伊凡(Ivan),感谢您的文章并帮助我们开展工作,这是为了普及静态代码分析技术。 绝对正确的是,如果PVS-Studio博客中的文章不成熟,可能会影响它们并得出如下结论:“我将只检查一次代码,更正错误,那样就可以了。” 这是我的个人痛苦,多年来我一直不知道该如何克服。 事实是关于项目检查的文章:
- 在人中引起惊叹的效果。 人们喜欢阅读诸如Google,Epic Games,Microsoft和其他公司之类的公司的开发人员有时失败的经历。 人们喜欢认为任何人都可能犯错,即使行业领导者也会犯错。 人们喜欢阅读此类文章。
- 此外,作者可以撰写有关该流程的文章,而不必费力地思考。 当然,我不想冒犯我们撰写这些文章的人。 但是,每次撰写新文章都比撰写一篇有关项目检查的文章要难得多(将许多错误,几个笑话与独角兽图片混合在一起)。
您写了一篇很好的文章。 我也有关于该主题的几篇文章。 其他同事也是如此。 此外,我以主题为“静态代码分析的哲学”的报告访问了多家公司,其中我在谈论的是过程本身,而不是特定的错误。
但是不可能写10篇有关该过程的文章。 好吧,要推广我们的产品,我们需要定期写很多东西。 我想用另外的评论来评论文章中的其他几点,以使讨论更加方便。
这篇简短的
文章是关于“静态代码分析哲学”的,这是我拜访不同公司时的主题。
伊万·波诺马列夫(Ivan Ponomarev)叶夫根尼(Evgeniy),非常感谢您对本文进行的有益评论! 是的,您在帖子中完全正确地担心了对“未成熟思想”的影响!
这里没有人要怪,因为有关
分析仪的文章/报告的作者并非旨在撰写有关
分析的文章/报告。 但是,在
Andrey2008和
lany最近发表了
几篇文章
之后 ,我决定我再也不能保持沉默了。
叶夫根尼(Evgeniy Ryzhkov)如上所述,伊凡(Ivan)将对本文的三点进行评论。 这意味着我同意那些观点,但我不予评论。
1.
该管道的标准阶段顺序如下所示...我不同意第一步是静态分析,而只有第二步是编译。 我认为,平均而言,编译检查比立即执行“更重”的静态分析更快,更逻辑。 如果您有其他看法,我们可以讨论。
2.
我没有碰巧与PVS-Studio合作。 就我对Codacy的经验而言,它们的主要问题是新旧错误的区分是一种复杂且并不总是有效的算法,尤其是在文件发生重大更改或重命名的情况下。在PVS-Studio中,它非常方便。 这是产品的杀手级功能之一,不幸的是,很难在文章中进行描述,这就是为什么人们对此产品不太熟悉的原因。 我们收集有关基准中现有错误的信息。 不仅是“文件名和行”,还有其他信息(三行的哈希标记-当前,上一个,下一个),以便在移动代码片段的情况下,我们仍然可以找到它。 因此,当进行较小的修改时,我们仍然知道这是一个旧错误。 分析仪也不会抱怨它。 现在有人可能会说:“好吧,如果代码进行了很多更改,那将无法正常工作,而您会抱怨它好像是新编写的吗?” 是的 我们抱怨。 但这实际上是新代码。 如果代码发生了很大变化,则这是新代码,而不是旧代码。
借助此功能,我们亲自参与了1000万行C ++代码的项目实施,每天都有大量开发人员对其“感动”。 一切顺利。 因此,我们建议向在其过程中引入静态分析的任何人使用PVS-Studio的此功能。 对于我来说,根据发布来固定警告数量的选项似乎不太合适。
3.
无论选择哪种方式介绍交付管道分析,都必须修复分析器版本我不同意这一点。 这种方法的绝对对手。 我建议以自动模式更新分析仪。 随着我们添加新的诊断程序并改进旧的诊断程序。 怎么了 首先,您将收到有关新的实际错误的警告。 其次,如果我们克服了一些旧的误报,这些误报可能会消失。
不更新分析器与不更新防病毒数据库(“如果它们开始通知病毒的情况”)相同。 在这里我们将不讨论防病毒软件整体的真正用途。
如果在升级分析器版本后,您有许多新警告,则通过该功能禁止显示警告,如我上文所述。 但不要更新版本...通常,此类客户端(肯定有一些)多年来不会更新分析器版本。 没时间了。 他们为续订许可证付费,但不使用新版本。 怎么了 因为一旦他们决定修复一个版本。 今天和三年前的产品是白天和黑夜。 原来是“我会买票,但不会来”。
伊万·波诺马列夫(Ivan Ponomarev)1.在这里你是对的。 我准备在一开始就同意编译器/解析器,甚至在本文中也应对此进行更改! 例如,臭名昭著的
spotbugs根本无法以不同的方式起作用,因为它会分析已编译的字节码。 例如,在Ansible剧本的制作流程中有一些特殊情况,最好在解析之前设置静态分析,因为静态分析在此比较轻巧。 但这是异国情调本身)
2.
根据发布版本固定警告数量的选项对我来说似乎不太合适...-是的,是的,它不太合适,技术含量较低,但非常实用:-)主要是,它是一种这是一种通用方法,通过这种方法,我可以在CI上使用Groovy或bash脚本,甚至在最可怕的项目中,即使在最可怕的项目中,都可以有效地进行静态分析,该代码具有任何代码库和任何分析器(不一定是您的分析器)。 顺便说一句,现在我们分别为不同的项目模块和工具分别计算警告,但是如果以更细化的方式(针对文件)划分警告,它将更接近比较新/旧警告的方法。 但是我们有这种感觉,我喜欢这种棘手的问题,因为它会刺激开发人员监视警告的总数并逐渐减少警告的数量。 如果采用旧方法/新方法,是否会激励开发人员监视警告编号的曲线? -可能是,可能是,否。
关于第3点,这是我经验的一个真实例子。 看看
这个提交 。 它是从哪里来的? 我们在TravisCI脚本中设置了短毛猫。 他们在那里工作,是高质量的大门。 但是突然之间,当新版本的Ansible-lint发现更多警告时,由于代码中的警告,一些拉取请求构建开始失败,而警告并没有改变! 最后,该过程被打破,紧急拉动请求被合并而没有通过质量门。
没有人说没有必要更新分析仪。 当然是! 像所有其他构建组件一样。 但这必须是一个自觉的过程,体现在源代码中。 并且每次操作都将取决于环境(无论我们是重新修复检测到的警告还是只是重置“棘轮”)
叶夫根尼(Evgeniy Ryzhkov)当我被问到:“是否可以检查PVS-Studio中的每个提交?”时,我回答是的。 然后添加:“仅出于上帝的考虑,如果PVS-Studio找到了东西,请不要使构建失败!” 因为否则,PVS-Studio迟早会被视为具有破坏性的事情。 在某些情况下,需要快速提交而不是与工具抗争,这种情况不允许提交通过。
我认为在这种情况下使构建失败是很糟糕的。 最好将消息发送给问题代码的作者。
伊万·波诺马列夫(Ivan Ponomarev)我认为没有“我们需要迅速作出承诺”这样的事情。 这都是一个糟糕的过程。 良好的流程可以提高速度,而不是因为我们需要“快速完成”时打破流程/质量门。
这并不矛盾,我们可以在某些静态分析结果类别上取得成功的前提下做得到。 这仅意味着以某些类型的发现被忽略的方式设置门,而对于其他发现,我们具有零容忍度。
我最喜欢的主题是“快速”主题。叶夫根尼(Evgeniy Ryzhkov)我是使用旧分析器版本的方法的坚定反对者。 如果用户发现该版本的错误该怎么办? 他写信给工具开发人员,工具开发人员甚至会修复它。 但是在新版本中。 没有人会为某些客户端支持旧版本。 如果我们不是在谈论价值数百万美元的合同。
伊万·波诺马列夫(Ivan Ponomarev)叶夫根尼,我们根本没有在谈论这个。 没有人说我们必须让它们变老。 这是关于针对其受控更新修复构建组件依赖项的版本-这是一门常见的规则,适用于所有内容,包括库和工具。
叶夫根尼(Evgeniy Ryzhkov)我理解“应该在理论上完成”。 但是我看到客户只有两个选择。 坚持新的还是旧的。 因此,当“我们有纪律,并且在两个版本上落后于当前版本”时,我们几乎没有这种情况。 对我来说现在说好还是坏并不重要。 我只是说说我看到的。
伊万·波诺马列夫(Ivan Ponomarev)知道了 无论如何,这都很大程度上取决于客户拥有什么工具/流程以及他们如何使用它们。 例如,我对C ++世界中的所有功能一无所知。