几个月前,我们Google的同事在Kaggle
举行了一次比赛,为在广受好评的
游戏 “ Quick,Draw!”中收到的图像创建分类器。 Yandex开发人员Roman Vlasov参加的团队在比赛中排名第四。 在1月份的机器学习培训课程中,Roman分享了他的团队的想法,分类器的最终实现以及竞争对手的有趣做法。
大家好! 我叫罗姆·弗拉索夫(Roma Vlasov),今天我将向您介绍快速抽奖! 涂鸦识别挑战赛。

我们团队中有五个人。 我在合并截止日期前加入了她。 我们很不幸,我们有些动摇,但是我们被金钱所掩盖,而他们却被黄金所掩盖。 我们名列第四。
(在比赛中,各团队观察自己的评级,该评级是根据拟议数据集的一部分显示的结果形成的。最终评级是在数据集的另一部分形成的。这样做是为了使比赛参与者不必针对特定数据调整其算法。因此,在决赛中,在评分之间切换时,排名有些“摇”(英语摇动-随机摇动):在其他数据上,结果可能有所不同,罗马的团队在前三名中排名第一。 AU三驾马车 - 就是金钱,金钱排行榜区,因为只有前三个位置靠奖“摇APA“队后已经排在第四位的方式同其他球队失去了胜利,金-...埃德的位置)..
比赛也很重要,因为叶夫根尼·巴巴赫宁(Yevgeny Babakhnin)为他获得了大师,伊万·索辛(Ivan Sosin)大师,罗曼·索洛维约夫(Roman Solovyov)仍然是大师,亚历克斯·帕里诺夫(Alex Parinov)获得了大师,我成为专家,现在我已经是大师。
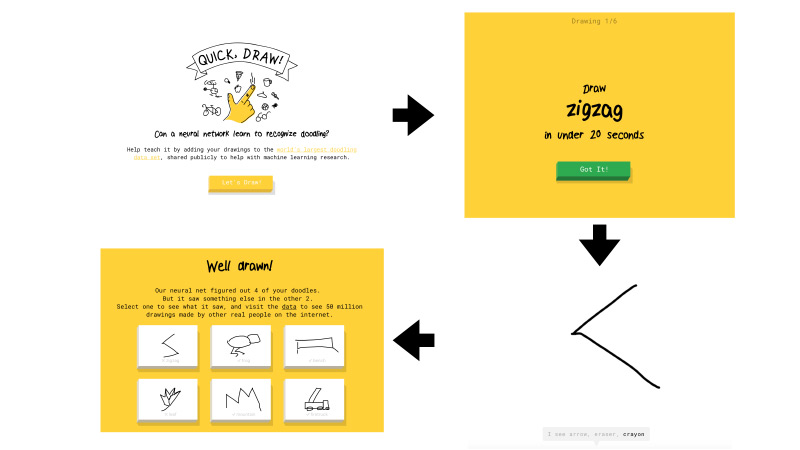
这是什么快速抽奖? 这是Google提供的服务。 Google旨在普及AI,并希望通过这项服务展示神经网络的工作原理。 您去那里,单击“让我们绘制”,然后会弹出一个新页面,提示您:绘制一个曲折,您有20秒的时间执行此操作。 例如,您尝试在20秒内绘制一个锯齿形。 如果一切正常,网络会说这是锯齿状,然后继续前进。 这样的图片只有六张。
如果Google的网络无法识别您绘制的内容,则会在任务上打叉。 稍后我将告诉您,无论图纸是否被网络识别,这将意味着将来。
该服务聚集了大量用户,并且记录了用户绘制的所有图片。

可以收集近5000万张图片。 由此形成了我们比赛的训练和考试日期。 顺便说一下,测试中的数据量和类数并不是用粗体显示的。 我稍后再讨论。
数据格式如下。 这些不仅是RGB图像,而且大致来说是用户所做的所有操作的日志。 文字是我们的目标,国家/地区代码是Doodle的来源,时间戳是时间。 识别的标签仅显示Google的网络是否识别了该图片。 绘制本身就是一个序列,即用户用点绘制的曲线的近似值。 和时间。 这是从开始绘制图片开始的时间。
数据以两种格式表示。 这是第一种格式,第二种是简化的。 他们从那里找出时间,并用较小的一组点近似该组点。 为此,他们使用
了Douglas-Pecker算法 。 您有大量的点可以简单地近似于一条直线,但实际上您可以仅用两个点来近似这条线。 这就是算法的思想。
数据分布如下。 一切都是统一的,但是有一些离群值。 当我们解决问题时,我们没有去看它。 最主要的是,没有类的确很少,我们不必进行加权采样器和数据过采样。

图片是什么样的? 这是飞机类别,其中的示例被标记为已识别和未识别。 它们的比率在1到9之间。如您所见,数据非常嘈杂。 我建议这是一架飞机。 如果您看不清楚,在大多数情况下,这只是噪音。 甚至有人试图写“飞机”,但显然是用法语写的。
大多数参与者只是简单地获取网格,将这一系列线中的数据渲染为RGB图像,然后将其放入网络。 我以大约相同的方式绘画:我选择了一个调色板,我用一种颜色绘制了第一行,该颜色在该调色板的开头,最后一行使用另一种颜色,在调色板的末尾,并且在它们之间的所有位置都插在该调色板上。 顺便说一句,这比您在第一张幻灯片上绘制时(黑色)绘制的效果更好。
其他团队成员,例如Ivan Sosin,尝试了稍有不同的绘画方法。 在一个通道中,他只绘制了一张灰色图片,在另一个通道中,他从32到255绘制了从开始到结束的每个笔画渐变,而第三个通道则在从32到255的所有笔画中绘制了渐变。
另一个有趣的事情是Alex Parinov通过国家/地区代码将信息投放到网络中。
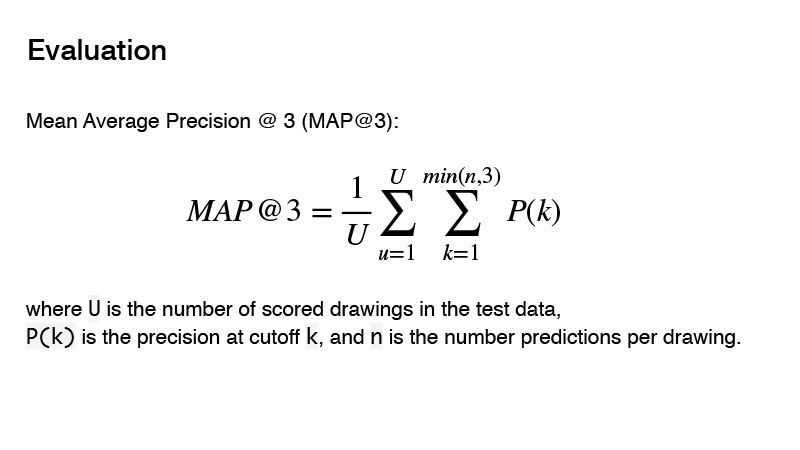
比赛中使用的指标是平均平均精度。 该指标对竞争的实质是什么? 您可以给出三个预测变量,如果这三个预测变量不正确,则得到0。如果存在正确的预测变量,则将其顺序考虑在内。 目标的结果将被视为1除以您的预测顺序。 例如,您做出了三个预测,第一个是正确的,然后将1除以1得到1。如果预测值正确并且其阶数为2,则将1除以2,就得到0.5。 好吧等等

通过数据预处理-如何绘制图片等-我们做出了一些决定。 我们使用了什么架构? 我们试图使用PNASNet,SENet等大胆的体系结构,以及SE-Res-NeXt等已经很经典的体系结构,它们正越来越多地参与新的竞争。 还有ResNet和DenseNet。



我们是怎么教的? 我们采用的所有模型都在imagenet上进行了预培训。 尽管有大量数据,但有5000万张图像,但是,如果您在imagenet上对网络进行预训练,则与仅从头开始训练相比,它显示出更好的结果。
我们使用了哪些培训技术? 这是热重启的Cosing退火,稍后再讨论。 我几乎在过去的所有比赛中都使用了这项技术,事实证明,训练网来达到最低的要求非常好。

下一步降低高原地区的学习率。 您开始训练网络,设置一些特定的学习率,然后学习它,然后您的损失逐渐收敛到某个特定的值。 您检查了一下,例如,十多个时代,损失没有改变。 您将学习率降低了一些价值,然后继续学习。 它再次下降一点,收敛到一定的最小值,再次降低学习率,依此类推,直到网络最终收敛。
进一步有趣的技术:不要降低学习速度,增加批量大小。 有同名的文章。 训练网络时,您不必降低学习率,只需增加批量即可。
顺便说一下,Alex Parinov使用了这种技术。 他以等于408的批次开始,当网络达到稳定状态时,他只是使批次大小增加了一倍,依此类推。
实际上,我不记得批处理量达到了什么价值,但有趣的是,Kaggle上有一些团队使用相同的技术,其批处理量约为10,000。顺便说一下,现代的深度学习框架,例如例如,PyTorch允许您非常简单地执行此操作。 您可以生成批次并将其完整地提交到网络,而不是将其完整地提交给网络,而是将其分成大块以便适合您的视频卡,计算梯度,并在计算整个批次的梯度后进行权重的更新。
顺便说一句,由于数据非常嘈杂,因此大批量仍在竞争中出现,并且大批量可以帮助您更准确地估算梯度。
还使用了伪轻描淡写;罗马索洛维耶夫(Roman Soloviev)最常使用伪装。 他从测试数据的一半采样到某个地方,并在这样的批次上训练了网格。
图片的大小起了作用,但事实是您有很多数据,需要长时间训练,而如果图片大小很大,则将需要很长时间训练。 但这并没有对最终分类器的质量带来太多影响,因此值得进行一些权衡。 他们只尝试了尺寸不是很大的图片。
这一切是怎么学习的? 首先,拍摄的是小尺寸的图片,在它们上运行了多个时代,这很快就花了时间。 然后提供了大图片,网络学习了,然后更多,甚至更多,以免从头开始训练它,而不用花费大量时间。
关于优化器。 我们使用了SGD和Adam。 这样,就有可能获得一个单一模型,该模型在公共排行榜上的速度为0.941-0.946,这相当不错。
如果以某种方式集成模型,那么您将获得0.951。 如果您应用其他技术,那么您将获得我们在公共董事会上获得的最终速度0.954。 但是稍后会更多。 接下来,我将告诉您我们如何组装模型,以及如何达到最终速度。
接下来,我想谈谈通过热重启进行Cosing退火或通过热重启进行随机梯度下降。 粗略地说,原则上来说,您可以坚持使用任何优化程序,但是最重要的是:如果您只训练一个网络并逐渐收敛到最小,那么一切正常,您将获得一个网络,这会犯某些错误,但是你可以教她一点不同。 您将设置一些初始学习率,然后根据此公式逐渐降低它。 您低估了这一点,您的网络达到了一定的最小值,然后您节省了权重,并再次设置了学习率(该值是在训练开始时开始的),因此从该最小值开始逐渐上升,并再次低估了您的学习率。
因此,您可以一次访问多个低点,在这些低点中,您的损失将为正负相同。 但是事实是,具有这些权重的网络会在您的约会中给出不同的错误。 通过平均它们,您将获得一定的近似值,并且速度会更高。
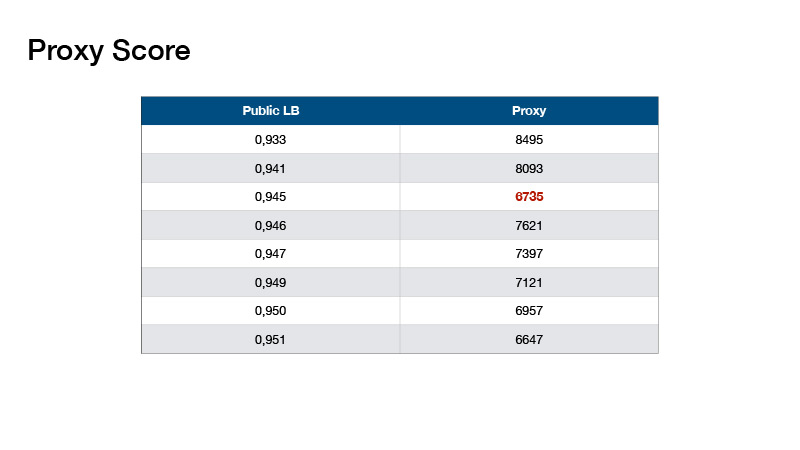
关于我们如何组装模型。 在演讲开始时,我说要注意测试中的数据量和类数。 如果在测试集中的目标数量上加1并除以类数,则得到的数字为330,这是写在论坛上的-测试中的类是平衡的。 可以使用。
基于此,罗曼·索洛维约夫(Roman Solovyov)发明了该指标,我们将其称为Proxy Score(代理人得分),与排行榜的相关性很好。 最重要的是:您进行预测,取得预测的前1名,并计算每个类的对象数。 从每个值减去330,然后将所得的绝对值相加。
事实证明这些价值。 这帮助我们没有做一个测试排行榜,而是在本地验证并为我们的乐团选择系数。
有了合奏,您可以获得如此快的速度。 还要做什么? 假设您使用的信息表明测试中的类是平衡的。
平衡是不同的。
其中一个例子是与赢得第一名的球员保持平衡。
我们做了什么? 由Evgeny Babakhnin提出,我们的平衡非常简单。 我们首先按前1名对我们的预测进行排序,然后从中选择候选者-这样一来,类别的数量就不会超过330。但是对于某些类别,事实证明,预测的数量要少于330。好吧,让我们按前2名进行排序和前3名,并选择候选人。
我们的平衡与第一名的平衡有何不同? 他们使用迭代的方法,选出了最受欢迎的一门课程,并将该课程的概率降低了少量-直到该课程不再最受欢迎。 他们参加了下一个最受欢迎的课程。 如此进一步降低直到所有类的数量相等。
每个人都使用加减法训练网络,但不是每个人都使用平衡法。 使用平衡,您可以赚到金子,如果幸运的话,也可以赚到黄金。
如何预处理日期? 每个人都以同样的方式对正负日期进行预处理-他们制作了手工制作的功能,试图用不同的笔触颜色对正时进行编码,等等。第八名的Alexey Nozdrin-Plotnitsky在谈论这一点。

他做了不同的事情。 他说您所有的手工功能都不起作用,您不需要这样做,您的网络必须自己学习所有这些。 相反,他想出了对数据进行预处理的学习模块。 他将未经预处理的源数据(点和时间的坐标)放入其中。
此外,他将坐标中的差异取平均值,并将其平均化。 他得到了一个相当长的矩阵。 他多次使用一维卷积获得一个64xn矩阵,其中n是点的总数,然后制作64个矩阵以将所得矩阵馈送到某些卷积网络的一个层,该层接受64个通道。原来它是一个64xn的矩阵,然后有必要组成一个一定大小的张量,以使通道数为64。他将0、32范围内的所有点X,Y归一化,以生成大小为32x32的张量。 我不知道他为什么要32x32,它发生了。 然后在这个坐标中,他放入了这个尺寸为64xn的矩阵的片段。 因此,他只是收到了32x32x64张量,可以将其进一步放入卷积神经网络中。 我有一切