
我想以最简单的方式
向初学者介绍
函数式编程的概念,重点介绍它的许多其他优点,这些优点将真正使代码更具可读性和表现力。 我在
Github的
Playground上为您挑选了一些有趣的演示。
功能编程:定义
首先,
函数式编程不是一种语言或语法,而是最有可能通过将复杂的过程分解为较简单的过程及其后续组合来解决问题的方法。 顾名思义,“
函数式编程 ”(
Functional Programming)是这种方法的组合单元。 此
功能的目的是避免在其
scope)之外更改状态或值。
在
Swift World中,有所有条件,因为这里的
功能像
对象一样完全参与了编程过程
,并且
mutation问题在
value TYPES(
struct结构和
enum枚举)的概念级别得到了解决,该
value有助于管理
mutation (
mutation ),并清楚地说明发生这种情况的方式和时间。
但是,
Swift并不是完全意义上的
函数式编程语言,尽管它认识到
函数式方法的优点并找到了嵌入它们的方法,但它并没有强迫您进行
函数式编程 。
在本文中,我们将重点介绍在
Swift中使用
函数式编程的内置元素(即“开箱即用”),并了解如何在应用程序中舒适地使用它们。
命令式和功能式方法:比较
为了评估
功能方法,让我们以两种不同的方式比较一些简单问题的解决方案。 第一种解决方案是“
命令式 ”,其中代码更改了程序内部的状态。
注意,我们在名为
numbers的可变数组中操作值,然后将其打印到控制台。 查看此代码,尝试回答以下将在不久的将来讨论的问题:
- 您想用代码实现什么?
- 如果在代码运行时另一个
thread尝试访问numbers数组,会发生什么情况? - 如果您想访问
numbers数组中的原始值会怎样? - 此代码的测试可靠性如何?
现在让我们看一下替代的“
功能性 ”方法:
在这段代码中,我们在控制台上获得了相同的结果,以完全不同的方式来解决问题。 请注意,这次,由于
let关键字,我们的
numbers数组是不变的。 我们已经将数字乘以数字的过程从
numbers数组移到了
timesTen()方法中,该方法位于
Array的扩展
extension 。 我们仍然使用
for循环并修改一个名为
output的变量,但是此变量的
scope仅受此方法限制。 类似地,我们的输入参数
self通过值(
by value )传递给
timesTen()方法,其范围与输出变量
output 。
timesTen()方法,我们可以在控制台上同时打印原始
numbers数组和结果数组
result 。
让我们回到我们的四个问题。
1.您想用代码实现什么?在我们的示例中,我们将
numbers数组中的
numbers乘以
10执行一个非常简单的任务。
使用
命令式方法时,为了获得输出,您必须像计算机一样,按照
for循环中的说明进行思考。 在这种情况下,代码显示了
实现结果。 使用
功能方法时,
timesTen()方法中的“
”被“包装”了。 如果此方法在其他地方实现,则实际上只能看到
numbers.timesTen()表达式。 这样的代码清楚地显示了此代码
实现的目标,而不是解决任务的方式。 这称为
声明式编程 ,很容易猜出为什么这种方法很有吸引力。
命令式方法使开发人员了解代码
工作,以确定他应该做什么。 与
命令式方法相比,
功能性方法更具“表达力”,并为开发人员提供了一个豪华的机会,使其可以简单地假设该方法已完成其声称的工作! (显然,此假设仅适用于预验证的代码)。
2.如果在代码运行时另一个thread尝试访问numbers数组,会发生什么情况?上面提供的示例存在于完全隔离的空间中,尽管在复杂的多线程环境中,两个
threads很可能尝试同时访问相同的资源。 在
命令式方法的情况下,很容易看出,当另一个
thread在使用
numbers数组的过程中可以访问
numbers数组时,结果将由
threads访问
numbers数组的顺序决定。 这种情况称为
race condition ,可能导致不可预测的行为,甚至导致应用程序不稳定和崩溃。
相比之下,
功能方法没有“副作用”。 换句话说,
output方法的
output不会更改我们系统中的任何存储值,而仅由输入确定。 在这种情况下,任何有权访问
numbers数组的
threads都将始终接收相同的值,并且其行为将是稳定且可预测的。
3.如果您想访问存储在
numbers数组中的原始值,会发生什么?
这是我们对“副作用”的讨论的延续。 显然,不会跟踪状态更改。 因此,使用
命令式方法,我们在转换过程中丢失了
numbers数组的初始状态。 我们基于
功能方法的解决方案将保存原始
numbers数组,并在输出中生成具有所需属性的新
result数组。 它使原始
numbers数组保持原样,并适合将来处理。
4.此代码的测试可靠性如何?
由于
功能方法会破坏所有“副作用”,因此经过测试的功能完全在方法内部。 此方法的输入永远不会发生任何变化,因此您可以根据需要多次使用该循环进行多次测试,并且始终会得到相同的结果。 在这种情况下,测试非常容易。 相比之下,在循环中测试
命令式解决方案将更改条目的开始,并且每次迭代后您将获得完全不同的结果。
福利摘要
正如我们从一个非常简单的示例中看到的那样,如果您要处理数据模型,那么
功能方法是一件很酷的事情,因为:
- 它是声明性的
- 它修复了与线程相关的问题,例如
race condition和死锁 - 它使状态保持不变,可用于后续转换。
- 这很容易测试。
让我们进一步学习
Swift 函数式编程。 它假定主要的“角色”是函数,并且它们应该主要
是第一类的对象 。
头等函数和高阶函数
为了使函数成为一流,它必须具有被声明为变量的能力。 这使您可以将功能作为普通数据类型进行管理,并同时执行它。 幸运的是,在
Swift函数是第一类的对象,即通过将它们作为参数传递给其他函数,作为其他函数的结果返回它们,将它们分配给变量或存储在数据结构中而得到支持。
因此,我们在
Swift还有其他函数-高阶函数定义为将另一个函数作为参数或返回一个函数的函数。 其中有很多:
map ,
filter ,
reduce ,
forEach ,
flatMap ,
compactMap ,
sorted等。 高阶函数的最常见示例是
map ,
filter和
reduce 。 它们不是全局的,它们都“附加”到某些类型。 它们适用于所有
Sequence TYPES,包括
Collection ,它由
Swift数据结构(例如
Array ,
Dictionary和
Set 。 在
Swift 5 ,高阶函数还可以使用全新的TYPE-
Result 。
map(_:)
在
Swift map(_:)将一个函数作为参数,并根据此函数转换某个
的值。 例如,将
map(_:)应用于
Array值
Array ,我们将参数函数应用于原始数组的每个元素,并且获得
Array ,但转换后的值也是如此。
在上面的代码中,我们创建了功能
timesTen (_:Int) ,该函数接受一个整数
Int值并返回整数值
Int乘以
10 ,并将其用作高阶
map(_:)函数的输入参数,并将其应用于数组
numbers 。 我们在
result数组中获得了所需的
result 。
map(_:)等高阶函数的参数函数
timesTen的名称无关紧要,输入参数的
和返回值很重要,即函数输入参数的签名
(Int) -> Int 。 因此,我们可以在
map(_:) -闭包-中以任何形式使用匿名函数,包括那些参数名缩短了
$0 ,
$1等的函数。
如果我们查看
Array的
map(_ :)函数,它可能看起来像这样:
func map<T>(_ transform: (Element) -> T) -> [T] { var returnValue = [T]() for item in self { returnValue.append(transform(item)) } return returnValue }
这是我们熟悉的命令性代码,但不再是开发人员问题,而是
Apple问题,
Swift问题。
Apple在性能方面对高阶
map(_:)函数的实现进行了优化,并且我们为开发人员保证了
map(_:)功能,因此我们只能使用
transform参数函数正确表达我们想要的内容而不必担心它将
实施。 结果,我们以单行的形式获得了可读性强的代码,它将更好,更快地工作。
参数函数返回的
可能与原始集合
元素的
不一致。
在上面的代码中,我们有可能以整数形式表示的整数integersNumbers,它表示为字符串,并且我们要使用由闭包
{ str in Int(str) }表示的
failable初始化
failable函数
Int(_ :String)将它们转换为
Int整数。
{ str in Int(str) } 。 我们使用
map(_:)进行此操作,并获得
Optional的
mapped数组作为输出:

我们
将数组
possibleNumbers Numbers中的
元素都转换为整数,结果是,一部分收到了值
nil ,这表明不可能将
String转换为整数
Int ,而另一部分变成了
Optionals ,它们具有以下值:
print (mapped)
compactMap(_ :)
如果传递给高阶函数的参数函数在输出处具有
Optional值,则使用含义相似的另一个高阶函数
compactMap(_ :)可能更有用,该函数与
map(_:)的作用相同,但还可以“扩展”在
Optional输出中接收到的值,并从集合中删除
nil值。

在这种情况下,我们获得了
compactMapped TYPE
[Int]数组,但可能更小:
let possibleNumbers = ["1", "2", "three", "///4///", "5"] let compactMapped = possibleNumbers.compactMap(Int.init) print (compactMapped)
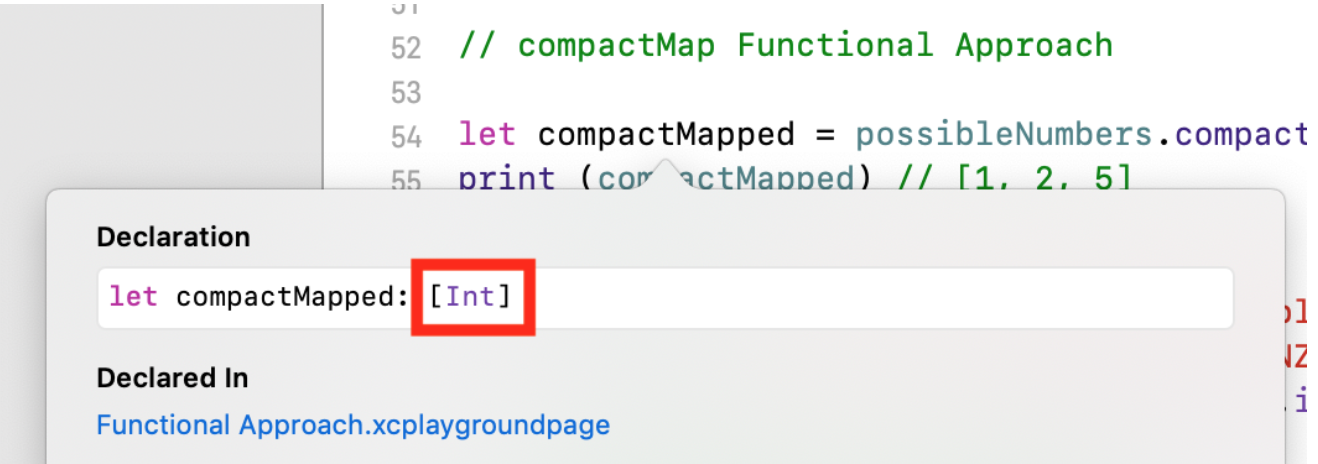
每当使用
init?()初始化程序作为转换函数时,就必须使用
compactMap(_ :) :
我必须说,使用高阶函数
compactMap(_ :)有足够的理由。
Swift “喜欢”
Optional值,不仅可以使用“
failable ”
init?()初始化程序来获取它们,还可以使用
as?来获取
as? “投放”
:
let views = [innerView,shadowView,logoView] let imageViews = views.compactMap{$0 as? UIImageView}
...以及
try? 处理某些方法引发的错误时。 我必须说,
Apple担心
try?使用
try? 通常会导致双倍的
Optional级别,而在
Swift 5中 ,应用
try?之后现在仅留下一个
Optional级别
try? 。
高阶
flatMap(_ :)名称中还有一个类似的函数,该函数略低一些。
有时,要使用高阶函数
map(_:) ,使用
zip (_:, _:)方法从两个不同的序列中创建一个成对的序列很有用。
假设我们有一个
view在该
view上表示了几个点,将它们连接在一起并形成一条虚线:
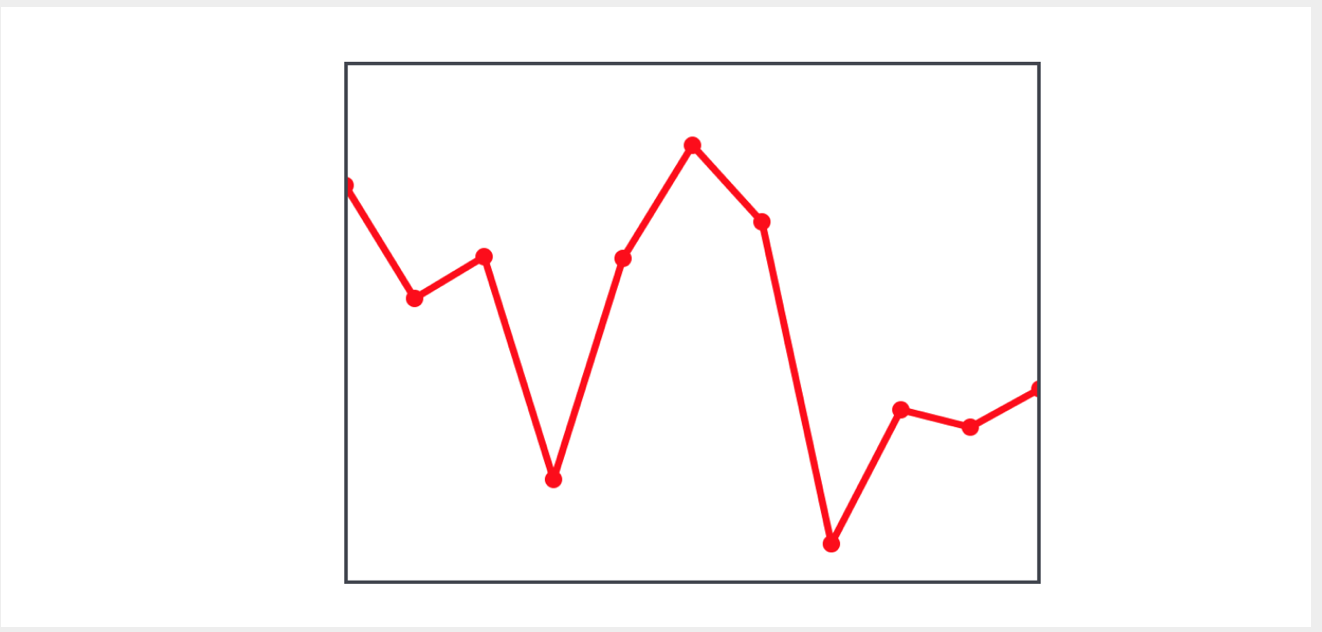
我们需要构建另一条折线来连接原始折线段的中点:

为了计算线段的中点,我们必须具有两个点的坐标:当前点和下一个点。 为此,我们可以使用
zip (_:, _:)方法创建一个由点对(当前点和下一个点)组成的序列,在该方法中,我们将使用点起点数组和以下
points.dropFirst() :
let pairs = zip (points,points.dropFirst()) let averagePoints = pairs.map { CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
有了这样的序列,我们可以很容易地使用高阶函数
map(_:)计算中点并将其显示在图形上。
filter (_:)
在
Swift ,高阶函数
filter (_:)可用于大多数
map(_:) 。 您可以使用
filter (_:)过滤任何
Sequence序列,这很明显!
filter (_:)方法将另一个函数用作参数,这是序列中每个元素的条件,如果满足条件,则该元素将包含在结果中,如果不满足,则不包含该元素。 这个“其他函数”采用一个值(
Sequence序列的一个元素),并返回
Bool ,即谓词。
例如,对于
Array数组,高阶函数
filter (_:)应用谓词函数并返回另一个数组,该数组仅由输入谓词函数返回
true的原始数组的那些元素组成。
在这里,高阶函数
filter (_:)接受
numbers数组的每个元素(用
$0表示),并检查该元素是否为偶数。 如果这是一个偶数,则
numbers数组的元素将落入新的
filted数组中,否则不属于该数组。 我们以声明的形式告知了程序我们想要获得的信息,而不是
我们应该
去做。
我将给出另一个示例,该示例使用高阶函数
filter (_:)仅获取值
< 4000的偶前
20斐波那契数:
let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
我们得到一个由Fibonacci序列的两个元素组成的元组序列:第n个和(n + 1)-th:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
为了进行进一步处理,我们使用
prefix (20)将元素的数量限制为前二十个元素,并使用
map {$0.0 }获取生成的元组的
0元素,该元素将对应于以
0开头的斐波那契序列:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
我们可以使用
map {$0.1 }来获取形成的元组的
1元素,它对应于以
1开始的斐波那契序列:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
我们借助高阶函数
filter {$0 % 2 == 0 && $0 < 4000}获得所需的元素,该
filter {$0 % 2 == 0 && $0 < 4000}返回满足给定谓词的序列元素数组。 在我们的例子中,它将是整数
[Int]的数组:
[0, 2, 8, 34, 144, 610, 2584]
还有一个对
Collection使用
filter (_:)有用示例。
我遇到
了一个真正的问题 ,当您使用
CollectionView显示一系列
images ,并使用
Drag & Drop技术,您可以收集一堆图像并将其移动到各处,包括将它们拖放到“垃圾桶。”

在这种情况下,转储到“垃圾箱”
removedIndexes的索引
removedIndexes数组是固定的,并且您需要创建一个新的图像数组,但索引中不包含这些图像的数组是
removedIndexes 。 假设我们有一个模拟图像的整数
images数组,以及这些整数的索引数组
removedIndexes需要删除的索引。 我们将使用
filter (_:)解决我们的问题:
var images = [6, 22, 8, 14, 16, 0, 7, 9] var removedIndexes = [2,5,0,6] var images1 = images .enumerated() .filter { !removedIndexes.contains($0.offset) } .map { $0.element } print (images1)
enumerated()方法返回由
offset索引和数组
element值组成的元组序列。
然后,我们filter对所得的元组序列应用过滤器,仅保留其索引$0.offset未包含在array中的那些元组removedIndexes。下一步,我们从元组中选择值,$0.element然后获取所需的数组images1。reduce (_:, _:)
reduce (_:, _:)大多数map(_:)人和方法也可以使用该方法filter (_:)。该方法reduce (_:, _:)将序列“折叠” Sequence为一个累加值,并具有两个参数。第一个参数是起始累加值,第二个参数是将累加值与序列元素组合Sequence以获得新累加值的函数。将输入参数函数Sequence一个接一个地应用于序列的每个元素,直到到达末尾并创建最终的累加值。 let sum = Array (1...100).reduce(0, +)
这是使用高阶函数的经典平凡示例reduce (_:, _:)-计算数组元素的总和Array。 1 0 1 0 +1 = 1 2 1 2 2 + 1 = 3 3 3 3 3 + 3 = 6 4 6 4 4 + 6 = 10 . . . . . . . . . . . . . . . . . . . 100 4950 100 4950 + 100 = 5050
使用该函数,reduce (_:, _:)我们可以非常简单地计算满足特定条件的斐波那契数的总和: let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
但是,高阶函数还有更多有趣的应用reduce (_:, _:)。例如,我们可以根据其大小非常简单明了地确定一个非常重要的参数UIScrollView-“可滚动”区域contentSize的大小subviews: let scrollView = UIScrollView() scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300))) scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600))) scrollView.contentSize = scrollView.subviews .reduce(CGRect.zero,{$0.union($1.frame)}) .size
在此演示中,累加值是GCRect,并且累加操作是合并我们union矩形的操作。尽管事实上高阶函数具有累积特性,但可以在完全不同的角度使用它。例如,将一个元组拆分为一个元组数组中的部分:framesubviewsreduce (_:, _:)
Swift 4.2引入了一种新型的高阶函数reduce (into:, _:)。该方法reduce (into:, _:)是在效率是有利的与所述方法相比reduce (:, :),如果使用所得到的结构COW (copy-on-write) Array或Dictionary。它可以有效地删除整数数组中的匹配值:
...或计算数组中不同元素的数量时:
flatMap (_:)
在继续使用此高阶函数之前,让我们看一个非常简单的演示。 let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
如果我们运行该代码以在其上执行Playground,那么一切看起来都很好,并且我们的代码firstNumber是相等的42: 但是,如果您不知道,它
但是,如果您不知道,它Playground通常会隐藏真正的代码firstNumber。实际上,该常数firstNumber有Optional: 这是因为
这是因为map (Int.init)在输出处它形成了OptionalTYPE值数组[Int?],因为并非每一行都String可以转换Int为该值,并且初始化程序Int.int正在“下降”(failable)。然后,使用该数组的函数first获取形成的数组的第一个元素,该元素Array也形成输出Optional,因为数组可能为空,我们将无法获得数组的第一个元素。结果,我们有一个double Optional,即Int??。我们有一个嵌套的结构,Optional在Optional其中它确实很难使用,而我们自然不希望拥有。为了从嵌套结构中获取价值,我们必须“潜入”两个层次。此外,任何其他转换都可以使水平进一步加深Optional。从双重嵌套中获取价值Optional确实很麻烦。我们有3个选择,所有这些都需要对语言有深入的了解Swift。if let , ; «» «» Optional , — «» Optional :

if case let ( pattern match ) :

?? :

- ,
switch :
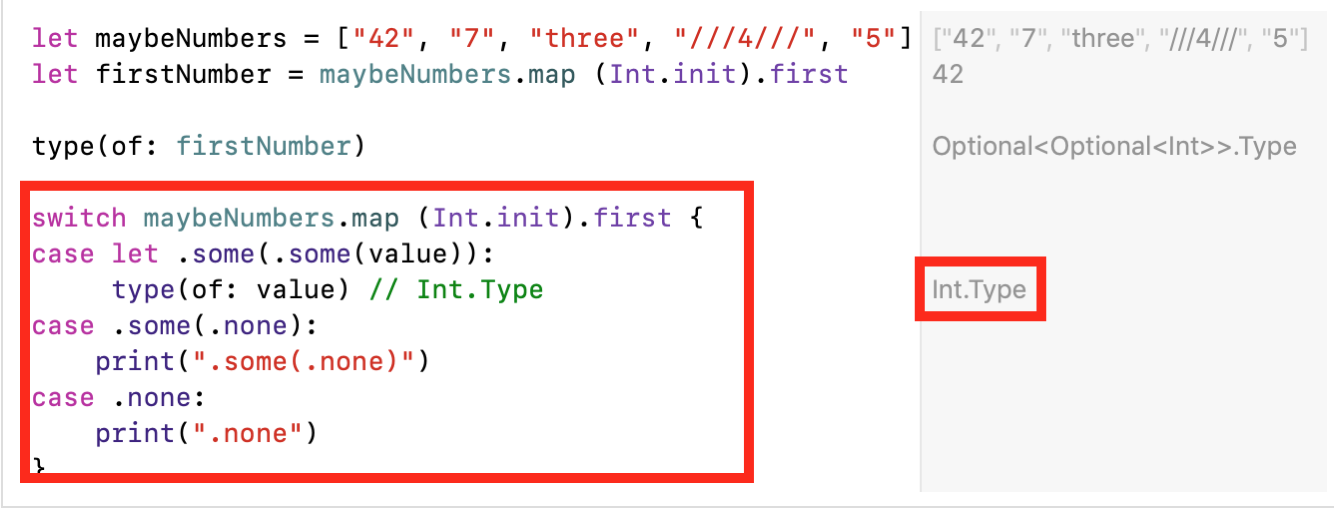
更糟的是,这种嵌套问题generic定义了操作的广义()容器的任何情况下都会出现map。例如,对于arrays Array。考虑另一个示例代码。假设我们有一个多行文本multilineString,我们希望将其分成小写(小写)字母的单词: let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .map{$0.split(separator: " ")}
为了获取单词数组words,我们首先使用方法将大写(大写)字母转换为小写(小写)lowercased(),然后使用该方法将文本分成几split(separatot: "\n")行并获得一个字符串数组,然后使用它将map {$0.split(separator: " ")}每一行分隔成单独的单词。结果,我们得到了嵌套数组: [["", ",", "", ","], ["", "", ";", "", "", "", "", ",", "—"], ["", ",", "", "", ":"], ["", "—", "", "", ",", "", "", "."], ["", "", ",", "", "", ","], ["", "", ".", "", ""], ["", ".", "", ",", ""], ["", "", "", ""], ["", "", ",", "", "«", "»"], ["", ".", "", ","], ["", ",", "", "", "!"]]
...它words有Array: 我们再次获得了“嵌套”数据结构,但是这次我们没有
我们再次获得了“嵌套”数据结构,但是这次我们没有Optional,但是Array。words例如,如果我们要继续处理接收到的单词,以查找此多行文本的字母范围,那么我们首先必须以某种方式“拉直” double的数组Array并将其变成single的数组Array。这类似于Optional本节开始时我们对double 进行的演示操作flatMap: let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
幸运的是,Swift我们不必诉诸复杂的句法结构。Swift为我们提供了现成的阵列Array和解决方案Optional。这是一个高阶函数flatMap!它非常类似于map,但是它具有与执行期间出现的“附件”的后续“拉直”相关的其他功能map。这就是为什么要调用flatMap它,它“拉直” flattens结果的原因map。让我们适用flatMap于firstNumber: 我们真的得到了C单电平的输出值
我们真的得到了C单电平的输出值Optional。对于数组来说,工作更加有趣。在表达式中,我们简单地替换为flatMapArraywordsmapflatMap: ...,而我们得到的单词数组
...,而我们得到的单词数组words没有任何“嵌套”: ["", ",", "", ",", "", "", ";", "", "", "", "", ",", "—", "", ",", "", "", ":", "", "—", "", "", ",", "", "", ".", "", "", ",", "", "", ",", "", "", ".", "", "", "", ".", "", ",", "", "", "", "", "", "", "", ",", "", "«", "»", "", ".", "", ",", "", ",", "", "", "!"]
现在,我们可以继续处理生成的单词数组words,但是要小心。如果再次将其应用于flatMap数组的每个元素,则words可能会得到意想不到但可理解的结果。 我们得到
我们得到[Character]包含在多行词组中的单个字母数组,而不是“嵌套”数组: ["", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ";", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ...]
事实是,字符串String是Collection字符的集合,[Character]并且flatMap针对每个单词,我们再次降低“嵌套”的级别,并得出一个字符数组flattenCharacters。也许这正是您想要的,也许不是。注意这一点。放在一起:解决一些问题
任务1
我们可以继续处理上一节中需要的单词数组,words并计算多行短语中字母出现的频率。首先,让我们将数组中的所有单词“粘合”到大行中,words并从中排除所有标点符号,即仅保留字母: let wordsString = words.reduce ("",+).filter { "" .contains($0)}
因此,我们收到了所有需要的信件。现在,让我们为它们制作一个字典,其中的键key是字母,值value是其在文本中出现的频率。我们可以通过两种方式做到这一点。第一种方法与使用出现在中的一系列新Swift 4.2的高阶函数有关reduce (into:, _:)。此方法非常适合我们以letterCount多行短语中出现字母的频率来组织字典: let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} print (letterCount)
结果,我们将得到一个字典letterCount [Character : Int],其中的键key是在学习的短语中找到的字符,而值value是这些字符的数量。第二种方法涉及使用分组来初始化字典,从而得到相同的结果: let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count} letterCount == letterCountDictionary
我们想letterCount按字母顺序对字典排序: let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
但是我们不能直接对字典进行排序Dictionary,因为从根本上来说它不是有序的数据结构。如果我们将函数sorted (by:)应用于字典Dictionary,则它将以给定的谓词数组的形式将给定谓词排序的序列元素返回给我们,map我们将其转换成[":17", ":5", ":18", ...]反映相应字母出现频率的字符串数组。我们看到这次sorted (by:)只是将“ <” 运算符作为谓词传递给高阶函数。该函数sorted (by:)期望“比较函数”作为输入中的唯一参数。它用于比较两个相邻的值并确定它们是否正确排序(在这种情况下,返回true)或否(返回false)。我们可以sorted (by:)以匿名闭包的形式提供此“比较功能”功能: sorted(by: {$0.key < $1.key}
我们可以像上面一样给它加上运算符“ <”,该运算符具有我们所需的签名。这也是一项功能,按键排序正在进行中key。如果我们想按值对字典进行排序,value并找出在该短语中最常见的字母,那么我们将必须对函数使用闭包sorted (by:): let countsStat = letterCountDictionary .sorted(by: {$0.value > $1.value}) .map{"\($0.0):\($0.1)"} print (countsStat )
如果我们看一下确定整个多行词组字母谱的问题的解决方案... let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .flatMap{$0.split(separator: " ")} let wordsString = words.reduce ("",+).filter { "" .contains($0)} let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
...然后我们会注意到,在此代码段中,基本上没有变量(不var,仅let)所有使用的函数名称在某些信息上反映了ACTIONS(函数),根本不用担心这些操作的实现方式:split-split,map-transformflatMap-transform with对准(通过去除嵌套中的一个电平),filter-过滤器,sorted-排序,reduce-由特定操作的装置把数据转换成一定的结构中的每行代码的该片段说明了我们使用,如果我们在功能的名称。罢了,“纯”变换使用map,如果我们执行使用嵌套层次的转换flatMap,如果我们只选择某些数据,则使用filter,等等。“最高顺序”的所有这些功能在设计和测试时都Apple考虑了性能优化。因此,这段代码非常可靠和简洁-解决问题所需的句子不超过5个。这是功能编程的示例。在此演示中应用功能性方法的唯一缺点是,出于不变性,可测试性和可读性的考虑,我们反复通过各种高阶函数来跟踪文本。对于大量的收集项目,Collection性能可能会下降。例如,如果我们先使用filter(_:)and,然后使用- first。在Swift 4 添加了一些新功能选项以提高性能,这些是编写更快的代码的一些技巧。1.使用contains,不first( where: ) != nil
Collection可以通过多种方式来验证对象是否在集合中。该功能可提供最佳性能contains。正确的代码 let numbers = [0, 1, 2, 3] numbers.contains(1)
代码不正确 let numbers = [0, 1, 2, 3] numbers.filter { number in number == 1 }.isEmpty == false numbers.first(where: { number in number == 1 }) != nil
2.使用验证isEmpty,而不是count零的比较
由于对于某些集合,count通过对集合的所有元素进行迭代来执行对属性的访问。正确的代码 let numbers = [] numbers.isEmpty
代码不正确 let numbers = [] numbers.count == 0
3. String使用isEmpty
字符串String输入Swift是字符的集合[Character]。这意味着对于字符串,String也最好使用isEmpty。正确的代码 myString.isEmpty
代码不正确 myString == "" myString.count == 0
4.获得满足某些条件的第一个要素
为了获得满足某些条件的第一个对象,可以对整个集合进行迭代,filter然后使用方法first,但是该方法在速度方面是最好的first (where:)。一旦满足必要条件,此方法就停止对集合进行迭代。该方法filter将继续遍历整个集合,而不管它是否满足必需的元素。显然,该方法也是如此last (where:)。正确的代码 let numbers = [3, 7, 4, -2, 9, -6, 10, 1] let firstNegative = numbers.first(where: { $0 < 0 })
代码不正确 let numbers = [0, 2, 4, 6] let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
有时,当集合Collection非常庞大且性能对您而言至关重要时,值得比较一下命令式和功能性方法,然后选择适合您的方法。任务2
reduce (_:, _:)我遇到的另一个很好的例子是非常简洁地使用了高阶函数。这是一个SET游戏。这是其基本规则。游戏的SET名称来自英文单词“ set”-“ set”。游戏SET涉及81张卡, 每张卡都有唯一的图片:每张卡具有4个属性,如下所示:数量:每张卡具有一个,两个或三个字符。字符类型:椭圆形,菱形或波浪形。颜色:符号可以是红色,绿色或紫色。填充:字符可以为空,阴影或阴影。游戏目的
每张卡都有唯一的图片:每张卡具有4个属性,如下所示:数量:每张卡具有一个,两个或三个字符。字符类型:椭圆形,菱形或波浪形。颜色:符号可以是红色,绿色或紫色。填充:字符可以为空,阴影或阴影。游戏目的SET:在桌上列出的12张卡中,您需要找到SET(一组)3张卡,其中所有3张卡上的每个符号要么完全重合要么完全不同。所有标志都必须完全遵守此规则。例如,人物的全部3张卡的数量必须是在所有3张卡相同或不同的颜色必须是相同的或不同的,等等...在这个例子中,我们只在显卡型号兴趣SET struct SetCard和算法的定义SET为第三张地图isSet( cards:[SetCard]): struct SetCard: Equatable { let number: Variant
该模型的各特征- 数 number,符号类型 shape,颜色 color和灌装 fill -呈现列出Variant具有三个可能的值var1,var2并且var3向第三整数对应rawValue- 1,2,3。以这种形式,rawValue易于操作。如果我们采取任何指示,例如color,然后将所有rawValue的colors3张卡,我们发现,如果colors所有的3张卡都是平等的,金额将等于3,6或者9,如果他们是不同的,那么量将平等的6。在任何情况下,我们有多重第三届达rawValue至colors全部三张牌。我们知道这是组成三张牌的先决条件SET。为了使3卡真正成为SET必需,对于所有符号SetCard-数量number,符号类型shape,颜色color和填充fill-它们的总和应rawValue为3的倍数。因此,在该static方法中,isSet( cards:[SetCard])我们首先计算阵列sums总和的rawValue所有3个地图使用高阶函数所有4性能图reduce的初始值等于0,和积累功能{$0 + $1.number.rawValue},{$0 + $1.color.rawValue},{$0 + $1.shape.rawValue},{ {$0 + $1.fill.rawValue}。数组的每个元素sums必须是3rd的倍数,然后再次使用reduce,但是这次的初始值等于true并累积了逻辑函数“ AND” {$0 && ($1 % 3) == 0}。在Swift 5中,为了测试一个数字与另一个数字的多重性,引入了一个函数来isMultiply(of:)代替%余数运算符。这也将提高代码的可读性:{ $0 && ($1.isMultiply(of:3) }。借助“ 功能性 ”方法,获得了这个神奇的短代码,用于找出3 SetCard张卡是否为SETith。我们可以确保它适用于:如何在此处,此处和此处在此游戏模型上构建用户界面()。Playground
SETUI纯净的功能和副作用
一个纯函数满足两个条件。它总是使用相同的输入参数返回相同的结果。结果的计算不会导致与外部数据输出(例如,向磁盘)或从外部借用源数据(例如,时间)相关的副作用。这使您可以极大地优化代码。此主题Swift轮廓非常清晰的现场point.free中的第一个集“ 中的作用 ”和“ 副作用 ”,这已被翻译成俄文,并提出作为“ 选项 ”和“副作用”。功能组成
从数学意义上讲,这意味着将一个功能应用于另一个功能的结果。在一个Swift函数中,它们可以返回一个值,您可以将该值用作另一个函数的输入。这是一种常见的编程习惯。想象一下,我们有一个整数数组,并且希望在输出中得到一个唯一偶数平方的数组。通常,我们按如下方式重新实现: var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] func unique(_ array: [Int]) -> [Int] { return array.reduce(into: [], { (results, element) in if !results.contains(element) { results.append(element) } }) } func even(_ array: [Int]) -> [Int] { return array.filter{ $0%2 == 0} } func square(_ array: [Int]) -> [Int] { return array.map{ $0*$0 } } var array = square(even(unique(integerArray)))
这段代码为我们提供了正确的结果,但是您看到最后一行代码的可读性不是那么容易。函数的顺序(从右到左)与我们习惯的功能(从左到右)相反,并且希望在这里看到。我们需要首先将逻辑指向多个嵌入的最内层部分-数组inegerArray,然后指向该数组外部的函数unique,然后再上一层-函数even,最后是结论函数square。这是函数>>>和运算符的“组合” |>,它可以帮助我们以非常方便的方式编写代码,将原始数组的处理表示为函数的“传递者integerArray”: var array1 = integerArray |> unique >>> even >>> square
几乎所有的专业语言,如函数式编程F#,Elixir并Elm使用这些运营商“组成”功能。至于Swift有没有内置运营商组成“功能>>>和|>,但我们可以帮助让他们很容易Generics,电路(closure)和infix运营商: precedencegroup ForwardComposition{ associativity: left higherThan: ForwardApplication } infix operator >>> : ForwardComposition func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C { return { right(left($0)) } } precedencegroup ForwardApplication { associativity: left } infix operator |> : ForwardApplication func |> <A, B>(a: A, f: (A) -> B) -> B { return f(a) }
尽管增加了成本,但在某些情况下,这可以显着提高代码的性能,可读性和可测试性。例如,在内部时,map您可以使用“ composition”运算符放置整个函数链,>>>而不是通过大量数组来追踪数组map: var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init) print (b)
但并非总是一种功能性方法会产生积极效果。最初,当它出现Swift在2014年时,每个人都急着用运算符编写用于函数“组合”的库,并解决了当时的难题,例如JSON使用函数编程运算符进行解析,而不是使用无限嵌套的构造if let。我本人翻译了有关JSON的功能解析的文章,该文章以其优雅的解决方案而使我感到满意,并且是Argo库的粉丝。但是开发人员Swift采取了完全不同的方式,并在面向协议的技术的基础上提出了一种更为简洁的代码编写方式。为了JSON直接将数据“传递” 到Codable,这自动执行该协议,如果你的模型包含已知的Swift数据结构:String,Int,URL,Array,Dictionary,等。 struct Blog: Codable { let id: Int let name: String let url: URL }
随着JSON从一个数据名篇 ... [ { "id" : 73, "name" : "Bloxus test", "url" : "http://remote.bloxus.com/" }, { "id" : 74, "name" : "Manila Test", "url" : "http://flickrtest1.userland.com/" } ]
...目前,您只需要一行代码即可获得一系列博客blogs: let blogs = Bundle.main.path(forResource: "blogs", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Blog].self, from: $0) } print ("\(blogs!)")
每个人都已经安全地忘记了使用函数“组合”的运算符进行解析JSON,如果有另一种更容易理解且更容易使用协议进行解析的方法。如果一切都很简单,那么我们可以将JSON数据“上传” 到更复杂的模型中。假设我们有一个JSON具有名称的数据文件,该文件user.json位于目录中Resources.,其中包含有关某个用户的数据: { "email": "blob@pointfree.co", "id": 42, "name": "Blob" }
我们有一个Codable User,该用户具有来自数据的初始化程序json: struct User: Codable { let email: String let id: Int let name: String init?(json: Data) { if let newValue = try? JSONDecoder().decode(User.self, from: json) { self = newValue } else { return nil } } }
我们可以newUser使用更简单的功能代码轻松地获得新用户: let newUser = Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }
显然,newUser将有一个TYPE Optional,即User?: 假设在我们的目录中
假设在我们的目录中Resources还有另一个文件,其名称为invoices.json,其中包含该用户发票上的数据。 [ { "amountPaid": 1000, "amountDue": 0, "closed": true, "id": 1 }, { "amountPaid": 500, "amountDue": 500, "closed": false, "id": 2 } ]
我们可以像使用一样完全加载这些数据User。让我们将结构定义为发票模型struct Invoice... struct Invoice: Codable { let amountDue: Int let amountPaid: Int let closed: Bool let id: Int }
...并解码上面显示JSON的发票数组invoices,仅更改文件路径和解码逻辑decode: let invoices = Bundle.main.path(forResource: "invoices", ofType: "json") .map( URL.init(fileURLWithPath:) ) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
invoices将是[Invoice]?: 现在,如果用户
现在,如果用户user与发票invoices不相等nil,我们希望将其与发票联系起来,并保存在UserEnvelope与发票一起发送给用户的信封结构中: struct UserEnvelope { let user: User let invoices: [Invoice] }
而不是执行两次if let... if let newUser = newUser, let invoices = invoices { }
...让我们写一个double的函数类似物if let作为辅助Generic函数zip,它将两个Optional值转换为Optional元组: func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? { if let a = a, let b = b { return (a, b) } return nil }
现在,我们没有东西给变量赋值的原因newUser和invoices我们只是嵌入我们所有的新功能zip,使用初始化UserEnvelope.init,它会努力! let userEnv = zip( Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }, Bundle.main.path(forResource: "invoices", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) } ).flatMap (UserEnvelope.init) print ("\(userEnv!)")
在一个表达式中,打包了一种用于以结构形式将JSON数据传递给复杂的数据的完整算法。struct UserEnvelopezip , , . user , JSON , invoices , JSON . .map , , «» .flatMap , , , .
操作zip,map并且flatMap是svoebrazny 领域特定语言(领域特定语言,DSL)将数据转换。我们可以进一步开发此演示,以表示异步读取文件内容是一种特殊功能,您可以在pointfree.co上看到该功能。我不是在任何地方和所有方面都对函数式编程的狂热爱好者,但是我建议适当使用它。结论
我给各种功能编程的示例的特征Swf的盒子”吨«出来,基于使用的高阶函数map,flatMap,reduce,filter和另一个用于序列Sequence,Optional和Result。它们可能是创建代码的“主力军”,,尤其是在其中涉及价值struct和枚举的情况下enum。iOS应用程序开发人员必须拥有此工具。可以在Github上Playground找到所有编译的演示。如果您在启动时遇到问题,可以查看此文章:Playground如何通过“ Launching Simulator”和“ Running Playground”消息消除Xcode Playground的“冻结”错误。参考文献:
Functional Programming in Swift: An Introduction.An Introduction to Functional Programming in Swift.The Many Faces of Flat-Map: Part 3Inside the Standard Library: Sequence.map()Practical functional programming in Swift